
第四開発事業部の西田です。
おはようございます。
3日目2つ目の投稿です。
セッションの空き時間ができたので再度 EXPO に行って初日もらいそびれた SWAG をもらったり、Datadog さんの巨大滑り台を滑ったり、AWS のグッズショップでお土産を買ったりしていました。
お昼は自らもブログ隊として出陣する平野副社長と各部署のブログ隊メンバーで集まって、こちらのお店でランチをいただきながら情報交換を行ないました。
美味しいご飯をいただいて士気も上々で Wynn 会場の DynamoDB のセッションに参加?
セッション内容


セッションのアジェンダ。
- DynamoDB の基礎
- DynamoDB のユニークな側面
- データモデリングのウォークスルー

スピーカーは DynamoDB に関する本も書いてらっしゃいます。
DynamoDB の基礎


DynamoDB の基礎的な知識に関する内容だったので割愛しますが、DynamoDB にとって Primary Key の設計が成功の鍵だというメッセージがありました。
DynamoDB のユニークな側面
パーティショニングは色々なデータベースで実装されているためユニークさではない。
DynamoDB のユニークさは
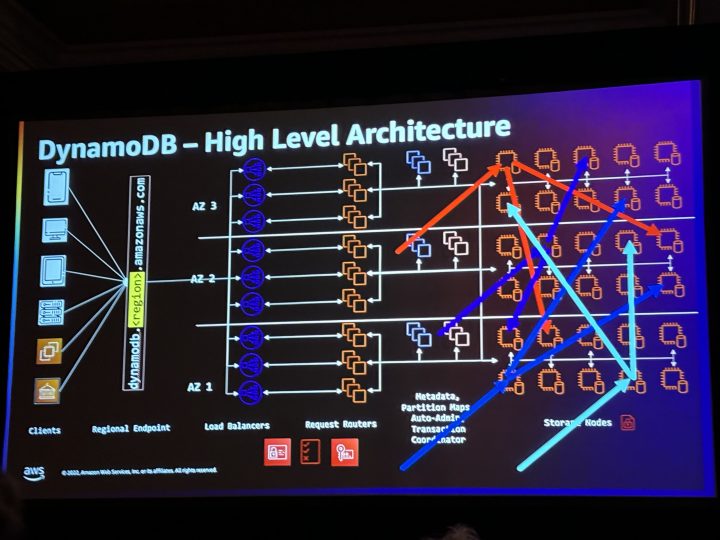
マルチテナントであり。

全てのリクエストがインデックスにヒットすることであり。

デフォルトで結果整合性のある読み込みであり(オプションで常にリーダーノードから読み出すことも可能)。

そして、操作ベースの課金であること。
データモデリングのウォークスルー

モデリングを行なう前に知っておかなければいけないのは
- データへのアクセスパターン
- ドメイン知識
- DynamoDB の基礎
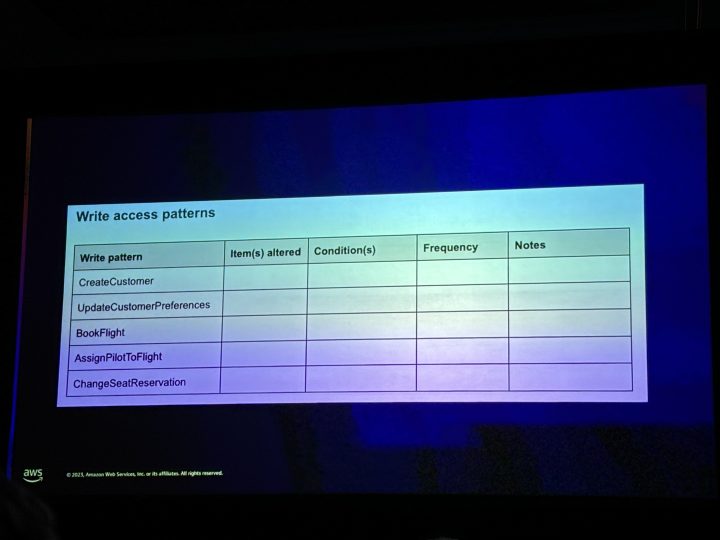
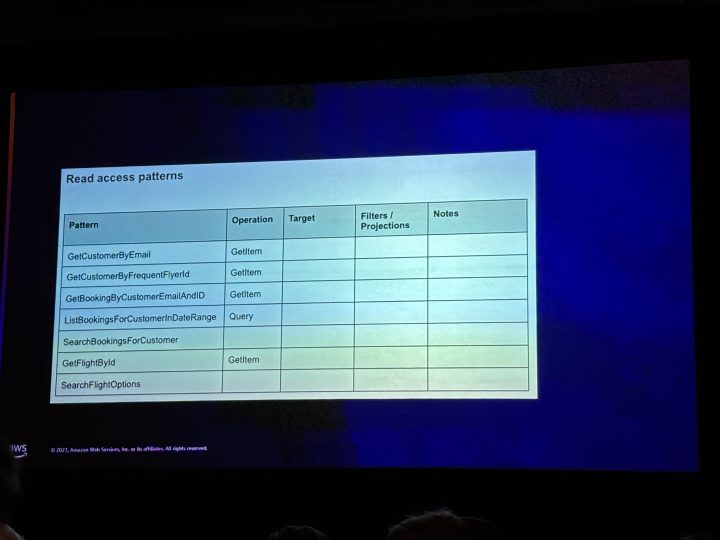
アクセスパターンのマトリクス表を作成し、アクセスパターンを洗い出す。

キャパシティユニットの見積もり計算。

操作と更新対象と条件をまとめる。

書き込み操作で考慮すること。
- ConditionExpressions を使用して制約を付与する。
- 複数のアイテムに対する操作はトランザクションを使用する。
- 長い時間のかかるトランザクションはクライアント再度で実装するか、Step Functions を利用する。
- EventBridge や DynamoDB Streams を使った非同期の更新も検討できる。
複雑なフィルタリング

複雑なフィルタリングに対応することは DynamoDB では難しい。

The Left-Prefix Index Ruleというデータベース設計の手法。
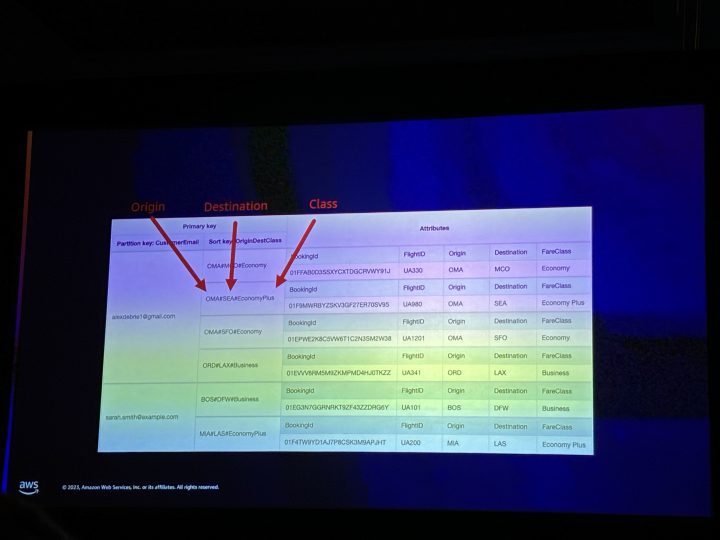
The Left-Prefix Index Rule の DynamoDB への適用例。

複雑なフィルタリングに対応するには
- オーバーフェッチング(過剰な読み込み)やクライアントサイドでのフィルタリング
- データセットが小さい時に限り
- セカンダリインデックスの射影を絞る
- 大きな項目だがフィルタリングの属性が少ない時に適している
- 可能な限り検索スペースを減らす
- フィルタリングに役立つ属性が必要
- 必要に応じて外部システムとの統合を行なう

こんなときは。

素直にこう言った外部のシステムを使いましょう。

外部のシステムとの連携方法(ただしオペレーションが増えることを忘れてはいけない)。
まとめ

感想
会場はほぼ満席で DynamoDB の関心の高さが伺えました。
DynamoDB は業務でもよく使い、個人的に思い入れのあるサービスですが設計で悩むことは多く、いいヒントと出会えるかと思って参加してみました。
アクセスパターンのマトリクス表をまとめるのはいいアイデアだと思いました。
またなんとなく設計パターンとして知っていたものに The Left-Prefix Index Rule という名前があることも初耳でした。
ただ、やはり DynamoDB の大きなつらみである複雑なフィルタリングへの対応を行えるような銀の弾丸は存在しないことが分かりましたね…。

