
はじめに
この記事は、Google Cloud Next Tokyo 2025のセッション聴講記事です。
内容は、安全なLLM活用を目的とした日本語LLMガードレール「chakoshi」の開発事例をご紹介します。
セッション情報
- イベント:Google Cloud Next Tokyo 2025
- セッション名:安全な LLM 活用へ: Google Cloud と Gemma で実装する日本語 LLM ガードレール
- 発表者:NTTドコモビジネス株式会社 新井 一博 氏、深山 健司 氏
この記事を読むと得られること
- 日本語特化ガードレール「chakoshi」の機能と技術的な仕組み
- オープンソースLLMのセルフホスト実装における実践的な知見
- Google CloudとGemmaを活用したLLMサービス開発のノウハウ
- リソース制約下でのモデル最適化手法(量子化vs低精度化の比較検証)
対象読者:オープンソースLLMを使ったサービス開発を検討している方、Google CloudでのLLM活用に関心のある方
LLM活用の現実:便利さと隣り合わせのリスク
急速に広がるLLM活用
LLMの活用が企業でも急速に広がっています。カスタマーサポートの自動応答、社内文書の要約、コンテンツ生成など、様々な業務でその威力を発揮しているのを目にする機会も増えました。
「コストを削減できた」「業務効率が大幅に向上した」「これまでできなかった分析が可能になった」
こうした成功事例を聞くと、自社でもどんどんLLMを活用したい!となりますよね。
見落としがちなLLM活用のリスク
しかし、こうした成功事例に注目が集まる一方で、LLM活用に潜むリスクについては十分に検討されていないケースは少なくありません。機密情報の漏洩、事実と異なる情報の生成、不適切なコンテンツの出力など、これらのリスクが現実になったとき、企業への影響は計り知れません。
LLMの便利さと隣り合わせに存在するリスクを適切に管理することが、安全なLLM活用の鍵となります。
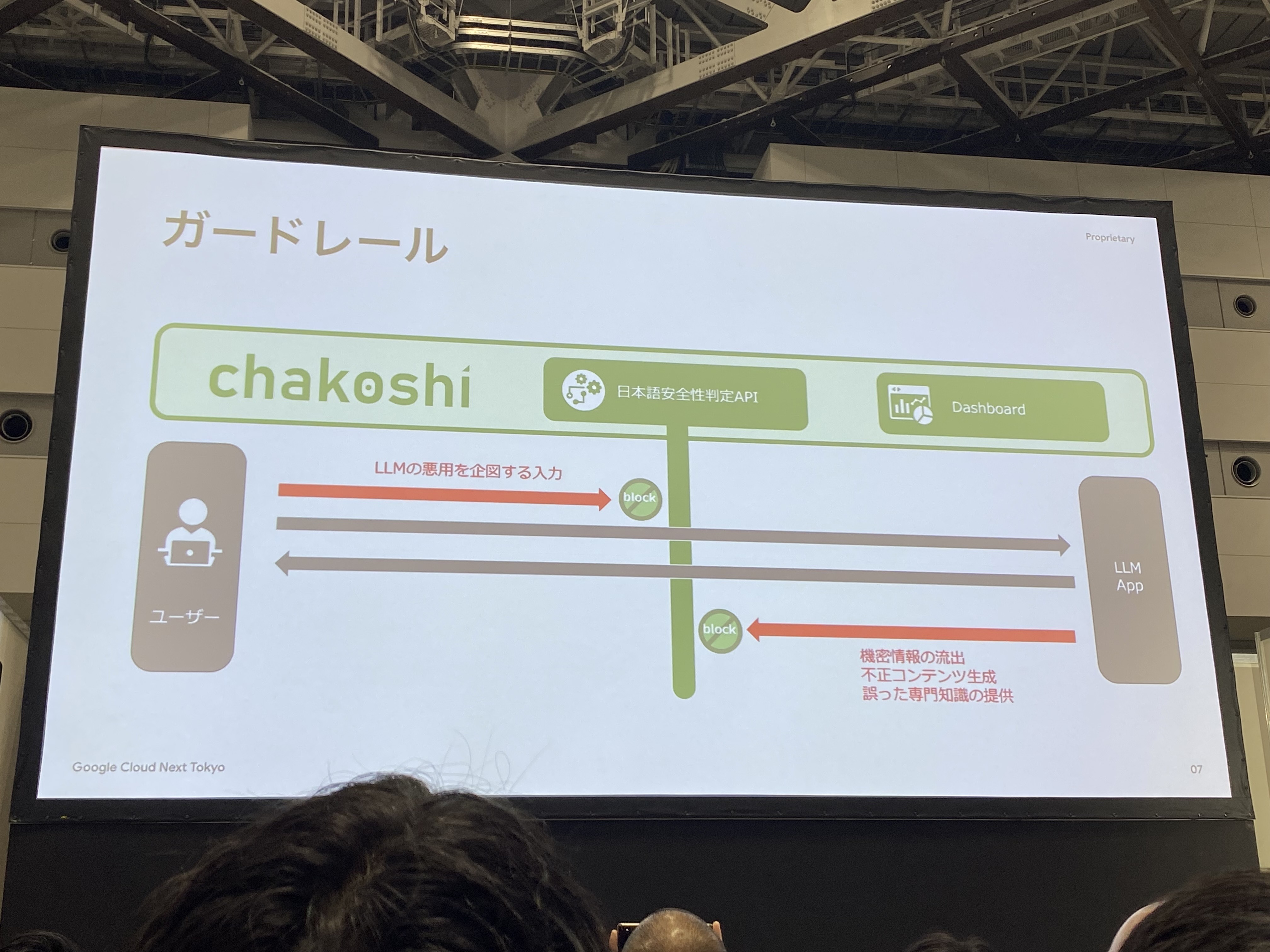
chakoshiとは?日本語ガードレールサービス
サービス概要
NTTドコモビジネス株式会社が開発したchakoshiは、生成AIアプリのリスク低減を目的とした日本語特化のLLMガードレールです。
現在はパブリックベータ版として提供されています。
主要機能
- 入出力の双方向監視:ユーザーからの入力とLLMからの出力をリアルタイムでチェック
- カスタマイズ機能:使い手側が検知項目を追加・変更可能
- 管理機能:検知履歴をUIから確認、ダッシュボードでの監視・分析
- APIサービス:既存アプリケーションへの組み込みが容易
chakoshiを支える技術
chakoshiのサービスを実現しているのは、Gemmaをベースにファインチューニングした日本語特化のテキスト安全評価モデルです。このモデルをGoogle Cloud上で動作させ、スケーラブルなAPIサービスとして提供しています。
現在パブリックベータ版として開発が進むchakoshiですが、その開発過程では、オープンソースLLMを使った実用的なサービスを構築するための様々な技術的な課題に取り組むことになりました。
ここからは、その開発を通じて得られた実践的な知見をご紹介します。
特に「インフラ」と「モデル」の2つの観点から、Google CloudとGemmaを活用したLLMサービス開発で実際に直面した課題とその解決アプローチを詳しく解説していきます。
インフラの知見:推論サーバのサーバレス化
サーバレス化への取り組み
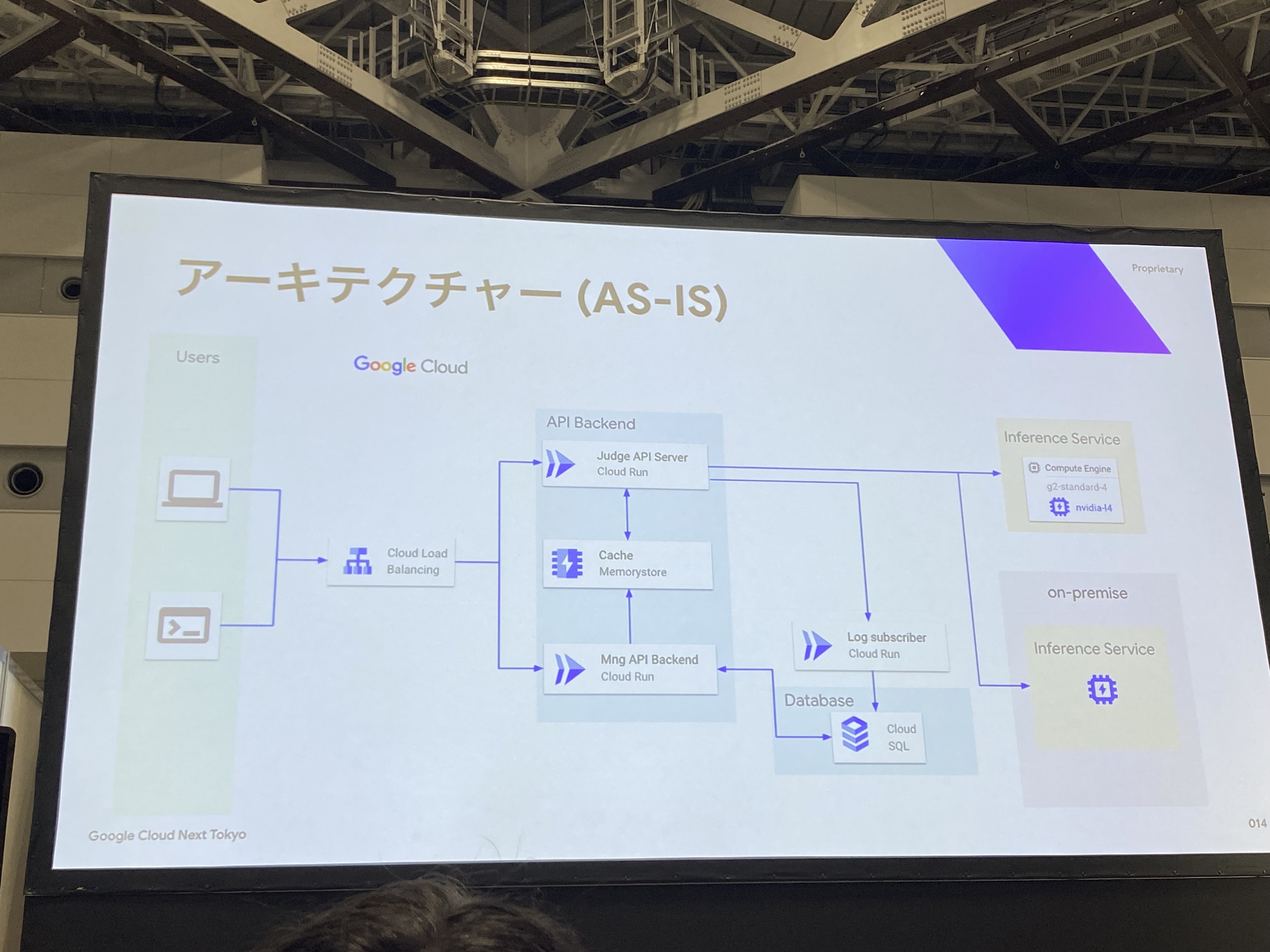
chakoshiでは、推論サーバのサーバレス化に取り組んでいます。
当初はCompute Engine(g2-standard-4 + NVIDIA L4)で運用していましたが、現在はCloud Run GPUへの移行を進めています。
推論サーバ以外は、全てサーバレスで構成されています。
chakoshiモデル推論インフラ要件
サーバレス化を検討するにあたり、インフラ要件は、主に以下の3つです。
- オートスケール
- 低学習コスト
- CI/CD
このうち、特に今回の「LLMガードレール」というサービス特有の要件がオートスケールです。LLMガードレールは、ユーザーアプリの呼び出しに比例したリクエスト数となるため、予測困難で急激な増減があるトラフィックへの柔軟な対応が必要になります。

Google CloudでのGPU利用サービス選択
chakoshiの要件を満たすため、Google Cloud上でGPUを利用できる3つのサービスを比較検討しました。
サービス比較
| サービス | 利用可能GPU | 学習コスト | CI/CDとの親和性 |
|---|---|---|---|
| Compute Engine | B200, B100, H200, H100, A100, L4, T4 | 低 | 低 |
| GKE | B200, B100, H200, H100, A100, L4, T4 | 高 | 高 |
| Cloud Run | L4のみ | 低 | 高 |
各サービスの特徴
Compute Engine
- 幅広いGPU選択肢があるものの、CI/CDパイプラインとの統合が困難
- VMの管理やデプロイプロセスが複雑
GKE (Google Kubernetes Engine)
- 豊富なGPU選択肢とCI/CD親和性を持つが、学習コストが高い
- Kubernetesの知識や運用ノウハウが必要
Cloud Run
- 利用可能GPUはL4のみという制限があるものの、「いつも通り使える」サービス
- 既存の知識とワークフローをそのまま活用可能
Cloud Run採用の決定
この比較検討の結果、chakoshiチームはCloud Runを選択しました。
決定理由
- 使い慣れたサーバレスサービス
- 既存CI/CDパイプライン(GitHub Actions)をほぼ変更なしで継続利用可能
セッションでは具体的なチーム規模や学習コストの評価方法については言及されませんでしたが、「使い慣れたサーバレスサービス」「既存CI/CDパイプラインをほぼ変更なしで継続利用可能」という発表者のコメントから、開発効率を重視した判断だったことが伺えます。これにより、インフラの学習や運用負荷を最小限に抑えながら、本来の目的であるLLMガードレールサービスの開発に集中できる環境を実現しています。
個人的にも、Cloud Runは学習コストが少なく使いやすいサービスで大好きです。
さらになんと!GPUまで使用できるようになり、鬼に金棒ですね!Cloud RunにGPU!
推論サーバをCloud Run GPUにすると、全てサーバレスでの構成が実現しますね。
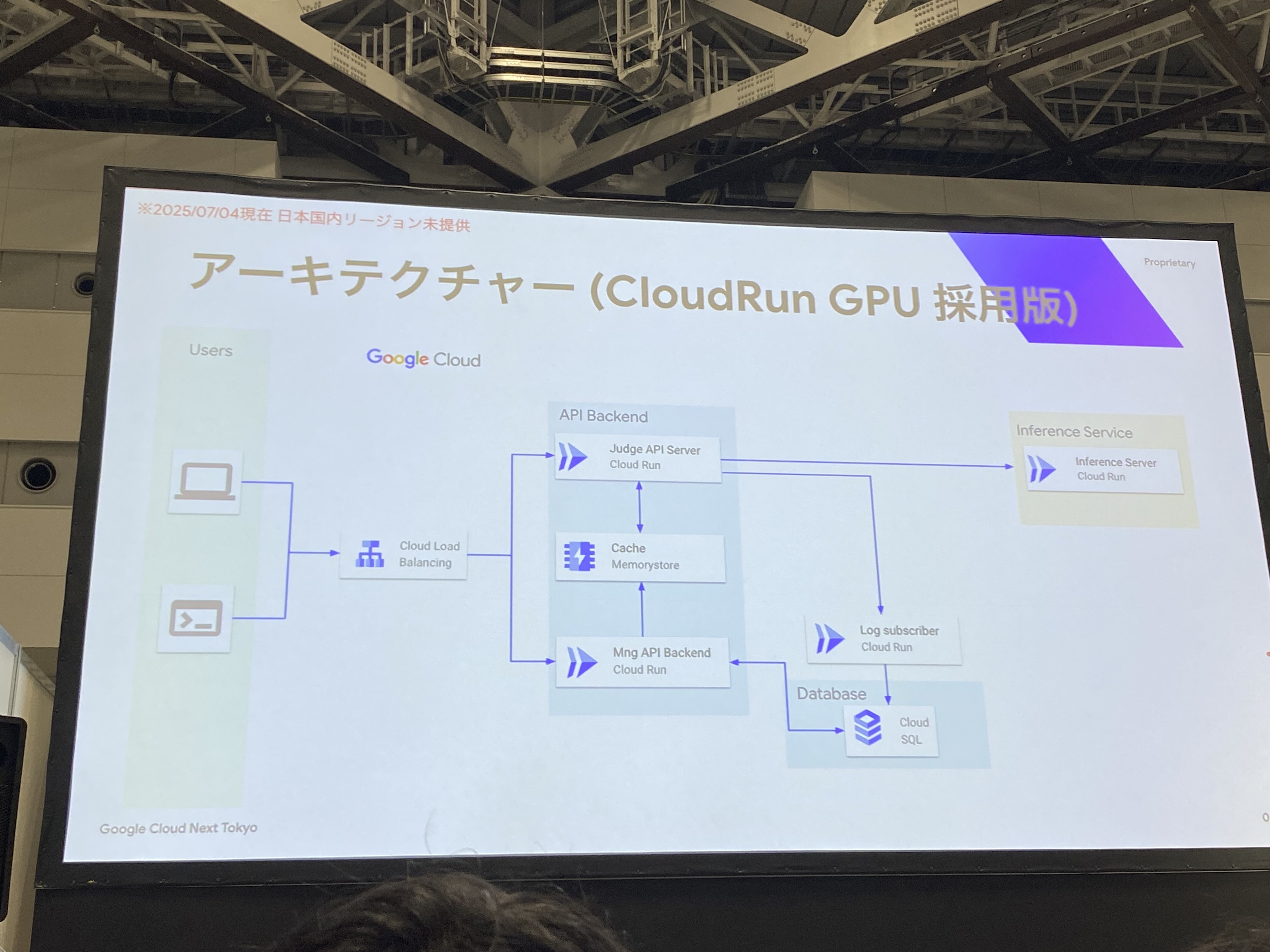
Cloud Runを推論サーバとして実装した際のポイント
ここからは、Cloud Runを推論サーバとして実装した際に、chakoshiチームが実際の開発で得られた知見を紹介していきます。ポイントは、主に以下の3つです。
- マルチコンテナ構成による責任分離
- 最大同時リクエスト数の設定
- オートスケール
1. マルチコンテナ構成による責任分離
chakoshiでは、Cloud Run上で以下の構成を採用しています。
構成
- APPコンテナ:ビジネスロジック、API処理
- 推論コンテナ(vLLM):モデル推論処理
なぜこの構成にしたのか?
この分離により、2つの大きなメリットが挙げられました。
メリット1:開発効率の大幅向上
- 既存のイメージ(vLLM)をそのまま使用できる
- ビルド時間が大幅に短縮
- 複雑なライブラリ依存関係の管理から解放
- バージョンアップ時のトラブルを回避
メリット2:運用の柔軟性
- APPコンテナに影響を与えずモデル更新が可能
- 異なる推論エンジンへの切り替えが容易
- A/Bテストの実施が可能
- モデル改善サイクルの高速化
このマルチコンテナ構成は、開発効率と運用の柔軟性を両立する非常に優れたアプローチですね。

2. 最大同時リクエスト数の適切な設定
Cloud Runのデフォルト設定には、LLM推論において重要な落とし穴があります。
落とし穴:デフォルト設定80は大きすぎる
Cloud Runはデフォルトで80同時リクエストを処理しますが、LLM推論では全て処理することは難しいです。
なぜ80は大きすぎるのか
- 1リクエストあたりの処理時間が長い(数秒〜数十秒)
- GPUメモリ使用量が大きい
ここがポイント:vLLMの最大処理バッチ数とCloud Runのリクエスト最大同時実行数を一致させる
- vLLMの最大処理バッチ数
max-num-seqsを確認(使用するイメージや、ライブラリの設定による) - Cloud Runの同時リクエスト数を同じ値に設定
- これにより安定したレスポンス時間を保証

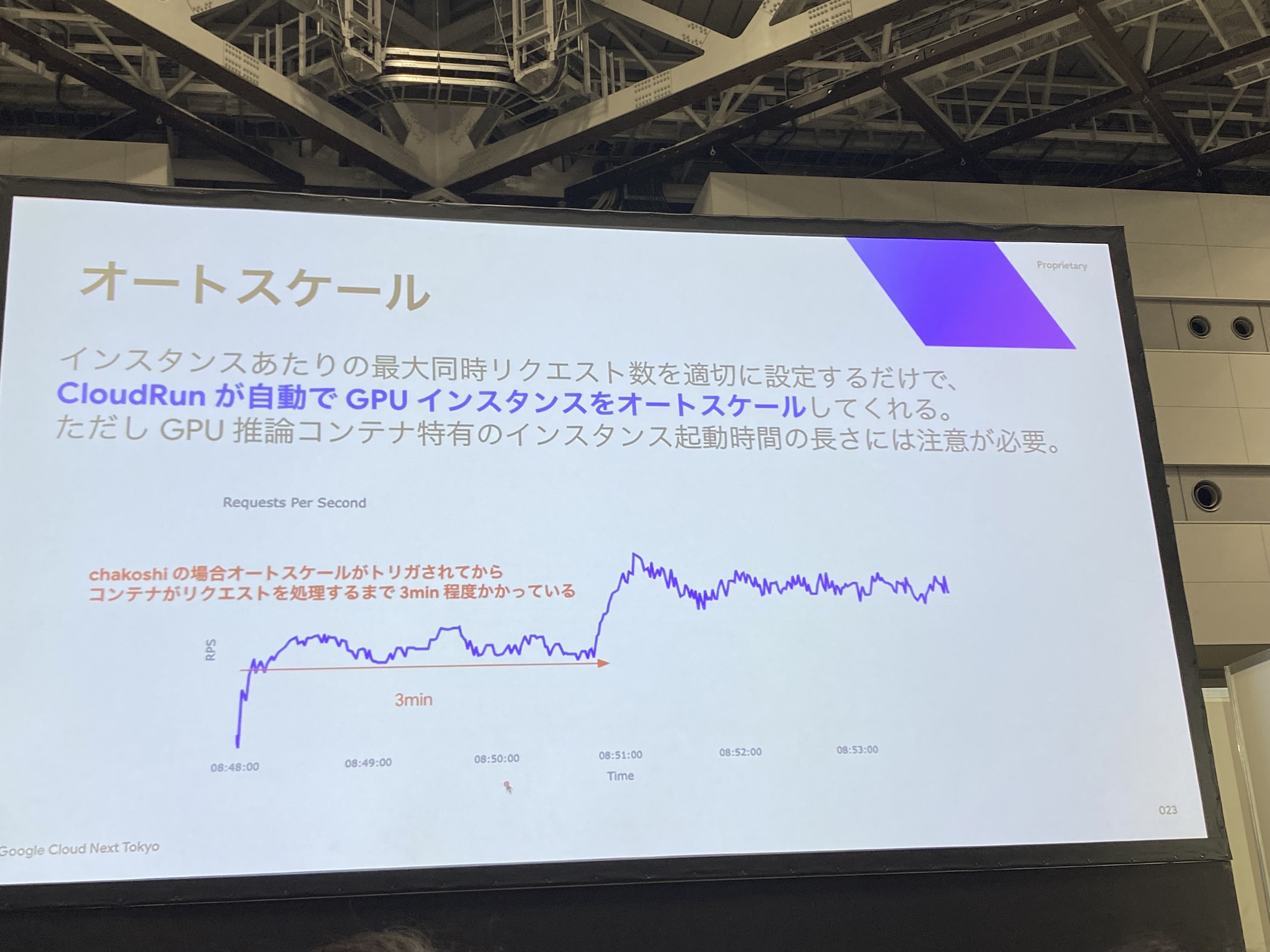
3. オートスケール時の注意点
Cloud Run GPUには、通常のCloud Runとは異なる特徴があります。
課題:起動時間が長い
GPU推論コンテナの起動には約3分かかります。
なぜこんなに時間がかかるのか
推論イメージ、モデルサイズが大きいため、GPU推論コンテナの起動に時間がかかってしまいます。
実運用での対策
chakoshiチームでは、ある程度余裕をみたホットスタンバイをさせてこの問題に対策しているようでした。
急激なトラフィック増加に備える場合、事前のスケーリング戦略が重要になりますね。
考慮事項
Cloud Run GPUを推論サーバとして使用するための考慮事項は、以下の3つのポイントが紹介されました。
- スケール時のラグ
- GPU選択肢が現状L4のみ
- 日本リージョンに未対応(2025年8月時点)
特に日本リージョン対応については、早く対応してほしいですよね!(レイテンシとかコンプライアンスとかとかとか)
モデルの知見:Gemmaの活用と最適化
なぜGemmaを選択したのか
chakoshiに求められるモデル要件
まず、chakoshiが実現すべき機能から、モデルに求められる要件を整理しました。
- 日本語テキストの有害性判定
- 文脈・ニュアンスの読解
- 口語・俗語への対応力
- 判定の透明性と精度
- 検知項目のカスタマイズ
- 独自カテゴリの追加・変更
- 追加によるデグレード防止
Gemma選択の理由
これらの要件を満たすため、chakoshiチームはGemmaを選択しました。
Gemma選択の理由
- 多言語対応:日本語含む140以上の言語をサポート
- ファインチューニングのしやすさ:独自判定基準の実装が容易
- セキュリティ:外部ネットワークから隔離された環境での稼働が可能
- エコシステム:Google Cloudとの親和性・充実したサポート
課題:L4 GPU制約下での高性能モデル運用
モデル精度とGPU制約のジレンマ
Gemmaを選択した後、chakoshiチームはモデルサイズ別の精度を比較しました。
chakoshiタスクでのF1スコア比較
| モデル | F1スコア | コメント |
|---|---|---|
| google/gemma-3-27b-it | 0.92 | 判定精度○、指示追従○ |
| google/gemma-3-12b-it | 0.89 | 判定精度○、指示追従○ |
| google/gemma-2-9b-it | 0.83 | 判定精度○、指示追従○ |
| google/gemma-3-4b-it | 0.81 | 判定精度○、指示追従△ |
だかしかし、ここで課題が生まれてしまいます。
課題:27Bモデルが最高性能だが、L4 GPUに乗らない
27Bモデルが最も高い精度(F1スコア: 0.92)を示しましたが、Cloud Run GPUのL4制約により運用できないことが判明しました。
メモリ使用量の現実
| モデル | 初期メモリ(GB) | ピークメモリ(GB) |
|---|---|---|
| google/gemma-3-27b-it | 52.4 | 56.3 |
| google/gemma-3-12b-it | 23.2 | 25.5 |
| google/gemma-2-9b-it | 18.1 | 19.6 |
| google/gemma-3-4b-it | 7.9 | 9.5 |
chakoshiの非機能要件:
- NVIDIA L4 GPU VRAM 24GB
- API最大入力文字数 2048文字
27Bモデルは56.3GBのピークメモリが必要ですが、L4 GPUは24GBしかありません。
この状況でCloud Runの利便性を活かしながらモデル性能を最大化するという、まさにエンジニアリングの醍醐味を感じる課題ですね。
インフラ制約とモデル性能のバランスを取る判断が求められた結果、
chakoshiチームは、モデルサイズの圧縮を試みたようです。
解決策:モデルの量子化・低精度化
3つのアプローチを検証
この課題を解決するため、chakoshiチームは12Bモデルをベースに3つの最適化手法を比較検証しました。
検証した手法
1. 量子化手法
- PTQ (Post Training Quantization):学習済みモデルの後処理量子化
- QAT (Quantization Aware Training):量子化を考慮したファインチューニング
2. 低精度化手法
- FP8:8bit浮動小数点での学習・推論
実装ツール:pytorch/ao を利用
検証結果とFP8採用
google/gemma-3-12b-itでの比較結果
| 手法 | F1スコア | ピークメモリ(GB) |
|---|---|---|
| ベースライン(BF16) | 0.89 | 25.5 |
| PTQ(int8) | 0.82 | 13.4 |
| QAT(int8) | 0.86 | 13.4 |
| FP8 | 0.87 | 13.4 |
FP8を採用した理由
- 精度劣化が最小:量子化手法より精度劣化が少ない(0.87 vs 0.82/0.86)
- メモリ効率:25.5GB → 13.4GBで大幅削減、L4 24GBに収まる
この最適化により、ほぼ精度劣化なくL4 GPUに載せることができるようになり、Cloud Run GPUでの運用が実現しました。ハッピーエンド。
まとめ
技術選択の全体像
chakoshi開発における主要な技術選択
- モデル選択:Gemma(オープンソース、日本語対応、ファインチューニング容易)
- インフラ:Cloud Run GPU(サーバレス、スケーラブル、CI/CD親和性)
- 最適化:FP8低精度化(精度維持とメモリ効率の両立)
chakoshi開発で得られた知見
インフラ面
- Cloud Run GPUによるサーバレス推論基盤は非常に有効
- マルチコンテナ構成による責任分離がキー
- 最大同時リクエスト数とオートスケール設定の重要性
モデル面
- Gemmaの日本語対応とファインチューニング容易性が決め手
- L4 GPU制約下でのモデルサイズ選択の現実的判断
- FP8低精度化による精度とメモリ効率のバランス実現
さいごにひとこと
いかがだったでしょうか。chakoshiの開発事例を通じて、Google CloudとGemmaを活用した実践的なLLMサービス開発の知見をご紹介しました。とても面白いセッションでずっとワクワクしっぱなしでした。
個人的に最も共感したのは、Cloud Run GPUでの「マルチコンテナ構成による責任分離」の話でした。既存のvLLM公式イメージをそのまま使うメリットの説明で「そうそう、それそれ!」となりました。ライブラリの依存関係の管理って本当に辛いし、ビルド時間もかかるし、そんなことより開発したい!といつも思っているので、すごく共感しました。
うおーーー、漲ってきます、迸ってきます。
Cloud Run GPUとGemmaの最強タッグで、LLMサービスをモリモリ開発して参りましょう。




