
こんにちは、アジャイル事業部のみちのすけです。re:Invent 2025 に現地参加しています!
この記事は re:Invent 「Make agents remember with Amazon Bedrock AgentCore Memory (AIM331)」のセッションレポートです。
Amazon の Principal Solutions Architect である Mrudhula Balasubramanyan さん、Sr Manager の Madhu Bussa さん、そして Experian の Senior VP である Imran Shah さんが、エージェントAIにおけるメモリの重要性と Amazon Bedrock AgentCore Memory の活用について紹介されました。
概要
セッションでは、エージェントAIアプリケーションにおけるメモリの役割と、Amazon Bedrock AgentCore Memory を使った実装方法が語られました。特に印象的だったのは、プレゼンテーション作成エージェントのデモ、Experian の実際の導入事例、そして 短期メモリと長期メモリを組み合わせた仕組み という具体的な内容です。
こんな方におすすめ
- エージェントAI アプリケーションを開発している方
- ユーザーの好みや過去の会話を記憶する機能を実装したい方
- カスタマーサポートやコーディングアシスタントなど、継続的な対話が必要なシステムを構築している方
- Amazon Bedrock を使ったAI開発に興味がある方
登壇者
- Mrudhula Balasubramanyan さん(Principal Generative AI Specialist Solutions Architect, Amazon Web Services)
- Madhu Bussa さん(Sr Manager, Solutions Architecture, Amazon Web Services)※セッション中では Jay という名前で紹介
- Imran Shah さん(Senior VP, Head of Engineering, Experian)
なぜエージェントにメモリが必要なのか
セッションの冒頭、Mrudhula さん(Mani さん)は会場の参加者に質問をされました。「エージェントAIにおけるメモリの概念を知っている方は?」という問いに、多くの手が挙がりました。
エージェントを構築する際、コンテキストウィンドウには多くの要素が含まれます。システムプロンプト、ドキュメント(RAGやナレッジベース)、ツール(アクションや機能)、インストラクション(タスクのガイドライン)、そして現在の会話履歴などです。
しかし、メモリ(Memory)は見落とされがち とのことでした。
Mani さんは、パーティーでの会話に例えて説明されました。何人かの人と話をした後、「あなたの名前は何でしたっけ?」と聞くような状況は避けたいですよね。エージェントも同じで、ユーザーと対話する際に過去のやり取りやユーザーの好みを忘れてしまうと、良いユーザー体験を提供できません。
正確で関連性のある回答を返すことはもちろん重要ですが、メモリがあることで、学習と個別化(personalization)が可能になる というのが重要なポイントです。

実例:プレゼンテーション作成エージェント
Mani さんは、このセッション自体のスライドを作る際に使ったエージェントを例に挙げて説明されました。
最初は メモリなしの基本的なエージェント を作成したとのことです。これは問題なく動作し、詳細なプロンプトとツール(Python PPTX ライブラリなど)を提供すれば、スライドデッキを生成できました。
ただし、毎回以下のような指示を繰り返す必要がありました:
- 技術プレゼンテーションには、この特定のスタイルを使用してください
- 責任あるAIの利用について触れてください(Mani さんはAIと責任あるAIに特に関心があるとのことです)
- などなど
これらは個人的な好みですが、メモリなしのエージェントでは 毎回同じ指示を繰り返す必要がある わけです。
そこで、Mani さんは メモリ付きエージェント を作成しました。このエージェントは、多くのスライドデッキを作成する中でMani さんの好みを学習し、ある程度時間が経つと、「このトピックについて技術プレゼンテーションを作って」と言うだけで、自動的に好みに沿ったスライドを生成できるようになったとのことです。
これは実際にセッションの最後にデモがあり、かなり説得力がありました。

メモリがなければ賢くなれない
エージェントに求められるのは、単に記憶することだけではありません。賢くあること も重要です。
エージェントが賢くあるためには、以下を保持・思い出す必要があります:
- ユーザーの好み:どんなスタイルを好むか、どんな要素を含めたいか
- 事実情報:過去のやり取りで明らかになった情報
- 前回セッションの要約:長い会話を要約して保持
例えば、エージェントと長い会話をして、後日戻ってきたとき、その会話を再開したい というのは非常に一般的なユースケースです。
しかし、会話履歴全体を保存すると、すぐに巨大になりすぎてしまいます。そこで、要約が重要になります。ユーザーが戻ってきたときに、「前回は〇〇について話しましたね。そのトピックを続けますか、それとも新しいトピックを始めますか?」とエージェントが聞けると良いですよね。
つまり、エージェントには 記憶するだけでなく、適切にリコール(思い出す)できる賢さ が求められるという話でした。
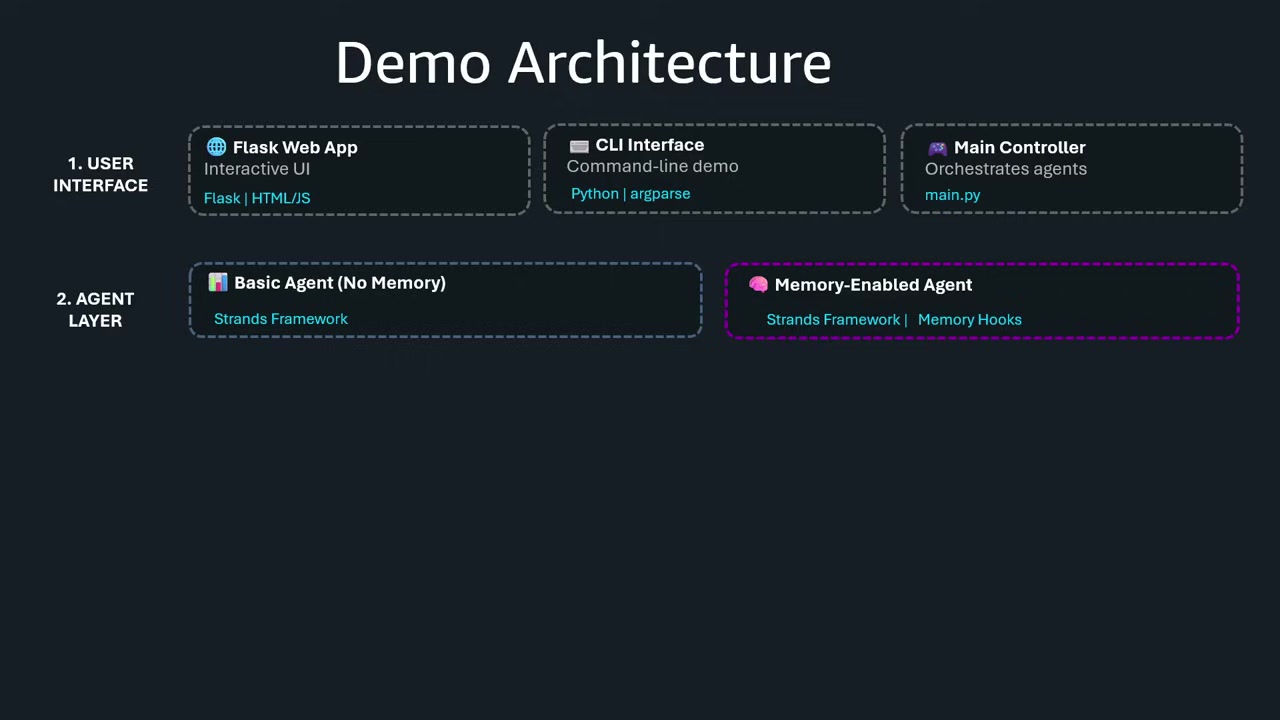
デモアーキテクチャの概要
Mani さんが構築したデモアプリケーションのアーキテクチャは以下のとおりです:
UI とフレームワーク
- ユーザーインターフェースは魅力的で使いやすいものに
- エージェントフレームワークとして LangGraph (Strands framework) を使用
- 2つのエージェント(メモリなし vs メモリあり)を並行して実行し、比較できる仕組み
メモリフック
エージェントフレームワーク内でメモリを統合する方法として、メモリをツールとして使う 方法と メモリをフックとして使う 方法があります。
Mani さんは メモリフック を使用しました。理由は、エージェントのライフサイクルの特定のタイミングでメモリを確実に呼び出せるからです。
例えば:
- メッセージが追加されるたびに、短期メモリに追加
- 必要なときにエージェントが長期メモリをツールとして呼び出す
メモリフックを使うことで、決定論的(deterministic) にメモリを管理できます。つまり、すべてのメッセージが確実に短期メモリに保存されるわけです。
使用したAWSサービス
- Amazon Bedrock:基盤となるLLMサービス
- Anthropic Claude 4.5 Sonnet:使用モデル
- AgentCore Memory:短期・長期メモリの管理
- IAM 権限統合:セキュリティとアクセス制御(最小権限の原則に基づく)
Mani さんは、セキュリティが非常に重要であること、そしてIAM権限を適切に設定することで、エージェントが必要な権限だけを持つようにし、ブラストラジアス(影響範囲)を最小化 できると強調されました。
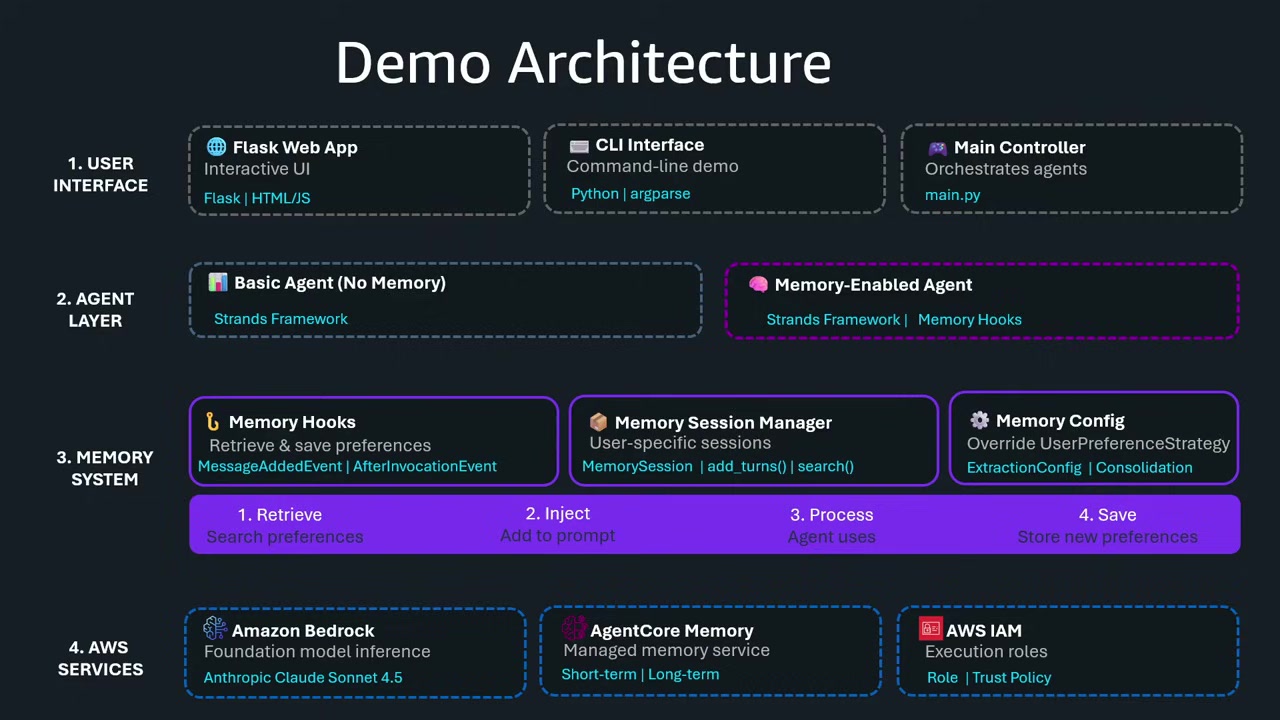
メモリシステムを自分で構築すると…?
では、もしメモリシステムを自分で一から構築するとしたら、どれだけの作業が必要でしょうか?
Mani さんは、エージェントの構築やデプロイは置いておいて、メモリシステムだけ を構築することを想像してほしいと言われました。
短期メモリに必要なもの
- 生のメッセージをそのまま保存できるストレージ
- 直近のK回のやり取りをエージェントに渡せる仕組み
- キーバリューシステムやデータベースが必要
長期メモリに必要なもの
- 複数セッションにわたってユーザーの好みを記憶
- クエリに基づいてセマンティック(意味ベース) に情報を取得
- ベクトルストアが必要
さらに必要な機能
- メモリの自動リフレッシュ:データが常に最新であること
- 重複の統合:例えば、「私はベジタリアンです」と「私はノンベジタリアンです」の両方が記録されていると、エージェントが混乱してしまいます。最新の情報(ノンベジタリアン)に統合する必要があります。
- セキュアな実装:すべてを安全に管理
- オブザーバビリティ:トラブルシューティングやデバッグのために、ログや監視を統合
これら全てを自分で構築するのは、非常に大きな労力 になります。
そこで、Amazon Bedrock AgentCore Memory の出番です。これらの重たい作業(heavy lifting)を AWS が引き受けることで、開発者は 顧客のためのアプリケーション構築 に集中できるようになります。
Amazon Bedrock AgentCore Memory の仕組み
ここからは、Jay さん(Madhu Bussa さん)がプロダクトマネージャーとして、AgentCore Memory の詳細について説明されました。
思考実験:人間の記憶
Jay さんは、まず思考実験を提案されました。
- 先週の会話を思い出してください。おそらくかなりよく覚えていると思います。一言一句覚えているかもしれません。
- では、1年前の会話を思い出してください。例えば、去年の re:Invent での会話やプレゼンテーション。覚えていますか?
1年前の会話については、細かいことは覚えていないかもしれませんが、最も重要な詳細や大まかな内容 は脳が覚えていて、それが今後の会話や行動に影響を与えますよね。
AgentCore Memory も人間の脳と同じように設計されている とのことです。

メモリリソースの構造
AgentCore Memory は、AWS アカウント内に Memory Resource(メモリリソース) をセットアップします。このリソースは以下の2つを含みます:
短期メモリ(Short-term Memory)
- 生の対話履歴:一言一句そのまま
- 保持期間:7日間から最大1年間(設定可能)
- 最近の会話を思い出す際に使用
長期メモリ(Long-term Memory)
- 重要な情報やキーインサイト:時間が経っても保持
- 永続的:期限なし
- エージェントが必要に応じて取得可能
エージェントは、タスクを完了するために、短期メモリと長期メモリの両方 を取得できます。

短期メモリの詳細
短期メモリでは、エージェントとのやり取りが Events(イベント) という形でメモリリソースに送信されます。
イベントの構成要素
- actorId:誰なのか(ユーザーID + エージェントID の組み合わせなど)
- sessionId:特定のやり取り(セッション)を識別
- イベント本体:会話履歴、メタデータ、画像や音声などのブロブペイロード
actorId と sessionId を使って、コンテキストトラッキング が簡単にできます。
短期メモリの主な用途
直近の会話履歴でエージェントを補完(hydrate)すること。これが基本です。
Jay さんの言葉を借りると、「誰も自分のエージェントが金魚のようになってほしくない」とのことです。短期メモリがあれば、これを防げます。

実例:ゴールデンレトリーバーの子犬
Jay さんは、自分の家族にゴールデンレトリーバーの子犬を飼うよう説得しようとしている(今のところ失敗中)という個人的なストーリーを共有されました。
新しいアプローチとして、PowerPoint ビルダーエージェント を使って、家族を説得するためのプレゼンを作ろうと考えたとのことです。
プレゼンには以下を含める予定:
- たくさんのかわいい写真
- 犬を飼うことの利点(責任感が身につく、犬を飼っている人は統計的に幸せ、など)
- 財務分析(コストの懸念に対処)
Jay さんは、エージェントと何度もやり取りをして、かなりの労力をかけました。しかし、最も困るのは、画面が突然真っ白になること。例えば、誤ってアプリを終了してしまった場合、元の場所に戻るのは非常に大変です。
AgentCore Memory を使えば、会話履歴だけでなく、インタラクション状態も保存できます。 つまり、中断した正確な地点に戻れるわけです。
Jay さんは、「来年の re:Invent では子犬を連れてきます!」とジョークを言われました。会場は笑いに包まれました。

ブランチング機能
AgentCore Memory は、短期メモリの高度な機能として ブランチング(Branching) をサポートしています。
ブランチングは以下のような場合に便利です:
- メッセージの編集:過去のメッセージを編集して、そこから別の会話を展開
- 並行イベントストリーム:例えば、ゴールデンレトリーバーの子犬、シベリアンハスキーの子犬、ジャーマンシェパードの子犬(これは Jay さんは疑問符をつけていましたが笑)の3つのプレゼンを同時に作成し、論理的に分離して管理
ブランチングを使えば、複数の方向性を試しながらも、それぞれを別々に管理できます。
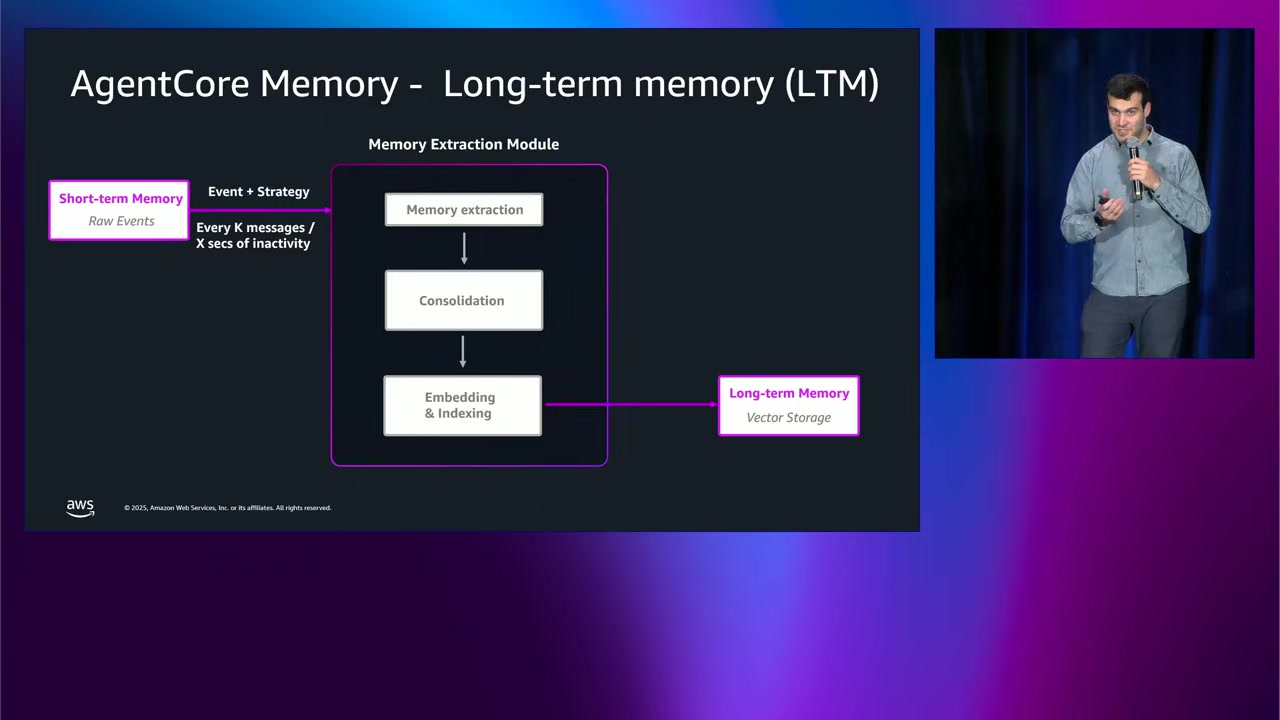
長期メモリの詳細
長期メモリでは、短期メモリからの生のやり取りが、自動的に構造化された永続的なインサイトに変換されます。
短期メモリが会話履歴をそのまま保持するのに対し、長期メモリは 長期的に必要なキーインサイトのみ を抽出します。
長期メモリへの変換プロセス
長期メモリへの書き込みは、複数ステップのプロセス です:
- Memory extraction(メモリ抽出):短期メモリから重要な情報を抽出
- Consolidation(統合):重複や矛盾する情報を統合
- Embedding & Indexing(埋め込みとインデックス化):ベクトルストレージに保存
このプロセスには LLM(大規模言語モデル)を使用 しています。
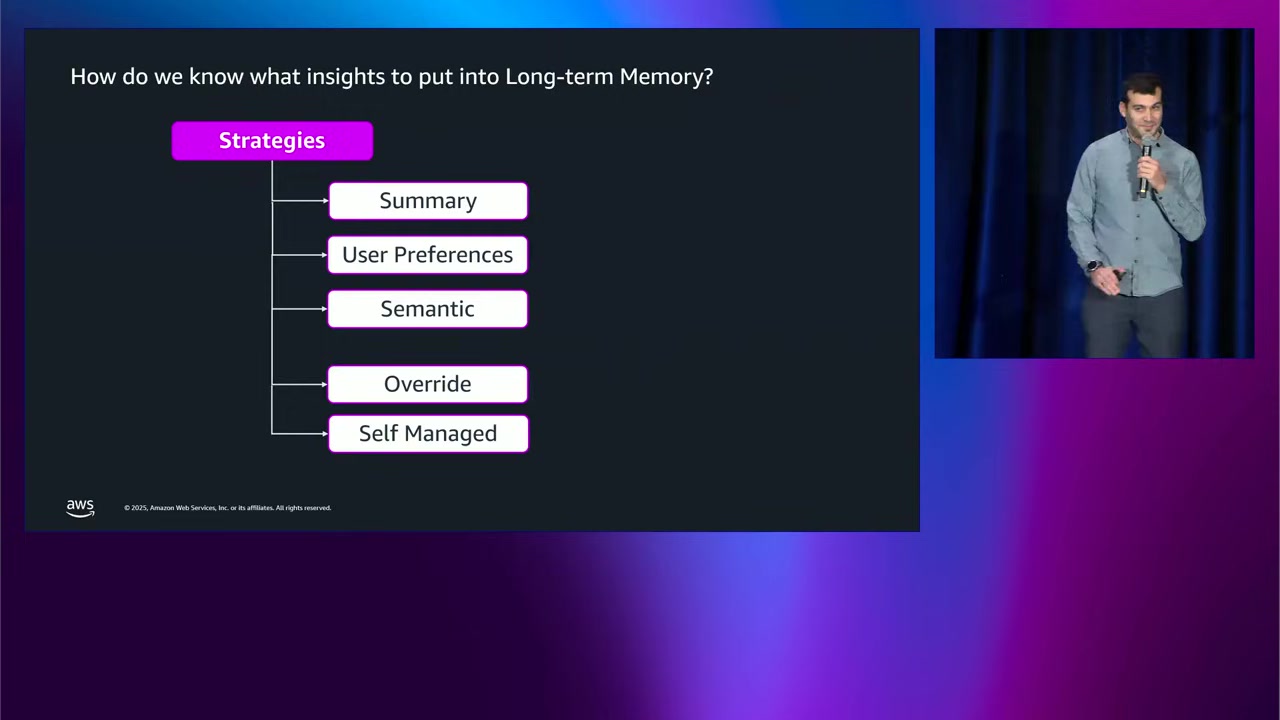
メモリストラテジー(Memory Strategy)
どの情報を長期メモリに保存するかは、メモリストラテジー を選択することで決まります。
AgentCore Memory には、3つの組み込みストラテジー があります:
1. Summary(要約)
- やり取りや会話を要約して保存
2. User Preferences(ユーザーの好み)
- ユーザーの好みを記録
- 例:「ユーザーはゴールデンレトリーバーとシベリアンハスキーを、ジャーマンシェパードよりも好む」
3. Semantic(セマンティック)
- やり取りに関する事実を記録
- 例:「ユーザーには家族がいて、家族は犬を飼いたがっている(願わくば)」
これらのストラテジーは、AWS コンソールまたは API 経由で簡単に追加 できます。ストラテジーを選択して追加するだけで、自動的に短期メモリから長期メモリへ情報が流れ始めます。とても簡単とのことです。
さらに細かい制御が必要な場合
組み込みストラテジーだけでは不十分な場合、以下の2つのストラテジーがあります:
4. Override(オーバーライド)
- 使用する LLM を選択可能
- 長期メモリに送信する際のプロンプトをカスタマイズ可能
5. Self-managed(自己管理)
- 抽出プロセスを完全に制御
- イベントが S3 バケットに配信され、通知を受け取る
- 独自の処理を経て、専用 API を使って長期メモリにメモリレコードを書き込む
すべてのストラテジーで作成されたメモリレコードは、セマンティック検索(クエリベースの検索) で取得可能です。
また、複数のストラテジーを組み合わせる こともできます。例えば、Summary と Semantic を組み合わせるのは理にかなっていると思います。最初は組み込みストラテジーから始めて、後で Override や Self-managed に移行するのが良いアプローチとのことでした。
メモリシステム全体の流れ
すべてをまとめると、以下のようになります:
- 左側(入力):ユーザーとエージェントのやり取りが、短期メモリに Events(イベント) として送信
- 中央(処理):設定されたストラテジーに基づいて、イベントが長期メモリに Memory Records(メモリレコード) として送信
- 右側(取得):短期メモリ(Events)と長期メモリ(Memory Records)の両方から、エージェントが情報を取得してタスクを完了
また、複数のエージェントが同じメモリリソースに読み書き可能 です。つまり、マルチエージェントのユースケースもサポートされています。
AgentCore Memory は、フルマネージドサービス であり、組み込みのオブザーバビリティとエンタープライズグレードのセキュリティ機能を備えているとのことです。

Experian の導入事例
ここからは、Imran Shah さん(Experian の Senior VP, Head of Engineering)が、Experian における AgentCore Memory の導入事例について語られました。
Experian について
Experian は、世界的な信用情報機関(クレジットビューロー)です。主な特徴:
- 15億人以上の消費者 のクレジットデータ
- 2億100万以上のビジネス にサービスを提供
- 99.9% の精度 でデータを配信
- 2億人以上のメンバー を支援
- FY25 売上高 75億ドル の市場リーダー
- 32カ国、25,000人の従業員
- 金融、ヘルスケア、自動車、通信、小売など、幅広い業界にサービスを提供
これだけの規模の企業が、AgentCore Memory を採用しているというのは、かなり説得力がありますね。

Experian の AgentCore Memory 導入前の状況
Experian は、当初 プロダクト固有の短期メモリ実装 を行っていました。
しかし、すぐに「これでは上手くいかない」と気づいたとのことです。
導入前のメモリ実装
Experian には2種類のメモリ実装がありました:
- マネージドメモリ:OpenAI Assistants などを使用し、スレッドレベルのメモリを提供
- カスタムメモリ:オープンソースフレームワークを活用し、スレッドレベルのメモリを提供
この2つが 共存 しており、チーム間でユーザーの混乱や不満が生じていました。
短期メモリの限界
短期メモリは機能しますが、エンタープライズスケールには対応できない とのことです。
たとえ従業員500人や顧客200人の小規模な企業でも、短期メモリには以下の課題があります:
- 継続性と永続性:長い会話履歴を保持するのが困難
- パフォーマンスとコスト:すべての組織にとって非常に重要
- クロスプロダクトリコール:製品やスレッドをまたいだメモリのリコールができず、ユーザーフラストレーションが発生
- コンプライアンスと規制:2年前のデータを遡って保持要件を満たすのが困難
これらの理由から、Experian はユニファイドメモリ(統合メモリ)アーキテクチャへの移行を決めました。
コンテキストオーケストレーション
Imran さんは、2つのコンテキストプレーン について説明されました。
権威的コンテキスト(Authoritative Context)
- ナレッジベース
- API
- データベース
- 組織のナレッジエコシステム
会話的コンテキスト(Conversational Context)
- 短期メモリ
- 長期メモリ
- エージェントステート
この2つのコンテキストプレーンを コンテキストワークフローに統合 することで、エンタープライズスケールで非常にインパクトのあるシステムが構築できます。
- LLM のプロンプティングがより効率的になる
- ユーザーペルソナからユーザーコンテキストを取得できる

AgentCore Memory 導入前の計画アーキテクチャ
Experian は、AgentCore Memory を知る前、自社でユニファイドメモリを構築する計画 を立てていました。
典型的な「ビルド」シナリオで、以下のコンポーネントが必要でした:
- Conversation Manager:会話を保存・取得
- Memory Manager:メモリレコードを保存・取得
- Memory Store / Vector DB Store:ベクトルデータベース
- ETL Pipeline:定期的にデータを供給
このモデルには、複数のカスタムコンポーネントを管理する運用上の複雑さ がありました。
AgentCore Memory 導入後のアーキテクチャ
AgentCore Memory を導入した後のアーキテクチャは、大幅に簡素化されました。
- フルマネージドの会話ストア
- フルマネージドの会話 API
- ETL オーバーヘッド ゼロ:メモリ抽出が自動化
これにより、以下のメリットが得られました:
- Faster time to value(価値提供までの時間短縮)
- Improved operational efficiency(運用効率の向上)
- Increased functionality(機能の増加)
このシナリオでは、エンジニアはエージェントの構築に集中でき、インフラについて心配する必要がない という点が強調されました。

Experian のコア設計原則
Experian が AgentCore Memory を活用する際の4つの柱:
1. Evaluation and test frameworks(評価とテストフレームワーク)
- メモリ抽出プロセスを継続的に評価
2. Cross-agent memory interoperability(クロスエージェントメモリ相互運用性)
- エージェント間でメモリを共有
- エージェント同士がオーケストレーションし、コンテキストを持った情報提供が可能
3. Shorter targeted context windows(短い目的特化型コンテキストウィンドウ)
- 簡潔で目的に沿ったコンテキスト
4. Namespace-based isolation(名前空間ベースの分離)
- マルチテナントアーキテクチャを実現
- 同じマスター共有アーキテクチャで複数のテナントにサービスを提供
これらの原則は、設計によって満たされているだけでなく、日常的に維持されているとのことです。

プライバシー、透明性、制御のための設計
Experian は、Memory Governance Service(メモリガバナンスサービス) を設計しました。
これは、長期AIメモリを管理するための統一された方法です。
主な機能
- ユーザー:自分のメモリを選択的に削除可能
- 管理者:必要に応じて定期的にパージする能力
つまり、ユーザーと管理者の両方にコントロールが委ねられています。
このアプローチにより、以下が実現されます:
- 優れたユーザー体験
- 信頼
- コンプライアンス:GDPR や CCPA などのガイドラインを確実に遵守
Imran さんは、Experian の中心には「セキュリティ、コンプライアンス、ユーザー体験」があり、AgentCore Memory アーキテクチャがこれらすべてを実現してくれていると語られていました。
また、Tiger Analytics と AWS チームがこの実装を支援してくれたことにも感謝を述べられていました。
ライブデモ:メモリありなしの比較
Imran さんのプレゼンテーションの後、再び Mani さんが戻ってきて、約束通りライブデモを実施されました。
デモの構成
- 基本エージェント(メモリなし)
- メモリ付きエージェント
- 比較機能:2つのエージェントに同じプロンプトを同時に送信
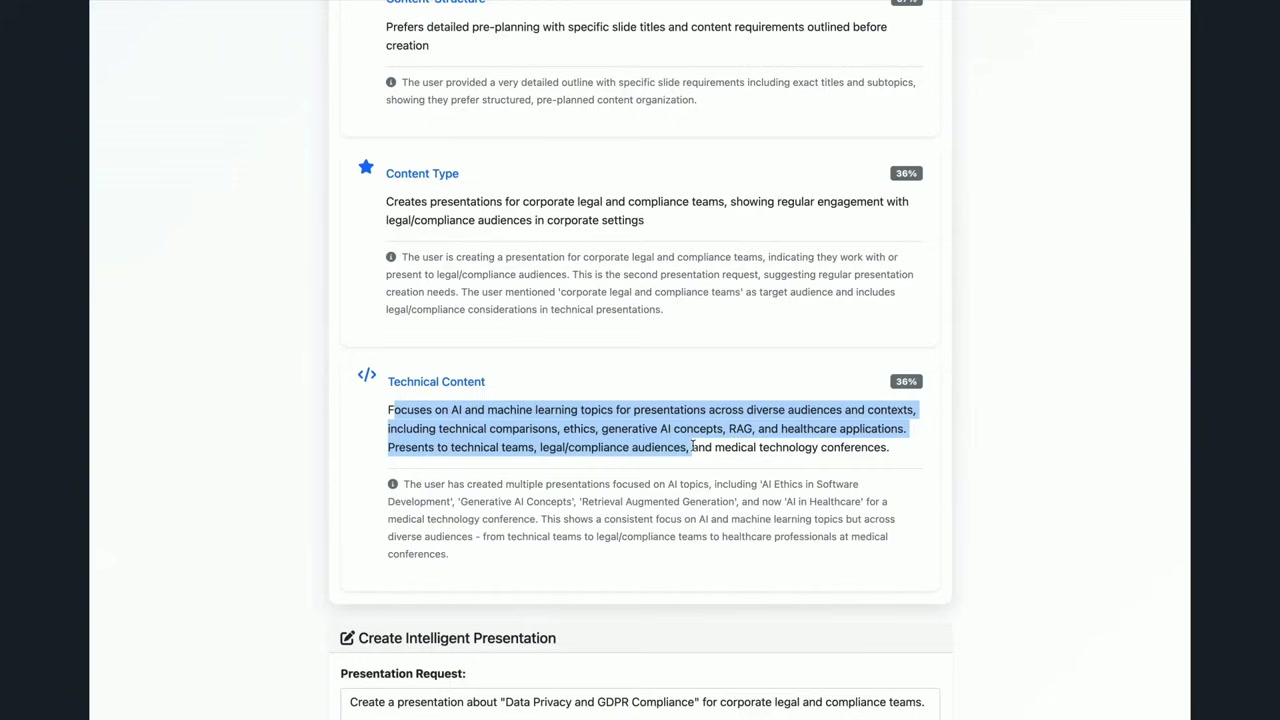
Mani さんは、既にこのエージェントを使っていくつかのスライドを作成しており、メモリ付きエージェントは Mani さんの好みを学習しているはずとのことです。
メモリ付きエージェントが記憶していること
デモ画面には、メモリ付きエージェントが記憶している Mani さんの好みが表示されていました:
- 技術プレゼンテーションには紫色のテーマ
- 技術フォント(コーディングIDEで使われるようなフォント)
- 実世界のユースケースを含める
- AI倫理を含める
- AI への執着:Mani さんはAIプレゼンテーションを作るのが好き(笑)
Mani さんは、「私のエージェントは私のことをよく知っている」と笑いながら言われました。
同じプロンプトを両方のエージェントに送信
Mani さんは、スタイルの好みを一切含まない、シンプルなプロンプトを両方のエージェントに送信しました。
バックグラウンドで何が起こっているかも表示されました:
基本エージェント
- プロンプトをそのまま受け取り、デフォルトの青いテーマでプレゼンテーションを生成
メモリ付きエージェント
- プロンプトを受け取る
- 長期メモリを検索:トピックに関連する好みを取得
- 再度検索:スタイリングに関連する好みを取得
- 取得した好みを適用してプレゼンテーションを生成
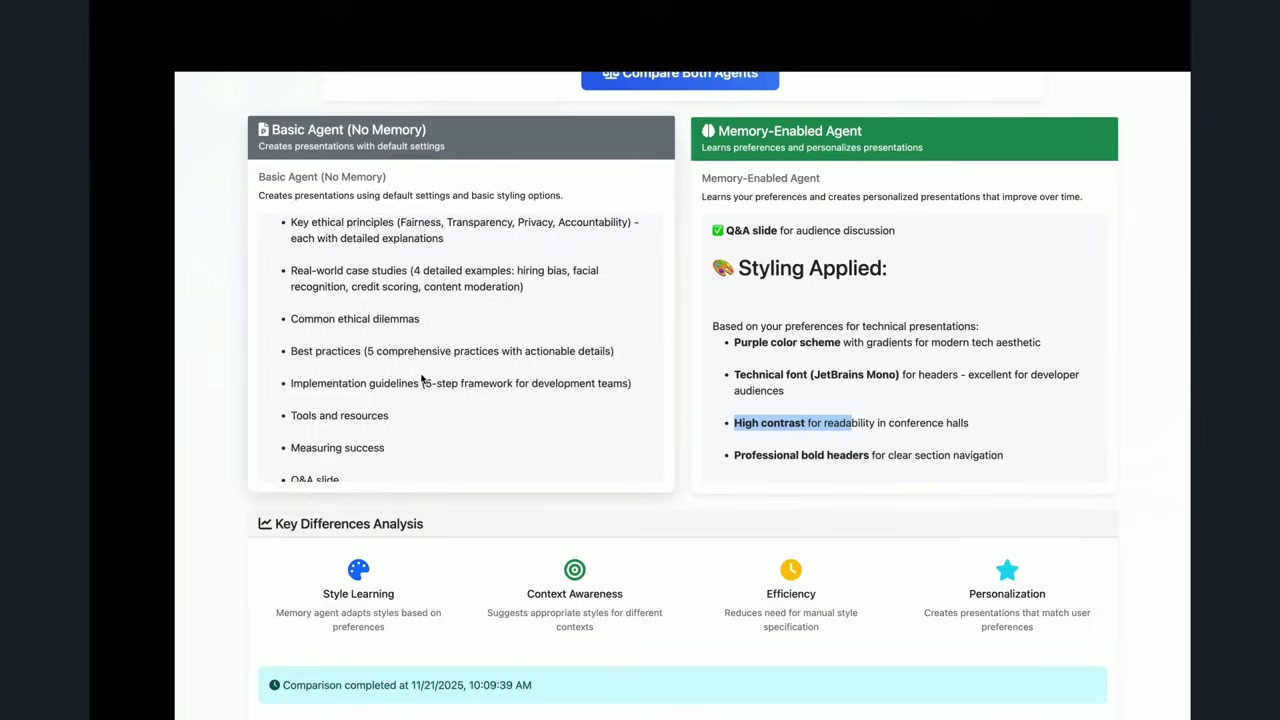
デモ結果
生成されたプレゼンテーションを比較すると、違いは一目瞭然でした。
基本エージェント
- 青いテーマ(デフォルト)
- スタイリング好みなし
- それでも良い仕事をしている
メモリ付きエージェント
- 紫色のテーマ(Mani さんの好み)
- 技術フォント(コーディングIDEで使われるフォント)
- AI倫理に関するスライドが含まれている
- コンテンツにも好みが反映されている(Mani さんが好むトピックが含まれている)
Mani さんは、「このデモは GitHub リポジトリで公開されています。agent core samples GitHub で検索すると、memory の下に完全なデモコードがあります」と紹介されました。
実際にデモを見ると、メモリの効果が本当によく分かりました。
メモリが重要なユースケース
セッションの後半では、メモリが重要となるユースケースが紹介されました。
1. コンテンツ作成
- Mani さんのプレゼンテーション作成エージェントのように、ユーザーの好みを学習してコンテンツを生成
2. コーディングアシスタント
Mani さんは、会場の参加者に質問をされました。「コーディングアシスタント(GitHub Copilot など)を使っている方は?」
多くの手が挙がりました。そして、「こんな経験ありませんか?」と続けられました:
- コーディングアシスタントにコードを生成させる
- コードを実行すると問題が発生
- 追加の指示を出す
- 毎回、「最小限のコード行数で変更してください。不要なファイルは作成しないでください」と指示する必要がある
Mani さんは、「エージェントは、修正を依頼すると、たくさんのテストファイルを作成しがちですよね」と言われました。会場では多くの人がうなずきました。
もしコーディングアシスタントにメモリがあれば、毎回同じ指示を入力する必要がなくなります。「このファイルを編集して」と言うだけで済みます。
また、メモリがあれば:
- ユーザーが Python を好む ことを記憶し、Java でコードを生成しない
- ユーザーのスタイルや好み を記憶
これにより、パーソナライズされた、より良い体験 が提供できます。
3. カスタマーサポートエージェント
カスタマーサポートの例も挙げられていました。
例えば、eコマースサイトでの問い合わせ:
- 返金について
- 商品の交換について
- 配達が遅れたことへの苦情
カスタマーサポートエージェントにメモリがあれば:
過去の問題を記憶
- 同じ顧客が同じ問題を繰り返している かどうか確認
- 何かを更新すべきかどうかの判断材料になる
- エージェント(人間)が「前回もこの方法で解決しました。同じ方法を試しましょう」とすぐに提案できる
顧客への配慮
- メモリがあることで、顧客を大切にしている ことが示される
- 正確で信頼できるヘルプを提供するだけでなく、顧客を覚えている ことが重要
Mani さんは、「次回エージェントAIアプリケーションを構築する際は、精度や関連性だけでなく、顧客体験 についても考えてください。また、エージェントが行う呼び出しの数を最小化することで、コストも削減 できます」と強調されました。
4. 教育アシスタント
- 学生の学習進捗を記憶
- 過去の質問や理解度に基づいて、パーソナライズされた学習体験を提供
5. ヘルスケアアシスタント
- 患者の症状履歴や治療経過を記憶
- 継続的なケアをサポート
6. 旅行プランニングアシスタント
- ユーザーの旅行の好み(ホテルのグレード、食事の好みなど)を記憶
- 次回の旅行計画をより簡単に
Mani さんは、スライドに6つのユースケースを挙げましたが、「これ以外にももっとたくさんのユースケースがある」と言われました。
正直、メモリが役立つシーンは本当に多いと思います。

ネクストステップ
セッションの最後、Mani さんは「今日のプレゼンテーションは終わりではなく、始まり です」と語られていました。
re:Invent 2025 では、Dr. Swami による keynote で、AgentCore 製品ラインの新機能が発表されるとのことです。
また、Mani さんは参加者に以下を呼びかけられていました:
- 何かユースケースを構築してみてください
- LinkedIn でつながるか、メールを送ってください
- アカウントチームに連絡して、Mani さんや Jay さんとつながってください
Mani さんは、「皆さんのストーリーを聞けるのを楽しみにしています。皆さんが次に何を構築するのか、知りたいです」と締めくくられていました。
まとめ
このセッションでは、エージェントAIにおけるメモリの重要性と、Amazon Bedrock AgentCore Memory を使った実装方法が紹介されました。
主要なポイント
- エージェントにはメモリが不可欠:学習と個別化を可能にする
- 短期メモリと長期メモリの組み合わせ:人間の脳と同じように設計
- フルマネージドサービス:開発者はアプリケーション構築に集中できる
- 複数のストラテジー:Summary、User Preferences、Semantic、Override、Self-managed
- Experian の導入事例:エンタープライズスケールでの成功例
- 実際のデモ:メモリありなしの違いが明確に
個人的には、Mani さんのライブデモが非常に説得力があったと思います。メモリなしのエージェントとメモリ付きのエージェントを並べて比較することで、メモリの価値が一目で分かりました。
また、Experian のような大規模企業が実際に導入し、アーキテクチャを大幅に簡素化できたという事例も、非常に参考になると思います。
今後、エージェントAIアプリケーションを開発する際は、メモリをどう設計するかが重要なポイントになりそうですね。Amazon Bedrock AgentCore Memory は、その重たい作業を肩代わりしてくれる強力なツールだと感じました。


