
「そもそもベクトルデータベースって何?」という方は、ぜひ前回の記事も併せてチェックしてみてください
ベクトルデータベースとは
今回は、ベクトルデータベース、「Pinecone」を実際に構築してみようと思います!
Pineconeにログイン
https://login.pinecone.io/login
インデックス作成手順
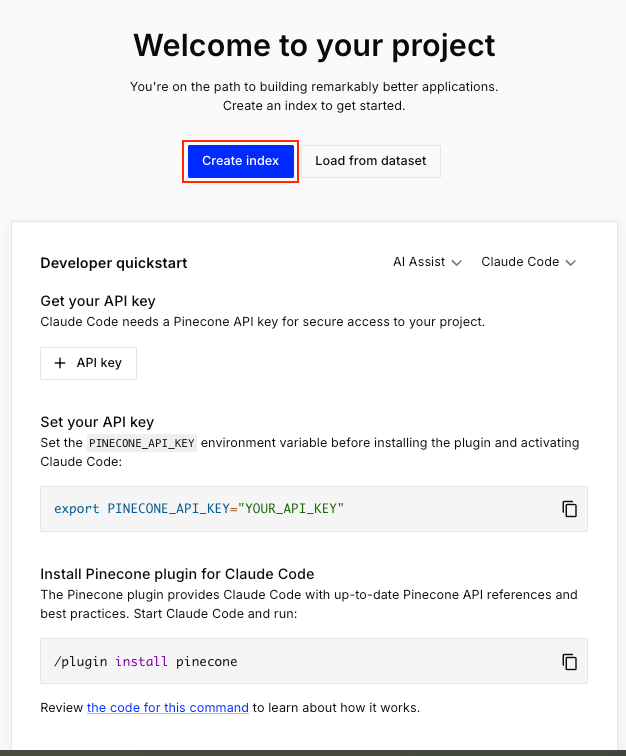
QuickStartからインデックスを作成
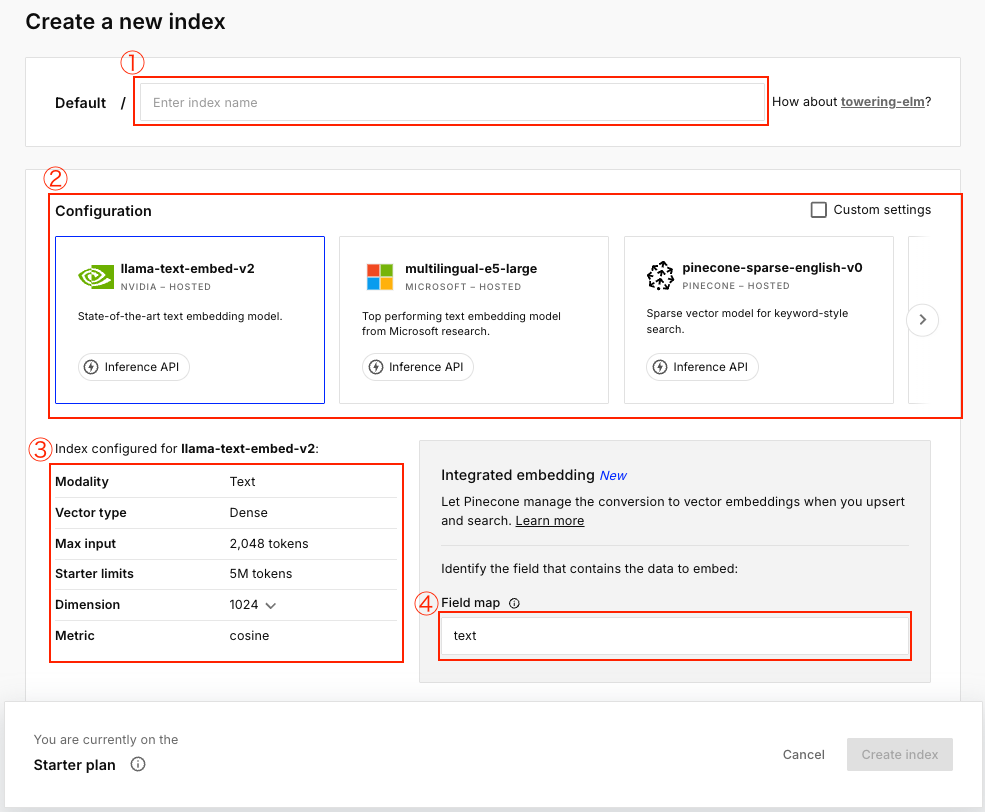
①インデックス名を入力
インデックス名を入力
データベースの識別名を決める
②Configurationを選択
テキストをベクトルに変換するAIモデルの選択
| モデル名 | 提供元 | 特徴 |
|---|---|---|
| llama-text-embed-v2 | Meta | 多言語対応、日本語に強い、バランス良好 |
| multilingual-e5-large | Microsoft | 100言語以上対応、高精度 |
| pinecone-sparse-english-v0 | Pinecone | 英語特化、キーワード検索向け |
| text-embedding-3-large | OpenAI | 高次元・高精度、コスト高め |
③各項目について
1. Modality(モダリティ)
処理できるデータの種類
- text: テキストのみ(最も一般的)
- image: 画像のみ
- multimodal: テキストと画像の両方
例: ブログ記事の検索なら text、画像検索なら image
2. Vector type(ベクトルタイプ)
ベクトルの形式
- Dense(密ベクトル)
- ほとんどの要素に値が入っている
- 意味的な類似性を捉える
- セマンティック検索(文字の一致ではなく、関連性の高い情報を結果として返す検索)に最適
例: [0.234, -0.567, 0.891, 0.123, …] # ほぼ全て非ゼロ
- Sparse(疎ベクトル)
- ほとんどの要素がゼロ
- キーワードベースの検索向け
- 従来の全文検索に近い
例: [0, 0, 0.5, 0, 0, 0, 0.8, 0, …] # ほとんどゼロ
選び方:
- 意味的な検索 → Dense(llama-text-embed-v2など)
- キーワード検索 → Sparse
3. Max input(最大入力)
1回で処理できるテキストの最大長(トークン数)
| 値 | 意味 | 用途 |
|---|---|---|
| 512 | 約400語(2000文字程度) | 短文、商品説明 |
| 2048 | 約1600語(8000文字程度) | ブログ記事、ニュース |
| 8192 | 約6400語(32000文字程度) | 長文記事、論文 |
注意: 最大入力を超えるテキストは切り捨てられるか、複数に分割する必要がある
4. Dimension(次元数)
ベクトルの長さ(数値の個数)
| 次元数 | 特徴 | トレードオフ |
|---|---|---|
| 768 | 軽量、高速 | 精度やや低い |
| 1024 | バランス良好 | 推奨 |
| 3072 | 高精度 | ストレージ・計算コスト高 |
選び方:
- 一般的な用途 → 1024(llama-text-embed-v2)
- 高精度が必要 → 3072(text-embedding-3-large)
- 高速・軽量 → 768
5. Metric(距離指標)
ベクトル間の「似ている度合い」を測る計算方法
Cosine(コサイン類似度)
- ベクトルの方向の類似性を測る
- テキストの意味的な類似性に最適
- -1(正反対)〜 1(完全一致)
使用例: テキスト検索、セマンティック検索
Euclidean(ユークリッド距離)
- ベクトル間の直線距離
- 値が小さいほど似ている
- 画像検索などで使用
使用例: 画像の類似度、座標データ
Dotproduct(内積)
- ベクトルの大きさと方向の両方を考慮
- 特殊な用途
使用例: レコメンデーション、スコアリング
④フィールドマップを選択
AIが意味を理解してベクトル化(数値化)するデータ部分
⑤キャパシティーを選択
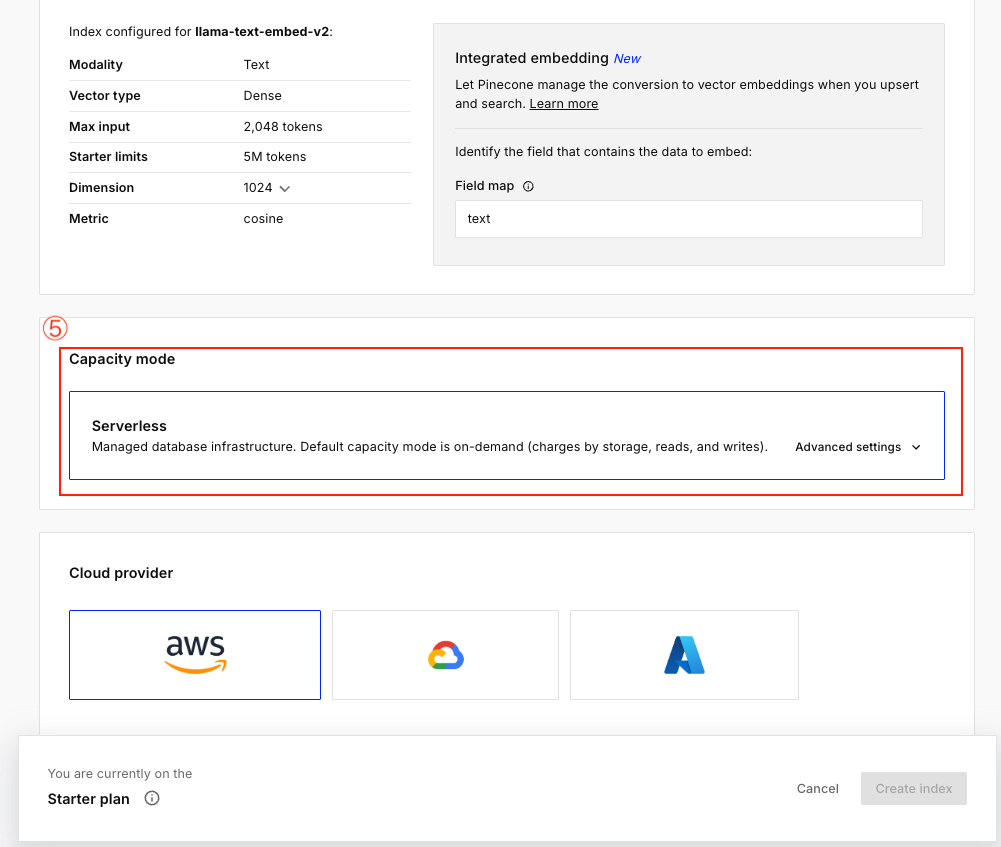
Capacity mode(容量モード)
リソースの割り当て方式
- On-demand(オンデマンド): デフォルト
- 自動でリソースを調整
- トラフィックの変動に対応
- 初期費用なし
- Dedicated(専用): Pod型のみ
- リソースを事前予約
- 安定したパフォーマンス
- 大規模本番環境向け
⑥クラウドプロバイダーを選択
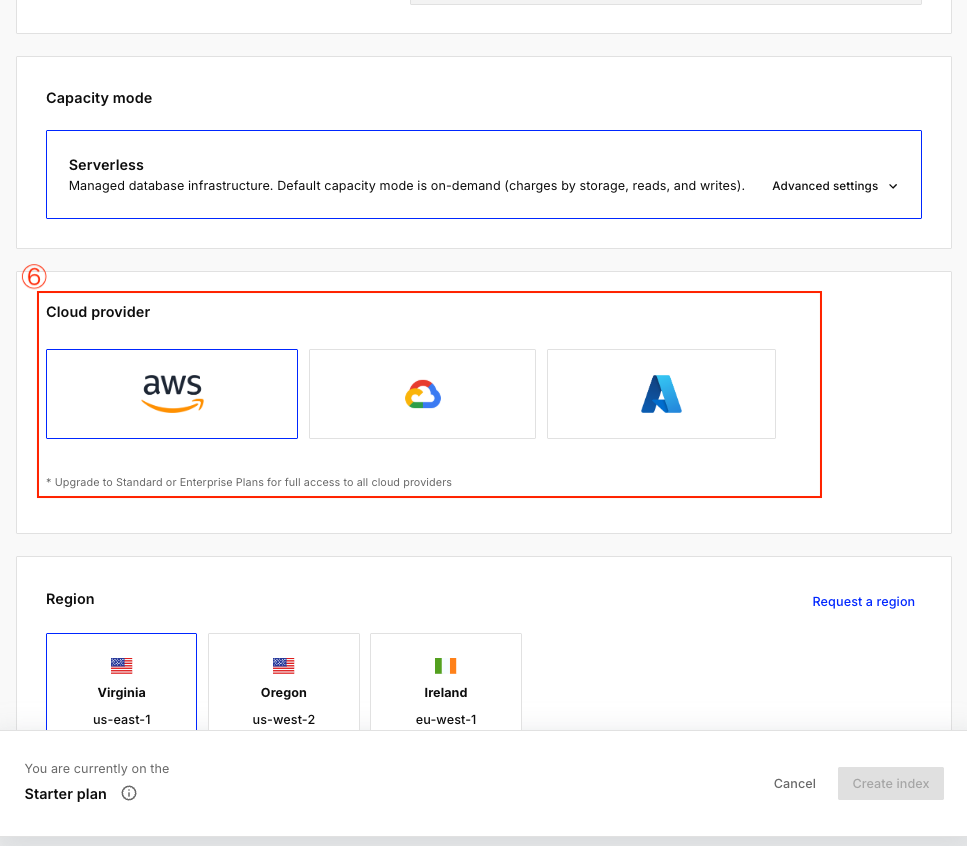
Cloud provider(クラウドプロバイダー)
インデックスをホストするクラウドサービス
- AWS: Amazon Web Services
- 最も広く展開
- 豊富なリージョン選択肢
- GCP: Google Cloud Platform
- Googleのインフラ
- 特定地域で有利
- Azure: Microsoft Azure
- Microsoftエコシステムとの統合
選び方: 既存のアプリケーションがホストされているクラウドと同じものを選ぶとレイテンシが低くなる
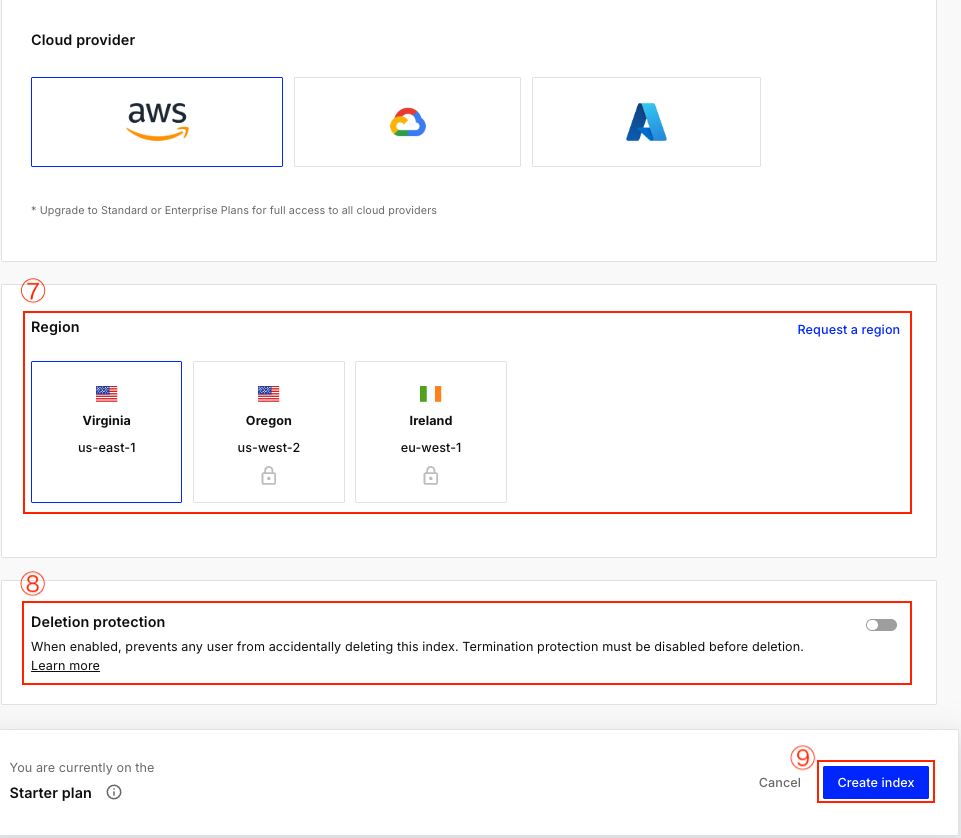
⑦リージョンを選択
Region(リージョン)
データセンターの物理的な場所
- us-east-1: 米国東部(バージニア)- デフォルト
- us-west-2: 米国西部(オレゴン)
- eu-west-1: 欧州西部(アイルランド)
- ap-southeast-1: アジア太平洋(シンガポール)など
選び方: ユーザーに最も近いリージョンを選ぶと応答速度が向上
⑧Deletion protection(削除保護)
誤って削除するのを防ぐ安全機能
⑨「Create Index」でインデックス作成
実際にデータを追加してみる
インデックスの作成ができたら、次はデータを追加(Upsert)してみましょう
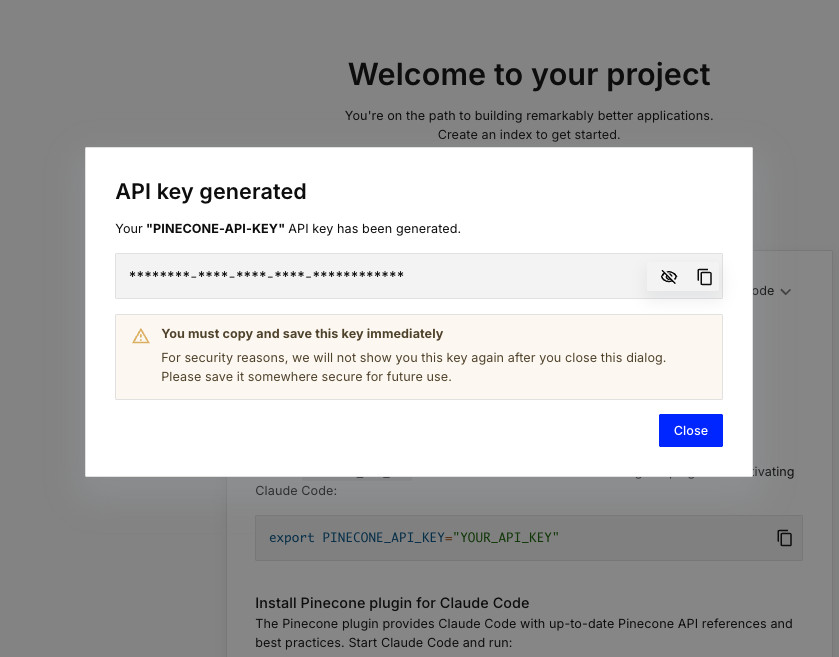
- APIキーの作成
Pineconeを外部から操作するために、まずはAPIキーを取得します
- Pineconeの管理画面からAPIキーを新規作成します
- 作成したAPIキーはメモしておきましょう
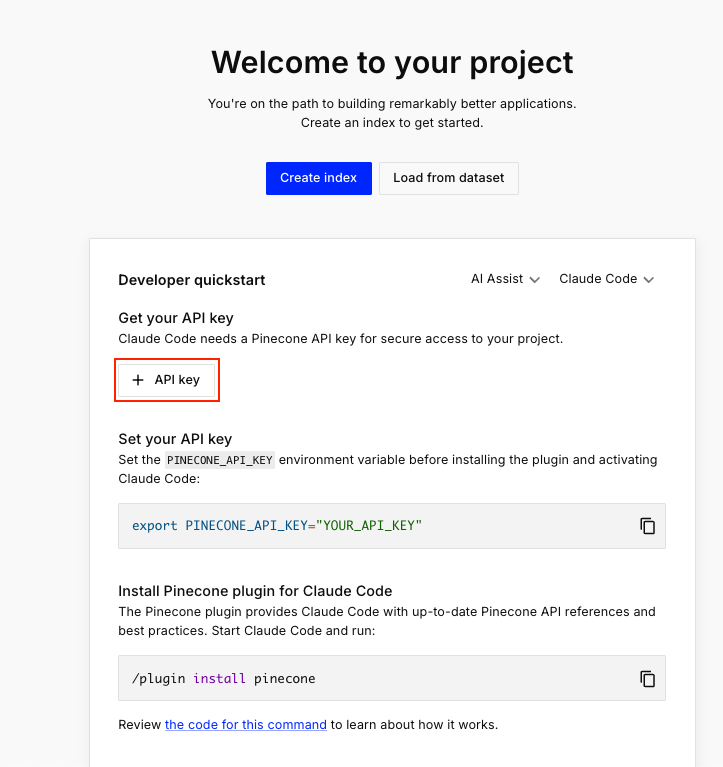
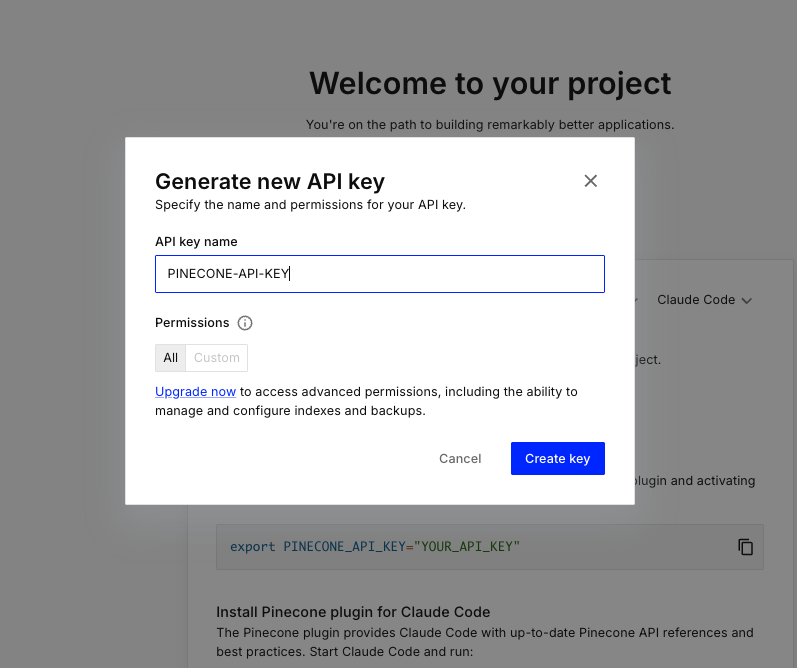
- Claude CodeのPineconeプラグインを活用
今回は、Claude CodeにあるPineconeプラグインを使用して、データを追加するためのPythonスクリプトを自動生成していきたいと思います
公式の手順があるので、そちらに従って作成します
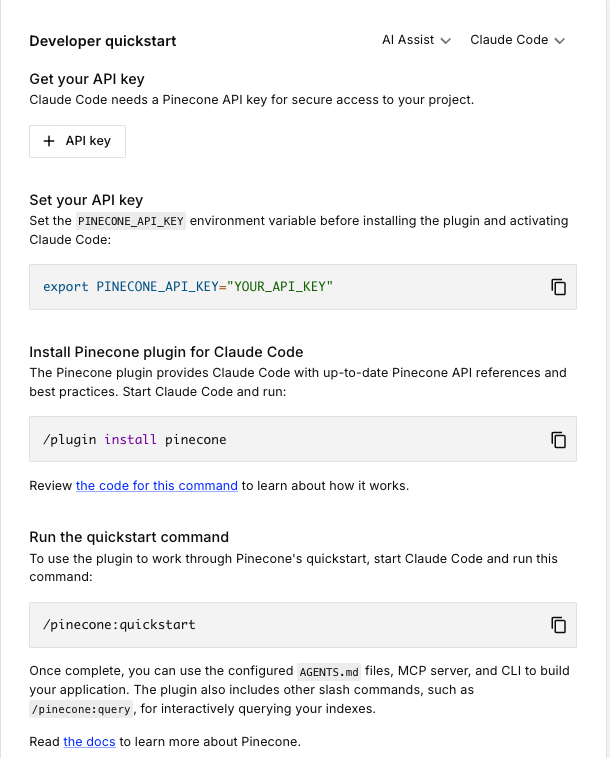
Pineconeプラグインを使用すると、対話形式でAPIの設定や操作スクリプトの作成を代行してくれるため、非常に簡単に作成できます
まずは、以下の手順でプラグインをインストール・実行します
プラグインのインストール
/plugins add pinecone
クイックスタートの実行
インストール完了後、以下のコマンドを実行します
/pinecone quickstart
実行の途中で、どのクイックスタートパスを利用するか選択を求められます
今回は「データの追加」を行いたいので、Aを選択してください
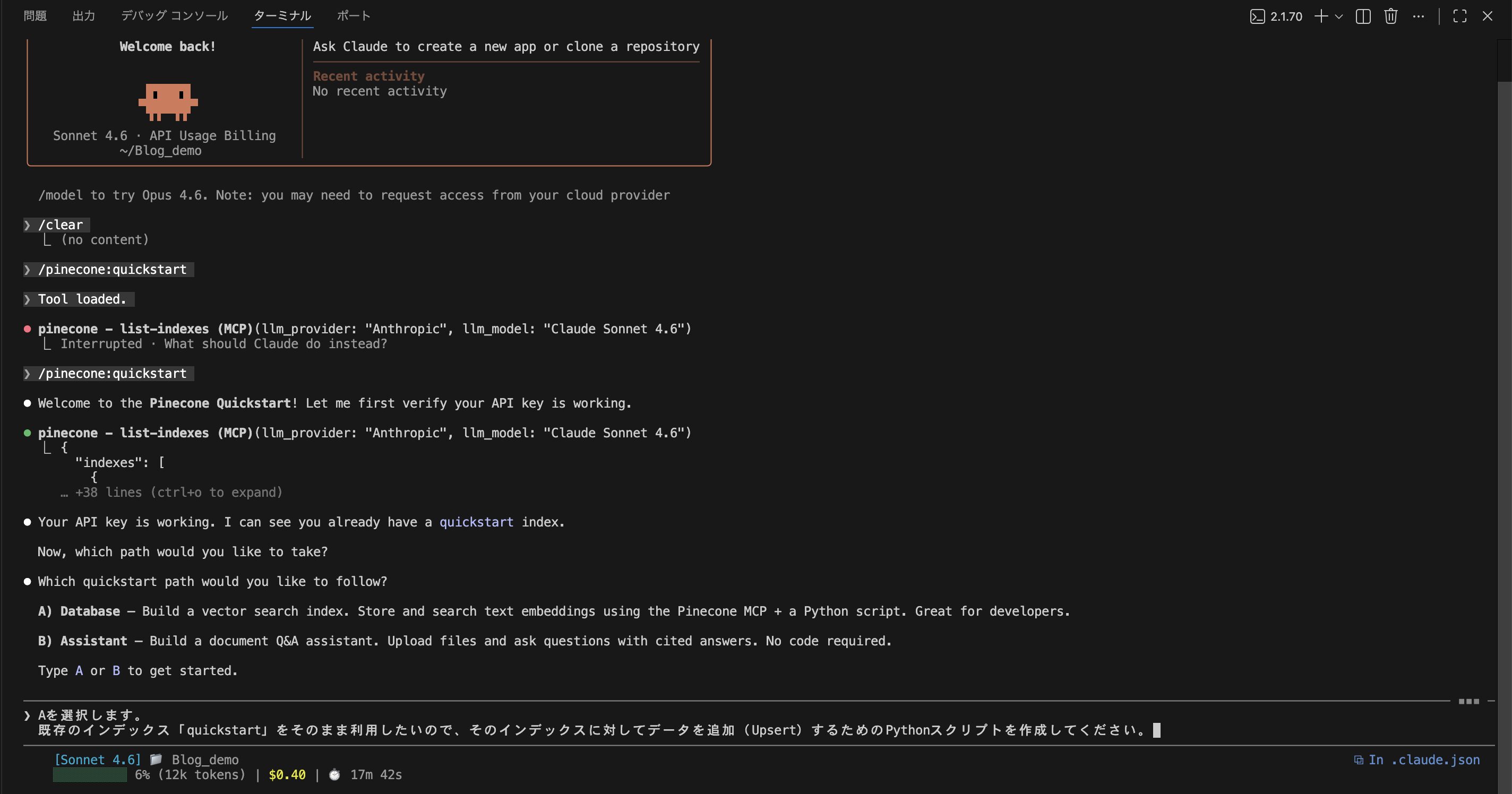
3. データの追加(Upsert)を実行
対話が終了すると、実行用のPythonスクリプトが自動生成されます
作成されたファイルを確認したら、以下のコマンドで実行してみましょう
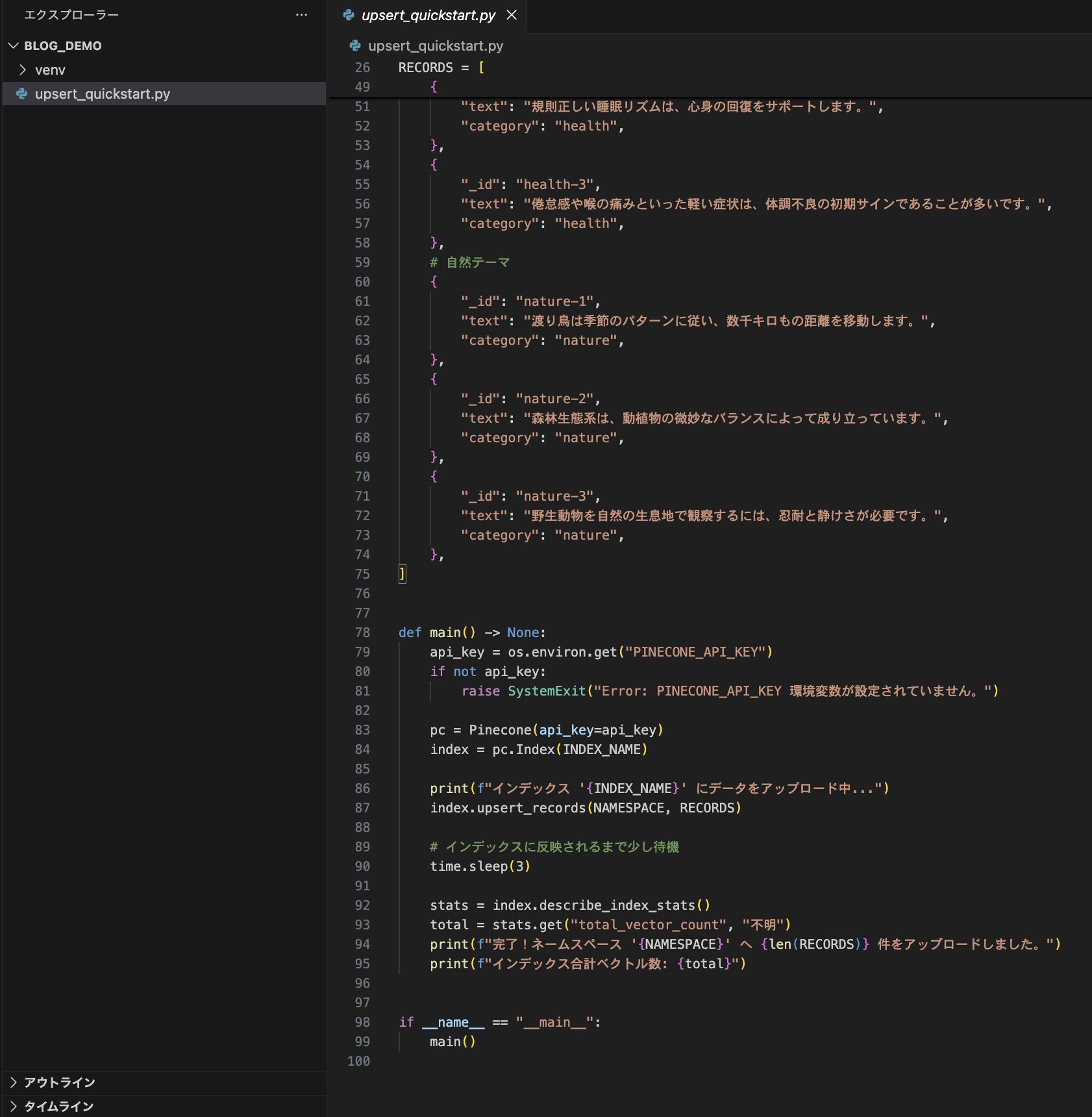
python upsert_quickstart.py
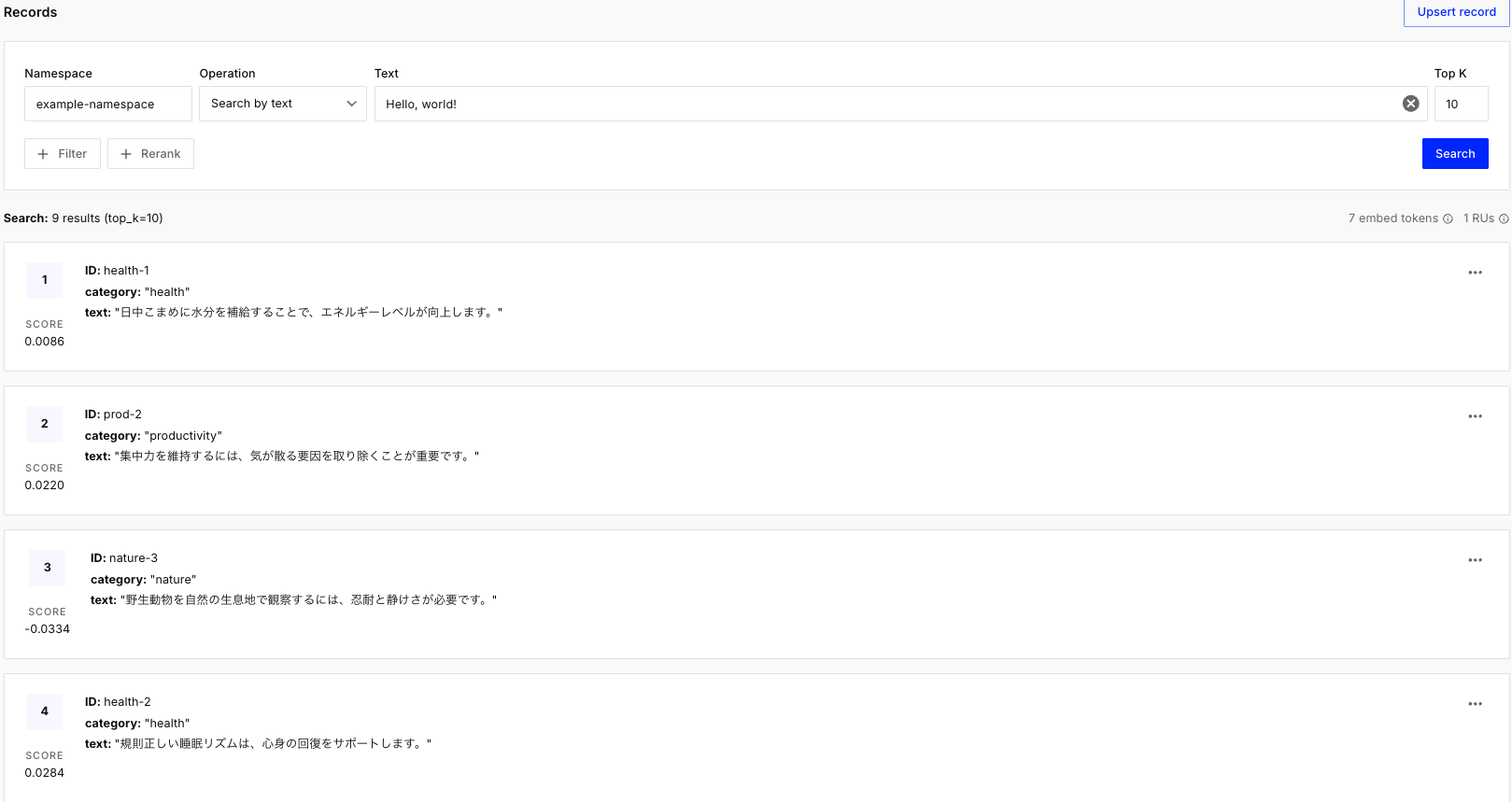
実行後、Pineconeのダッシュボードの「Indexes」から、Record Countが追加されていることを確認できれば成功です!
終わりに
実際に手を動かしてベクトルデータベースを構築・操作してみることで、データの持たせ方や仕組みを具体的にイメージすることができました。
次回は、今回構築したデータベースを活用して、RAG(検索拡張生成)の実装にチャレンジしてみたいと思います!

