
こんにちは、セキュリティエンジニアの田所です。
普段、CSIRT の業務の一つとして、CVE の確認や社内共有を行っています。
今回、それらの業務を自動化する仕組みの強化に取り組みました。
人間のレビューを組み込みながらも、生成 AI (LLM) を活用して調査などを省力化しています。
この CSIRT 業務を支援する LLM パイプラインは、Amazon Bedrock 上の Claude と AWS Step Functions で設計しました。
情報源の収集から周知文ドラフトの生成・配信まで、人間のタッチポイントは GitHub Issue でのドラフトレビュー 1 箇所に集約する構成です。
設計を進める中で何度もぶつかったのが、LLM の出力の癖との付き合い方でした。
プロンプトで丁寧に指示を書いても、想定外の出力が返ってくる場面は少なくありません。
プロンプトとコードの両面で強制しないと本番運用には乗らない、ということを実感することになりました。
本記事では、Bedrock + Claude の使いどころ、Anthropic Tool Use と事前 fetch の使い分け、プロンプトキャッシュの設計、LLM の癖と付き合う 3 段階の安全弁を設計判断の事例として共有します。
1. 取り組みの背景
社内 CSIRT では、公開される CVE などの脆弱性情報を集めて、関連度を判定し、社内エンジニアへの展開を通じて対応につなげる業務を担っています。
情報源の選定・関連度判定・周知文ドラフトの作成・配信、と複数のステップがあり、属人化や工数の重さが残る領域でした。
そこで、AWS の Step Functions と Bedrock を用いて、これらのプロセスを支援する LLM パイプラインを設計しました。
モデルは、Claude Sonnet と Haiku を使い分けています。
キーとなる設計方針は次の 2 つです。
- 人間が判断するポイントは GitHub Issue 1 箇所に集約する: レビュー対象を 1 つの場所にまとめれば、見るべき場所が増えない
- 自動化するのはキャッチ・トリアージ・ドラフト・配信の 4 つ: 判断は人間に残す
この方針に沿って、Bedrock + Step Functions + GitHub Actions の組み合わせで実装しています。
2. 全体アーキテクチャ
実装したパイプラインの全体像は次の 4 ステップです。
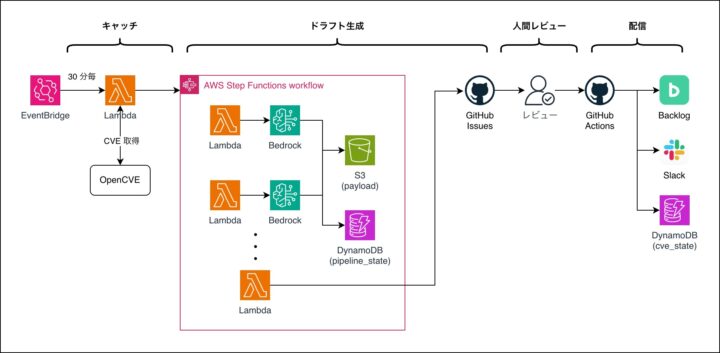
OpenCVE API からスコアや関連度の高いものを取得し、CSIRT のレビュー対象を絞り込んでいます。
使っている主な AWS サービスは次のとおりです。
- ワークフロー: AWS Step Functions / AWS Lambda
- データ連携: Amazon S3 / Amazon DynamoDB
- スケジュール・通知・監視: Amazon EventBridge / AWS Chatbot / Amazon CloudWatch
- 認証・シークレット管理: AWS IAM / AWS Secrets Manager
3. Amazon Bedrock + Claude の使いどころ — モデル使い分け・Tool Use と事前 fetch・プロンプトキャッシュ
今回の構成において、ap-northeast-1 (東京) を主たる AWS リージョンとしています。
Lambda や DynamoDB、S3 などは ap-northeast-1 にあるため、Amazon Bedrock についても、ap-northeast-1 での動作が求められています。
Amazon Bedrock 経由で Claude Sonnet 4.6 と Haiku 4.5 を使っており、ap-northeast-1 と ap-northeast-3 のクロスリージョン推論プロファイル (JP CRIS) で東京を中心に動かしています。
ドラフト生成のワークフローは Step Functions の 6 stage で構成しています。
AcquireLock # CVE 単位のロック取得 (重複処理防止)
→ Research # NVD やベンダー公式 advisory から情報収集
→ Draft # 起票文ドラフトを生成
→ [FactCheck + StyleAudit] # 並列、Tier-1 逐語照合 / 体裁ルール照合
→ Refine # 指摘をもとにドラフトを修正
→ ReVerify # 修正後に再 FactCheck + StyleAudit
→ IssueUpsert # GitHub Issue を起票 or 既存 Issue に追記
→ ReleaseLock # ロック解放
stage 別のモデル使い分け
6 stage 構成のうち、Bedrock を叩く stage は 5 つあります。
それぞれにモデルを割り当てたのが次の表です。
| stage | モデル | 理由 |
|---|---|---|
| Research | Haiku 4.5 | fetch ツールのループ中心、要約は高速かつ低コストで十分 |
| Draft | Sonnet 4.6 | 集めた情報の統合、フォーマットに沿った起票文の組み立て |
| FactCheck | Haiku 4.5 | ルーブリックベースの逐語照合、判定は単純 |
| StyleAudit | Haiku 4.5 | ルール静的照合、ツール不使用 |
| Refine | Sonnet 4.6 | fact-check と style-audit の指摘を統合する判断 |
合成判断や微妙なトーン調整は Sonnet、ルール照合と要約は Haiku、というのが今のところの落とし所です。
Tool Use の使いどころ — 動的呼び出しと事前 fetch の使い分け
Anthropic 公式の web_search / web_fetch (built-in tools) は Bedrock 経由では利用できないため、自前のカスタムツールを用意しました。
Tool Use の使い方は、決定論的に渡せるソースと発見的調査が必要なソースで使い分けています。
決定論的に渡せるソースは事前 fetch + プロンプト注入
CVE 番号から URL が一意に決まるソース (NVD・主要ベンダー advisory) は Tool Use にせず、Lambda handler 側で直接 fetch し、原文を user prompt に埋め込んでいます。
特に fact-check stage は Tier-1 原文を Claude に逐語照合させる用途なので、決定論的に渡す方式が合います。
Tool に任せた場合に起きる「LLM が公式ソースを呼ばずに reasoning だけで判定する」事故が原理的に起きません。
もうひとつのメリットとして、CVE 番号のような ID 文字列の取り違えリスクを下げる効果があります。
LLM のトークナイザは ID や URL のような意味的に独立した文字列を複数のサブトークンに分割するため、文脈に複数の CVE が出てくると、生成時に別の番号と混同する事故が理論的にあり得ます。
handler 側で CVE 番号を直接渡す方式なら、LLM が番号を生成するパスが存在しないため、このリスクが原理的に消えます。
発見的調査が必要な部分は Tool Use として残す
advisory に書かれた references を辿って深掘りする操作 (任意 URL fetch) は、事前にどの URL を取るか決められません。
こういう発見的な調査は Tool Use の柔軟性が活きる場面なので、動的 Tool として残しています。
そして残した動的 Tool には、Anthropic Tool Use の tool_use_log を後段の監視レイヤーとして使う仕組みを併用しています。
ツールを呼んだ形跡がないのに「深掘り済み」を主張してくる、といった LLM の自己申告に振り回されないよう、外形的な事実 (実際にツールを呼んだか) で判定するためです。
「Tool Use は便利だが、決定論的に渡せるものは Tool にせず prompt に入れる、動的探索が必要な部分にだけ Tool Use を使う」というのが、Tool Use まわりで効いた工夫でした。
プロンプトキャッシュの設計 — 1h TTL × 定期ポーリングのローリング
複数の stage で繰り返し参照されるルール定義や参考データをプロンプトキャッシュで再利用しています。
入力トークンを継続的に節約するため、設計上 2 つの工夫を入れています。
1h TTL × 定期ポーリングでローリングしてキャッシュを活かす
プロンプトキャッシュの TTL は 1h を採用し、EventBridge で定期的にポーリングを行います。
「1h TTL > ポーリング間隔」の関係を作ることで、前回ポーリング時に書き込んだキャッシュが次回ポーリングまで生存し続けます。
system prompt 側にのみ cachePoint を置き、固定/可変を明確に分離
cache_control: {"type": "ephemeral", "ttl": "1h"} は system prompt 側にのみ適用し、user メッセージ (CVE 本文や現在日時などの可変部分) は cache 対象外にしています。
固定部分と可変部分の境界を明示的に切ることで、Tool Use ループで Claude と複数回やり取りする間 (同じ Lambda invocation 内) も、system prompt のキャッシュはヒットし続けます。
JP CRIS のクロスリージョン推論
Bedrock の推論プロファイルは、jp.anthropic.claude-sonnet-4-6 と jp.anthropic.claude-haiku-4-5-... (ap-northeast-1 と ap-northeast-3 を束ねた jp.* プレフィックスの JP CRIS profile) を使っています。
東京を中心に運用しつつ、リージョン間で自動的にルーティングされるので、単一リージョン運用よりも高いスループットが得られる構成です。
4. 苦労したポイント — LLM の癖と上手に付き合う設計
Claude を本番運用に乗せていく中で繰り返しぶつかったのが、LLM の出力ブレです。
観察された出力ブレのパターン
| 症状 | 対処 |
|---|---|
| Tool を呼ばずに reasoning だけで判定してくる | Tool 化をやめ、handler 側で事前 fetch して prompt に注入 |
| Claude 自身は「問題なし」と返してくるが、別の自動チェックで要レビューの指摘が出ている | コード側で要レビューに強制上書き |
| 本来出力すべきでない自己コメントが出力に紛れ込む | 出力受け取り側で正規表現フィルタで除去 |
| プロンプトで禁止した表現を出力する | プロンプトに明示の置換ルールを追加 |
| プロンプトで要求したフィールドを返さない | スキーマに default 値を設定して受け取り側で吸収 |
設計原則 — プロンプトとコードの両面で強制する
複数の出力ブレを通じて、痛感した原則があります。
プロンプトの指示だけで Claude を完全に制御することはできない。
なので、重要な不変条件はプロンプトとコードの両面で強制する形にしました。
- プロンプトで「やってほしい」「やってはいけない」を 例示込み で書く
- それでもブレて外れるパターンはコード側で強制的に整形・拒否する
- どちらでも対処できないものは「要レビュー」マークを付けて CSIRT のレビューに上げる
3 段階目の「人間レビューに上げる」が、最終的な安全弁になります。
最初に決めた「人間の判断ポイントを GitHub Issue 1 箇所に集約する」設計が、ここでも効いてくる形です。
このパイプライン全体で Human-in-the-loop が登場する場面は、ここだけです。
CSIRT はドラフトをレビューし、判断結果を返します。
判断はルールで固定する — LLM の選択肢を業務側で縛る
「LLM の判断に委ねず、業務ルールでコードに固定すること」が、もう 1 つの安全弁です。
プロンプトで「適切に判断してください」と書いても、判断のブレは必ず残ります。
特に、複数の選択肢があってどれかを選ぶ場面では、業務として「こう決める」を先に決めてしまう方が、ブレない出力につながります。
具体例として、CVSS スコアの二重評価への対応があります。
同じ CVE でも、ベンダーによって CVSS スコアが異なるケースがあります。
LLM にそのまま渡すと、ドラフト時に片方だけを採用してしまったり、fact-check で「照合に失敗」と判定されたりして、ループにハマることがありました。
それに対して、例えば「高いスコアを優先する」「特定ベンダーのスコアを優先する」「必ず両方記載する」など、判定のルールを決めて、プロンプトとコードの両面で固定しました。
どちらを選ぶかを LLM に任せず、業務として「こう決める」を先に決めておきます。
これによって出力が安定し、ループも収まりました。
まとめ
Amazon Bedrock (Claude モデル) と AWS Step Functions で組んだ、CSIRT 業務支援パイプラインの設計知見を共有しました。
設計の途中で何度も実感したのは、「LLM を信じきって全部任せる」ではなく、「LLM の癖と付き合う設計を組んで、人間レビューを 1 箇所だけ残す」というスタンスでした。
プロンプトとコードの両面で強制し、それでも対処しきれないものは人間に上げる、という 3 段階の安全弁が、本番運用を成り立たせている根本の設計です。
本記事が少しでも皆様の参考になりましたら幸いです。



