
セッションタイトル
AI エージェントのオブザーバビリティ実践

はじめに
先日、AWS Summit Japan 2026 に参加し、「AIエージェントのオブザーバビリティ」をテーマにしたセッションを聞いてきました。未経験でこの業界に飛び込んでから、ちょうど1年。日々の業務で監視に向き合ってきた今だからこそ、このテーマが気になっていました。
私はKDDIアイレットのMSPとして監視運用保守をしています。
今の私はまだ「AIのシステム」を監視しているわけではありません。でも、AIが当たり前に業務へ入ってくるこれからの時代、監視する対象がAIにも広がるのは間違いないと感じています。
本記事は、MSPの現場で1年を過ごした自分が「AIの監視」という次のテーマを学んだ記録として読んでいただけたら嬉しいです。
そもそも「オブザーバビリティ」って?
オブザーバビリティ(可観測性)は、ざっくり言うと「システムの中で今なにが起きているかを、外から見て分かるようにすること」です。
セッションでは、それを支える3つの主要な手がかりが紹介されました。普段の監視でもおなじみのものです。
- ログ:何が起きたかの記録
- メトリクス:数値で見る状態(CPU使用率やリクエスト数など)
- トレース:処理が「どこを通って」進んだかの足あと
なぜ、AIの監視は「今までの監視」と違うのか
ここからが本題で、生成AIの監視は、普段やっているサーバー監視とは質的に違う難しさがある、という話でした。
普通のシステムなら、問題が起きればエラーとして痕跡が残ります。
ところがAIは、一見ちゃんと答えているのに、その中身が間違っていることがあります。エラーは出ていない、見た目は正常、でも答えがデタラメ…そんなことが起こりうる。つまり「エラーが出ていない=正常」とは限らないのです。
その背景として、AIが「生成AI → AIエージェント → エージェンティックAI」と進化し、だんだん人間の監視が少なくて済む(自律的に動く)方向へ向かっているという話もありました。人が逐一見なくなるからこそ、自動で見守るしくみが要る、というわけです。
そのうえでセッションでは、生成AIならではの「特有の課題」が、はっきり4つ挙げられていました。
- AIは推論で動くため、同じ入力でも毎回ちがう動きをする
- 複雑に連鎖する呼び出しの中から、根本原因を追わないといけない
- 生成AIの呼び出しを、専用の観点で収集・分析する必要がある
- 性能(速さなど)だけでなく、応答の「品質」まで含めて健全性を見る必要がある

だから、エラー通知を待つ受け身の監視だけでは足りなくて、こちらから能動的に「中身が大丈夫か」を見に行く必要がある。これがAI監視の出発点でした。あわせて、AIで特に見るべき数値(メトリクス)として、こんな例が挙げられていました。
- トークン使用量:AIが処理する文章の量。入力と出力の量で、コスト(料金)を予測するのに使う
- レイテンシ:リクエストから応答までの時間
- スロットリング:上限(一定時間に処理できる回数)を超えてしまったリクエストの数
- エラー:システム側/ユーザー側のエラー数
データはどう集める? — OpenTelemetryという「共通の形」
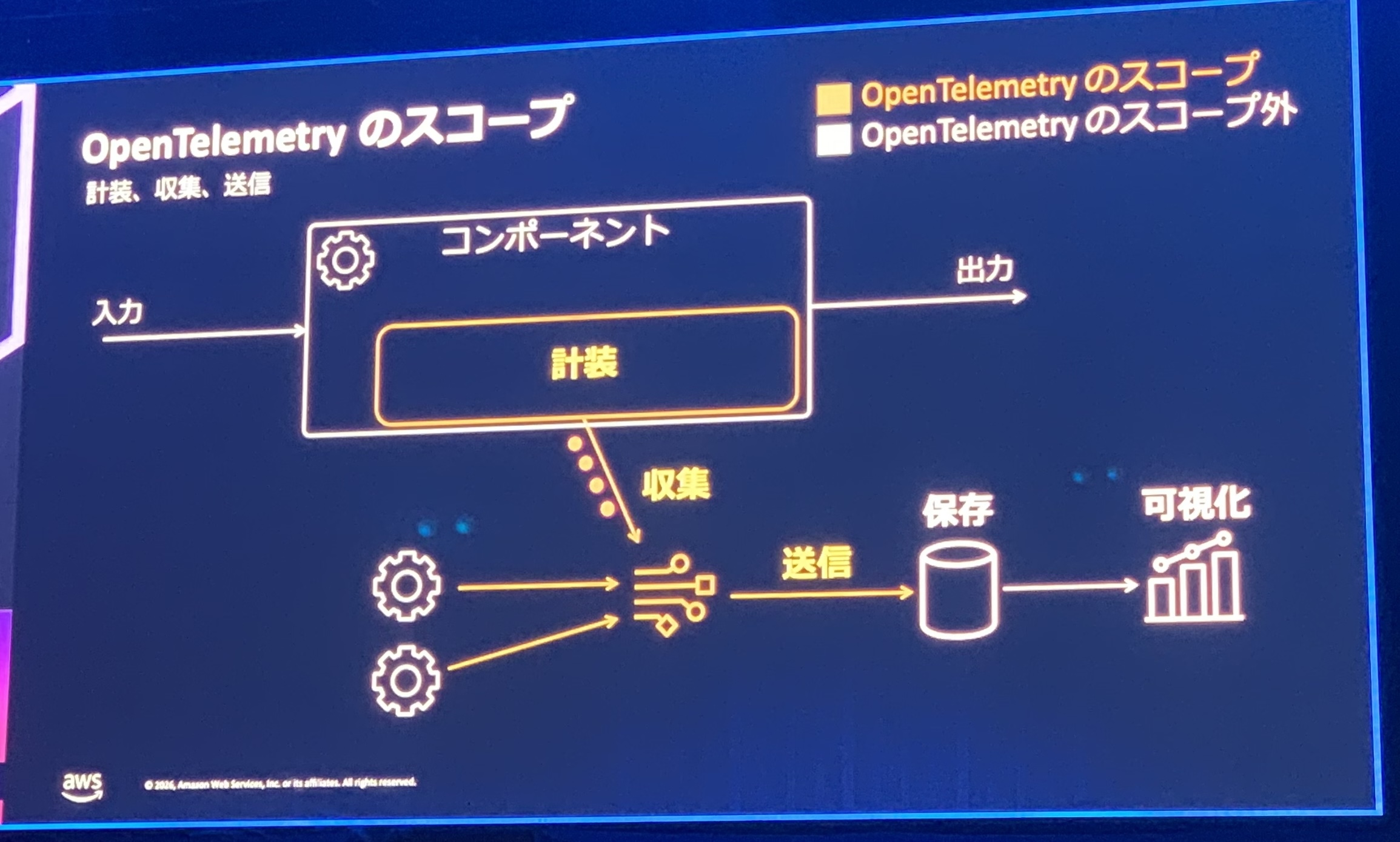
次は「どうやってAIの状態を集めるの?」という話。ここで出てきたのが OpenTelemetry という仕組みです。
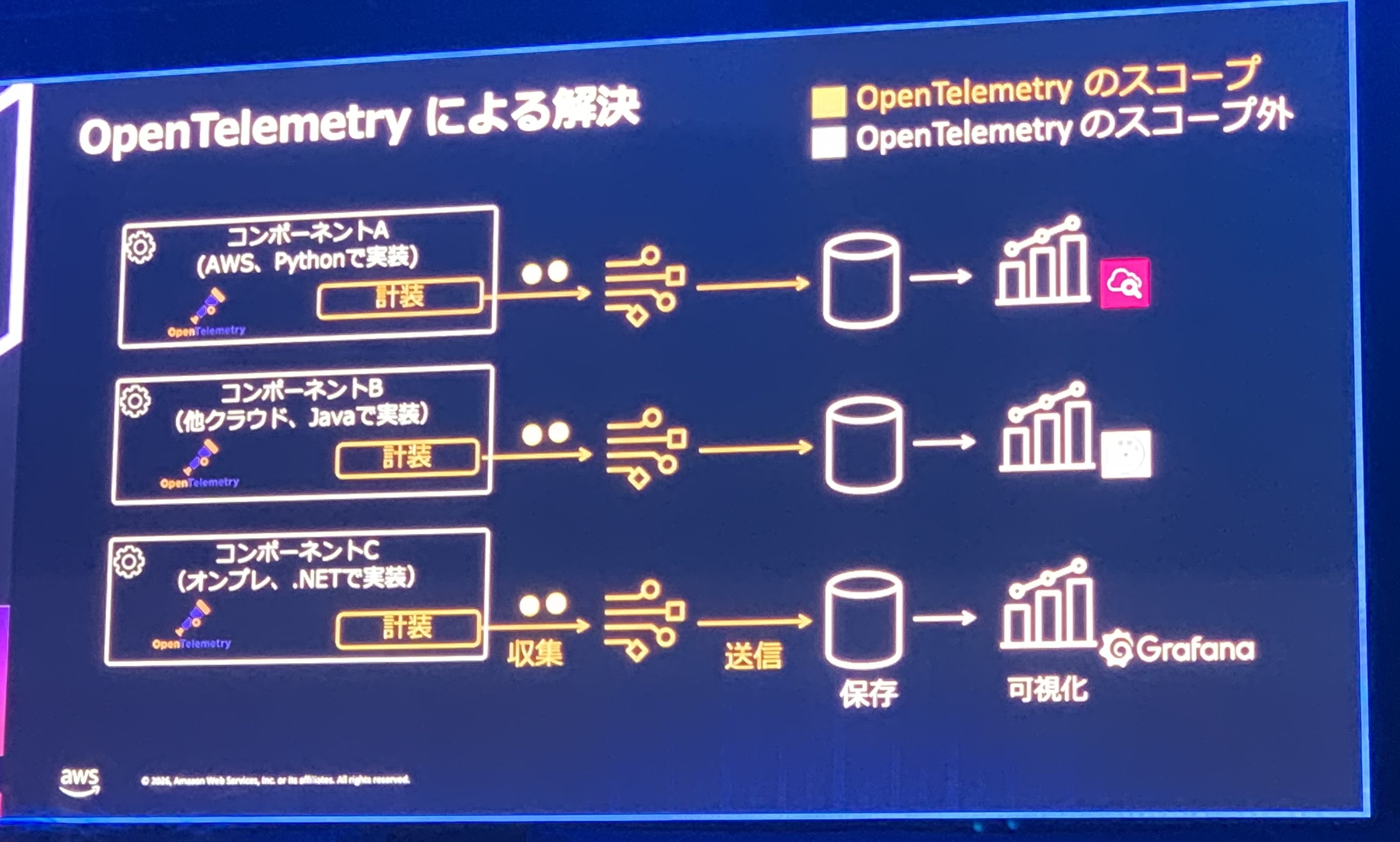
OpenTelemetryは、トレース・メトリクス・ログといったデータを、言語や環境を問わず共通のやり方で「集めて・送り出す」ための、オープンソースの仕組みです。ただし、データの「保存」や「見える化」まではしません。そこはCloudWatchのような監視ツールの役割で、OpenTelemetryはそこへデータを届けるところまでを担当します。
つまり、バラバラな言語・環境のデータをOpenTelemetryで共通の形にそろえてCloudWatchに送り、CloudWatchの画面でまとめて見る、という流れです。送り先のツールを自由に選べる(特定のベンダーに縛られない)のも利点です。
何が見えるの? — 主な3つの機能
集めたデータで、実際に何が見えるのか。主な機能を3つ紹介します。
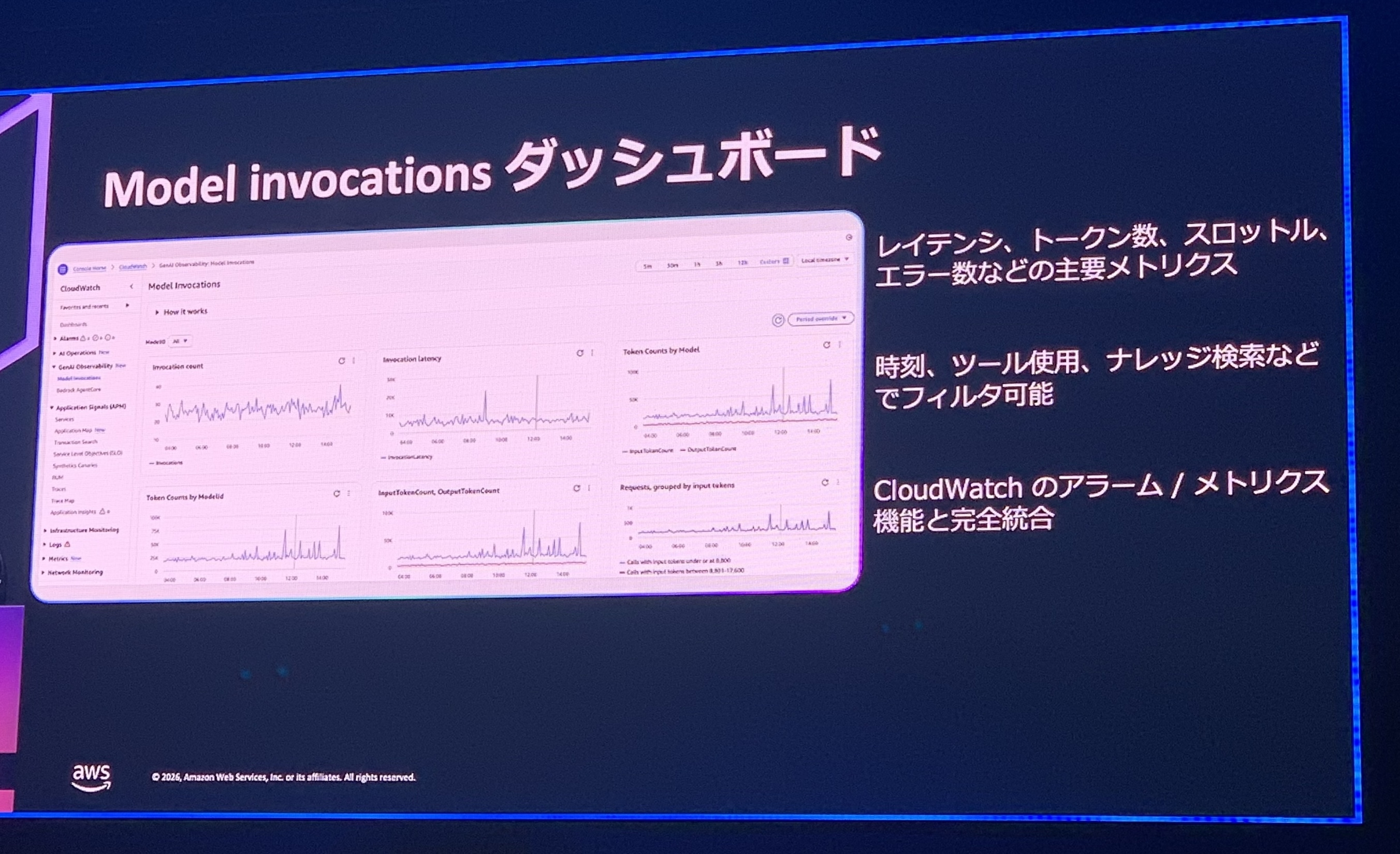
① Model invocations ダッシュボード(数値をまとめて見る)
レイテンシ、トークン数、スロットル、エラー数といったAIの主要な数値を、最初から用意された画面でまとめて見られる機能です。時刻やツールの使用、ナレッジ検索などで絞り込みもでき、CloudWatchのアラート機能ともつながっているので、「しきい値を超えたら通知」も設定できます。
これは、普段監視ツールのダッシュボードでリソースのグラフを見ている自分にとって、いちばんイメージしやすい機能でした。日々ダッシュボードを使っていて価値を感じるのは2つあります。ひとつはリアルタイムで状態が見られること。もうひとつは、まとめて見られることで「影響がどこに出ているか」を推測しやすくなることです。つまりこれは、普段の監視のやり方を、対象をAIに変えてそのまま持ち込めるイメージです。
② トレース(処理の流れを追う)
AIの処理を、入れ子の構造で追える機能です。
- セッション:複数のやり取りをまとめた一連の会話
- トレース:1回の「指示 → 応答」のかたまり
- スパン:トレースの中の1つの作業単位
これによって「どこで時間がかかったか」「どこでエラーが起きたか」をピンポイントで追えます。

③ ログ(入力と出力をそのまま残す)
AIは「同じ質問でも毎回まったく同じ答えとは限らない」性質があります。だから、後から「もう一回試して再現」ができません。そこで、そのときの入力と出力を、ログとしてしっかり残せることが大事になります。
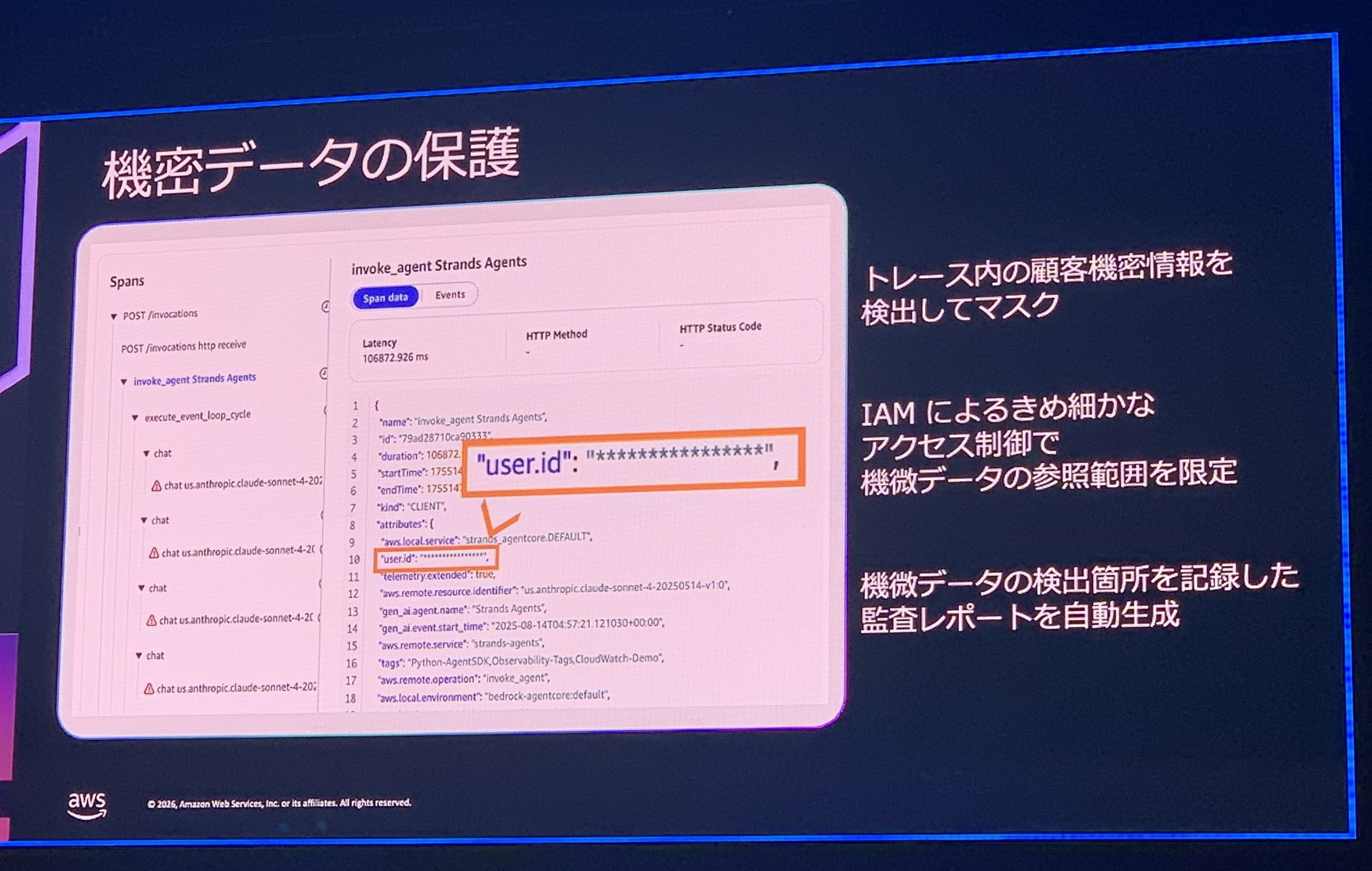
そして特に印象に残ったのが、機密情報の扱いです。セッションでは、トレース内の顧客の機密情報を検出してマスクできること、IAMで参照できる範囲を限定できること、誰が機微なデータを見たかを記録した監査レポートを自動で作れること、が紹介されていました。
「ちゃんと良い答えを返せているか」まで見る — AgentCore Evaluations
エラーが出ない以上、「そもそも良い答えを返せているのか」という品質そのものを見たくなります。それを担うのが Amazon Bedrock AgentCore Evaluations でした。
セッションでは、評価の主な観点として4つが挙げられていました。
- 情報への忠実さ:与えられた情報から外れずに答えているか
- 指示への忠実さ:言われた指示にちゃんと従っているか
- 有用性:相手の期待に応えられているか
- 回答の的確さ:質問に対してズレずに答えているか

あらかじめ14種類の評価役(Evaluator)が用意されていて、自分で評価役を作ることもできます。人が一つひとつ目視でチェックしなくても自動で品質を見続けられて、結果はCloudWatchにまとまって表示されるそうです。
品質の評価は、正直いまの自分の業務からは少し遠い話です。ただ、気にする場面は想像できました。これからはAIを使って分析する場面も増えていくはずで、そこでAIが間違った答えを持ってきていたら、その後の対応が全部崩れてしまいます。だから「動いているか」だけでなく「ちゃんと正しい答えを返せているか」まで見られる仕組みは、これから効いてくるんだろうなと思います。
まとめ — 監視の「次のテーマ」が見えた
セッションのまとめは、とてもシンプルでした。
① OpenTelemetry で計装し、CloudWatch 生成AI オブザーバビリティで挙動を可視化する
② Bedrock AgentCore Evaluations を設定し、AI Agent の品質を継続的に評価する
今回いちばん印象に残ったのは、AIの動きをログに出力できるようになって、これまでブラックボックスだった部分が少しずつ見えるようになってきたことです。しかもそのログを、機密情報はマスクした状態で残せて、必要なときだけIAMで権限を分けてマスク前の中身も確認できます。
これは自分の勉強にも直接つながる話でした。正直なところ、私はまだネットワークやバックエンドの基礎が固まっていなくて、日々の調べ物ではAIにかなり助けてもらっています。そのAIの答えの裏付けになるログがちゃんと残ると分かれば、後から判断するときの材料になりますし、同じことを二度AIに聞き直さずに済むな、とも思いました。
監視の現場で1年やってきて感じたのは、AIの監視はまったくの別物ではなく、今の監視の延長線上にあるということです。ログ・メトリクス・トレースで状態を見て、しきい値で異常に気づいて、原因を切り分ける。その土台は同じで、そこに「中身が正しいか」というAIならではの視点が加わるイメージでした。
これからは、監視の導入まわりの学習も進めていきたいと思っています。OpenTelemetryは実装したことがありませんが、今回学んだようなAIエージェントもうまく使いながら、オブザーバビリティの課題を自分の手で解決していけるようになりたいです。




