
セッション情報
- セッション名:Define once, trust everywhere: The semantic layer for governed AI
- 登壇者:
- Miles Betro(Senior Product Manager – GCP Looker and AI Services, Google Cloud)
- Aleks Flexo(Senior Product Manager – GCP Looker, Google Cloud)
- Paul Pritchard(Group CEO, Overdose Digital)
- Ryan Delaney(Chief Experience Officer, Overdose Digital)
先に30秒でまとめ
- 発表されたもの:Looker の LookML セマンティックレイヤーを軸に、Conversational Analytics の精度向上、外部 AI エージェントから呼び出せる Managed MCP hub、BI 体験のフルリニューアルを一気に発表しました。
- 何が変わったか:
- Gemini が SQL を直接書かず Looker API コール経由で動く設計を明確化
- OSS と Managed MCP の両方で Looker のセマンティックモデルを外部エージェントに開放
- Expression / Insight / Visualization Assistant など Gemini ベースの BI アシスタント群が追加
- 具体的に何が嬉しいか:「revenue とは何か」を一度 LookML で定義しておけば、人間も AI エージェントも全員が同じ定義で動くので、ダッシュボードと AI の答えがズレません。
- 一番強い主張 / 目玉機能:「業界唯一のフルスタックでネイティブ統合された AI ファースト BI」と言い切る Managed MCP hub。
- 印象的だった事例:Overdose Digital の Krative。利益(profit)を一次メトリクスに据えて、Looker が変化を検知すると自律的に画像や動画クリエイティブを生成し、Meta などに配信していくループです。
特に注目したい3つの発表
1. LookML × Conversational Analytics ── AI が SQL を自力生成しない設計
Gemini に SQL を書かせず、LookML で定義済みのフィールドとメトリクスを使った Looker API コールを生成させる。LLM の負荷を下げて精度を上げる狙いです。
2. Open BI & Managed MCP hub ── 外部エージェントからセマンティックレイヤーを呼ぶ
OSS と Managed MCP の両方を Looker から提供。外部 AI エージェントが Looker のセマンティックモデルに対して直接クエリしたり、LookML を書いたりできます。
3. Self-service modernization ── BI 体験の刷新と AI アシスタント群
Looker UI のフルリニューアルと、Gemini ベースの3つのアシスタント(Expression / Insight / Visualization)。CSV を上げると LookML が自動生成されてエクスプローラーが立ち上がるデモも披露されました。
本編
セマンティックレイヤーとはなにか、なぜ今重要か

セマンティックレイヤーは、ビジネス用語と生のデータの間にある「翻訳レイヤー」です。仕組みとしては Google Translate に近いものです。「product」「revenue」「customer」といったビジネス用語を、複雑なテーブル構造やカラム名から切り離して定義しておくレイヤーですね。
ここがちょっと面白いポイントで、登壇者は「ガバナンスは人間だけのものじゃない」と何度も繰り返していました。データサイエンティストやアナリスト、エンジニアに加えて、AIエージェントも「信頼できる、よく記述されたデータ」を必要としている。エージェントが SQL を打つ前に「revenue とは何か」を理解できないと、ハルシネーションは止まらないわけです。
revenue ひとつ取ってもこれは深い話で、ある会社では「総売上から返品分を引いたもの」が revenue だったりします。LookML で定義していないと、マーケティングと営業と財務でそれぞれ微妙に違う数字を持ってしまい、経営会議で「なんで数字が合わないの?」と詰められる──というあるあるです。
Looker の LookML はそのエンジン部分です。モジュール型で、コードベースで、Git によるバージョン管理が効く、安全なガバナンス。スライドでは total_profit や customer_age といった measure / dimension の定義例が示されていました。一度定義してしまえば、ダッシュボードでも会話インターフェースでも、外部の AI エージェントからのクエリでも、同じ定義が使われます。

スライド 12 では、LookML、Knowledge Catalog、BigQuery Measures が連動してエージェント向けデータクラウドの統一コンテキストを構成する図が示されていました。LookML が Looker のセマンティックレイヤー、Knowledge Catalog がメタデータの辞書、BigQuery Measures が BigQuery 側のメトリクス定義、という役割分担です。Q&A では「LookML と BigQuery Measures は完全に相互運用できる」「BigQuery Measures を取り込んで LookML にマップしたり、Looker から BigQuery Measures として publish したりできる」と説明されていました。これも Next ’26 での発表項目です。
① LookML × Conversational Analytics ── AI が SQL を自力生成しない設計

ここが個人的に一番なるほどと思ったところです。
Looker の Conversational Analytics では、Gemini が SQL を直接書きません。代わりに、LookML で定義済みのフィールドやメトリクス、結合を使った Looker API コールを生成します。Looker がそれを受け取って、実際の SQL を組み立てて実行する。出力だけ Gemini に戻ってきます。

スライド 15 では、ユーザーの質問が Reasoning Engine に入った後の分岐が図示されていました。BigQuery 側に直結すれば LLM が生成した SQL が BigQuery で実行される。Looker 側に行けば LookML 由来のメトリクスや結合に基づいて Looker が SQL を実行する、という分岐です。Conversational Analytics には Data Canvas(BigQuery 直結)、Looker プラットフォーム経由、Data Studio Pro 経由の3つのサーフェスがあって、BigQuery 直結はアナリストが SQL をレビューして手直しするユースケース向け、Looker 経由はガバナンスが効いた本番ユースケース向け、と使い分けが想定されています。
なぜこの設計にしたのか。具体的には3つの課題があります。

ひとつ目は 相対的な日付フィルタ。「last 30 days」「past six weeks」といったローリングウィンドウは LLM が SQL で正確に生成するのが地味に難しい。Looker には日付処理が組み込み済みなので、API コール側でハンドリングできます。
ふたつ目は 複数カラムにまたがる複雑な結合。複合キーで結合するケースや、結合先のカラム名が違うケースは LLM が苦手です。Looker の Explore には結合が事前定義されているので、LLM はそれを呼ぶだけで済みます。
みっつ目は 複合メトリクス。月次アクティブユーザーや顧客生涯価値、retention rate のような derived table を使うメトリクスは、会社ごとに定義が違うので LLM が空気を読んで再構築するのは無理がある。LookML で定義しておけば、会話側はそのメトリクスを「選ぶ」だけで終わります。
例として登壇者が紹介していたのが「How much revenue was generated by traffic source for accessories in the last 30 days?」という質問。一見シンプルですが、LookML を見ると revenue は「complete かつ返品なし」だけを集計するフィルタ付きメトリクスとして定義されている。生 SQL で sum(revenue) を書くと数字が膨らんでしまうのですが、LookML 経由なら自動でフィルタが効きます。
Q&A でも「raw SQL に対して、LookML のシノニムや description といったメタデータを足していくと精度が有意にステップアップする」という話が出ていました。LLM がコンテキストウィンドウにデータ本体を全部引き込まなくても、メタデータだけで「データが何なのか」を理解できるので、往復回数が減ってエラー修正の頻度も下がる、というのが Miles の説明でした。
② Open BI & Managed MCP hub ── 外部エージェントからセマンティックレイヤーを呼ぶ

Looker が OSS と Managed MCP の両方を提供します。アーキテクチャの柔軟性を最大化する狙いだそうです。
Managed MCP hub では4つのユースケースが挙げられていました。
- Trusted querying:外部 AI クライアントから Looker モデルに対してクエリを実行して、データのインサイトを取得する
- Content creation:自然言語プロンプトで保存済みコンテンツを呼んだり、新しいレポートやダッシュボードを生成したりする
- Instance health:インスタンスの健全性チェック、オブジェクト使用状況の分析、未使用 LookML 要素の検出
- LookML authoring:LookML ファイルの作成と編集。データベーススキーマをコンテキストとして利用できる
スライドでは「業界唯一のフルスタックでネイティブ統合された AI ファースト BI」と言い切っていました。OSS と Managed の両方を出す、というのが Looker の差別化軸らしいです。
③ Self-service modernization ── BI 体験の刷新と AI アシスタント群
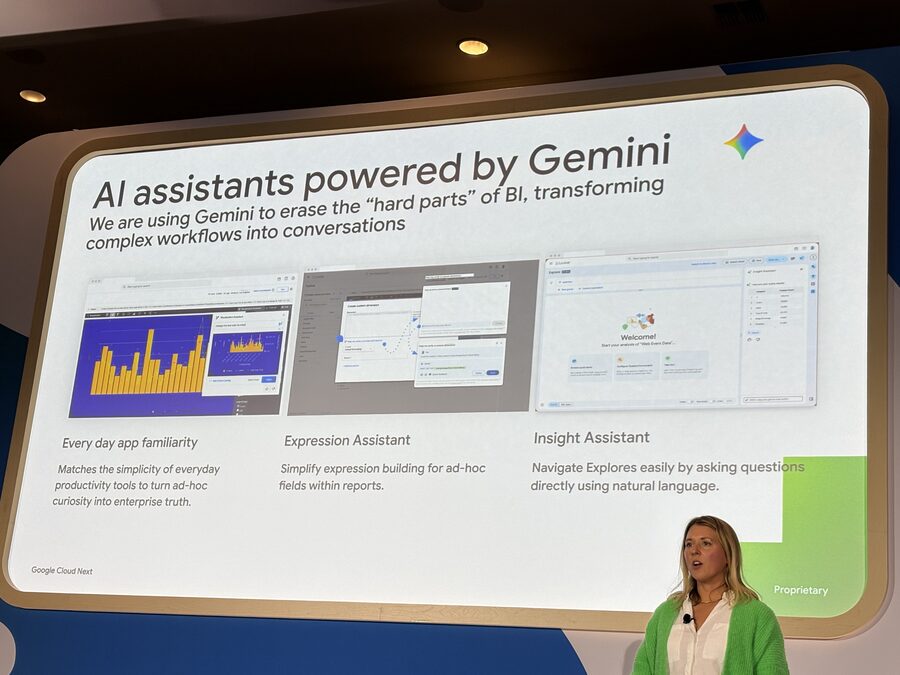
Looker の UI は今、フルリフレッシュ中です。「Google-easy BI experience」というキーワードで、日常使いのプロダクティビティツールに近い操作感を目指している、と説明されていました。レガシー BI に縛られているチームを引き剥がす、という言い方です。

Gemini ベースのアシスタントが3つ追加されます。
- Expression Assistant:レポート内のアドホックフィールドの式を自動生成
- Insight Assistant:自然言語で Explore をナビゲートして、データに直接質問
- Visualization Assistant:カスタムデザインのビジュアルをコーディングなしで生成
デモで一番ウケていたのが、CSV や Excel を Looker にアップロードすると LookML が自動生成されてエクスプローラーが立ち上がる機能。Aleks は CMO から送られてきた NPS の CSV をその場でアップロードして、集計関数を sum から average に変えて、既存のトランザクションデータと合わせた Conversational Analytics エージェントをその場で構築していました。アップロードしたデータは BigQuery のスクラッチスキーマに書き込まれて、最初はアップロードした本人だけがアクセスできるそうです。BigQuery の複数コネクション対応も近いうちに来るとのこと。
ほかにも AI suggested quick starts、ローンチ済みのタブダッシュボード(Tab dashboards)、ページ付きレポート、行制限の拡張なども紹介されていました。
実装事例:Overdose Digital が作った Krative

Overdose Digital は10年続くグローバルなデジタルコマースのコンサルティング会社です。150人以上のコマース専門家が、400以上のマーチャントを支援してきた、と紹介されていました。Group CEO の Paul と Chief Experience Officer の Ryan が登壇しました。
彼らが作ったのが Krative。自律的にハイパーローカライズド広告クリエイティブを生成するエージェントです。アーキテクチャの肝は、LookML で「利益(profit)」を唯一の一次メトリクスとして定義したこと。ROAS や session ではなく、product や category、cohort、city ごとの実利益で判断する。AI は利益にもとづいてのみ動きます。
ループはこんな具合です。Looker が利益のトレンドやクリエイティブ疲労、地域の天候パターンの変化といったパフォーマンストリガーを検知 → Creative Brief Agent や Image Generation Agent などのエージェントが起動 → Imagen や Veo 3 を使って画像や動画、テキストアセットを各アスペクト比で生成 → Meta などに配信、と続きます。配信後はまた Looker がパフォーマンスを取り込んで、creative fatigue パイプラインがキーワードとスコアを更新する。データから洞察、洞察からアクション、アクションから成果のループが閉じています。デモではオーストラリアの家具ブランドの事例として、Sydney 向けと山岳エリア向けで異なるクリエイティブが自動生成されて、季節性(オーストラリアは冬に入る)まで反映されていました。
3人のエンジニアが6ヶ月で構築した、という数字が印象的でした。スリムなチームでも、セマンティックレイヤーが信頼できるとここまで作り込める、という実例ですね。
ステータス表
| 機能名 | ステータス |
|---|---|
| Looker Conversational Analytics | GA |
| Open BI / Managed MCP hub | Preview(詳細未公表) |
| Expression Assistant | Preview(詳細未公表) |
| Insight Assistant | Preview(詳細未公表) |
| Visualization Assistant | Preview(詳細未公表) |
| CSV/Excel データアップロード → LookML 自動生成 | Preview(詳細未公表) |
| タブダッシュボード | GA |
| BigQuery Measures ↔ LookML 相互運用 | 発表(Next ’26) |
おわりに
セマンティックレイヤーの話は、これまで「BIツール内部の最適化」という色が強かったように思います。今回のセッションでクリアになったのは、それが「人と AI エージェントの共通言語」というレイヤーに昇格した、という点です。
日本のエンプラ現場でも「売上の定義が部署ごとに微妙に違う」「営業の数字と財務の数字が合わない」みたいな話はよく聞きます。これまではダッシュボードを直して終わりだったところが、AI エージェントを業務に入れる段になると一気に深刻になります。「売上とは何か」を AI が知らないままに動くと、間違った数字でアクションまで取られてしまうからです。
一度定義しておけば人間も AI も同じ答えを返す ── このシンプルな原則を、Looker は LookML というコードベースの言語で実装しています。Knowledge Catalog や BigQuery Measures との相互運用も含めて、Agentic Data Cloud の中核に座る設計だと感じました。AI エージェントを本気で業務に入れる前に、まず自社のセマンティックレイヤーがどうなっているかを棚卸しする ── そういう順番が、今後ますます当たり前になっていきそうです。




