事の経緯
BIツールを使ってのデータの視覚化要望がありました。
AWSを使っていたので、QuickSightで実現できるかなと思ってましたが結構色々なハードルがあったのでその備忘録です。
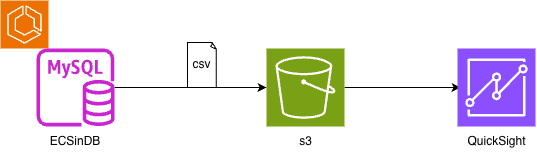
MySQLからエクスポートしたCSVをS3で読み込んでQuickSightの計算フィールドで1、2回の計算や変形くらい出来るかと思ったのですが思った様にいきませんでした。
当初の構成
出来なかった事
QuickSight
- 異なるデータセット間で計算出来ない
- 計算フィールドで使えるのは同データセットのカラムのみ
- 同データセットの異なるカラム同士で2度以上の計算が難しい
- 計算フィールドを使って判定式を作ったり計算する事は出来るが、計算結果を別の式に使おうとすると計算/整形が出来ない
- 1グラフ:1データセットしか選択出来ない
- グラフで、データセットAのカラム1とデータセットBのカラム2を選択する事は出来ない
結局Athenaで取り込んでETLしないとQuickSightで描写したかった内容にならなかったので、以下の構成にしました。
最終的な構成

出来た事
Glueクローラー
定期実行のスケジューラーをかけられる
- ネイティブでスケジューラーをサポート
フォルダの命名規則によって、Athenaに追加カラムを設定出来る
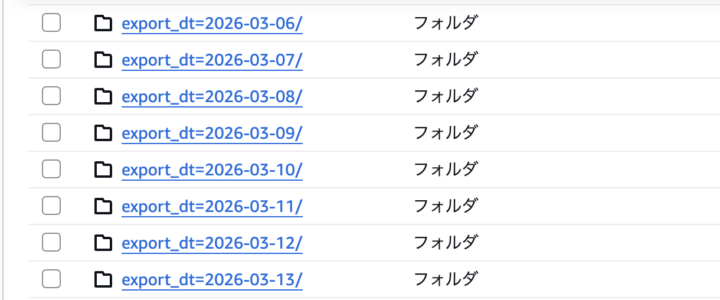
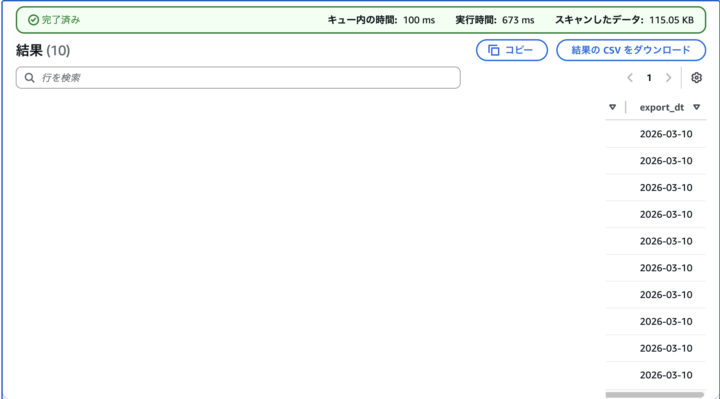
- 「{カラム名}={値}」というフォルダ名を付けてその中に読み込むファイルを置くと、取り込んだすべての行にカラムと値が追加される
- 例:「export_dt=2026-03-10」と付けた場合、「export_dt」カラムと「2026-03-10」が追加される
-
参考リンク:「クローラーを使用したデータカタログへの入力」
ファイル内容からカラムの自動識別可能
- 精度に多少問題あり
- とりあえずデータレイクとして溜めてから運用を考えるケースでおすすめ
- データ形式がわかっているならClassifiersを使って型固定を推奨
差分検知方法にバリエーションがある
- 全ファイルの追加・削除を取り込む全文スキャン
- フォルダやファイルが追加された部分だけ取り込む増分スキャン
- 元ファイルが削除された場合、Athena側にだけ半端なデータが残る点に注意
ELTや任意SQL文の実行をネイティブにサポート(Apache Spark)
- 最低1DPU(vCpu4,メモリ16GB)=$0.44から始まる高スペック高コスト
- 今回は毎日数MBを数秒で整形するため過剰。Lambdaで実装
Athena
Glue経由でcsvの内容をテーブルに出力
- 元ファイルに影響を与えず独立したテーブルを作成し、計算や整形が可能
LambdaにAthenaのAPIを叩かせ、任意SQL文を実行して整形後テーブルを生成
- Athena自身に定期的なクエリ実行機能はないのでLambdaから実行
QuickSightのデータセットとしてネイティブサポート
- データセットとしてAthenaのテーブルを1クリックで指定可能
QuickSight
一つのダッシュボードに複数のデータセットを追加出来る
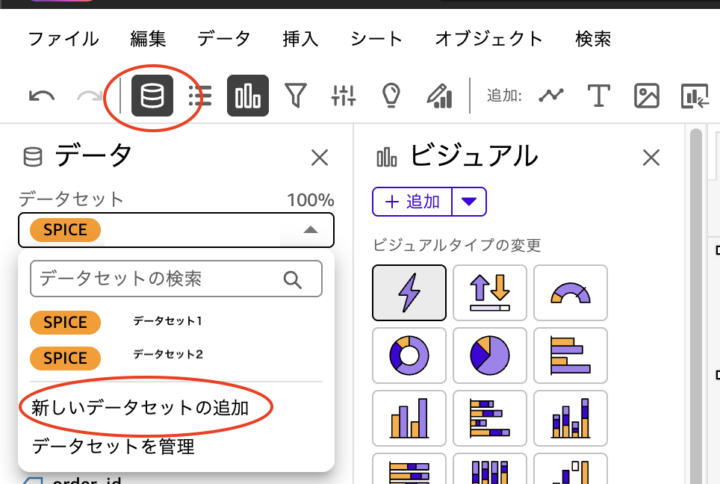
- データセットのプルダウン「新しいデータの追加」から複数のデータセットを同一分析・ダッシュボードに追加可能
日付などを操作する「フィルター」は、異なるデータセットで同名・同型のカラムがあれば連動出来る
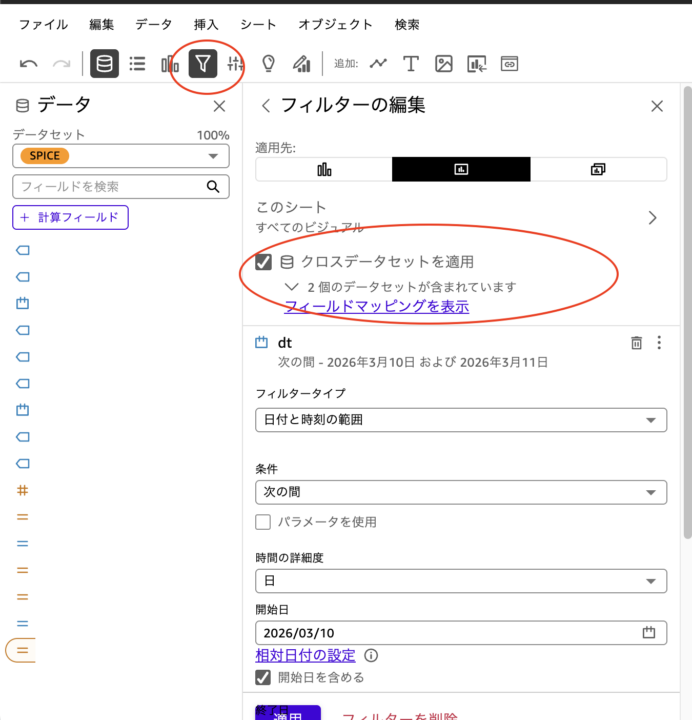
- 例:日付型のdtカラムがどちらのデータセットにもあった場合、フィルターでdtカラムを対象にし、「クロスデータセットを適用」で描写する日付を変えた場合同時に変わる
- 初期状態だとデータセット1のdtと、データセット2のdtを別々に変える必要がある
QuickSightのアクセス権限は管理コンソール以外にも、AWS側IAMでも操作出来る
- IAMロール「aws-quicksight-service-role-v0」が自動生成され動いている
- terraformなどで権限を付与可能
最後に
AWSでBIツールと言えばQuickSightが候補に上がりますが、他のBIツールと比較して、出来る事と出来ない事が異なるので導入前の検討材料になれば幸いです。


