
前回、ベクトルデータベース(Pinecone)を構築し、データを保存するところまで完了しました。
今回は、そのデータをもとにLLMが回答を生成する「RAG(Retrieval-Augmented Generation)」の仕組みを構築していきます。
前回の記事をまだ読んでいない方は、ぜひこちらからご覧ください。
1. 使用するLLM(Groq)について
今回は、GroqをLLMとして使用します
Groqとは?
LPU(Language Processing Unit)という独自のプロセッサを搭載し、従来のGPUよりも圧倒的な速さでテキスト生成が可能な推論エンジンです
2. Groqのセットアップ
まずは、APIを利用するための準備を進めましょう
アカウント作成
Groqにアクセスし、アカウントを作成します
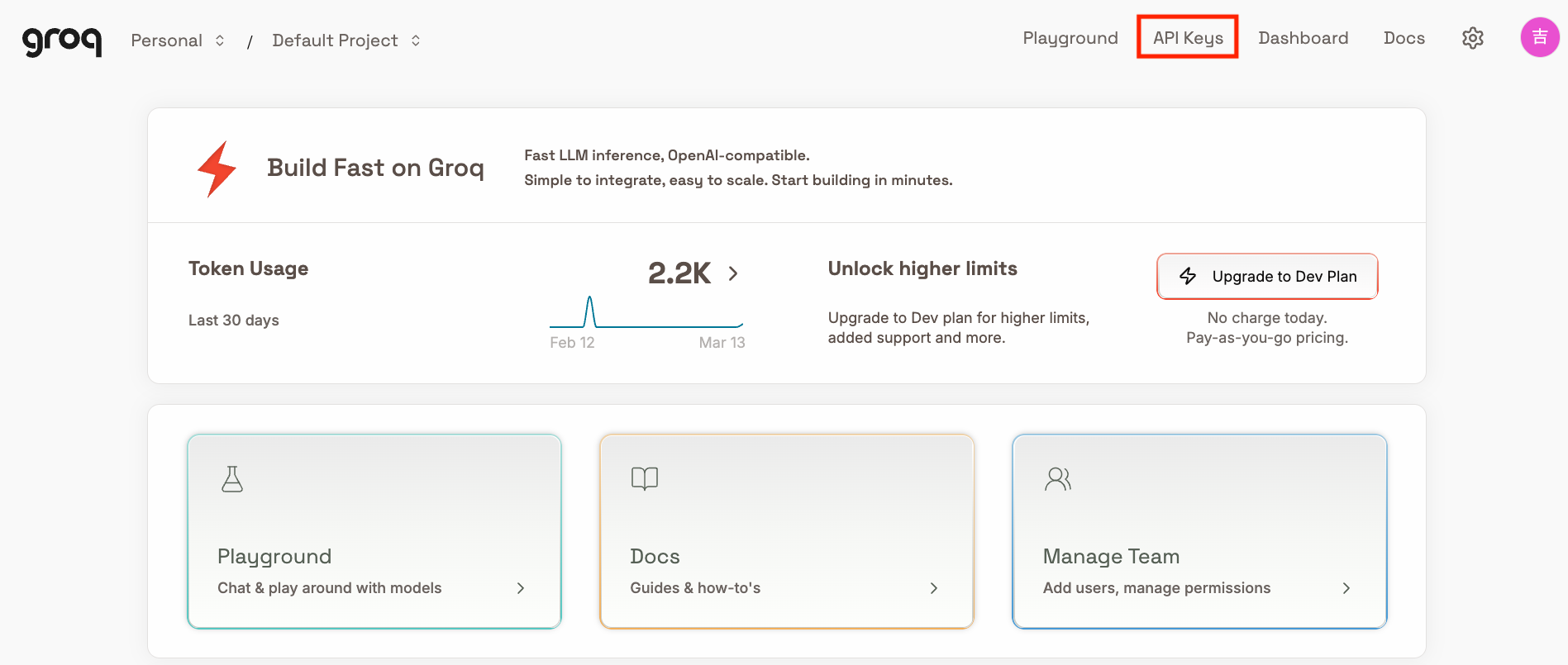
APIキーの発行
ログイン後、右上の「API Keys」から「Create API Key」をクリックして作成・コピーします
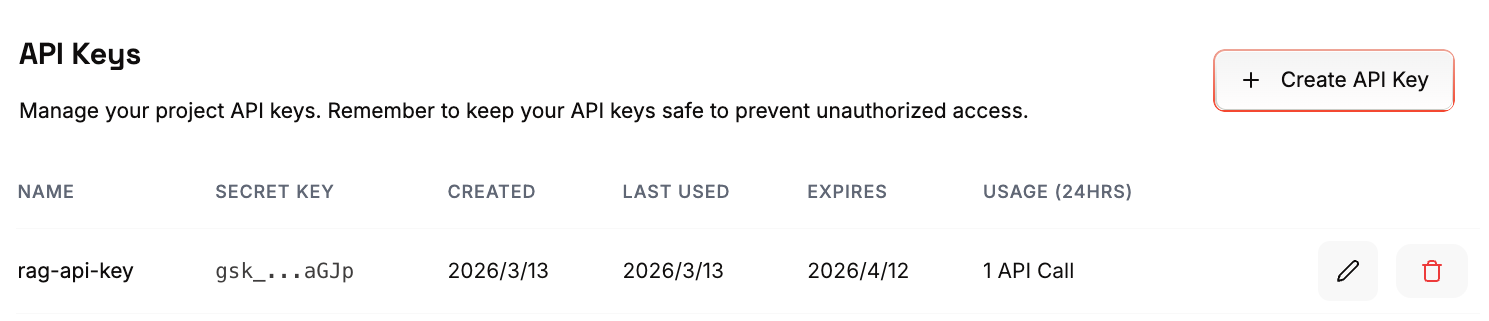
環境変数の設定
ターミナルで以下のコマンドを実行し、APIキーを設定します
export GROQ_API_KEY="先ほどコピーしたAPI KEY"
3. ライブラリのインストール
今回使用するライブラリをインストールします
pip install groq
4. RAG実行スクリプトの作成
Pineconeから関連情報を取得し、Groqで回答を生成するスクリプト(rag_quickstart.py)を作成します
"""
Pinecone + Groq による RAG(検索拡張生成)デモスクリプト
フロー:
1. ユーザーの質問を受け取る
2. Pinecone で関連ドキュメントを検索(セマンティック検索)
3. 取得したコンテキストと質問を Groq LLM に渡す
4. 回答を生成して表示する
環境変数:
PINECONE_API_KEY - Pinecone の API キー(必須)
GROQ_API_KEY - Groq の API キー(必須)
"""
import os
from pinecone import Pinecone
from groq import Groq
# --- 設定 ---
INDEX_NAME = "quickstart"
NAMESPACE = "example-namespace"
TOP_K = 3
GROQ_MODEL = "llama-3.3-70b-versatile"
def search_context(index, query: str) -> list[str]:
"""Pinecone でクエリに関連するドキュメントを検索する。"""
results = index.search(
namespace=NAMESPACE,
query={"top_k": TOP_K, "inputs": {"text": query}},
)
hits = results.get("result", {}).get("hits", [])
return [hit["fields"]["text"] for hit in hits if "text" in hit.get("fields", {})]
def generate_answer(groq_client: Groq, question: str, context_chunks: list[str]) -> str:
"""取得したコンテキストをもとに Groq LLM で回答を生成する。"""
if not context_chunks:
context_text = "(関連する情報が見つかりませんでした)"
else:
context_text = "\n".join(f"- {chunk}" for chunk in context_chunks)
prompt = f"""以下のコンテキスト情報をもとに、質問に日本語で答えてください。
コンテキストに含まれない情報は回答に含めないでください。
【コンテキスト】
{context_text}
【質問】
{question}
【回答】"""
response = groq_client.chat.completions.create(
model=GROQ_MODEL,
messages=[{"role": "user", "content": prompt}],
temperature=0.2,
)
return response.choices[0].message.content.strip()
def main() -> None:
pinecone_api_key = os.environ.get("PINECONE_API_KEY")
groq_api_key = os.environ.get("GROQ_API_KEY")
if not pinecone_api_key:
raise SystemExit("Error: PINECONE_API_KEY 環境変数が設定されていません。")
if not groq_api_key:
raise SystemExit("Error: GROQ_API_KEY 環境変数が設定されていません。")
pc = Pinecone(api_key=pinecone_api_key)
index = pc.Index(INDEX_NAME)
groq_client = Groq(api_key=groq_api_key)
print("=== Pinecone + Groq RAG デモ ===")
print("終了するには 'quit' または 'exit' と入力してください。\n")
while True:
question = input("質問を入力してください: ").strip()
if not question:
continue
if question.lower() in ("quit", "exit"):
print("終了します。")
break
print("\n[1] Pinecone で関連ドキュメントを検索中...")
context_chunks = search_context(index, question)
if context_chunks:
print(f"[2] {len(context_chunks)} 件のコンテキストを取得しました:")
for i, chunk in enumerate(context_chunks, 1):
print(f" {i}. {chunk}")
else:
print("[2] 関連するドキュメントが見つかりませんでした。")
print("\n[3] Groq で回答を生成中...")
answer = generate_answer(groq_client, question, context_chunks)
print(f"\n【回答】\n{answer}\n")
print("-" * 60 + "\n")
if __name__ == "__main__":
main()
5. 動作確認
準備が整いましたら、スクリプトを実行してみましょう
python rag_quickstart.py
実行すると質問の入力を求められます
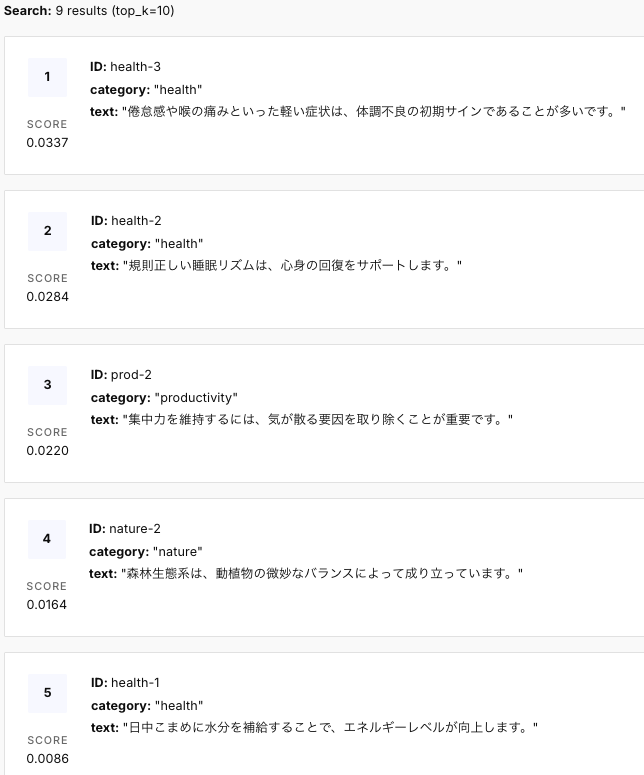
例えば「体調が悪いときはどうすればいい?」と入力すると、Pinecone内のデータに基づいた回答が返ってきます

Pineconeに格納されている以下のデータが正しく参照され、Groqによって自然な文章にまとめられていることがわかります
終わりに
「ベクトルデータベースとは何か」という基礎から、実際の構築、そして今回のGroqとPineconeを用いたRAG環境の構築まで、一連の流れを通すことができました。
今回の取り組みを通じて、これまで「RAG(検索拡張生成)」という言葉に対して抱いていたぼんやりとしたイメージが、実際に手を動かすことで一気に解像度が高まったと思います。
この記事が、これからRAG構築に挑戦する方にとって少しでも参考になれば幸いです。


