
はじめに
当ブログは2025/8/5,6に東京ビッグサイトにて行われたセッションレポートとなります。
タイトル:生成 AI は LLM だけじゃない! 分子情報の基盤モデル開発最前線
登壇者:SyntheticGestalt株式会社 代表取締役CEO 島田 幸輝 氏
セッション概要
分子情報の基盤モデルの開発をされているそのモデル開発における取り組み、なぜテキストや画像と異なり、分子情報の基盤モデルが無いのか、開発おいてどのような学習が必要なのか、その取り組みと成果についてお話しされておりました。
セッション内容
取り組みにおける課題
分子の基盤モデルでは、情報量の少なさにより学習データが少なく、1D、2Dの情報であると、特性などの情報が非常に限られており、データが複雑でもあることから、既存の AI 技術をそのまま応用できないことが課題であるとお話されておりました。
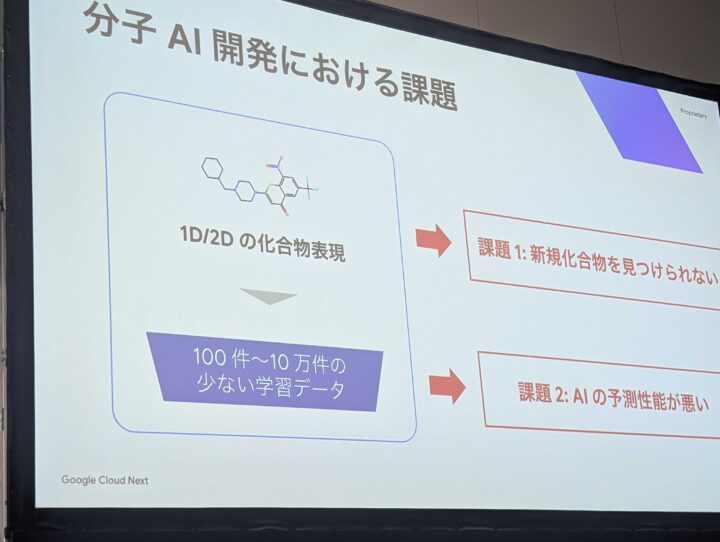
以降に記載する課題に関して SyntheticGestalt 様のページにても記載されておりましたので、詳細ご覧になりたい方はこちらご覧ください
新規化合物が見つけられない
2次元データだと化合物が見つけられず、似たようなパターンであれば人間でも検出できますが、分子 AI では 4D による複雑なパターンによる検出については、AI にしかできない発見になり、これを見つけることが課題となっている。
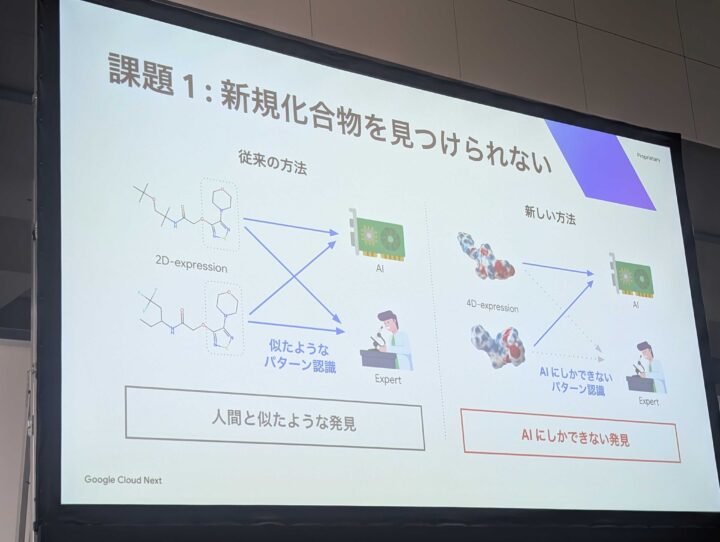
AI の予測性が悪い
従来の方法では学習データと現場データに大きな乖離があり、この大きな乖離を基盤モデルで学習し活用することで、この乖離を埋めることで予測性を高める活用が可能になるとのことでした。

事前学習
近年の注目を浴びた生成 AI では LLM モデルを活用し、テキストや画像における大規模な事前学習を行っておりました。分子 AI では先に記載したように、4D による事前学習が必要であることから、 LMM が重要であるとお話されておりました。
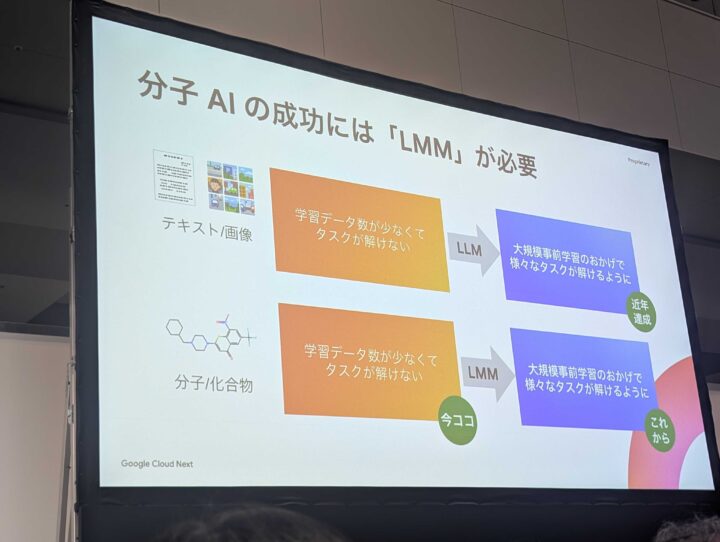
解決策
AI モデルに加えて、基盤モデルを活用することで、高精度で簡単に開発が進められるとのことです。

課題に対しての解決策として重要な3点を挙げられておりました。

それらを解決する基盤モデルとして開発されたのが、次の内容です。
SG4D10B
これらの課題を解決するための分子の基盤モデルとして SG4D10B を開発されて、これが世界最大の分子の基盤モデルとのことです。

基盤モデル開発について
分子 AI では立体構造が重要で表示上グレーの部分がタンパク質でこの形が一定ではなく、様々な山形の形となっているとのことです。

学習においてはこの化合物がどのような立体構造となるのか、という4次元情報が AI 開発では重要となり、

それらを学習データと活用し、分子基盤モデルの中で他を圧倒するモデルを開発することができたとお話されておりました。

訓練手法
4次元情報として、世界的なサプライヤーから情報提供を受けて、100億件のデータポイントを学習データを利用し、開発されたとのことです。
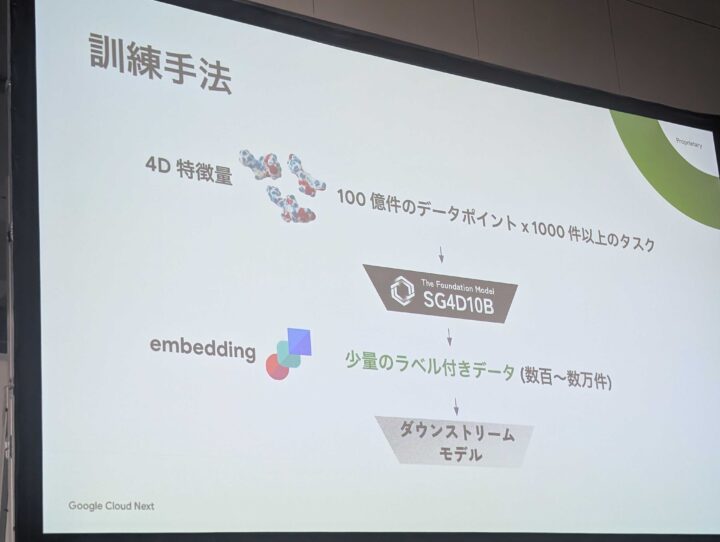
これらは、GPU、CPUクラスターで毎日10万件の処理を行い開発されたと、お話されておりました。このクラスターでの学習処理においては、GENIAC の支援を受けて行われたとのことでした。GENIAC については、弊社も関わらせてもらっているので、こういった分子の分野にも遠いながら関われていることが光栄に感じました。
結果
モデルとしては創薬ベンチマークでも Top3 を誇っており、世界最大のモデルとなっているとのことです。

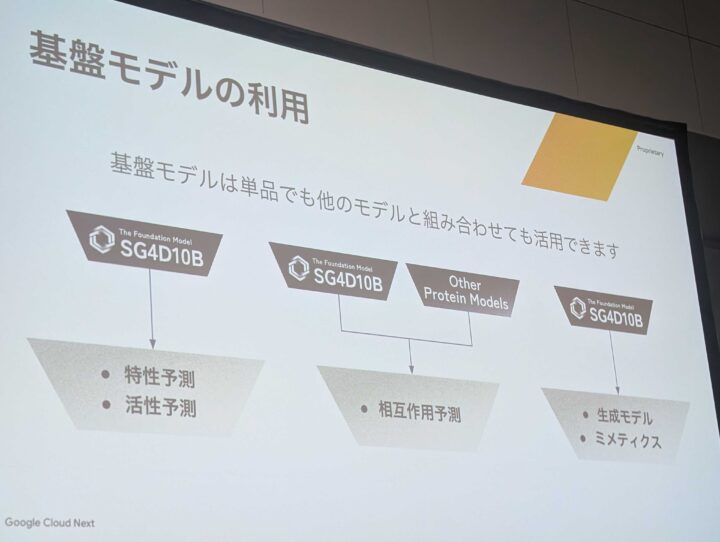
基盤モデルは他のモデルと組み合わせた活用法についてもご紹介されておりました。
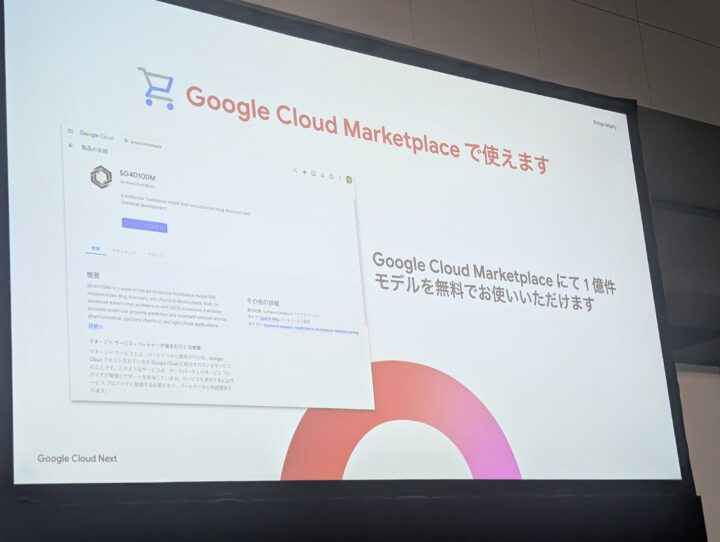
このモデルについては Google Cloud のマーケットプレイスからも利用可能とのことで、誰でも利用可能とのことです。
セッションまとめ
世界最大規模の分子基盤モデルを開発された成果として、今後の新薬等の開発を加速させたいという展望をお話されておりました。

まとめ
分子 AI の基盤モデルという目にする機会は少ないセッションでしたが、単純なテキスト等のモデルと異なり、こういった分野に特化した基盤モデルの開発の貴重なお話を聞くことができて、とても貴重な機会でした。GENIAC にかかわらさせてもらっているので、単純な Google Cloud の環境の側面だけでなく、お客様側の取り組みをお伺いすることができ、良い機会でした。Next Tokyo ではこういった機会も得られるので、ただ技術について学ぶだけでなく、様々な事例を拝聴する目的での参加もありだなと思いました。




