
先日幕張メッセで開催された AWS Summit Japan 2026 に参加してきました!
この記事では、私が印象に残ったセッション「汎用LLMで足りない領域に、どう挑むか」についてレポートします。
Day1で行われた「ヒューマノーム研究所」さんのセッションです。
この講演を聞くまで私は「AI活用」= 「タスクに応じてツールやプロンプトを工夫してAIを使う」ことだと思っていました。モデルを作るなんて、世界規模の大きい会社がやることという認識でした。しかし今回の講演で、モデルを0から作るという選択肢が身近であることを知りました。
「同じモデルを使えば、同じ結果になる」という当たり前の話
講演の冒頭でこんな話がありました。
全員が同じAIモデルを使えば同じ結果になる。そうなると、資本がある大きな会社が勝つ。それでは小さな会社はビジネスにならない。
汎用モデルが学習しているのは、基本的にウェブ上の公開情報です。自社のデータは当然入っていませんし、数値データや時系列グラフのような情報も現時点では十分に含まれていません。もちろんプロンプトや使い方の工夫で変わることはあります。しかし、内包されている知識や技術が同じ以上、大きな出力の差は生まれません。
では、どうすれば差別化できるのか。その答えが「0からモデルを作る」でした。
モデルを作ると決意した理由
モデルを作るには膨大なお金と時間がかかります。ファインチューニングやRAGという選択肢もある中で、なぜ0からモデルを作ることに投資したのか。お話されていた理由は下記でした。
1.業務上、自社のグラフや数値のデータを扱うことが有効であり、汎用LLMのテキスト形式は向いていなかったから。
2.このモデルを作れば、自社の業務領域で世界最高精度を狙えるから。
3.自社が生き残るためにはこれしかない!と考えたから。
モデルを作るのにかかった費用は約2億円だそうです。「世界最高精度を狙える」という判断のもと、約2億円という高額な投資に踏み切れる覚悟がこの会社の強さだと感じました。AIが誰でも使える時代だからこそ、意思決定の差が会社の成長を左右するのだと思います。
9億細胞分のデータを学習させる
業務で扱っているのは生物の細胞データです。このデータを「Excelのシートのような形式」に変換して学習させます。
膨大な数のデータです。確かにこの量のデータがあるにも関わらず、汎用LLMで扱えないのは勿体無いと思いました。プロジェクト開始から学習終了までの半年間で、1億円程度の計算費用がかかったそうです。
驚いたのはモデルの規模感です。できあがったモデルのパラメータ数は3億2600万で、GPT-2相当とのことでした。GPT-2というと、今の最新モデルと比べるとずっと小さいイメージがあります。小さいモデルでうまくいくのか疑問に思いましたが、世界中の雑多なテキストを処理する必要はなく、細胞データだけに特化すれば十分と聞いて納得しました。
AWSエンジニアとの協働
構成図はこちら。GPUが学習するデータはS3に保管されており、FSx for Lustreを高速バッファとして経由させてGPUに供給される構成です。
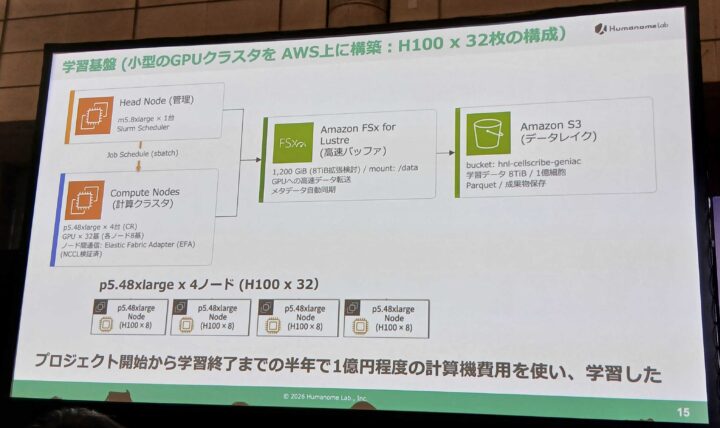
この構成に辿り着くまで、いくつかの課題がありました。
1.ストレージが想定外にいっぱいになった
途中保存のモデルファイルが膨らんで、FSxの容量が枯渇してしまったそうです。AWSエンジニアの提案のもと、S3に保存先を切り替えて解決しました。
2.ログを保存しすぎて学習が止まった
ログの保存頻度が高すぎて、CPUとGPUの同期処理が失敗し、学習が途中で止まってしまったそうです。解決策は「保存するログを絞る」というシンプルなものでした。
これらはAWSのエンジニアが解決したというよりも、一緒に試行錯誤しながら作成したそうです。
「細胞の世界地図」を作ることで、救える命がある
最後にビジョンの説明がありました。
病院や研究機関が持っている細胞データだけでは、量に限界があります。1万人に1人しかかからない希少疾患だと、サンプルが極端に少なく、薬が見つからないことも多いそうです。1人のために薬を作ることは現実的ではなく、治療に難航しています。
そこで、世界中の細胞データを集めて「細胞の世界地図」を作れたらという発想です。どの細胞がどういう状態にあるかを網羅的に把握できれば、「この異常にはこの薬が効くかもしれない」という予測精度が上がり、今は治療法がない希少な疾患に罹っている方の命を救えるかもしれない。このお話を聞いて、このモデル作成の挑戦が世界を変えるのではないかと大きな可能性を感じました。




