こんにちは、DX開発事業部の山中です。Google Cloud Next ’26 に現地参加しています!
この記事は Google Cloud Next ’26「Context Engineering for Agents」のセッションレポートです。MongoDB の Frank Liu さんが、エージェントのコンテキストウィンドウをどう設計するか、という話を Lightning Talk(20分)でされました。
「プロンプトエンジニアリング」という言葉はすっかり定着しましたが、エージェント時代に求められるのは「コンテキストエンジニアリング」だ、という主張から始まるセッションでした。エージェントは次の行動をコンテキストウィンドウの情報だけをもとに判断します。そこに何を入れ、何を入れないか——この設計がエージェントの性能を左右するという話です。

こんな方におすすめ
- LLMエージェントを開発・運用している方
- RAGの検索精度に悩んでいる方
- マルチエージェントシステムのコストが想定より膨らんでいる方
- KV-Cacheを効率的に活用したい方
登壇者
- Frank Liu(Staff Product Manager, MongoDB AI Research)
コンテキストエンジニアリングとは
Frank さんはセッション冒頭でこう定義されました。
Context engineering is the iterative process of curating exactly the information an agent needs — no more, no less — inside its context window to guide what it does next.
「エージェントが次に何をすべきかを導くために、コンテキストウィンドウに入れる情報を過不足なく整えていく反復プロセス」というものです。
「過不足なく」というのがポイントで、「多ければ良い」わけでも「少なければ良い」わけでもないという話がこの後のデータで裏付けられていきました。
なぜコンテキストが重要か——3つのデータポイント
原則の説明に入る前に、「コンテキストの品質がなぜ重要か」をデータで示すスライドが3枚続きました。
セマンティック検索を入れると全モデルで性能が上がる
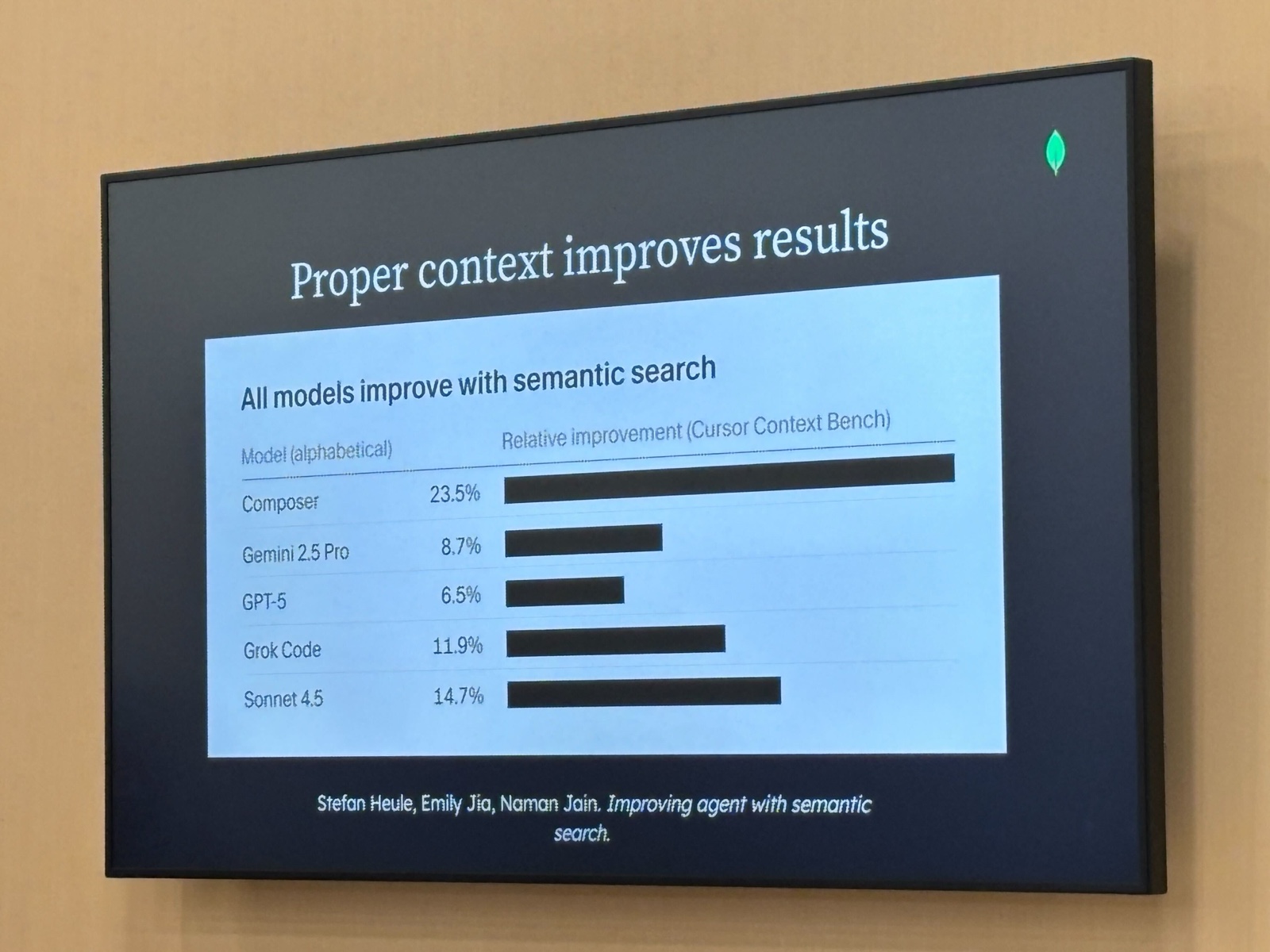
Cursor Context Bench というベンチマークで、セマンティック検索を使った場合の性能改善幅を各モデルで測定した結果です。
| モデル | 改善率 |
|---|---|
| Composer | +23.5% |
| Sonnet 4.5 | +14.7% |
| Grok Code | +11.9% |
| Gemini 2.5 Pro | +8.7% |
| GPT-5 | +6.5% |
測定対象が全て改善している点が、「コンテキストの質を上げることが性能向上につながる」という主張の裏付けになっています。なお「Composer」は Cursor のエージェント機能(Composer モード)で、単体の LLM ではなくシステム全体として測定されているため、改善幅が最も大きくなっている可能性があります。
コンテキストが長くなりすぎると性能が落ちる(Context Rot)
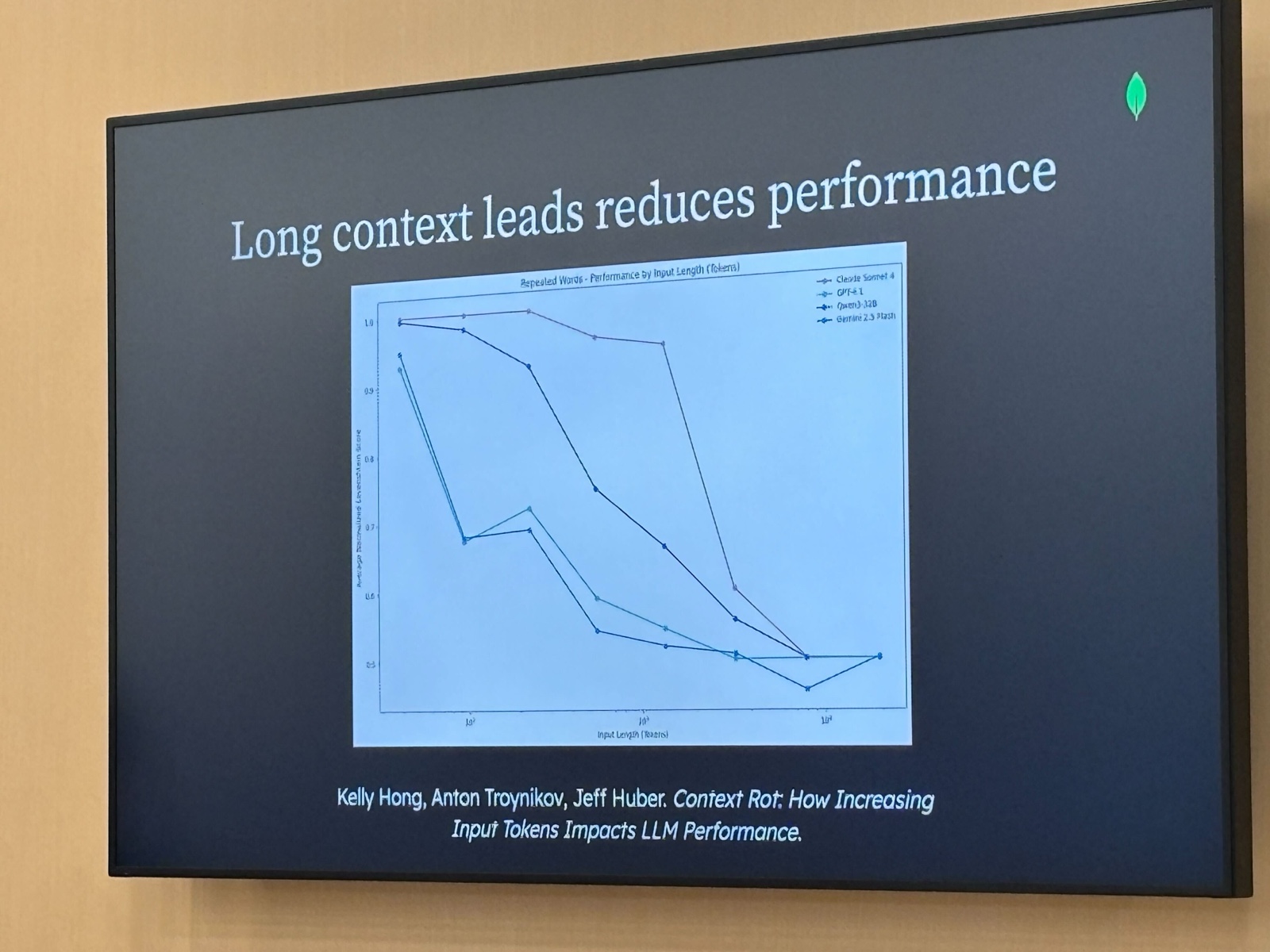
複数モデルを対象に、入力トークン数と性能の関係を測定したグラフです。どのモデルも入力が長くなるにつれて性能が低下し、特に 10^4 トークン付近から急落するモデルもあります。
「Context Rot(コンテキスト腐敗)」という論文のタイトルが引用されていて、コンテキストに古い情報や無関係な情報が蓄積すると性能が落ちていくことを示しています。
マルチエージェントではコンテキストが次々に積み上がる

Agent 1 → Agent 2 → Agent 3 と処理が渡っていく際に、それぞれのコンテキストウィンドウに前段の情報がそのまま引き継がれていく様子の図です。Agent 3 のコンテキストウィンドウには、Agent 1 からの引き継ぎ情報(User Request, Q3 Report, Company Metrics, Date)に加えて Agent 2 が追加した情報(Trend Analysis, Key Insights, Segment Performance)がそのまま入り、さらに Agent 3 自身の出力(Recommendations, Executive Summary, Risks)が加わっています。
前日に私が聴講した「Build multi-agent systems that actually work」でも、マルチエージェントは単一エージェントの3〜10倍のトークンを消費するという話がありましたが、その原因がこの「コンテキストの引き継ぎ」にあることが視覚的に分かります。
「適切なコンテキスト → 性能向上」「過剰なコンテキスト → 性能低下」「マルチエージェントではコンテキストが膨れがち」という3つの問題を整理した上で、Frank さんは5つの原則に入りました。
5つのコンテキストエンジニアリング原則

- RPIフレームワーク(Research, Plan, Implement)を使う
- データ/メモリ層にコンテキストを保存・検索する
- 各ステップの末尾にプランを追加する
- 成功と失敗の両方からエージェントに学ばせる
- LLMの制約を理解する——過去のコンテキストを変えない
原則1: RPIフレームワーク(Research, Plan, Implement)
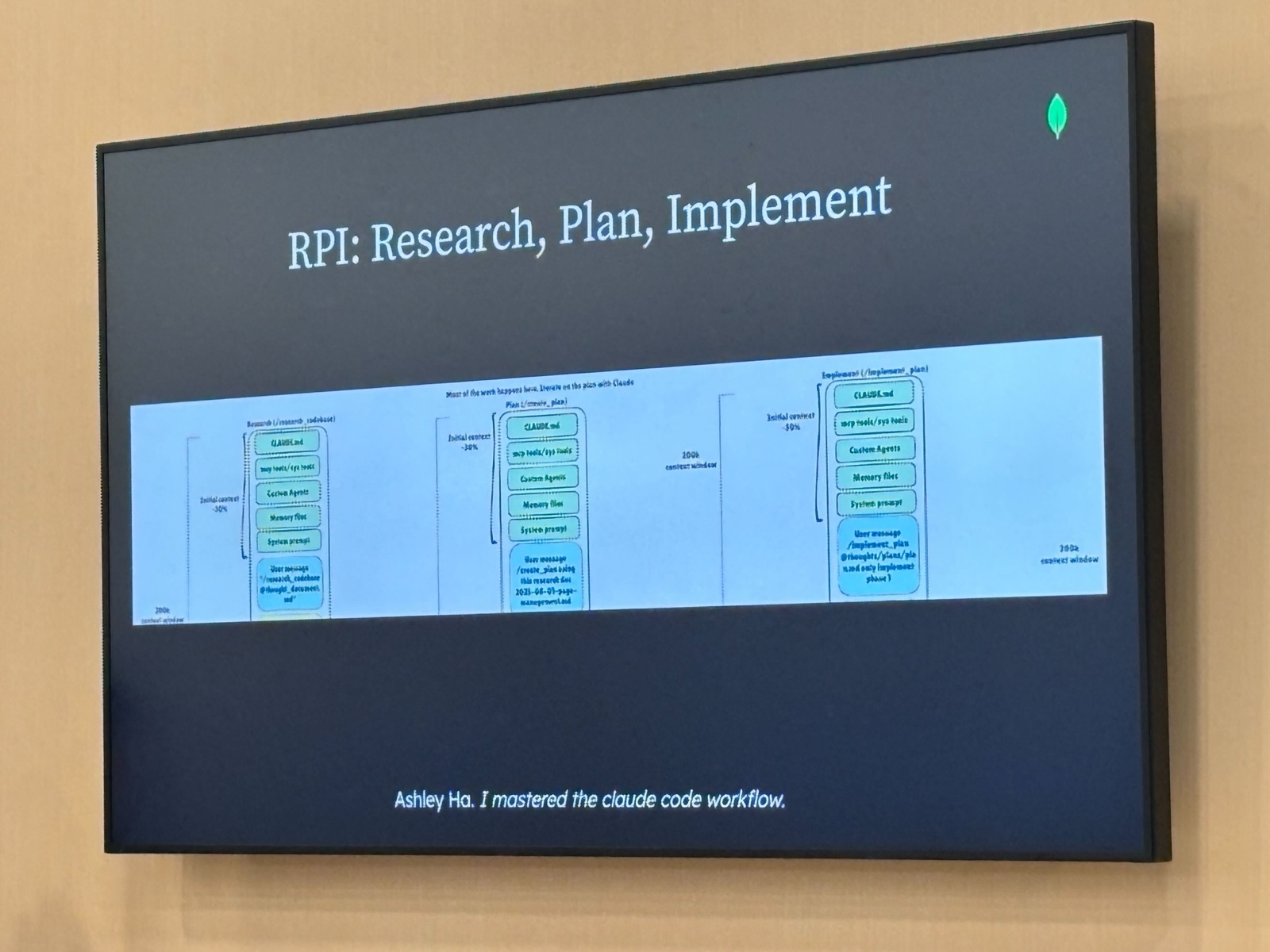
コンテキストウィンドウを「Research」「Plan」「Implement」の3フェーズに分割して使うアプローチです。それぞれ独立したコンテキストウィンドウ(~200k tokens)を持ちます。
- Research フェーズ: CLAUDE.md、MCP ツール、Custom Agents、Memory files、System prompt に加え、ユーザーのリクエストを入力。リサーチ結果を思考ファイルに残す
- Plan フェーズ: Research フェーズの出力(思考ファイル)を元に、新しいコンテキストでプランを作成する。ここでの反復が「Most of the work happens here」と図に書かれているとおり、ほとんどの判断はこのフェーズで行われます
- Implement フェーズ: Plan フェーズで確定したプランをユーザーメッセージで参照しながら実装を進める
この図は Ashley Ha さんの「I mastered the claude code workflow.」という記事から引用されていました。Claude Code の実際のワークフローをそのまま原則として紹介している形です。
フェーズを分けることで、リサーチで積み上がった大量のコンテキストを引き継がずに済み、各フェーズが「自分に必要な情報だけ」で動けるというわけです。
原則2: データ/メモリ層にコンテキストを保存・検索する
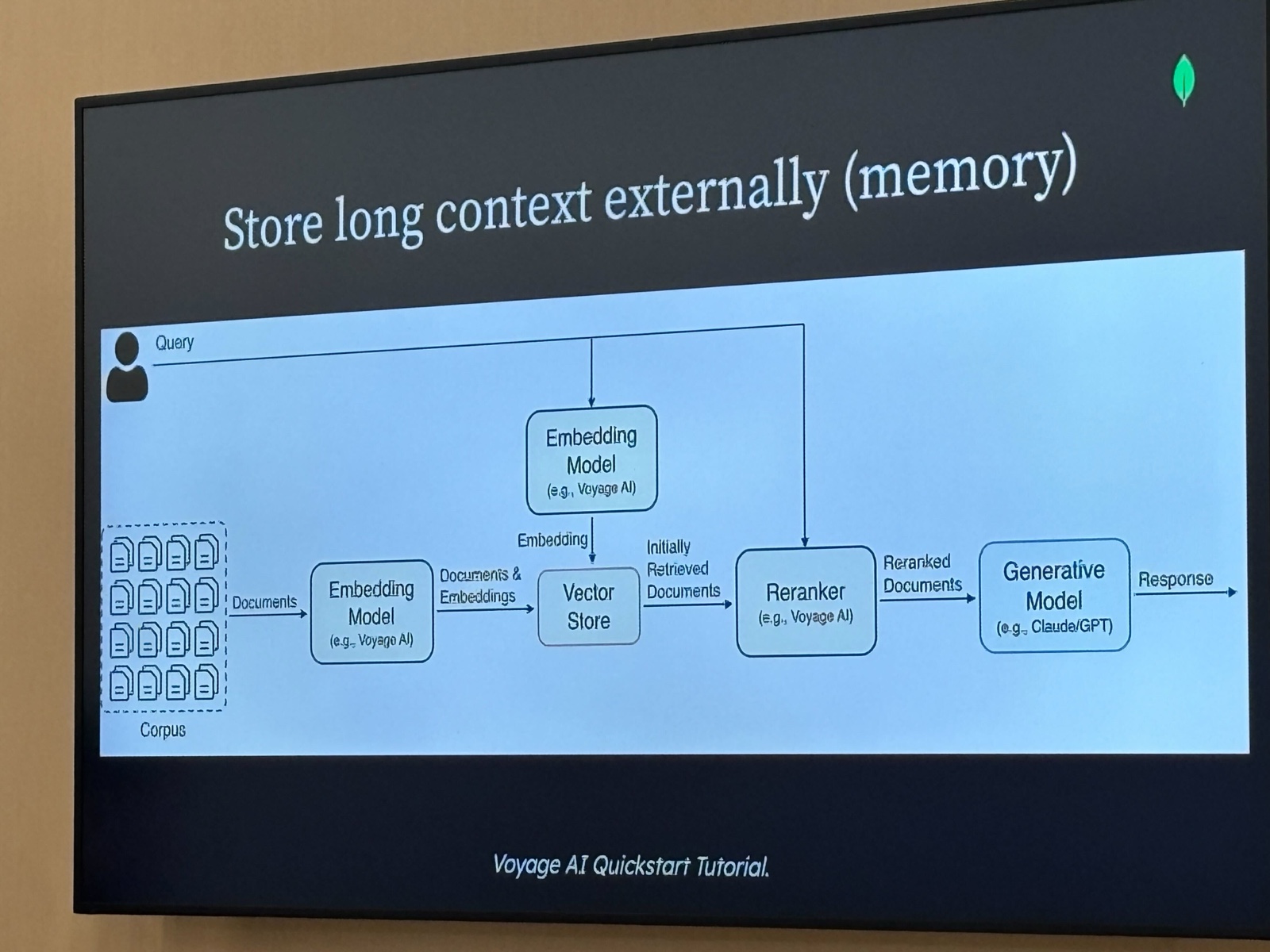
長いコンテキストはモデルのウィンドウ内に持たず、外部ストアに保存してクエリ時に必要な部分だけ取り出す、というRAGのアーキテクチャです。
図の流れはこうなっています。
- ドキュメント群(Corpus)を Embedding Model(Voyage AI)でベクトル化して Vector Store に保存
- クエリが来たら同じ Embedding Model でクエリをベクトル化
- Vector Store から初期検索(Initially Retrieved Documents)を取得
- Reranker(Voyage AI)で再ランキング
- Generative Model(Claude / GPT)に渡して回答生成
「長いコンテキストを詰め込みすぎない」ために、関連する情報だけを動的に取り出す設計です。
原則3: 各ステップの末尾にプランを追加する
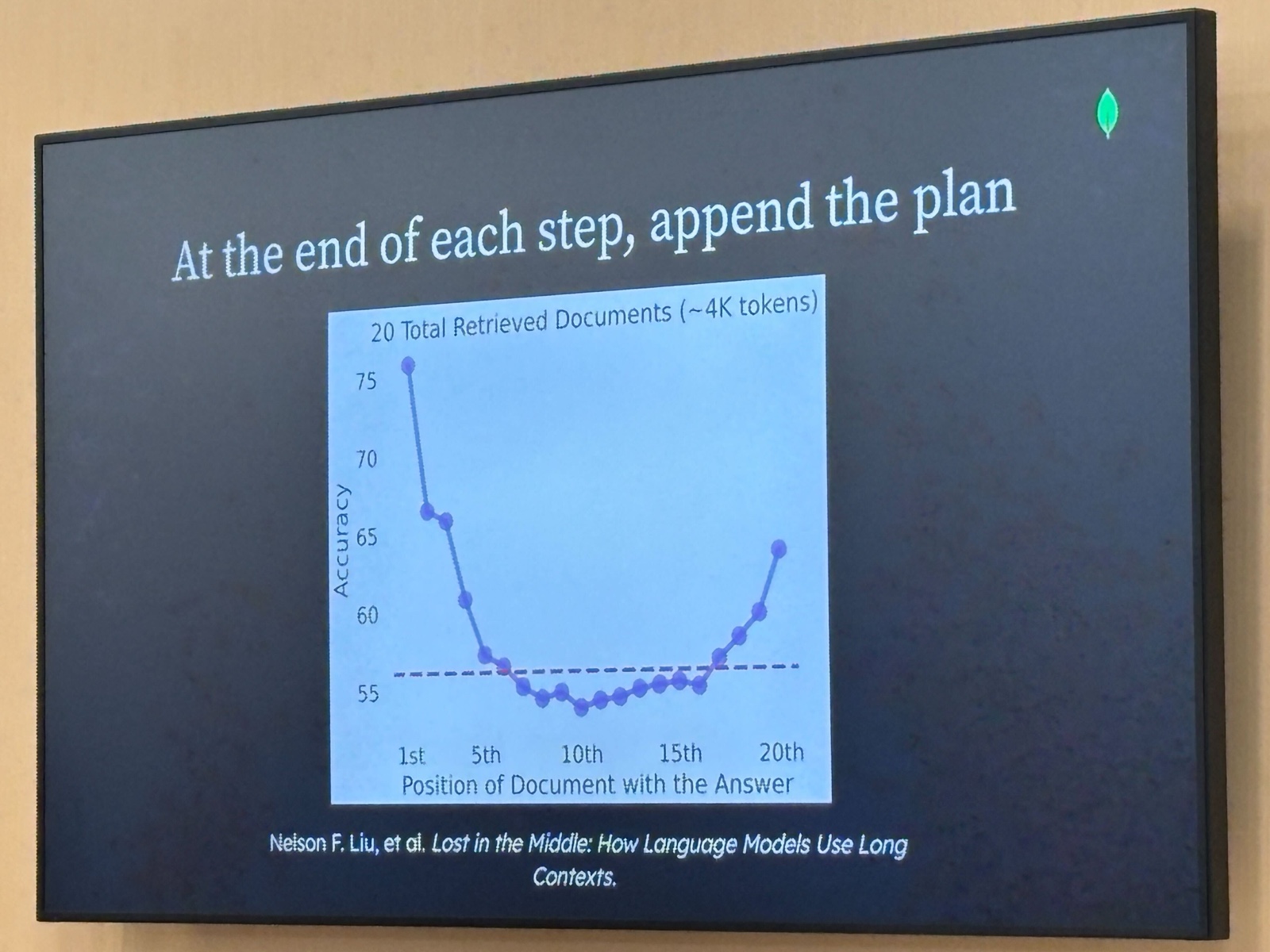
20件のドキュメントを検索してLLMに渡す実験で、「回答が含まれるドキュメントの位置」と「精度」の関係を測定した結果です。グラフが U 字型になっており、先頭(1位)付近で精度 ~75%、末尾(20位)付近で ~65% なのに対して、中間(10〜15位)では ~55% まで落ちています。
これが「Lost in the Middle」と呼ばれる現象で、LLMはコンテキストの先頭と末尾の情報は参照しやすいが、中間の情報はアテンションが届きにくくなります。
この特性を踏まえた設計ルールが「各ステップの末尾にプランを追加する」です。新しいステップで重要な情報(今後の計画)を「末尾に追加(append)」し続けることで、LLMが最も参照しやすい位置に常に最新の計画が置かれます。「途中に挿入する」のではなく「末尾に追加する」という点が重要です。
原則4: 成功と失敗の両方からエージェントに学ばせる

Few-shot learning(インコンテキスト学習)の活用です。スライドにはゼロショット・ワンショット・フューショットの比較が示されていました。
ファインチューニングなしに、コンテキストに「正しい例」と「失敗した例」の両方を含めることで、エージェントが同じミスを繰り返さなくなります。「成功例だけ」でなく「失敗例も含める」という点が、このセッションで強調されていた部分です。
原則5: 過去のコンテキストを変えない——KV-Cacheを設計に組み込む

Manus の開発経験から得られた知見で、KV-Cache の設計に直結する話です。
スライドには「Design Around the KV-Cache」という見出しで2つのパターンが比較されています。
NGパターン(❌): 次のステップで新しいアクション・オブザベーションを、過去のコンテキストの「途中」に挿入する。既存のトークン列が変わるため、挿入した位置以降のKV-Cacheが全てキャッシュミスになる。
OKパターン(✅): 新しいステップの情報は常に「末尾に追加」するだけにする。既存コンテキスト(Instruction → Action 1 → Observation 1 → … → Action 3 → Observation 3)はそのまま保持されるためキャッシュヒット。新たに追加した Action 4 → Observation 4 の部分だけキャッシュミスになる。
「原則3: 末尾にプランを追加する」と同じ「追加(append)」の考え方で、性能とコスト効率の両方を確保できます。コンテキストを書き換えたくなる場面(例:中間の計画を修正したい)があっても、末尾に新しい計画として追加する方が設計上も運用上も優れているということです。
MongoDB & Google Cloud でのコンテキストエンジニアリング
セッションの後半は MongoDB の製品紹介パートでした。「5原則を実装するために MongoDB が何を提供しているか」という構成です。

MongoDB が提供するコンテキスト関連の機能は4つです。
- Vector: ベクトル検索
- Text: テキスト検索
- Embedding: 埋め込みモデル(Voyage AI との統合)
- Reranker: 再ランキング
これらが JSON Document Model 上で動作し、セキュリティ・耐久性・可用性・パフォーマンスの基盤の上に乗るという構造です。
voyage-context-3——エージェント向けに設計されたコンテキストモデル

Voyage AI の voyage-context-3 という埋め込みモデルが紹介されました。
通常のチャンク埋め込みは「そのチャンクの内容だけ」をベクトル化しますが、voyage-context-3 は「Contextualized Chunk Embeddings」という設計で、チャンクレベルの詳細な情報と、ドキュメント全体のハイレベルな情報を1つのベクトルに含めます。図中の説明には「Each vector contains detailed info about chunk and high-level info about the whole document」とあります。
エージェントが長文ドキュメントから特定のチャンクを検索する際に、チャンク単体ではなくドキュメント全体のコンテキストも考慮した検索ができる点がエージェント向けの強みとのことです。
Before/After: MongoDB を使った構成の簡略化
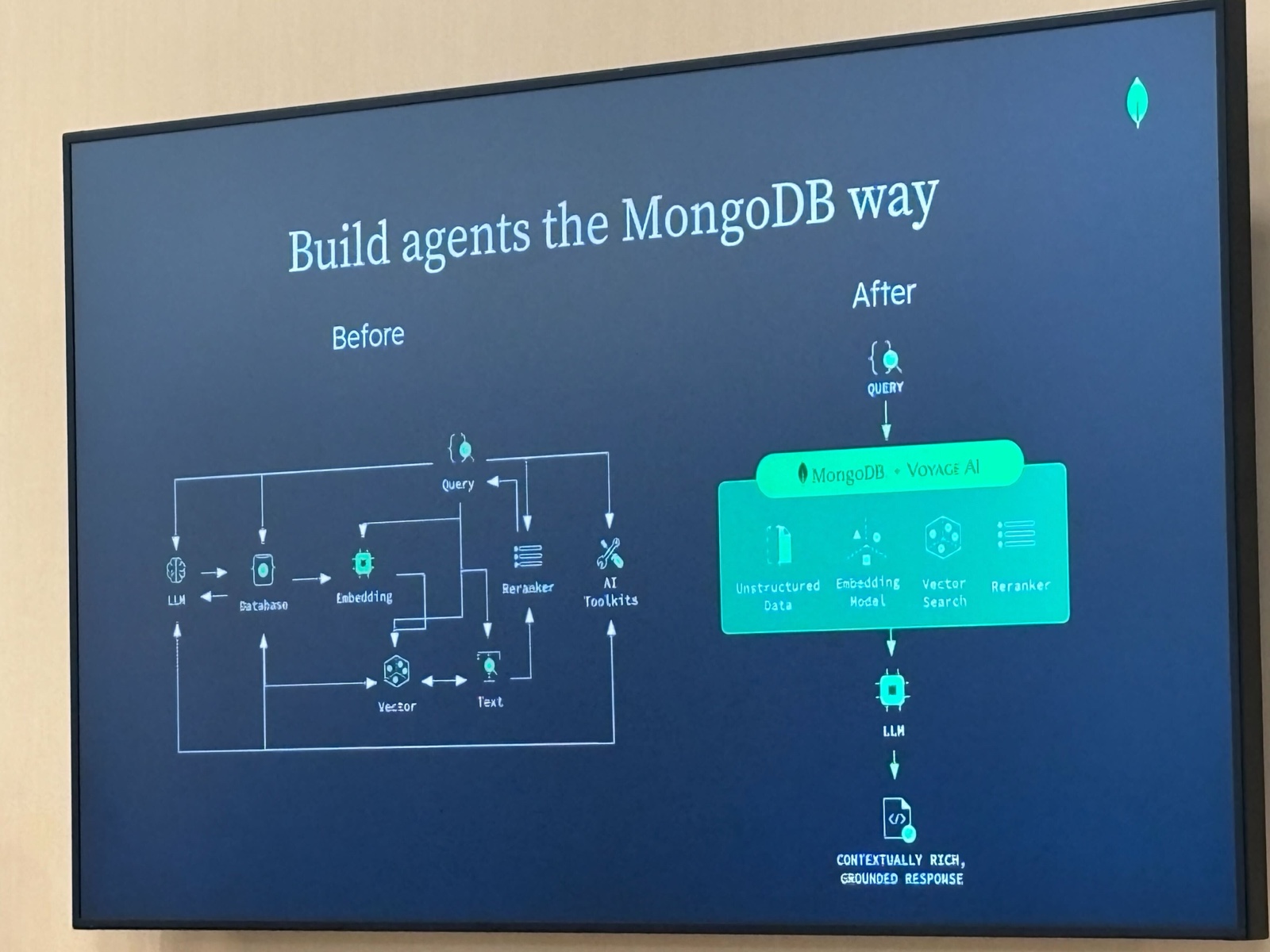
コンテキスト設計の「Before」と「After」が比較されていました。
Before(導入前): LLM、Database、Embedding、Vector、Text、Reranker、AI Toolkits がそれぞれ独立したコンポーネントとして存在し、相互に接続されている複雑なグラフ構造。
After(MongoDB + Voyage AI): クエリ → MongoDB(Unstructured Data、Embedding Model、Vector Search、Reranker を統合)→ LLM → Contextually Rich, Grounded Response という直線的なパイプライン。
インフラ周りの複雑さを MongoDB + Voyage AI に任せることで、アプリケーション側が「コンテキストエンジニアリング」の5原則の実装に集中できる、という締め方でした。
まとめ
Frank Liu さんが20分で整理したコンテキストエンジニアリングの5原則をまとめます。
| 原則 | 要点 |
|---|---|
| 1. RPIフレームワーク | Research → Plan → Implement でコンテキストを分割管理 |
| 2. 外部メモリから検索 | 長いコンテキストは外部ストアに置き、必要な分だけ取り出す |
| 3. 末尾にプランを追加 | LLMは先頭・末尾を参照しやすい(Lost in the Middle対策) |
| 4. 成功・失敗例で学習 | Few-shot でコンテキスト内にパターンを渡す |
| 5. 過去のコンテキストを変えない | KV-Cache のヒット率を保つために追記のみ行う |
全体を通して、「エージェントに渡すコンテキストを意図的に設計する」という当たり前のようで実装時に見落としがちな話が、データで裏付けられていました。特に KV-Cache の設計(原則5)は、コストとレイテンシに直結するので、マルチターンのエージェントを作る際に意識したいところです。




