
はじめに
当記事は、先日開催された Google Cloud Next Tokyo 2025 の中で行われたセッションのレポートとなります。
タイトル:BigQuery 最新アップデート速報!Google Cloud Next(米国開催)発表内容から見るデータ分析の未来
登壇:Google Cloud 山田 雄氏
セッション概要
本セッションでは、データ分析基盤として重要な役割を担う BigQuery の最新機能について、Google Cloud Next(米国開催)での発表内容を中心にご紹介いただきました。
サイロ化されたインサイトから統合インテリジェンスへ
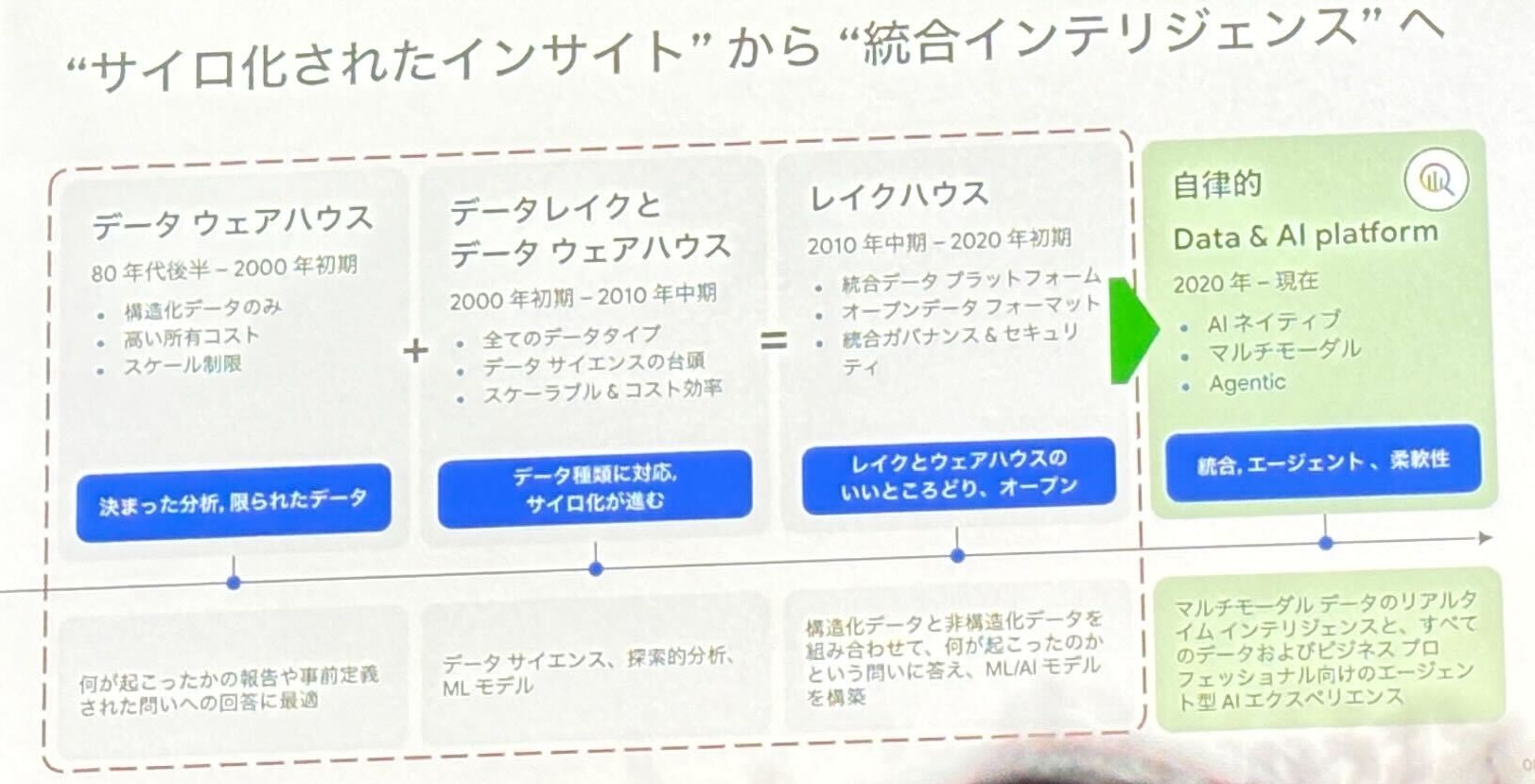
まず、80年代後半から現在に至るまでのデータ基盤の変遷が紹介されました。
構造化データを扱うデータウェアハウスの時代から、あらゆるデータをそのまま蓄積するデータレイクの時代を経て、両者の利点を統合したレイクハウスが生まれ、そして2020年から現在までは、自律的 Data & AI platform というコンセプトがあるとのことです。
自律的 Data & AI platform は、以下のように定義されています。

BigQuery の3つのイノベーション
本セッションのテーマである、BigQuery の3つのイノベーションがこちらになります。
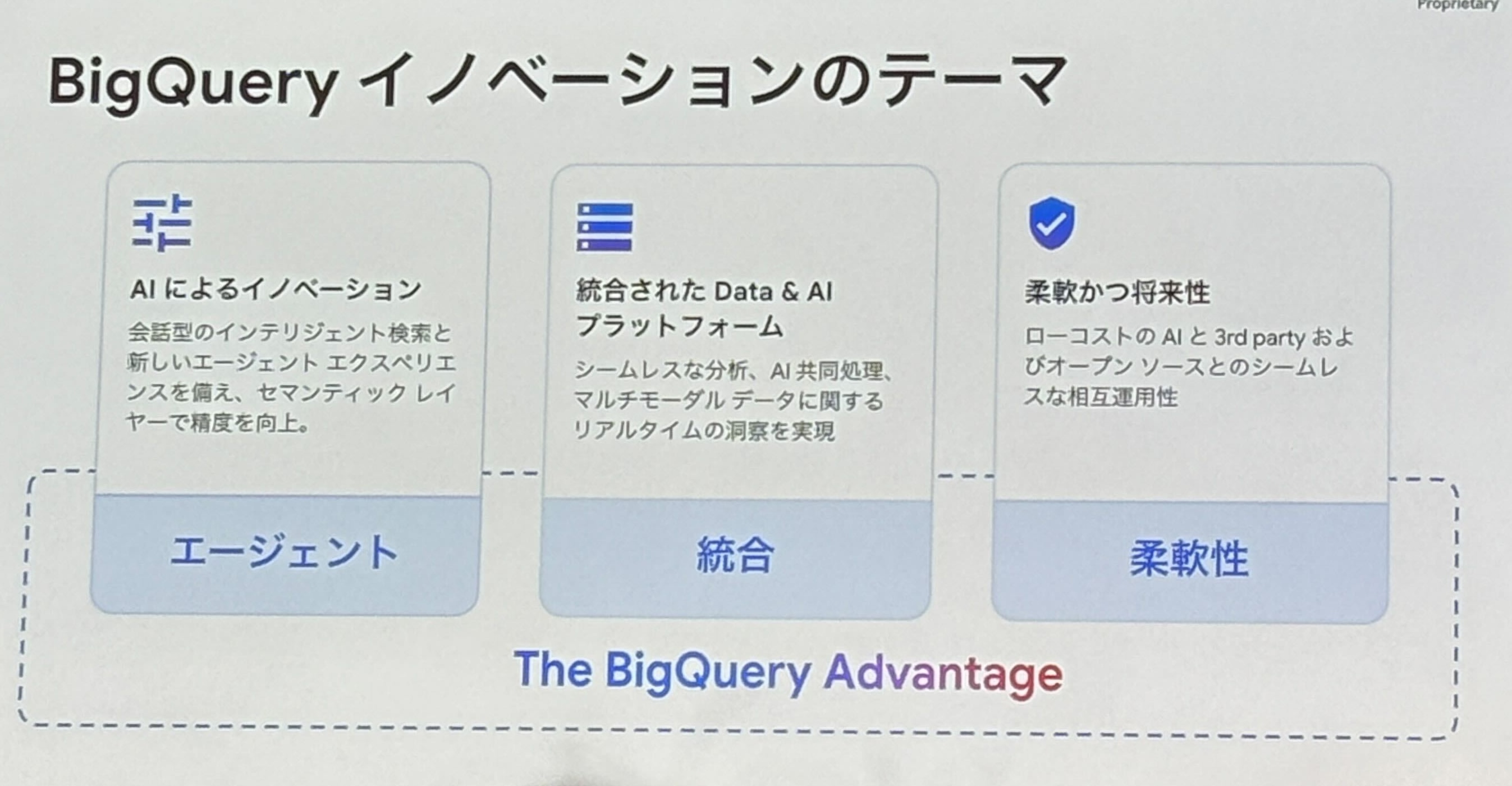
- AI によるイノベーション (エージェント)
- 統合された Data & AI プラットフォーム (統合)
- 柔軟かつ将来性 (柔軟性)
アップデート内容
ここから BigQuery のアップデート内容が紹介されました。各機能には一般提供されているものやプレビュー版のものがありました。
各パートについてざっくりとご紹介させていただきます。
- データエージェントファミリー
- Data Engineering Agent
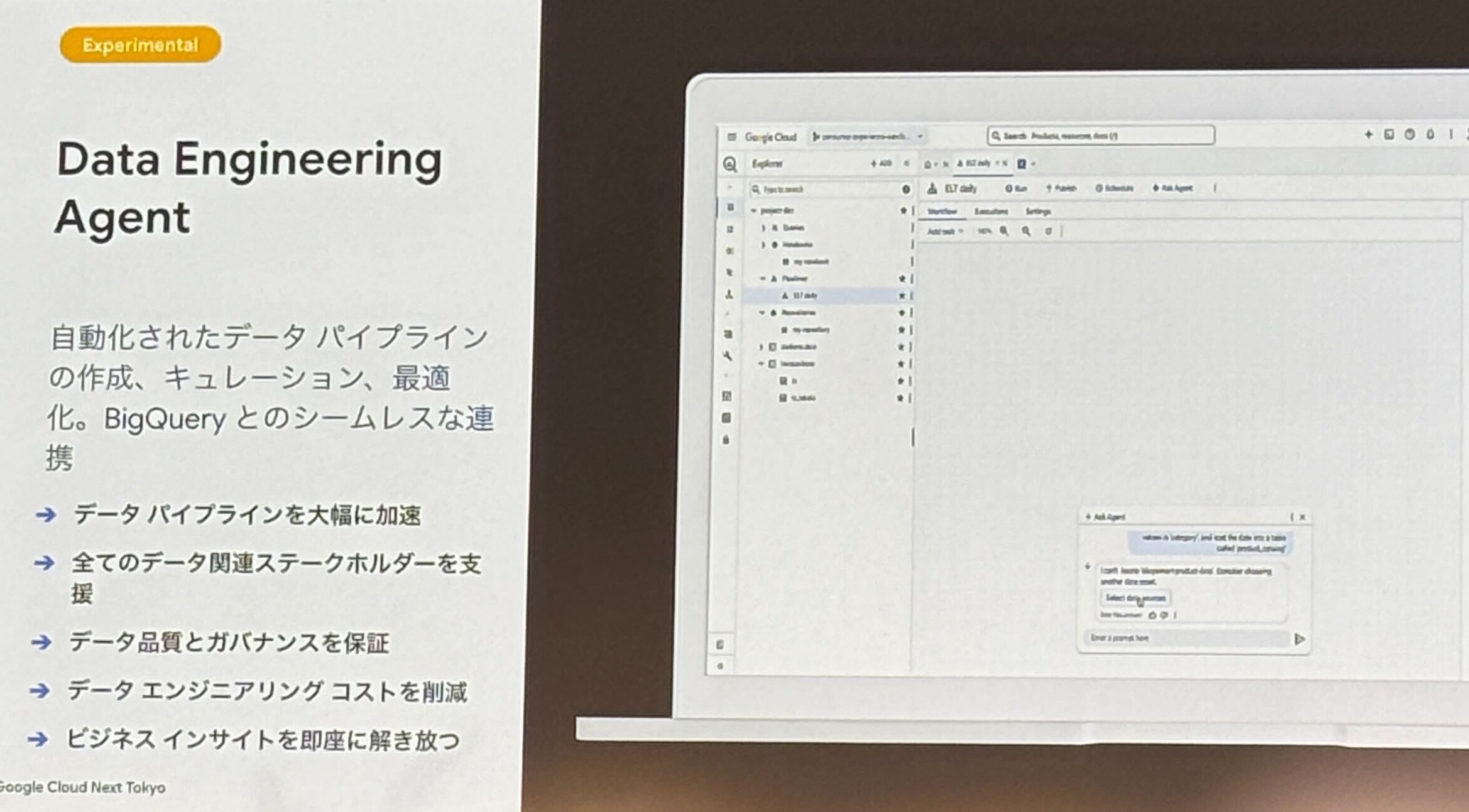
- データパイプライン構築の自動化 (自然言語による指示も可能)
- Data Governance Agent
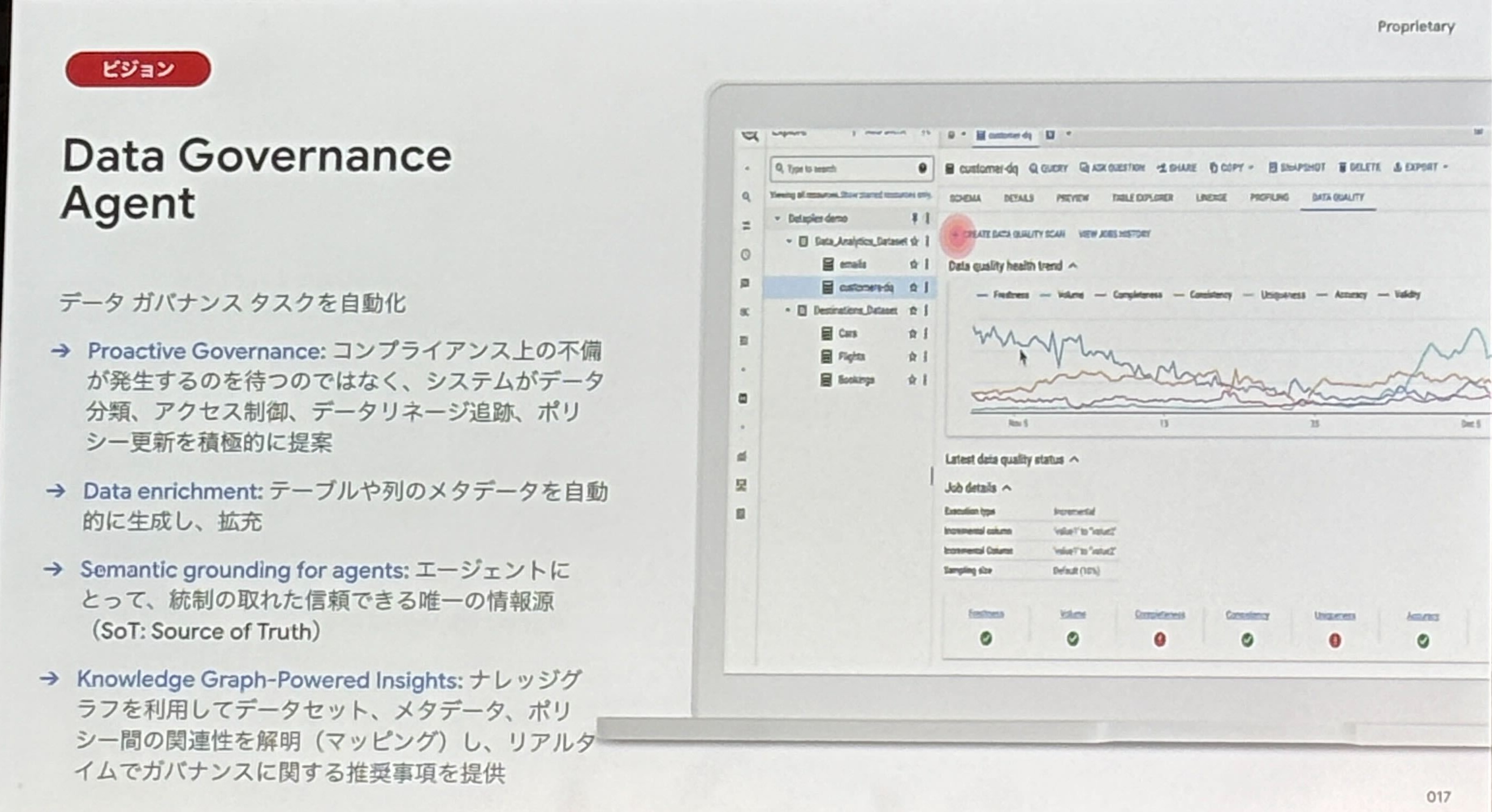
- コンプライアンス不備の事前検知と提案
- テーブルや列のメタデータ(説明文など)を自動で生成・拡充
- ナレッジグラフを活用し、データ間の関連性を可視化
- Data Science Agent
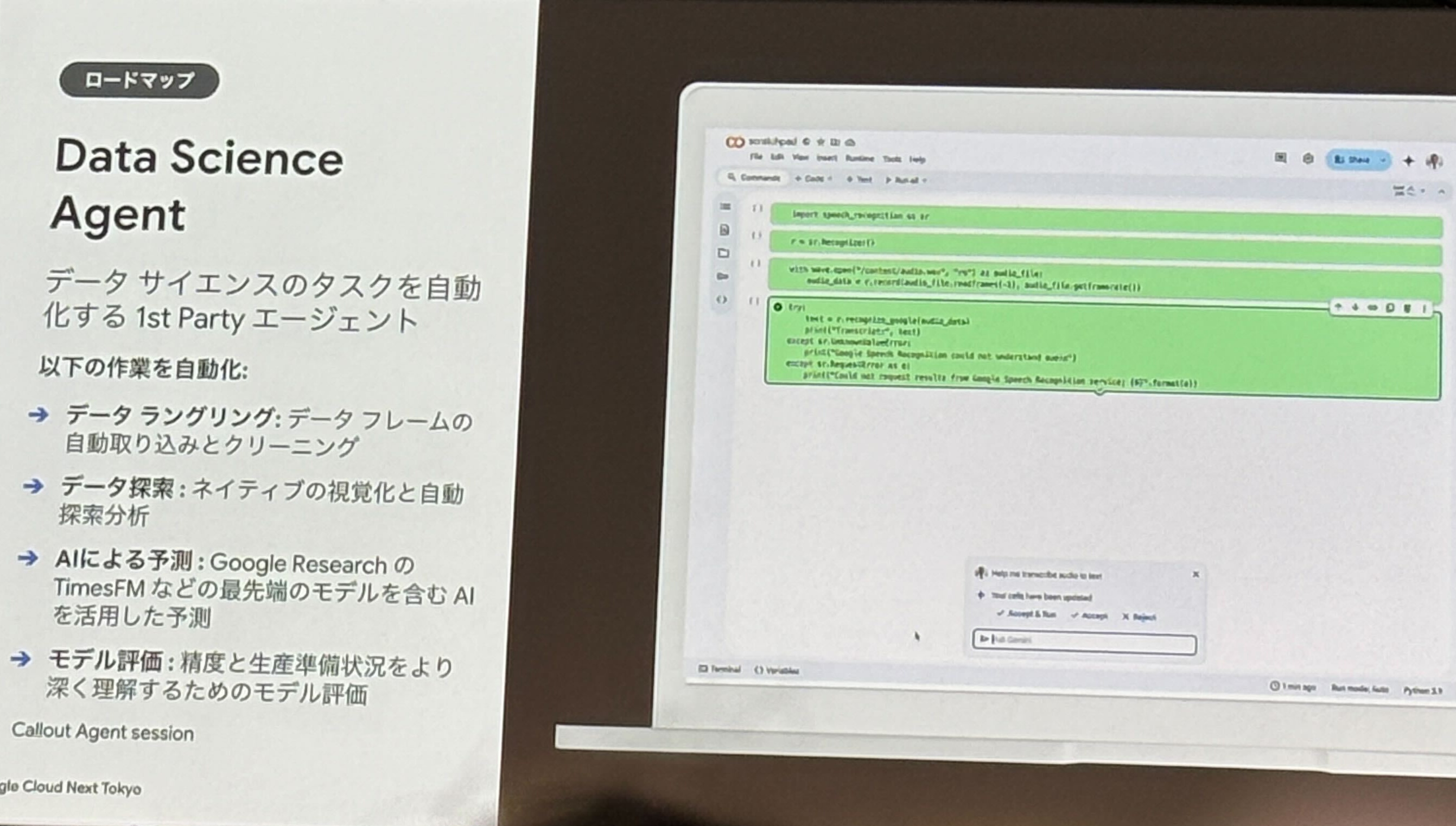
- 探索的データ分析(EDA)の自動化
- Colabノートブックとの連携
- データ可視化とモデリングの効率化
- Conversational Analytics Agent
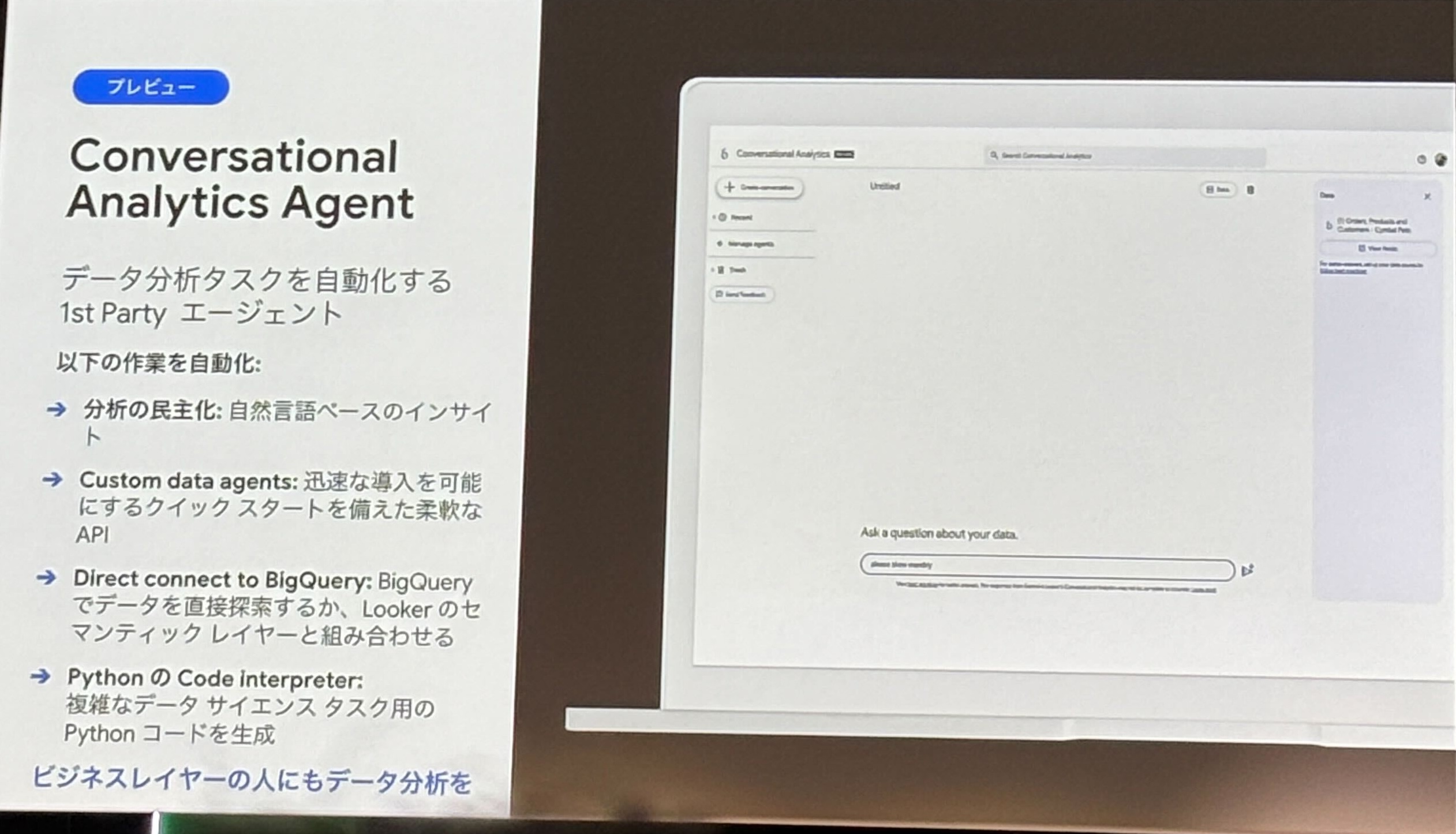
- 自然言語でのデータ検索(Data QnA)
- 専門的な SQL クエリを書かなくてもデータ分析が可能
- 自然言語でのデータ検索(Data QnA)
- エージェントを活用したメダリオンアーキテクチャ (メダリオンアーキテクチャ with Data Agents)
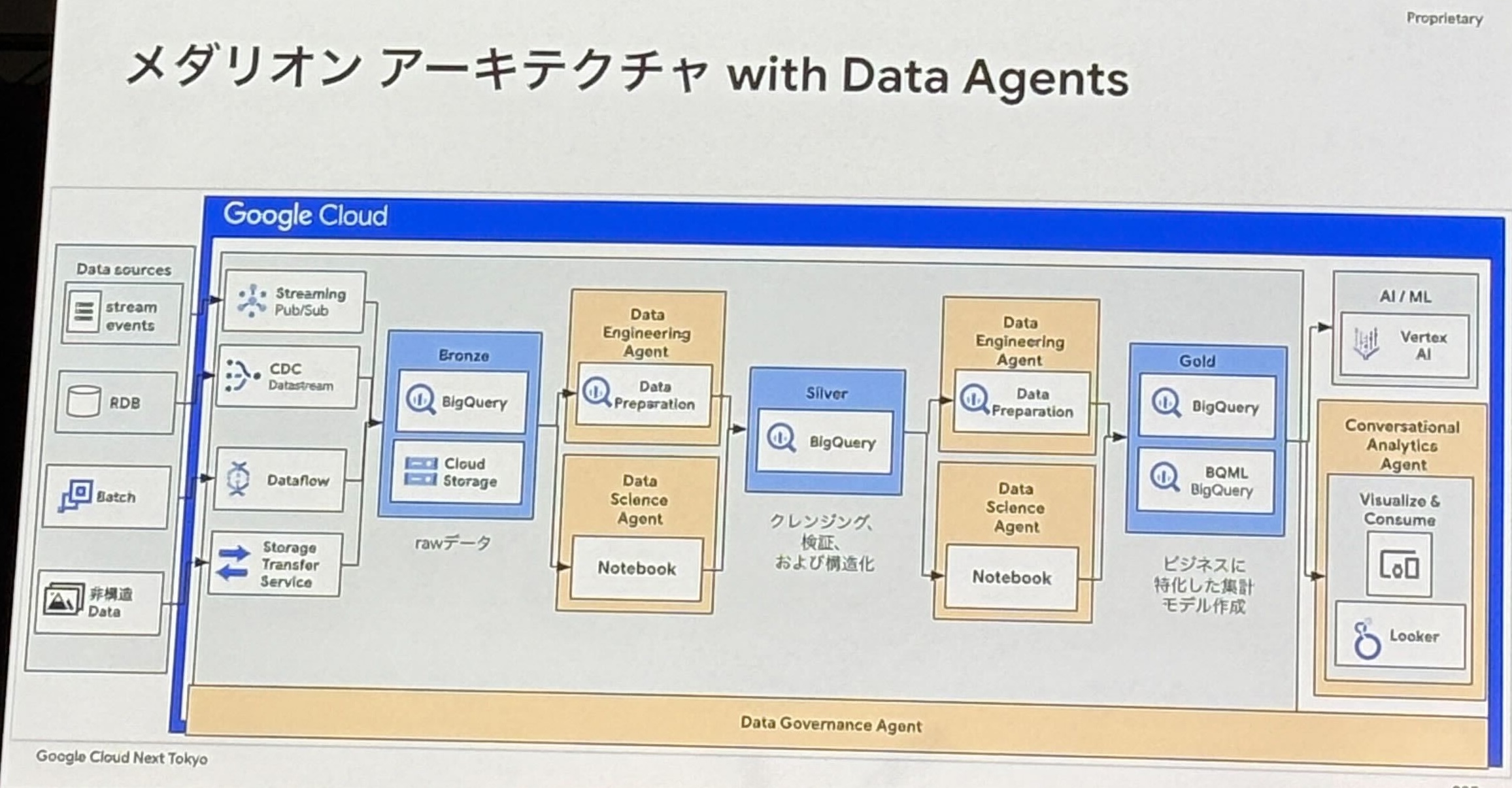
- データ変換処理は Data Engineering Agent、品質チェックは Data Governance Agent、モデル作成は Data Science Agent、データ分析は Conversational Analytics Agent がそれぞれ支援。
- Data Engineering Agent
- Gemini in BigQuery
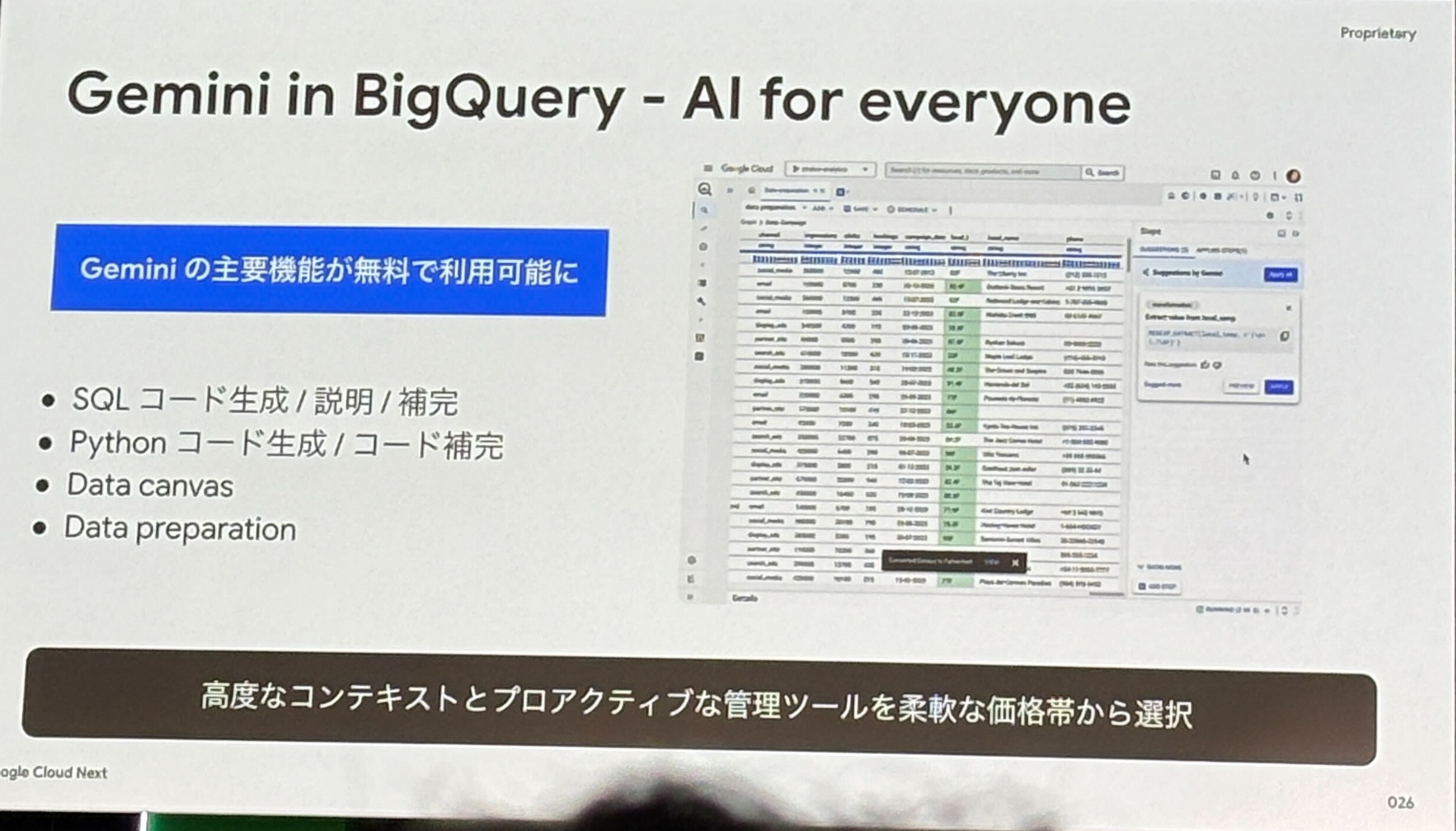
- SQL や Python コードの生成や補完
- 異なる DB の SQL を GoogleSQL へ翻訳
- BigQuery Data Preparation では、SQL データパイプラインの開発やデータの準備をサポート
- Data Canvas では、自然言語から SQL やチャートを自動生成し、ユーザーのデータ分析をサポート
- BigQuery AI Query Engine
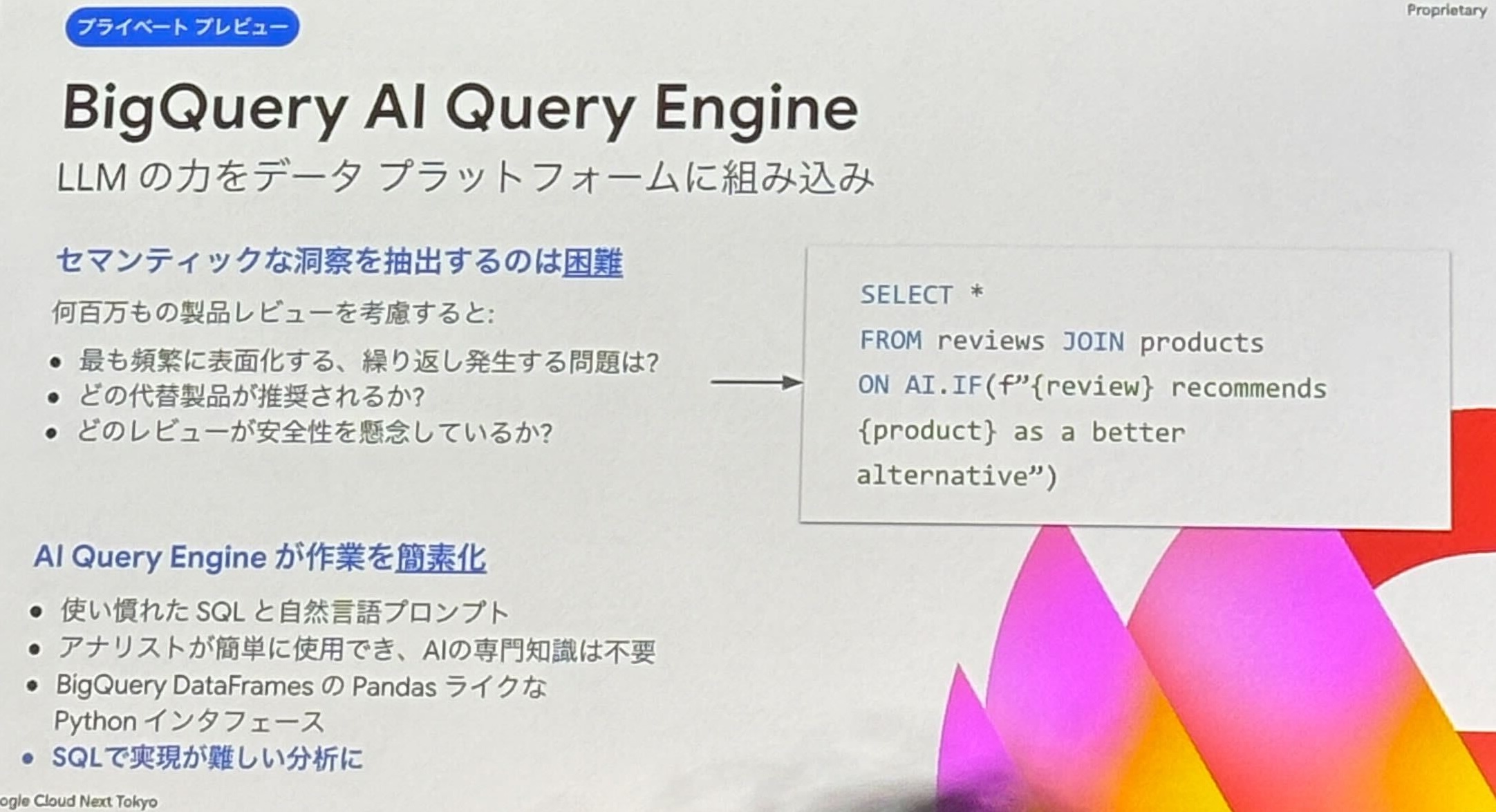
- LLM の力を活用し、自然言語から高度なセマンティック (意味的) な分析クエリを生成
- 新しい Workload Management
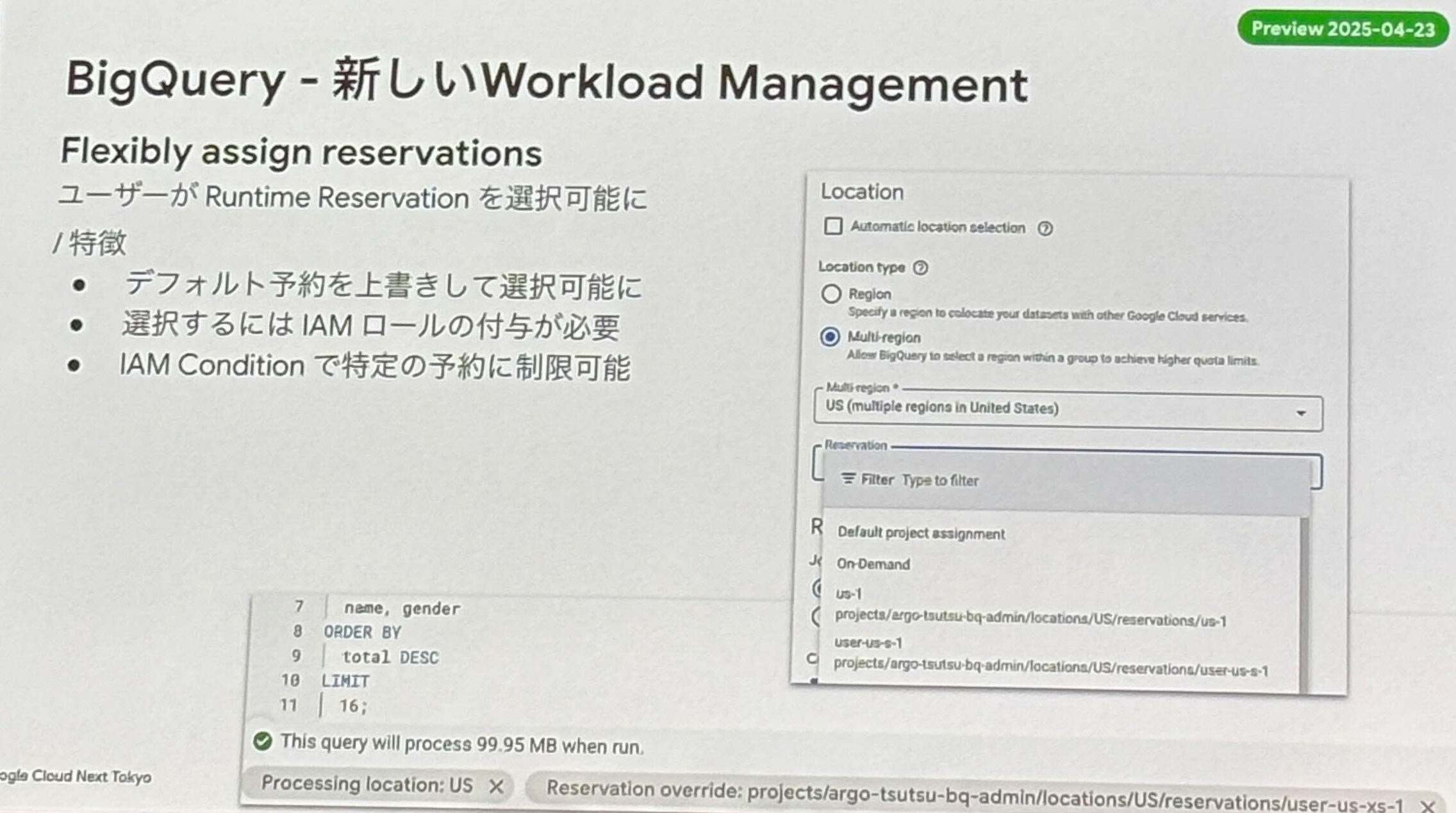
- これまでプロジェクト単位で設定していた reservation をユーザーが選択可能となった
- BigQuery クエリ実行グラフと SQL 文の対応可視化
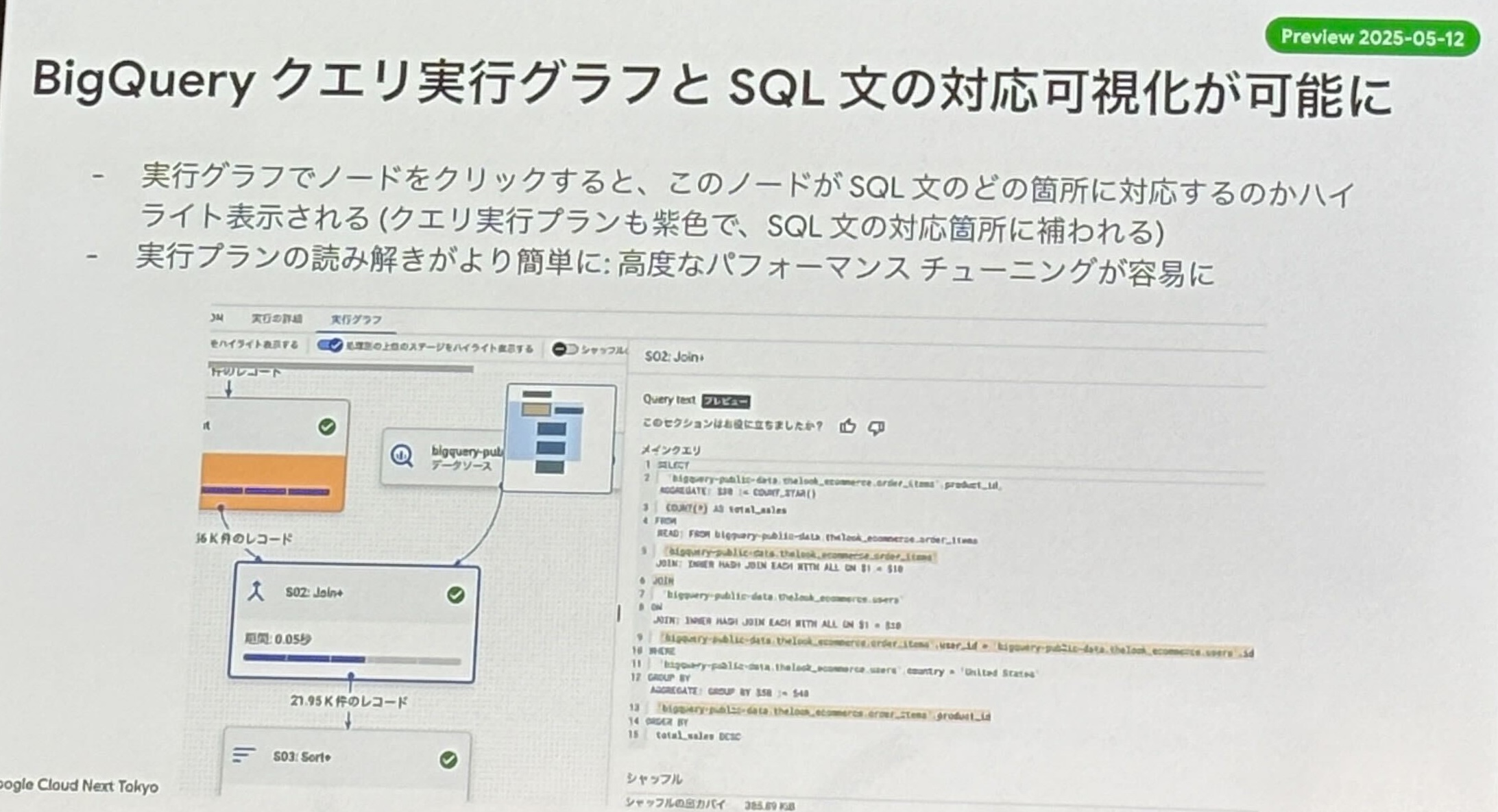
- 実行グラフのノードが SQL クエリのどの部分に該当するのかが確認可能となり、ボトルネックの特定が容易に
- GROUP BY 句の拡張機能

- GROUP BY STRUCT、ARRAY、ALL といった構文が利用可能に
- BigLake tables for Apache Iceberg in BigQuery

- Iceberg エクスペリエンスを選択可能に
- BigQuery アドバンストランタイム

- BigQuery クエリプロセッサに拡張ベクトル化が提供され、クエリのパフォーマンスが向上
- デフォルト設定の構成

- 設定画面から個人 / 構成設定を設定可能に
- BigQuery Tables の CMETA

- BigQuery テーブルと外部テーブルの両方で、メタデータをインデックスとして作成可能に
- 継続的クエリ

- SQL によって受信データのストリームに対して無制限のサーバレス分析を実行
- リアルタイムの分析を行う自動化パイプラインの開発
- BigQuery のデータをリアルタイムで変換し、Pub/Sub や DB、BigQuery や検証済みのパートナー統合に複製
- Data Transfer Service が MySQL と PostgreSQL に対応

- Data Transfer Service が CloudSQL やオンプレミス、AWS、Azure で稼働する MySQL および PostgreSQL に対応
- Spanner への Export

- Enterprise または Enterprise Plus 限定で BigQuery のデータを SQL で Spanner にExport 可能に
- 外部データセットに Spanner をサポート

- BigQuery の外部データセットに Spanner を指定可能に
- Dataplex automatic discovery

- Cloud Storage 上のデータをスキャンし、カタログ、BigLake テーブル、外部テーブル、オブジェクトテーブルを自動作成
- Pub/Sub メッセージに対する SMT 機能

- Pub/Sub への公開時および Pub/Sub からの受信時に軽量なデータ変換処理が可能に
- データ変換処理のために Cloud Run functions や Dataflow などの別サービスが不要に
- BigQuery sharing での Pub/Sub トピック共有
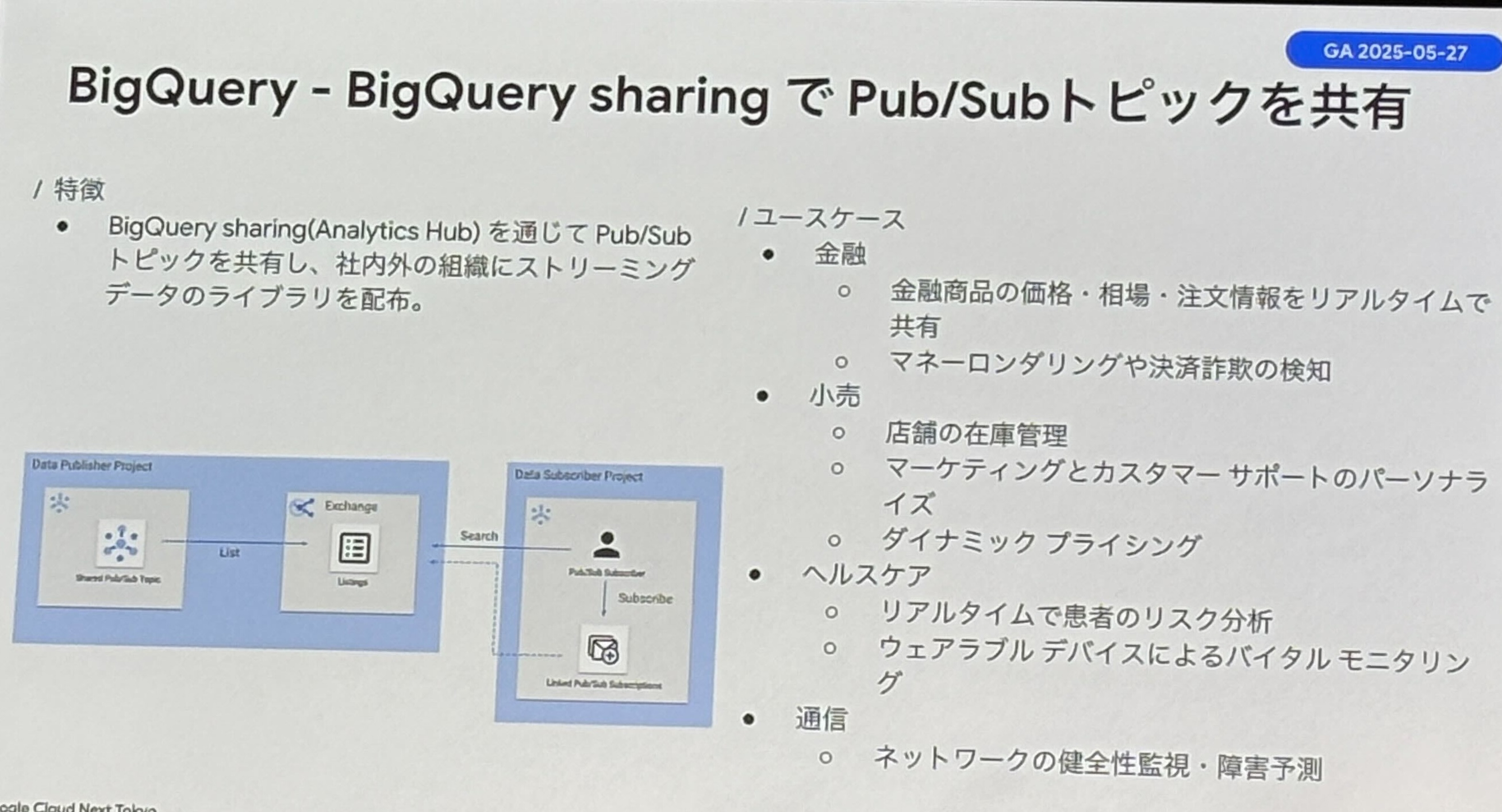
- BigQuery sharing で Pub/Sub トピックを共有し、社内外の組織にストリーミングでデータ配布が可能に
- Google Maps Places データ利用

- Google Maps が持つ豊富な POI を自社データと統合し、BigQuery で利用可能に
おわりに
本セッションでは、Google Cloud Next (米国開催) での BigQuery 関連の発表内容をご紹介いただきました。BigQuery 周りで様々なアップデートがありましたが、特に印象に残ったのは自然言語から SQL を生成し、分析が可能になる機能でした。その他、パイプラインの作成やデータの準備についてもサポート機能がでてきており、こういった機能によってデータ分析自体はより簡単になる一方、どういった分析を行うかを検討する部分の重要度が増してくると感じました。BigQuery はアップデートの多いサービスのため、今後の新機能にも注目していきたいと思いました。




