
AWS re:Invent にて行われたワークショップ「DAT405: Build a web-scale application with purpose-built databases & analytics」に参加しました!

ワークショップでは、以下のAWSサービスを組み合わせ、それぞれの強みを活かした実装を行いました。単一のデータベースですべてを処理するのではなく、ワークロードの特性に応じたデータストアを選択し実装することで、それぞれのデータベースの使いどころを学ぶことができます。
今回は、オンライン書店アプリケーションを題材に、各データベースを効果的に活用しながらコアとなる部分を修正していくワークショップでした。
Level: 400 – Expertのセッションだったのですが、部分的に触ったことがないサービスがあってもスムーズに進められるくらいの内容でした。(初めてのLv400セッションで身構えていたのですが、案外大丈夫でした!)

主な機能と使用したDBサービスをざっくり紹介します。
- 書籍のカタログデータや注文情報
- リレーショナルなデータ構造とトランザクション管理が必要な部分で、Amazon Aurora を使用
- 買い物かご(ショッピングカート)
- 高いスケーラビリティと低レイテンシが求められるキーバリューストアとして Amazon DynamoDB を利用
- ベストセラー表示
- 頻繁にアクセスされるデータのキャッシングを行い、読み取り負荷の軽減とアプリケーションの応答速度向上を実現するために Amazon ElastiCache を使用
- 「これを買った人はこの商品も買ってます」のおすすめ表示
- 複雑な関係性を扱うレコメンデーション機能の実装に Amazon Neptune を使用
- 本の全文検索
- 大量の商品データに対する全文検索機能を提供するために Amazon OpenSearch Service を使用
今回のデモアプリケーションの構成図はこちら。
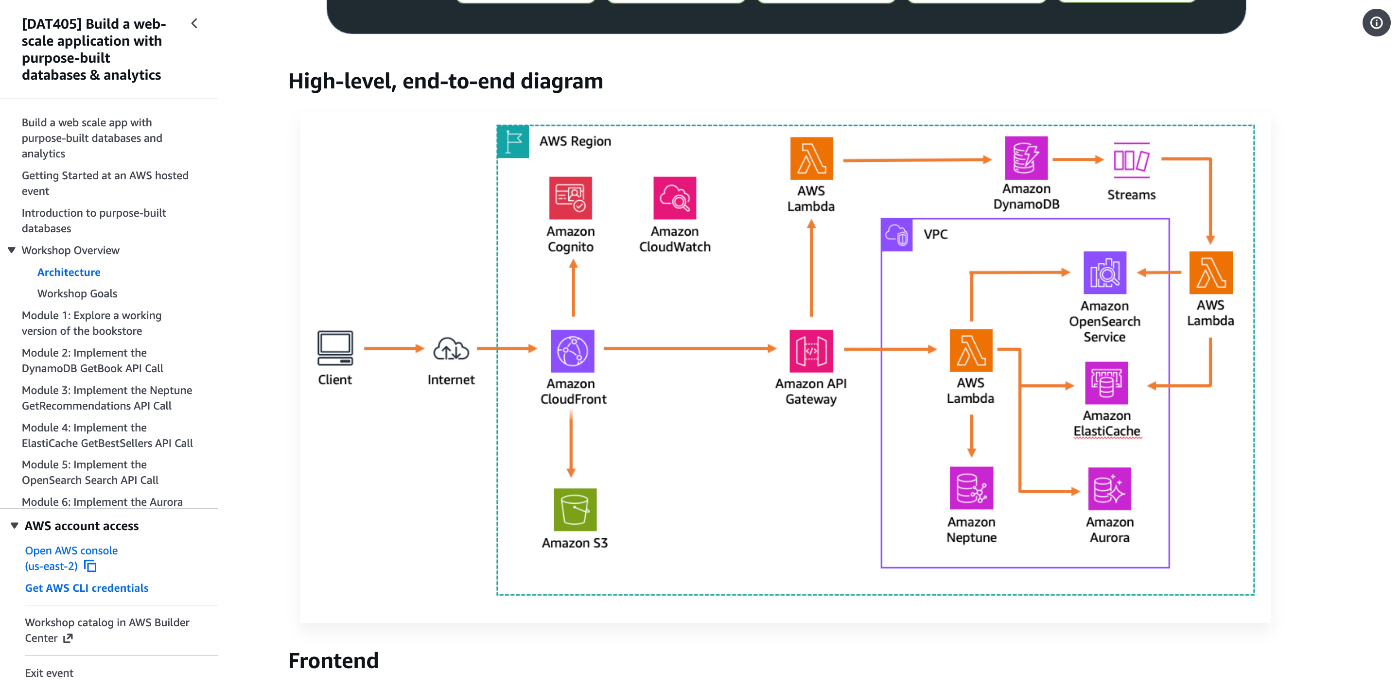
壊れたアプリケーションを修復しながら進める
このワークショップのユニークな点は、ゼロから構築するのではなく、「すでにデプロイされているが、機能が壊れているアプリケーション」を修復していく形式で進むことです。
最初にアクセスしたデモサイトには、画面上部に「This instance of the bookstore is broken(この書店インスタンスは壊れています)」という赤いバーが表示されていました。
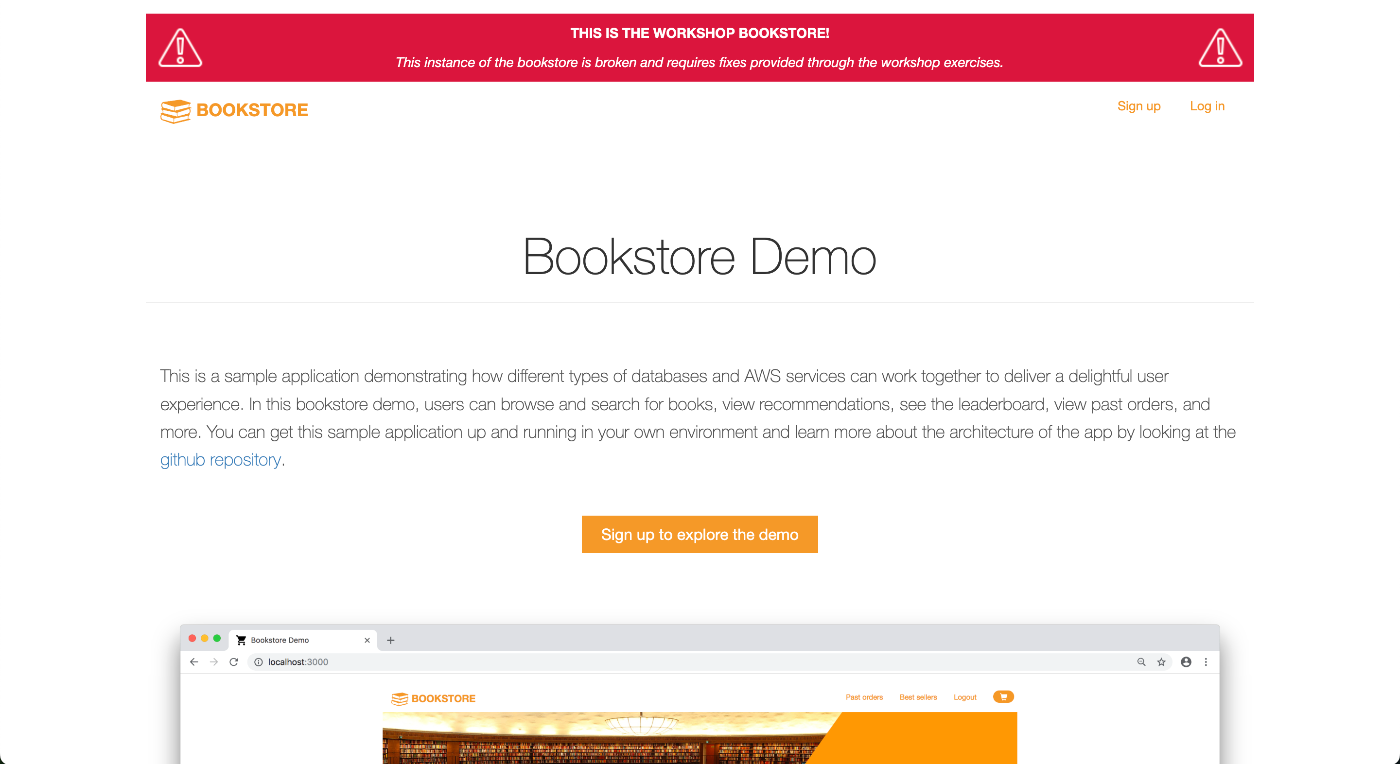
UIは表示されますが、データベースと接続するバックエンド処理(AWS Lambda)が未実装の状態です。そのため、書籍をクリックしても詳細情報が取得できず、ネットワークエラーが発生します。参加者は各モジュールを通じてコードを実装し、正常なECサイトへと作り上げていきます。
Amazon DynamoDB による書籍データの取得
最初のステップでは、Amazon DynamoDBの実装を行いました。 ここでは、特定の書籍情報を取得する GetBook APIのバックエンドを修正します。DynamoDBはキーバリューストアとして機能しており、書籍IDをキーにして高速にメタデータを取得する役割を担っています。

コードを修正しデプロイが完了すると、これまでエラーになっていた書籍詳細ページが正しく表示されるようになり、自分のコードが正しく動いていることを即座に実感できました。

Amazon Neptune によるレコメンデーションの仕組み
個人的に特に興味深かったのが、Amazon Neptuneを使用したレコメンデーション機能の実装です!
ワークショップ内の解説では、グラフ理論における「二部グラフ(Bipartite graph)」の概念が紹介されました。ユーザー(Customer)と書籍(Book)をノードとし、購入(Transaction)をエッジとして結ぶことで、関係性を可視化します。

「ある本を買ったユーザーが、他にどんな本を買っているか」という探索を、グラフデータベース特有のトラバーサル(横断)によって高速に行います。
SQLで同様のことを行おうとすると複雑な結合(JOIN)が必要になりパフォーマンスが懸念されますが、グラフデータベースを使うことで効率的に実現できる仕組みを学びました。

Amazon ElastiCache によるベストセラー機能の実装
ECサイトにおいて、アクセス頻度が非常に高いのがランキング(ベストセラー)の表示です。
トップページにアクセスするたびに、膨大な販売履歴データを持つデータベース(Aurora)に対して「売上の多い順に商品を並べ替えて取得する」という集計クエリを実行するのは、データベースへの負荷が高く、ページの表示速度も低下させる原因になります。
そこで Amazon ElastiCache を導入し、集計済みのベストセラー情報をキャッシュする実装の修正を行いました。
フロントエンドからの GetBestSellers API リクエストに対し、ElastiCache (Redis) にデータがあるかを確認し、キャッシュヒットすればそこから高速にデータを返すというロジックを実装します。
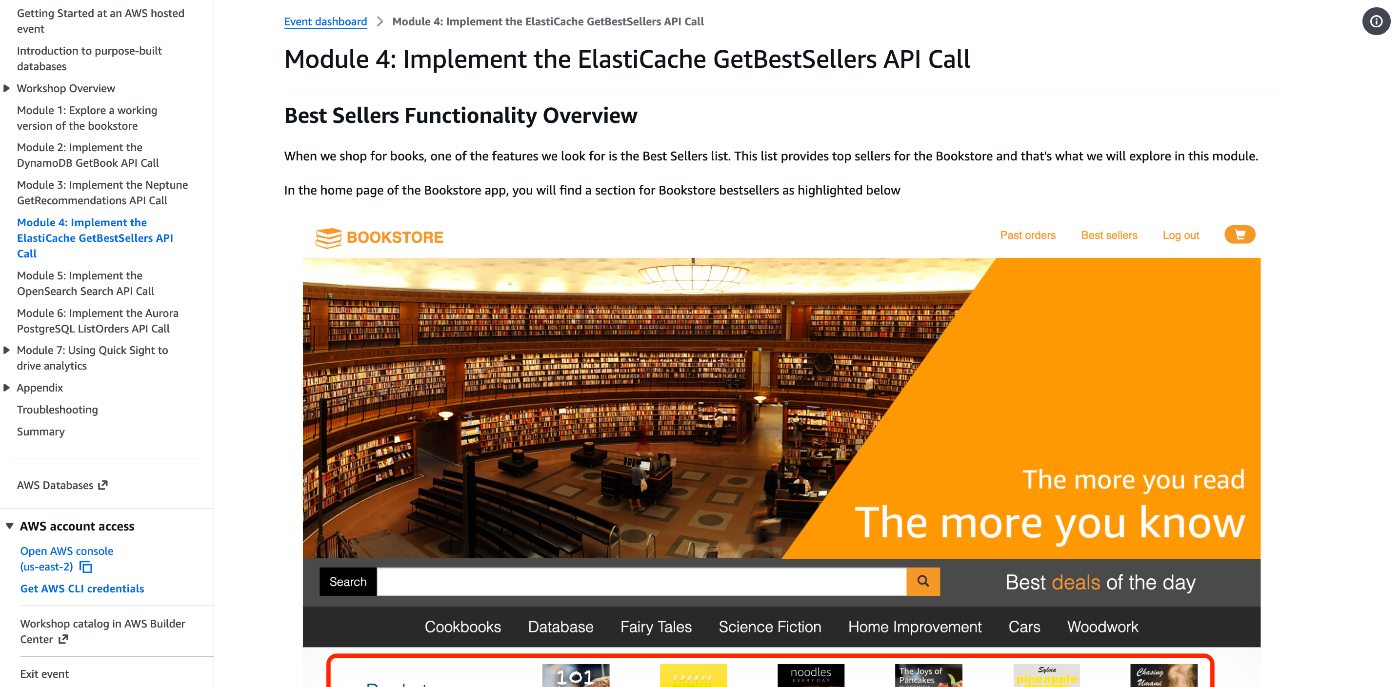
実装前はトップページの「Top 20 best sellers」部分が読み込み中のまま動かない状態でしたが、バックエンドのLambda関数を修正してデプロイすることで、瞬時にランキングが表示されるようになりました。また、商品が購入された際には Amazon DynamoDB Streams をトリガーとして AWS Lambda が実行され、ElastiCache 上のランキング情報が更新される仕組みも実装されていました。

データの可視化による分析
ワークショップの最後では、蓄積されたデータを利用して、Amazon QuickSightによるデータ分析と可視化も行いました。

データベースに保存された販売データなどにQuickSightから直接接続し、売上のグラフなどを簡単に作成することができました。アプリケーションの構築だけでなく、その後のデータ活用まで見据えた包括的な内容でした!
まとめ
「Purpose-built databases(目的別データベース)」という言葉の通り、要件に合わせて最適なデータベースを選択し、それらを適切に組み合わせることで、高性能でスケーラブルなアプリケーションが構築できることを実感したワークショップでした。
個人的には、Amazon Neptune を使うことが初めてだったので、こうやってクエリを書いて実行するのかと実装を通じてAPIの仕様などを掴めてとても面白かったです!
