
はじめに
運用手順書のレビューをAIに任せたら、こんな返事が返ってきました。
全体として大きな問題はありません。以下の2点のみ修正してください。 - 手順3の説明がやや曖昧です - リンク名を正式名称に合わせてください
一見、まともです。むしろ、ちゃんと見てくれているように見えます。
でも、人間が同じ手順書を見直すと、必須項目の抜け、旧URLのままのリンク、例外時の手順漏れ、テンプレート順序の違いが残っていました。AIが指摘した2点は、4つの重大な漏れの手前にある些末な問題でした。
怖かったのは、AIが間違えたことではありません。見ていない項目があるのに、全部見たような顔で「大きな問題はありません」と返してきた ことでした。
ここで気づきました。AIレビューで本当に危ないのは、誤判定よりも “未確認が見えないこと” だと。
AIに「正しい答え」を出させるのではなく、「正しく確認したこと」を証明させる。それが “根拠カバレッジ” です。
この記事では、その失敗から「根拠カバレッジ」という考え方に至るまでの経緯と、明日からレビュープロンプトの末尾に貼れる最小テンプレを共有します。まだ運用しながら育てている途中なので、つまずいた点と限界もあわせて書きます。
結論
- 「ナレッジをたくさん渡せばAIがうまくやってくれる」は幻想だった。材料が増えるほど結果はブレる。
- 効いたのは「チェックの やり方 」を定義したこと(暗黙の観点 → 具体的なチェック項目への分解)。
- それでもAIは項目を静かに飛ばす。カバレッジ表(全項目を必ず1行ずつ計上)で、すり抜けをほぼ止められた。
- 「該当なし(N/A)には理由を必須」「何と照らしたか(比較先)を列に」「判定を根拠に紐づける(トレーサビリティ)」で、ブレが減り、結果を人に渡せるようになった。
- 体感ベースだが、レビュー結果への差し戻し(「ここ見てないですよね?」)は、カバレッジ表の導入を境に明らかに減った。
- これは「AIに正しくレビューさせる方法」ではなく、「AIが本当に確認したことを、あとから検証できる形にする方法」——いわば AI時代のQA設計 の話です。
以下、ここに至るまでの失敗と打ち手を順番に書きます。
前提:どんなタスクをAIにレビューさせたか
「決まった観点に沿って、ドキュメントや成果物をチェックし、合否と指摘を返す」——コードレビュー、規約準拠チェック、運用手順書の点検。エンジニアの周りには、この形の“定型レビュー”がたくさんあります。
この種のレビューには共通の悩みがあります。観点が多い(必須項目、テンプレ準拠、リンク・参照の妥当性、手順の再現性、表記ルール……)、毎回ぜんぶ人手で見る、そして 見る人によってポイントがブレる。「これは生成AIに任せたい」と考えるのは、自然な流れでした。
失敗①:材料を全部渡せばできると思っていた
当初は楽観していました。判断材料はもう揃っています。スタイルガイド、設計ガイドライン、テンプレート、過去の指摘ログ。これらを全部AIに渡せば、うまくやってくれるだろう、と。
ところが、まったくうまくいきませんでした。同じ対象を渡しても毎回違うことを言う。些末な箇所を細かく指摘する一方で、肝心な観点は見落とす。“惜しい”とすら言えない状態でした。
ここで分かったのは、AIは「材料」は持てても「それをどう使うか」は知らないということです。ナレッジを盛れば賢くなるわけではなく、むしろ材料が増えるほど何を基準にすべきか分からなくなり、ブレが大きくなる。足りなかったのは知識ではなく「照らし方」でした。
打ち手①:チェックの“やり方”をチェックリストとして定義する
腹をくくって、チェックの やり方そのもの を作りにいきました。やったのは3つです。
- 過去の指摘をすべて分析する:実際に「修正してほしい」と返したケースを集めて逆算し、「結局、何を見ていたのか」を実例から抽出する。
- 熟練者の判断を言語化する:無意識に見ているポイントを少数の観点に整理する
(例:①定義どおり実行できるか ②再現性 ③初心者でも迷わないか ④ガイドライン準拠 ⑤ミスしにくい動線)。 - 具体的なチェック項目に落とし込む:観点をカテゴリ(A〜E)× 数十項目に分解し、各項目に「NG例」「どう検出するか」「何に照らすか」をセットで定義する。
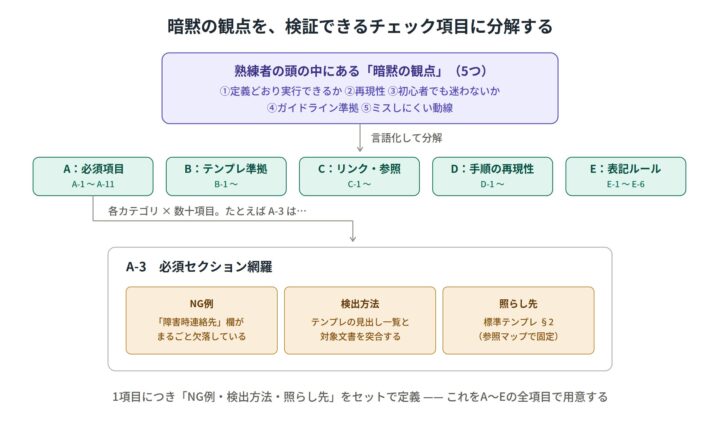
地味に重かったのはここです。観点の言語化と項目への分解には、想像していたよりずっと時間がかかりました。ただし、後続の打ち手はすべてこのチェックリストの上に乗っています。
精度は上がりました。が、ここで冒頭の事件が起きます。
失敗②:それでも、項目を静かに飛ばす(“すり抜け”)
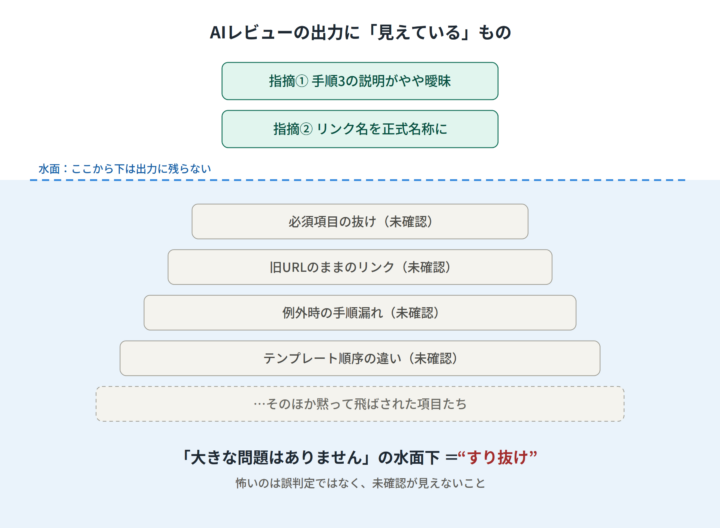
数十項目を渡しても、AIは目立つ項目だけを拾い、残りを黙って飛ばす。しかも出力は「全部見ました」という顔をしている。
人間のレビューなら「ここは見ていないですよね」と突っ込めますが、AIの出力は 抜けが見えません。間違えるよりも厄介です。これを “すり抜け” と呼ぶことにしました。
なぜ起きるのか。
- 数十項目が「参照知識」止まりで、1項目ずつ歩いて合否を出す“強制”がない。なんとなく見て分析する作りだから、黙って飛ばせる。
- 評価したのか/していないのかが 出力に残らない。
- 「見て出さなかった」のか「そもそも見ていない」のか 区別できない。
- トピックが散在していると、目立つ節に注目して埋もれた節を軽視しやすい。
結論は、「全項目をカバレッジ表化(=強制)するのが最も効く」 でした。
打ち手②:カバレッジ表で「見た証拠」を強制する
「きちんと見てください」と頼むのをやめました。代わりに、全項目を1行ずつ並べた表を必ず作らせます。各行に「OK / 要修正 / 該当なし」を付け、表が埋まっていない=まだ終わっていない、と定義します。
イメージは経理の帳簿です。1項目たりとも帳簿から消させません。
問題は「チェック項目が足りないこと」ではなく、「見た証拠が出力に残らないこと」だったわけです。これだけで、すり抜けはかなり止まりました。少なくとも、レビュー結果を受け取った人から「これ、ちゃんと見たんですか?」と聞き返される回数は、体感ではっきり分かるほど減りました。
打ち手③:N/A(該当なし)が最後の逃げ道だった
表を作らせても、完全には消えませんでした。賢いモデルほど「これは該当なし」で項目を消化していくのですが、その中に “見ていないのにN/A” が混ざります。N/Aは、すり抜けの最後の隠れ家でした。
対策は一行のルールです。「該当なしには、なぜ対象外なのか理由を一言そえる」。理由が書けない=まだ見ていない、ということなので炙り出されます。地味ですが、ここで精度がぐっと安定しました。
打ち手④:「比較先」を足したら、結果を人に渡せるようになった
レビュー結果を人に渡すと、必ず「これはなぜ“問題なし”なのか」と疑問が返ってきます。OK/NG は出ていても、何と照らしてそう言えるのかは、確認した本人(この場合はAI)の中にしかありません。根拠が辿れないと、受け取った側がまた一から見直すことになります。
そこで、列をもう一本足しました。「比較先(何と照らして判定したか)」です。
Before
| 項目 | 判定 | 備考 |
|---|---|---|
| B-1 テンプレ準拠 | ⚠ | 要修正 |
| C-1 リンクの遷移先 | ✅ |
After
| 項目 | 判定 | 比較先 | 備考 |
|---|---|---|---|
| B-1 テンプレ準拠 | ⚠ | 📄 標準テンプレ | 該当欄がリンク形式になっていない |
| C-1 リンクの遷移先 | ✅ | 🔗 実在チェック(スクリプト) | 全リンク正常に遷移 |
比較先は一種類ではありません。テンプレと比べた/ガイドラインと比べた/検出ルールで引っかけた/リンクを実際に確かめた/過去のNG例と比べた、と複数あります。だからこの列は、判定の “出どころ地図” になります。説明可能になるうえ、書けない=未照合の炙り出し にもなり、一石二鳥でした。
比較先をブレさせない「参照マップ」
地味に効くのが、比較先をその場の思いつきで決めていない ことです。項目を定義したときに、あわせて「この項目はこの根拠に照らす」という 参照マップ——どのテンプレ/どのガイドライン§/どの検出ルールに当てるか——も用意してあります。だから比較先が人によってブレず、毎回同じ土俵で判定できます。「全部見たか(カバレッジ表)」と「何と照らしたか(比較先)」が安定して回るのは、この “照らし先の地図” が下支えしているからです。
改善後の出力——冒頭の4つの漏れは、こう検出される
改善後の出力は、こんな形になります(カテゴリ名・項目は一般化した例)。
判定の凡例:✅ 準拠 / ⚠ 修正提案あり / – 該当なし
| 項目 | 判定 | 比較先 | 備考 |
|---|---|---|---|
| A-1 連絡経路の記載 | ✅ | 📄連絡先テンプレ | 記載あり・テンプレと整合 |
| A-3 必須セクション網羅 | ⚠ | 📄標準テンプレ §2 | 「障害時連絡先」セクションが欠落 |
| A-9 例外時の明示 | ⚠ | 📘過去NG例集 | リストア失敗時の分岐手順なし(同型のNG例あり) |
| B-1 セクション順序 | ⚠ | 📄標準テンプレ | §3 と §4 が逆順 |
| B-4〜B-6(特定機能まわり) | – | 📋チェックリスト | 対象機能を導入していないため該当なし |
| C-1 リンクの遷移先 | ⚠ | 🔗実在チェック(スクリプト) | 2件が旧ドメインのURL(リダイレクト検出) |
A-1 から E-6 まで 全項目を1行ずつ計上 します(上は ✅/⚠/– を含む代表行の抜粋)。
冒頭でAIが「大きな問題はありません」と素通りした4つの漏れ——必須項目の抜け(A-3)、例外時の手順漏れ(A-9)、テンプレ順序の違い(B-1)、旧URL(C-1)——が、すべて1行ずつ ⚠ として表面に出てきます。「該当なし(–)」には必ず理由が付き、見て出さなかったのか、そもそも見ていないのかが、もう混ざりません。
打ち手⑤:トレーサビリティ(判定 ↔ 根拠の紐づけ)
比較先を書かせるところから、もう一歩進めました。各判定を「根拠」に紐づけて辿れるようにする=トレーサビリティ です。判定ごとに「どのガイドライン/どのテンプレ項目/どの過去NG例/どのリンク確認に基づくか」を結びつけます。
打ち手④(比較先)との違いは、守備範囲です。
たとえば、こういうケースを考えてみてください——リンクの実在チェックはすべて✅で、テンプレ準拠の判定も済んでいる。
ところが、その判定が 旧版のテンプレート に照らして行われていたとしたら。リンクは正しい。判定の手続きも踏んでいる。でも、照らした根拠そのものが古い。比較先の列だけだと「📄 標準テンプレ」と書かれて通ってしまいますが、根拠を「標準テンプレ v2.3 §4」のように版数まで紐づけていれば、版ズレに気づけます。
リンクチェックが守るのは「リンク先が実在し、正しい遷移先か」。
トレーサビリティが守るのは「そもそも正しいルールに照らして判定したか」。守る軸が違うので、“正しそうに見えて実は的外れな判定” を減らせます。
これは品質管理の世界で昔からある考え方です。「どの判定が、どの根拠に支えられているか」を1枚に紐づけて管理しておくと、後から検証も改善もしやすくなります。
つまり、これは「根拠カバレッジ」だった
根拠カバレッジとは——何を見たか・何と比べたか・なぜそう判定したかを、全項目について残すこと。
ここまでの打ち手を一段上から見ると、やっていたことは一つでした。「結果」だけでなく「結果にたどり着いた証拠」を、検証できる成果物として残させる。
ふつうのAIレビューと並べると、違いがはっきりします。
| よくあるAIレビュー | 根拠カバレッジ型レビュー |
|---|---|
| 指摘だけ返す | 全チェック項目を返す |
| 問題のある箇所だけ出る | OK / 要修正 / 該当なし(N/A) が全部出る |
| 見たかどうか分からない | 1項目1行で「確認済み」になる |
| N/Aで黙って逃げられる | N/Aには理由が必須 |
| 判定理由が曖昧 | 比較先・根拠に紐づく |
| 受け取った人が一から再確認 | 受け取った人は結果を“検証”できる |

チェックリスト、ルーブリック、品質保証——どれも昔からある考え方です。ただ、AIに任せるときは少し違う意味を持ちました。人間のためのチェックリストではなく、AIが“見たことにしていないか”を検証するための証拠 になるからです。
なぜ今、AIレビューに「根拠カバレッジ」が必要なのか
AIにレビューや評価を任せる場面が増えるほど、問われることが変わってきます。「AIがそれらしい指摘を出せるか」は、もう論点ではありません。本当の論点は、その指摘を後から検証できるかです。
スコアやコメントだけを見ても、AIがどの項目を確認し、どの項目を飛ばしたのかは分かりません。そして業務レビューでは、間違った指摘よりも、未確認のまま“問題なし”に見えてしまうことのほうが危険です。冒頭の「大きな問題はありません」が、まさにそれでした。
だから必要なのは、AIに正解を祈ることではありません。
確認した項目・比較先・根拠を、検証できる形で残させることです。根拠カバレッジは、AIにレビューを“任せる”ためのテクニックではなく、AIのレビュー結果を“あとから検証できる成果物”に変えるためのQA設計です。
この方法の限界——「表ごと偽装されたら?」に答えておく
ここまで読んで、こう思った方がいるはずです。「N/Aの偽装は理由必須で潰せた。では、✅の偽装は? 表そのものを“埋めたふり”されたら?」
正直に書くと、完全には防げません。できるのは捏造のハードルを上げることです。
根拠の書けない✅は判定として受け取らない(=未確認扱い)。リンク実在確認のように機械で検証できるものはスクリプトの結果を根拠に使い、捏造の余地がない領域を増やす。
つまり根拠カバレッジは「AIを信じるための仕組み」ではなく、「疑うコストを劇的に下げる仕組み」です。
全件再レビューしていた状態から、根拠を辿って抽出検算できる状態へ。人間の関与はゼロにはなりませんが、軽くなります。
自分の業務に導入する4ステップ
考え方が腹落ちしたら、導入は次の順番で進めるのがおすすめです。打ち手①〜⑤を、ゼロから始める人向けの手順に並べ直したものです。
- チェック項目を洗い出す:過去の指摘ログから「結局何を見ていたか」を逆算し、観点→項目に分解する。最初は10項目程度の小さなリストで十分です。完璧なリストを作ってから始めるのではなく、運用しながら育てる前提で小さく始めるほうが続きます。
- 項目にIDを振り、カバレッジ表の形を決める:「1項目=1行、省略禁止」のルールをプロンプトに固定します。IDがあることで「A-3が抜けている」と機械的に指差せるようになります。
- N/Aに理由を必須化する:「書けない=未確認とみなす」の1行を足します。コスト最小で効果が大きい、最初に入れるべきルールです。
- 項目ごとに比較先を決める(参照マップ):「この項目はこのテンプレ/このガイドライン§に照らす」を、項目定義とセットで持ちます。比較先をその場の思いつきにさせないことが、判定のブレを止めます。
ステップ1〜3だけでも、“すり抜け”の大半は止まります。4は、レビュー結果を人に渡す段階になってから足しても遅くありません。
コピペで使えるAIレビュー用プロンプトテンプレ(最小構成)
考え方だけだと再現しづらいので、最小の出力ルールを置いておきます。これをレビュー用プロンプトの末尾に足すだけでも、“すり抜け” はかなり減ります。
# AIレビュー 出力ルール 以下の全チェック項目について、必ず 1項目 = 1行 で表にすること。項目の省略は禁止。 | 項目 | 判定 | 比較先 | 備考 | |------|:----:|--------|------| | A-3 必須セクション網羅 | 要修正 | 📄標準テンプレ v2.3 §2 | 「障害時連絡先」セクションが欠落 | - 判定は OK / 要修正 / 該当なし(N/A) / 未確認 のいずれか。 - 該当なし(N/A) には「なぜ対象外か」を必ず書く。 - 比較先には「何に照らしたか」を、後から辿れる粒度(版数・節番号・ルールID・検出ログなど)まで具体的に書く。 - 比較先が書けない項目は OK にせず「未確認」とする(=まだ確認しきれていない)。
ポイントは、「ちゃんと見て」と頼むのをやめて、「見た証拠を、この形で必ず出せ」と成果物の形を指定すること。完了条件を、モデルの判断に任せず、検証できる出力仕様として固定するのがコツです。
おわりに
「AIにレビューを任せる」と聞くと、賢いモデルへの丸投げを想像しがちです。でも実際に効いたのは、やり方を定義し、見た証拠を強制し、根拠を辿れるようにする——どれも品質管理の世界では古典的で地味な工夫でした。
AIレビューで本当に怖いのは、誤判定そのものより「見ていないのに見たことになる」こと。この構図はレビューに限りません。要約、調査、データ移行——AIに任せるあらゆるタスクで、「完了の定義」をモデルの判断に委ねた瞬間に、同じことが起きます。
だからこそ、AIに正しくやってくれることを期待するだけではなく、正しく確認したかを後から確かめられる形にしておく必要があります。
根拠カバレッジは、AIを信じるための仕組みではありません。
AIを使いながら、必要なところではちゃんと疑えるようにするための仕組みです。
まずは、いま使っているレビュープロンプトに 「比較先」の列を1本足し、該当なし(N/A)には理由を必ず書かせてみてください。 空欄になった場所には、これまで見えなかった未確認が隠れているかもしれません。


