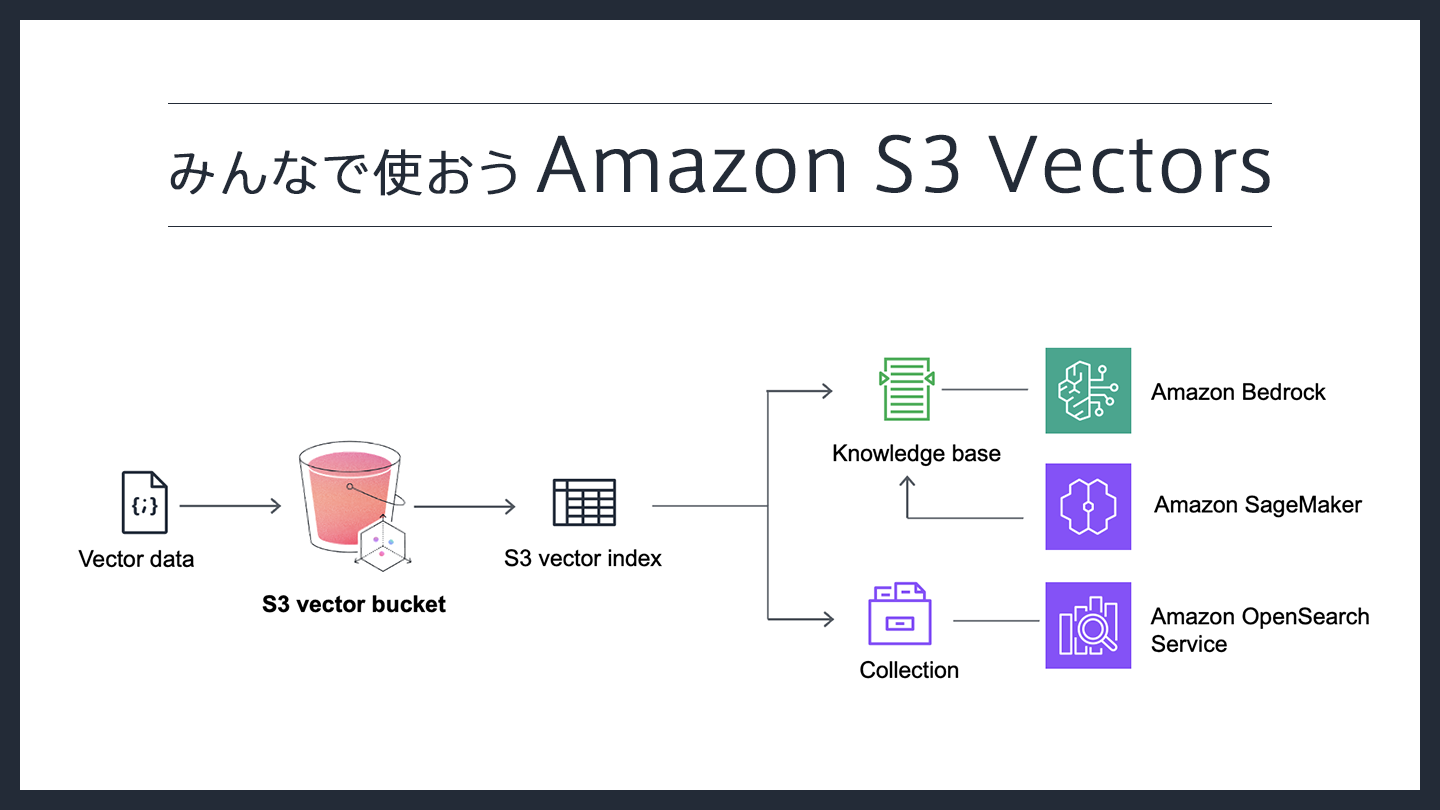
はじめに
みなさん、新しく GA になった Amazon S3 Vectors をご存知でしょうか?
これは、これまでありそうでなかった
「ファイルのテキスト解析を行い、Amazon Bedrock などからナレッジベースとして検索可能にするサービス」です。
これにより、ベクトル検索のためだけに PostgreSQL などのデータベースを立ち上げる必要がなくなり、
S3 ベースであることから コストを大幅に抑えられる点も大きな魅力と言えます。
本記事では、S3 Vectors の実力を手軽に試すための検証内容と、その手順を簡単に解説します。
記事の内容を試す時間
読むのに3-4分
試すのに5-6分
簡易な実装手順
手順は簡単に以下の4ステップです。
- S3バケットの準備とデータ投入
- Bedrock Knowledge Bases の作成
- データの同期(ベクトル化)
- テストとRAGの検証
※ステップの詳細はあとで詳しく解説します。
構築手順解説
まずS3バケットを作ります

そしてサクッと適当に作ったPDFを10点ほどアップロードします。
検証のために やる気の上げ方やAmazonの課題 など さまざまな異なる意味合いのpdfファイルをアップロードしてみます。

S3へアップロードします。

次はBedrockに行って、先ほどのS3のデータをベクトル化して行きます。

本日時点(2025/12/15)では左のタグの下の方にナレッジベースの項目があり、それを選択すると以下画面が開くので、ここで作成ボタンを押します。

データソースでS3を選択します。

S3のURIの項目で、先ほどのS3を指定。
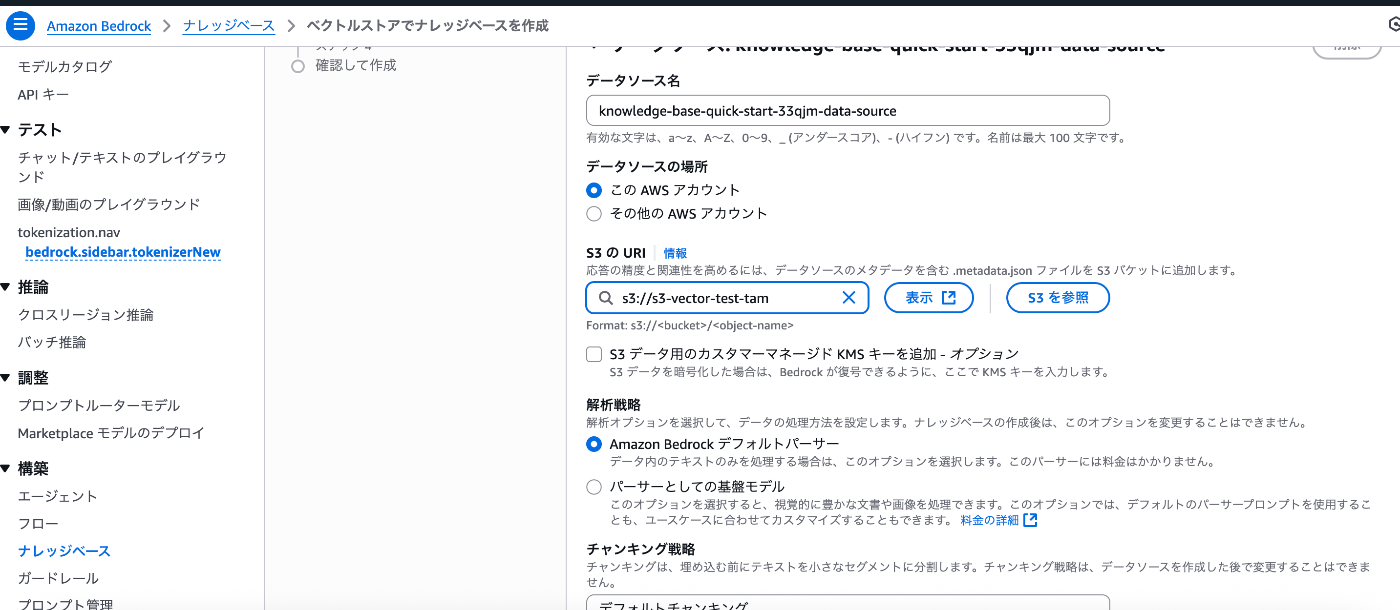
アップデートでS3 Vectorsの項目が増えているので、選択します。

ここでベクトル化を行う埋め込みモデルの選択をします。
基本は新しい世代のText Embeddingsモデルを選択して良いです。

ここでナレッジベースを作成を押し、少し待ちます。

少し待つとデータベースの準備が整います。

ここで以下画像にある 同期ボタン のクリックをします。
ベクトル化(テキストの意味検索ができるようになる)はこのタイミングで実施されます
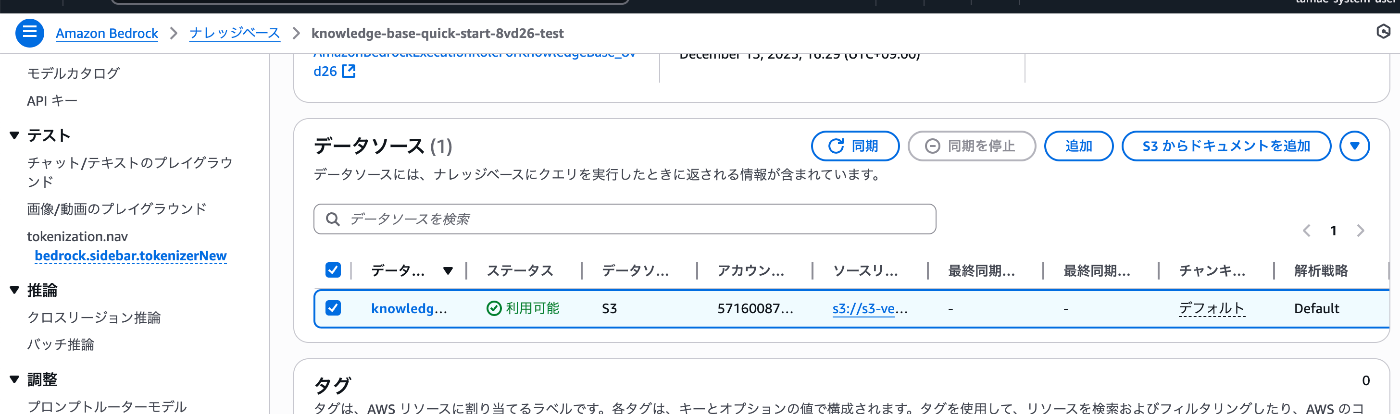
同期が完了すると、これでS3 Vectorsが使えるようになったので、Bedrockでテストをして行きます。
先ほどと同様左ナレッジベースに移動し、右上の「ナレッジベースをテスト」で検証していきます。
「取得のみ」と「取得と応答」を選択できます。
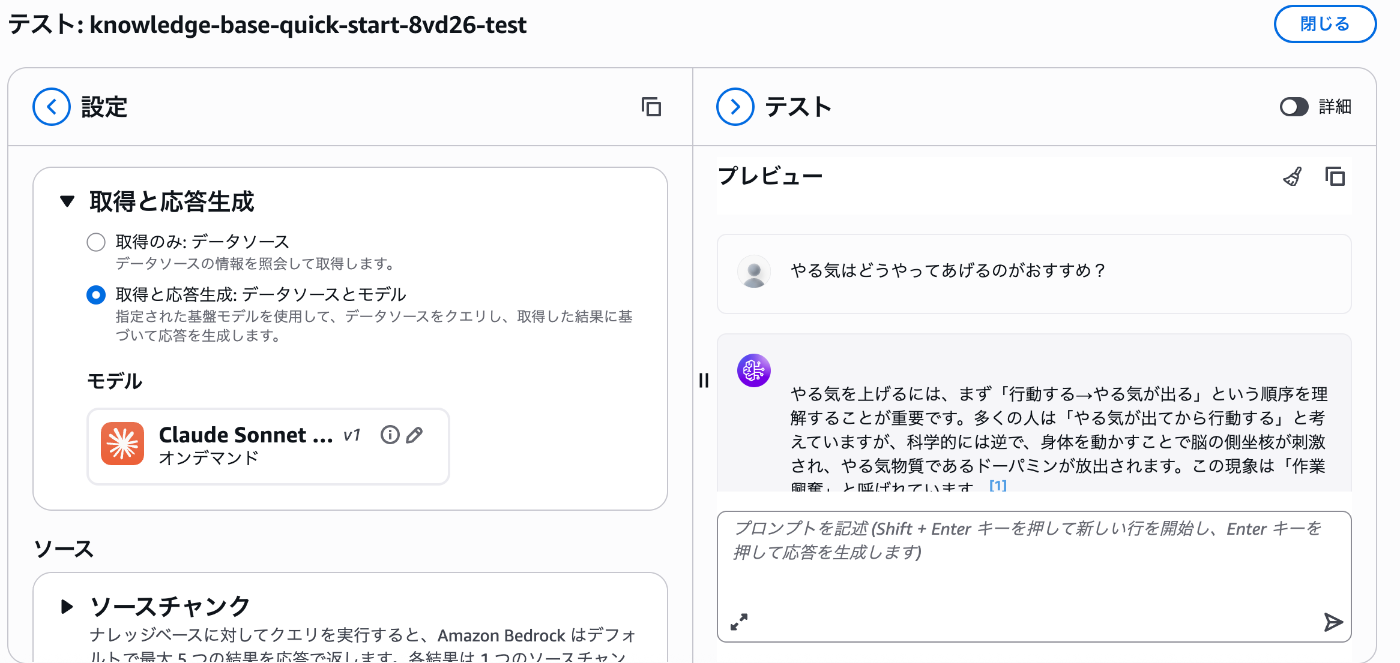
この違いはより自然な対話ができるのが取得と応答で、
該当情報を引っ張ってくるだけでいいシンプルなものが取得のみとなります。
結果を見るとやる気の上げ方について、アップロードしていたものをちゃんととってきてくれることがわかります。
取得と応答なだけあり、丁寧な返答です。
ここで先ほどとは異なる、Databricks関連での技術系のソースを検索してみます。

うまく引っ張れていることがわかりますね。
取得のみのバージョンを試したのは以下の画像です。

不要な情報(会話)はなく、端的に情報をとってきていることがわかります
以上で簡易ですが検証を終わります。
5分もかからずベクトルデータベースを構築できることが伝わったのではないでしょうか?
手順おさらい
先ほどまでの手順の振り返りです。
- S3バケットの準備とデータ投入
- 通常のS3バケットを作成し、検証したいドキュメント(PDF、HTML、テキストファイルなど)をアップロードします。
- (ポイント) ドキュメントの量が多くなくても、RAGの威力を確認するには十分です(例:数十個のファイル)。
- Bedrock Knowledge Bases の作成
- AWSコンソールでAmazon Bedrockの画面を開き、「Knowledge Bases」を作成します。
- データソースとして、先ほど作成したS3バケットを指定します。
- ベクトルストアとして「Amazon S3 Vectors」を選択します。
- 使用する埋め込みモデル(例:Titan Embeddings)を選択します。
- データの同期(ベクトル化)
- Knowledge Basesの画面で「Sync(同期)」を実行します。これにより、S3内のドキュメントが自動的に読み込まれ、選択した埋め込みモデルによってベクトル化され、S3 Vectorsに格納されます。
- テストとRAGの検証
- Knowledge Basesのテスト画面またはBedrockのコンソール画面に移動し、「Retrieve and Generate(検索と生成)」機能を使って質問を投げかけます。
- 例: 質問:「最新の製品ロードマップについて教えてください。」
- S3 Vectorsから取得した関連情報(ソースドキュメント)に基づいて、LLMが回答を生成する様子を確認できます。
- 従来のキーワード検索では難しかった、自然言語の意味(セマンティック)に基づいた検索精度を体感できます。
終わりに
いかがだったでしょうか?
S3 VectorsとBedrockを組み合わせた構築がノンコードかつスムーズに構築でき、
低コストなベクトルデータベースを簡単に利用できることがわかったと思います。
ベクトルデータベースも民主化できるいい時代になりましたね。
Congratulations on database democratization!
