
はじめに
もともとは Qiita で紹介していた記事の 響きがかっこいい、Zed に乗り換えてみた話 がありまして、Zed が結構いい感じなので、Qiita ではなく、こちらでご紹介したいと思い、こちらのブログに続編載せさせてもらいます。
前回記事の最後に、「Ollama で Gemma を動かして Inline Assistant をローカルで使うのもそのうち試したい」と書いたんですが、試したので、その記録です。
きっかけ
そもそもなんでやろうと思ったかですが、、以下の理由です。
- Inline Assistant を API キーを利用せずに、課金せずに使いたかった
- ローカル LLM を動かしてみたかったですね。
そこで選んだのが、話題になった Gemma 4 を Ollama で動かして、Zed のプロバイダーとしてぶら下げるという構成です。
ローカル LLM を動かそうと思うと、いくつか方法があるようでちょろっと聞いてみたらこんな感じでした。
| 方法 | 特徴 | 向いている人 |
|---|---|---|
| Ollama | セットアップが最も簡単。pull して run するだけ。OpenAI 互換 API を自動で提供。Zed や VS Code 等との連携が豊富 |
とにかく手軽に使いたい人。エディタ連携が目的の人 |
| llama.cpp | Ollama の内部でも使われている C++ 推論エンジン。量子化(GGUF 形式)に強く、細かいパラメータ制御が可能 | パフォーマンスを自分でチューニングしたい人。量子化レベルを細かく選びたい人 |
| vLLM | バッチ推論・高スループットに特化した Python 製サーバ。PagedAttention で効率的なメモリ管理 | GPU 搭載 Linux 機で本格的にサーブしたい人。複数リクエストを捌く用途 |
| LM Studio | GUI アプリ。モデル検索・ダウンロード・チャットがワンストップ。内部は llama.cpp | CLI が苦手な人。まずモデルを試してみたい人 |
| MLX(Apple 専用) | Apple Silicon のユニファイドメモリに最適化された Apple 公式フレームワーク。Python API 中心 | Mac で最大限の性能を引き出したい人。Python から直接使いたい人 |
上記の「向いてる人」を見てもらえればわかりますが、実質、Ollama 、MLX くらいなんじゃないかなという印象です。
Ollama で今回いってみたいと思います。
一番はすぐ出てきたのがこれなのと、調べてみた感じもこの方法が多いみたいです。
Zed から Ollama を使うとこんな感じの経路で叩いていきます。
※これ以降のネタバレも色々含んじゃってますが、、
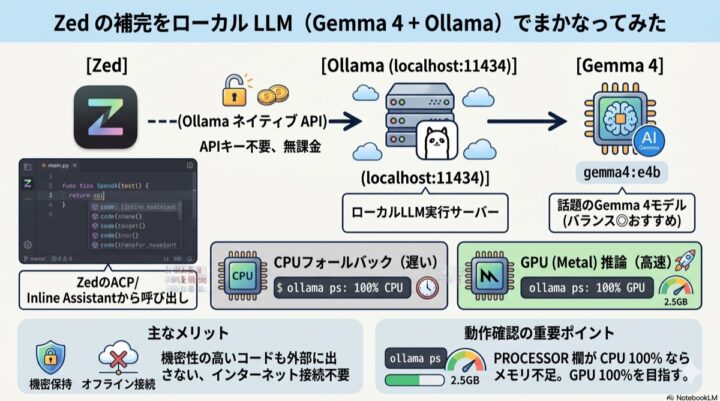
Ollama はローカルで LLM を使えるようにしてくれます。利用したいモデルを ollama pull で落としてくると、あとは HTTP API で叩けるようになります。Zed 側はこの Ollama を公式にプロバイダーとしてサポートしているので、設定ファイルに数行書くだけで、チャット欄や Inline Assistant からそのモデルを呼べるようになります。
API キーも外向き通信もいらないので、なにかが起きて Claude とか Gemini とかみんな使えなくなったら、私はローカルで悠々とローカル LLM を利用することができます。いいでしょ。
では、やっていきます。
1. セットアップ手順
Ollama を入れる
brew install ollama
インストールしたら、バックグラウンドでサーバを起動しておきます。
ollama serve
Gemma 4 を pull する
Docker でコンテナ動かすときみたいですが、ollama pull でモデルをダウンロードして ollama run で実行する、という docker pull → docker run 風な流れです。Ollama はコンテナランタイムの LLM 版みたいな感じです。
では、pull します。
ollama pull gemma4:e4b
Gemma 4 には複数のサイズがあり、タグで指定し、pullできます。
私の MacBook Air M2(24GB)では何が快適に動くのかですが、26b でやったらピンチでした。
そのため、e4b かなって感じで選びましたが、Claude に出させると、以下のような形みたいです。
やっぱり e4b が合うみたいです。
| モデル | サイズ | 動作可否 |
|---|---|---|
| gemma4:e2b | 7.2GB | 軽快に動作。常用向き |
| gemma4:e4b | 9.6GB | 余裕で動作。バランス◎おすすめ |
| gemma4:26b (MoE) | 約15GB前後 | 動くが 24GB だと他アプリ圧迫しそう |
| gemma4:31b Dense | 約20GB超 | 厳しい。スワップ多発の可能性大 |
pull が終わったら一度動作確認。
$ ollama run gemma4:e4b "hello" Hello! How can I help you today? 😊
返事が返ってきてますね。
Zed の設定に Ollama プロバイダーを追加する
Zed の設定ファイル(~/.config/zed/settings.json)に、language_models.ollama のブロックを追加します。
{
"language_models": {
"ollama": {
"api_url": "http://localhost:11434",
"available_models": [
{
"name": "gemma4:e4b",
"display_name": "Gemma 4 E4B (local)",
"max_tokens": 128000
}
]
}
}
}
ポイントは available_models に明示的にモデルを列挙しておくこと。これをやっておくと、チャット欄のモデル選択ドロップダウンに「Gemma 4 E4B (local)」がちゃんと出てきます。
チャット欄・Inline Assistant で選ぶ
- チャット欄:右下のモデル選択ドロップダウンから
Ollama > Gemma 4 E4B (local)を選ぶ - Inline Assistant(
Ctrl+Enter):同じくモデル選択で Ollama のモデルを指定
チャット欄
右下にある記載みてもらうとわかると思います。
Inline Assistant
文字列の右の方に表示されているのがわかると思います。

これで、投げると、クラウドではなく、ローカルの Gemma 4 が応答してくれます。
2. 使ってみた感想
====ここの感想は Gemma 4 が書いてます。====
(実際に使ってみた所感)
全体的な印象としては、クラウドサービスと比較すると若干のタイムラグは感じるものの、ローカル環境でこのレベルの推論ができるのは驚異的です。特に、機密性の高いコードや、外部に漏らしたくない思考プロセスをエディタ上で処理できる点が、最も大きなメリットだと感じました。
- レスポンス速度:体感的には非常に高速で、質問に対する応答は2〜3秒以内に得られます。大量のコンテキストを処理する際にはGPUの負荷が高まるため、やや遅延を感じることがありますが、実用上は十分な速度です。
- 補完の質:プロンプトの意図やコードの文脈を適切に汲み取ってくれるため、一般的なボイラープレートコードの補完や、型定義の推測などでは「頭の良いアシスタント」として機能してくれます。
- Inline Assistant での書き換え:非常に優秀です。関数のリファクタリングや、コメントに基づいた実装例の補完など、ピンポイントでの提案力は抜群で、ワークフローの停滞感を減らしてくれます。
- チャットでのコード質問:設計のレビューや「この挙動の理由」という質問には的確に回答してくれますが、最新のトレンドや極めて専門的な知識を問われると、時に一般的な回答に留まることもあります。
- マシンへの負荷:Metal(GPU)が適切に使える状態であれば、負荷は高いものの発熱は許容範囲内です。しかし、前述の通り、メモリの空き状況によって負荷(CPU/GPUの配分)が劇的に変わり、メモリ管理こそが最も重要なファクターだと再認識しました。
============
上記内容について、大きなズレはないかなと思いました。確かにコンテキストが多いと結構時間がかかってしまいますが、短文でのチャットや、ちょっとした Inline Assistant での修正などは、まったく気にならないスピード感です。ただ少し盛り気味で書いてある気がします。
マシンへの負荷もバンバン並行で走らすのは難しいですが、その1つのタスクにおける処理であればスペック的に問題なくやり取りでき、ちゃんと GPU が使われていることもわかりました。
GPU で動いているか確認する
さっき書いてしまいましたが、モデルを pull したら、ollama ps で GPU 推論になっているか確認した方がいいです。CPU 使っているとだいぶもっさりします。
最初に試したときは、何も気にしていなかったので、こんな状態でした。
改善前(重い常駐アプリあり):
PhysMem: 23G used (1862M wired, 10G compressor), 101M unused
$ ollama ps NAME ID SIZE PROCESSOR CONTEXT UNTIL gemma4:e4b c6eb396dbd59 10 GB 100% CPU 4096 4 minutes from now
PROCESSOR が 100% CPU。24GB 中 23GB 使用、空きたったの 101MB。メモリが足りずに GPU に載りきらず、CPU フォールバックしてしまい、簡単な質問の応答に 2分45秒 もかかっていました。
そこで少し整理したところ(そもそも普段からやらないとですが)、、、
改善後:
PhysMem: 21G used (1861M wired, 9124M compressor), 2527M unused
$ ollama ps NAME ID SIZE PROCESSOR CONTEXT UNTIL gemma4:e4b c6eb396dbd59 11 GB 100% GPU 128000 Forever
100% GPU になりました。空きメモリが 101MB → 2.5GB に回復し、GPU でちゃんと推論されるようになっています。
最初に動いたら、何で動いているか、ぜひ気をつけてみてみてください。
まとめ
今回、Zed + Ollama + Gemma 4 でローカル LLM 環境を構築してみました。
Zed は Ollama を公式サポートしているので、settings.json に数行書くだけでローカル LLM を組み込めました。Docker を触ったことがある人なら pull して run する感覚がそのままなので、導入のハードルは想像以上に低かったなと思いました。
先ほども書いてますが、もし何かあって、Claude、Gemini などが使えなくなったときは、私はローカルで悠々と動かすことができるのと、これから軽量モデルで優秀なものが出てきたら、モデル追加して試してみたいなと思いました。感想に書いてあるようなところを書けるなら優秀かなぁと思います。
その際は、使用感として、どんなふうに違うのかなどがを理解し、やりたいことによって使い分けできるといいなと思いました。
