
はじめに
ある日突然、AWS Backup のダッシュボードに「期限切れ」と表示され、RDS のバックアップジョブが取得できていない状況に気づく——そんな経験はないでしょうか。
このような事象は、RDS インスタンスのストレージ空き容量が逼迫したことによる自動バックアップの長時間化が原因である場合があります。
本記事では、RDS のディスク容量不足 → 自動バックアップの長時間化 → AWS Backup ジョブ期限切れという一連のメカニズムと、その調査・対策を解説します。
発生した事象
AWS Backup のコンソールを確認したところ、RDS のバックアップジョブが「期限切れ」になっていました。
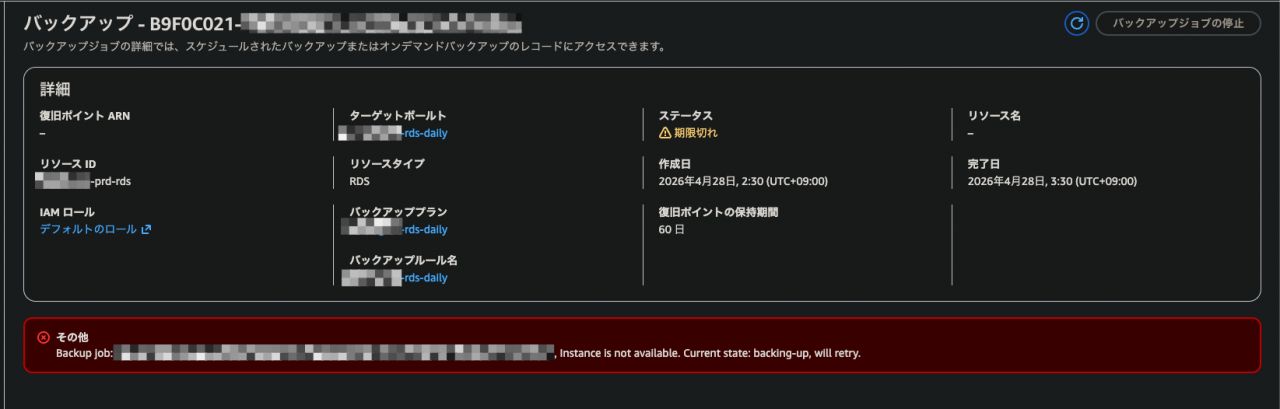
詳細を確認すると、以下のエラーメッセージが記録されていました。
Backup job: xxxxxxxx, Instance is not available. Current state: backing-up, will retry.
このエラーの意味は、「RDS インスタンスがバックアップ実行中(backing-up 状態)のため利用不可能。リトライします。」 というものです。
AWS Backup がリトライを繰り返しているうちに、バックアップウィンドウ(完了までの最大時間)を超えてしまい、ジョブが期限切れになっています。
原因の調査:ストレージ使用率の確認
なぜ RDS の自動バックアップがそれほど長時間かかっているのか、ストレージの状況を確認します。
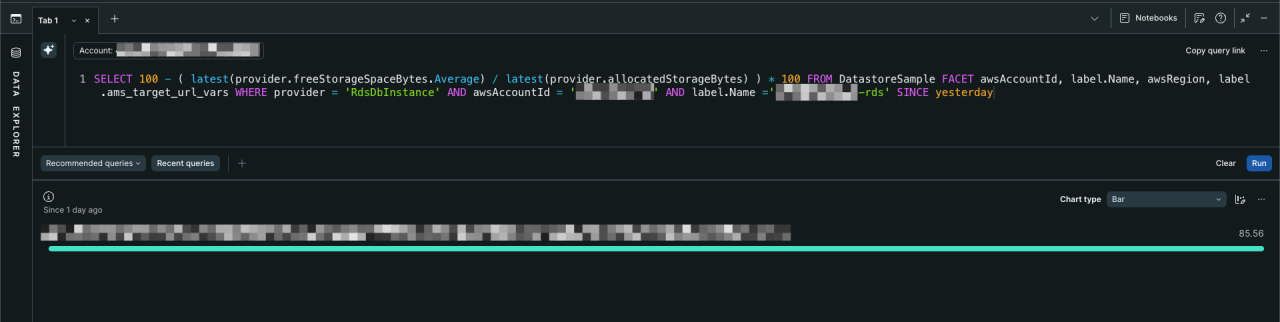
これはNew Relicにて該当RDSの以下のメトリクスを確認しているクエリですが、
ディスク使用率 = 100 - 空き容量 / 割り当て済み容量 * 100
対象の RDS インスタンスのストレージ使用率が 85%超 に達していることが確認できます。
ストレージの空き容量が少ない状態では、バックアップ時の I/O 処理が逼迫し、スナップショット取得に通常よりも大幅に時間がかかります。これが AWS Backup のタイムアウトの直接の引き金になっていました。
問題のメカニズム
以下の流れで問題が連鎖しています。
① RDS インスタンスのストレージ使用率が 85% 超に達する ↓ ② RDS の自動バックアップウィンドウ(深夜帯)が開始 ストレージ逼迫により I/O が飽和し、バックアップ処理が長時間化 → RDS が「backing-up」状態のまま長時間継続 ↓ ③ AWS Backup も同じ時間帯にバックアップジョブを開始 RDS が「backing-up」状態のため "Instance is not available" を返し続ける ↓ ④ AWS Backup がリトライを繰り返すが、 設定したバックアップウィンドウ(最大時間)内に完了しない ↓ ⑤ AWS Backup がジョブを「期限切れ」に遷移させる → その日のバックアップが存在しない状態になる(データ損失リスク)
ポイント:RDS の「backing-up」状態とは
RDS が自動バックアップを実行中の場合、インスタンスは backing-up 状態になります。
この状態では、AWS Backup が新たなスナップショット操作のためにインスタンスにアクセスしようとしても 「利用不可能」として扱われ、完了まで待機またはリトライし続けます。
ストレージが逼迫していると backing-up 状態が通常より長時間続くため、AWS Backup のバックアップウィンドウと衝突しやすくなります。
参考: Managing automated backups – Amazon RDS 公式ドキュメント
AWS Backup のバックアップウィンドウとは
AWS Backup のバックアップルールには「完了までの最大時間」という設定があります。
| 設定項目 | 内容 |
|---|---|
| バックアップウィンドウ開始時刻 | バックアップジョブを開始する時刻 |
| 完了までの最大時間 | ジョブが完了するまでの猶予時間(デフォルト: 8 時間) |
この時間を超えてもバックアップが完了しない場合、ジョブのステータスが「期限切れ」に遷移します。
「期限切れ」になったジョブは バックアップデータを残しません。その日のバックアップは存在しない状態となります。
参考: Backup plan options and configuration – AWS Backup 公式ドキュメント
対策
対策 1(恒久対策):RDS ストレージの拡張・自動スケーリングの有効化
最も直接的な対策です。ストレージを手動で拡張するか、ストレージの自動スケーリングを有効にします。
自動スケーリングを有効にすると、使用率が閾値に近づいた段階で自動的に拡張されます。
RDS コンソール → 対象インスタンス → 変更 → [ストレージの自動スケーリング] を有効化 → 最大ストレージ容量を設定
対策 2(緩和策):AWS Backup のバックアップウィンドウを延長する
バックアップ完了までの時間が長い場合、「完了までの最大時間」を延長することで期限切れを防止できます。
ただしこれは根本解決ではなく、ストレージ対応と合わせて実施してください。
AWS Backup コンソール → バックアッププラン → 対象ルール → 編集 → [完了するまでの最大時間] を延長(例: 1 時間 → 8 時間)
対策 3(監視強化):ストレージ使用率アラームの設定
ストレージの空き容量が一定値を下回った段階でアラートを受け取れるようにします。
CloudWatch や New Relic 等の監視ツールで FreeStorageSpace(または使用率)を監視し、閾値(例: 80% 超)でアラートを設定します。
対策 4(監視強化):AWS Backup ジョブ失敗の通知設定
EventBridge と SNS を使って、バックアップジョブの「期限切れ」「失敗」を即座に検知する仕組みを作ります。
EventBridge ルール: イベントソース: AWS Backup イベントタイプ: Backup Job State Change 状態: EXPIRED / FAILED ターゲット: SNS → メール / Slack 通知
対策まとめ
| 対策 | 種別 | 効果 |
|---|---|---|
| RDS ストレージ拡張 | 恒久対策 | バックアップ遅延の根本解消 |
| ストレージ自動スケーリング有効化 | 恒久対策 | 容量枯渇の自動防止 |
| AWS Backup ウィンドウ延長 | 緩和策 | 遅延中のジョブ期限切れを防止 |
| ストレージ使用率アラーム | 監視強化 | 容量不足の早期発見 |
| EventBridge によるバックアップ失敗通知 | 監視強化 | バックアップ欠損の即時検知 |
よくある誤解
「期限切れになっても RDS のスナップショットは残っている?」
残りません。
「期限切れ」になったジョブは完了していないため、バックアップデータは作成されていません。そのジョブの日のバックアップは存在しない状態となります。
参考: Troubleshooting – AWS Backup 公式ドキュメント
「Multi-AZ なら影響ない?」
Multi-AZ 構成の場合、スナップショットはスタンバイレプリカから取得されるため本番への I/O 影響は軽減されます。ただし、バックアップ処理の長時間化自体は発生します。ストレージ容量の問題は Multi-AZ とは別の軸の問題です。
まとめ
RDS のストレージ容量不足は、単なるディスクの問題にとどまらず、バックアップの欠損というデータ保護上のリスクに直結します。
AWS Backup のジョブが「期限切れ」になっている場合、まずは RDS のストレージ使用率を確認してみてください。
最終的には、以下の 3 点を組み合わせた対策が有効です。
- 根本対策: ストレージの拡張 / 自動スケーリングの有効化
- 緩和策: AWS Backup ウィンドウの延長
- 監視強化: ストレージ使用率アラーム + バックアップ失敗通知
バックアップは「取れていること」だけでなく、「取れているかを確認できる仕組み」があって初めて機能します。定期的な確認体制も合わせて整備することをおすすめします。
以上です。
なお、本記事の内容は執筆時点の情報に基づいています。AWS の仕様は変更される場合がありますので、最新情報は公式ドキュメントを参照してください。

