
はじめに
Falcon LLM モデルという、大規模言語モデルを SageMaker で訓練したセミナーを受けてきたのでその速報となります。
口語の翻訳となるので、多少冗長となるところもあるかと思いますが、
そのあたりは帰国次第修正を随時行なっていくかと思います。
大規模言語モデルをどういったアプローチで訓練し、SageMaker の選択に至ったのかをこの記事で追っていきたいと思います。


前段として:AI technology development and its impact on sustainable development goals.
今年の6月にアラブ首長国連邦初の AI 企業のスピンオフが発表されました。
その企業は Falcon をベースとした開発を行なっています。
テクノロジーイノベーションインスティテュートで私たちが行なっていることは、単に出版物や出版を目的としてその技術を開発するだけではなく、課題を解決したいと考えている研究を行なっています。
そのため、私たちはお客様の世界的な課題に耳を傾け、テクノロジー準備レベルまでテクノロジーを開発することでそれに対処し、その後、それをさまざまなお客様に提供してさまざまなパイロットを実行します。
そして、それをスタートアップ企業としてスピンアウトすることもできますし、事業化してベンチャーとして設立することもできます。
私たちは先進テクノロジーを信じており、それは持続可能な開発目標に大きな影響を与えるでしょう。私たちは、教育、ヘルスケア、AI テクノロジーに焦点を当てた 17 の持続可能な開発を複数持っています。
そして私たちは、オープン サイエンス、オープン 研究、オープン エンド、オープン AI モデルを信じています。
それは公平であるべきであり、誰もがその知識、科学、先進的なモデルにアクセスできるべきです。
一度アクセスできれば、さまざまなセクターにわたる地球規模の課題を解決する高度な技術を開発できるからです。
持続可能な開発目標の下でも、コラボレーションのオープン性もエコロジーを幅広く活用するために重要です。
また、私たちはこれらの高度な成果を達成するインタラクティブ AI を開発および導入する際に、人間の価値観と安全な行動の考慮を保護しています。これははるか昔に始まりました。
なぜ、2022 年 2 月には世界最大のアラビア語 LM モデルも登場するのでしょうか。
大規模な言語モデルとしての Nora の機能について知っていたのは技術コミュニティだけでした。そして私たちはすでにロードマップを持っており、リソースもすでに知っています。私たちは適切な財政投資を行なっており、テクノロジーの進歩に貢献できると信じています。そこで私たちは Falcon のロードマップを設定しました。
これは Falcon 100 ATV のときに開始された段階的な作業ですが、その前に 5 つが確認され、5 つが 1 兆個のトークンでトレーニングされ、サイズはわずか 400 億のパラメータでした。
もちろん、私たちは 3 兆 5,000 億のトークンを使用して、Web 上で 1,800 億のパラメーターをファイルにトレーニングするという旅を続けます。
サイズを拡大することもできます。
そこで、同様のサイズの GBT 3 を使用してモデルをトレーニングしましょうというアイデアが生まれました。
Web データ全体を使用して検索言語モデルをトレーニングすると、当社のデータに遭遇し、データをフィルタリングし、データ パイプラインを構築し、異なるトランスフォーマー用の異なる分散アーキテクチャを使用してすでにトレーニングしています。
Training a large language model for research and commercialization.
そして重要なのは、この基盤を開発すれば、さまざまな顧客やさまざまなビジネス分野向けにさまざまなユースケースを構築できるほどの共通アルゴリズムを構築できるということです。
その一つの例がラベル付けが必要な大量のデータがあるインテリジェントな機械学習アルゴリズムです。
従来の機械学習アルゴリズムをトレーニングするときは、特定のタスクのみを参照していました。ただし、大規模な言語モデルを使用します。
トレーニングが完了すると、同時にラベル付けされていない大量のデータが得られ、複数のタスクを解決できる最高の基礎モデルの 1 つが手に入ります。
テキスト生成から自動化、ShotSpotter への要約、およびさまざまな精神や分野にわたるその他の多くのアプリケーションまでは、もちろんですが、簡単なステップではありません。
旅が始まります。
Training large language models for multilingual capabilities.
最も重要な要素の 1 つはコストです。
しかし、ここであなたが解決しようとしているのは、単に目的以上のものを構築しようとしているのか、それとも、さまざまな開発者のさまざまな研究者がそのモデルを利用してアクセスできるように、最高のモデルの 1 つを構築しようとしているのかどちらかを明確にしなければなりません。
そして、ここで私は 前述のFalcon を紹介します。前にも述べたように、機械学習アプリケーションやそれが破壊するテクノロジーに関係なく、それがビジネスや組織のためであるか、あるいは潜在的な問題を解決するという使命のため、機械学習は使用しません。
ではどうやってやったのかというと、5 つの 400 億パラメータ内でトップの革新的なオープンソースの 1 つを構築しました。
Training a large language model with 100 billion parameters.
これは、Amazon の 384 GPU を使用して 1 つのものとトークンを使用しています。
また、Fico には 1,800 億のパラメーターがあり、3 兆 5,000 億のトークンを使用してトレーニングされています。
また、トレーニングの最後の 1 か月間では、最大 4000 GPU でトレーニングされます。
ここでは、7週間のさまざまなサイクルがあり4 から 1,800 億 のパラメーターがあることがわかります。
それらのすべてで、トランスフォーマーにデコーダー構造を使用しています。
また、この膨大な数のトレーニングトークンを使用してEMSをトレーニングします。
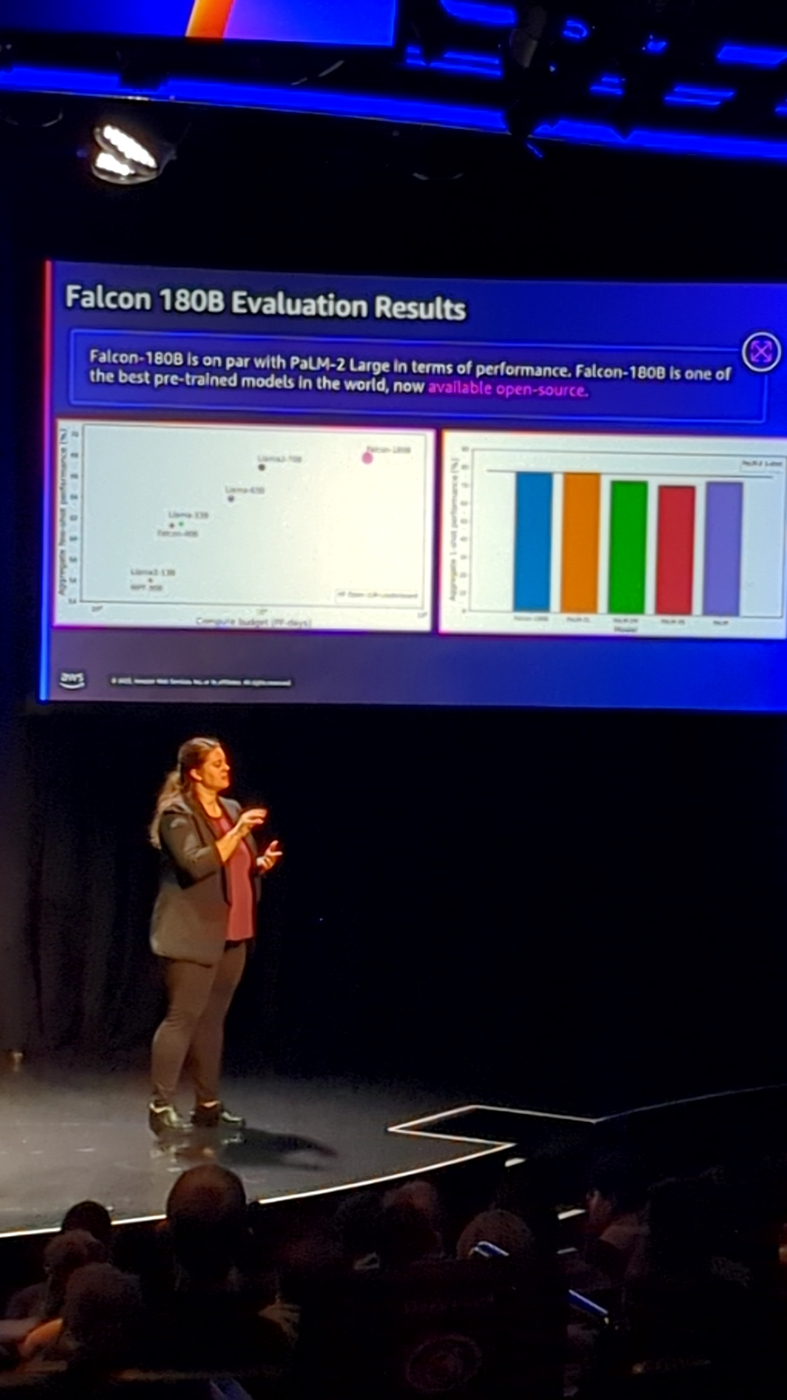
こちらがその表です。
ここで、実際に幅広い機能を備えていること、また推論要件の観点からさまざまなビューの使用が可能であることがわかります。
5 台から 100 台の ATV は AI の責任ある使用を強調するオープン ソース制限の下で利用可能であり、世界で最も強力な LM モデルの 1 つをどのように構築したかを説明します。
前に述べたように、主な基準の 1 つはデータです。 データが修飾されていることを確認し、データ セット内の重複を削除する必要があります。
したがって、考慮する必要がある段階が複数あります。
再トレーニングのコンピューティング バジェットが増えるにつれて、さまざまな段階を経ることになります。
したがって、モデルのサイズを増やすか、トレーニングを長くする必要があります。
そこでまず、最初の段階から始めました。そこではもちろんフィルタリングを実行し、テキストに関して抽出したいものをすべて抽出します。
そのため、テキストに焦点を当てました。
したがってHTML ページからテキストのみを抽出し、170 以上の言語が利用可能な言語識別を抽出します。
英語またはヨーロッパ文字の削除のみに焦点を当てます。

焦点を当てる理由は何故でしょうか?
前に述べたように、大規模な言語モデリングのパフォーマンスに影響を与えたり、パフォーマンスを低下させたりしないことを確認するために、多くの実験を行ないました。
数値としての誤差としては80 ~ 85% の範囲です。
機種にもよりますがデータ的には高画質なものが中心です。
そしてもちろん、キュレーションされたデータから 17 ~ 20 程度の端数が得られ、そのキュレーション データの割合も得られます。
私たちは、ボックスの技術データに対する会話データ セット、さらにデータ セットに埋め込まれている会話とボックスの適切な割合を知るために、多くの実験を行ないました。
私たちが望んでいた LM の多言語スケーラビリティにも確実に対応できるようにするために、私たちは多くの実験を行ないました。
そして最終的には、私たちだけが英語とラテン系ヨーロッパ言語にこだわりたいと決心しました。
あなたが尋ねたい、または検討したいと考えている主な質問の 1 つは、
データのみの場合、フィルタリングとアプリケーションを使用してモデルをトレーニングすることで、自然言語などによって測定されるデータ作成でトレーニングされたモデルよりも優れたパフォーマンスを発揮する可能性があることがわかりました。
Web データ セットの 50% を超える強力なベースラインがすでにある場合、モデルのパフォーマンスが低下し始めることがわかります。 したがって、特に過去に経験がある場合は、データに注意を払う必要があります。
Optimizing AI training with Amazon SageMaker and custom containers.
彼らは高い安定したフロップを維持したいと考えていました。 この部屋にいる技術者以外の人にとって、フロップは基本的に、メトリックまたは尺度、または計算ノードが数学的演算を実行できる速さです。
それは言い換えれば、トレーニング処理の速度と、スケーリング則からの入力に基づいて非常に具体的な計算予算を設定します。
したがって、モデルのサイズ、モデルのパラメーターの数、セットのサイズに基づいて、特定のコンピューティングでそのモデルのトレーニングを終了するかどうかを決定する場合があります。
また、トレーニングには大量のデータが必要なので、ペタバイト規模のデータを効率的に前処理したいと考えていました。
効率的に動作し、時間通りに完了できるクラスターが必要だったので、これも非常に重要でした。
そのデータを同じクラスターに移動できるようにします。
実験の最初の反復では、トレーニングインスタンス は 100 あたり 384 GPU の使用を開始し、規模を拡大する際に 1000 * 100 加算のトレーニングを開始すること、パフォーマンスの一貫性を維持すること、またはパフォーマンスへの影響がそれほど大きくないことを確認したいと考えていました。
つまり、そのスケールが 84 倍から 4000 倍になるのです。
次に私たちは、トレーニング プロセスにおけるパフォーマンスへの影響を軽減したいと考えていました。
もちろん、物事はいつも初めは失敗します。
そして、これが理由となってある計算日数や予算を中断しないように、
できるだけ早くトレーニング プロセスを再開するようにしました。
最適化 ストレージを最適化することで、ストレージが中間に存在し、すべての通信がすべてのノードとストレージ間で行なわれます。
そして、このコミュニケーションはあまり最適化されておらず、効率的でもありません。
これはトレーニング プロセス全体の速度を低下させることになるため、トレーニング プロセスを高速化して最適化するために、ポケットにあるすべてのチェックを確実に活用する必要があります。
このようにして、彼らが現在目にしているすべての課題に基づいて、私たちはシンプルなアプローチに従うことにしました。
そこで、そういった事象に集中し迅速に始めたかったので、Amazon SageMaker を使用することにしました。
トレーニングインスタンスのチームは、HPC クラスターの構築や、これらのインスタンス間の通信と構成を行なうために構成されたすべての基盤となるインスタンスの構成についてあまり気にしたくありませんでした。
そこで彼らは、Amazon Sage Maker をそのために使用することにしました。

次に、コンテナ自体については、カスタム セットアップとカスタム構成を使用してコンテナをゼロから再構築しました。
したがって、分散トレース ライブラリは、すべてのベース コード、すべてのトレーニング、およびストレージ (つまりバックエンド) との通信のすべてを構築して、完全にスクラッチから構築されました。
したがって、データをプルダウンして、s3 からデータを取得する形とします。
そして、モデルの状態を保存するとき (チェックポイントと呼びます)
適時にデータをアップロードします。
彼らは、トレーニングを実現するためにさまざまなプロセスをすべて調整できるカスタム エージェントを構築しました。
そうして、ECR リポジトリからのすべてのコンテナがクリーニング プロセスを開始し、そのトレーニングを監視し、マスターの正常なチェックポイントから必要なトレーニングを再開した障害のあるノードがあるかどうかを確認します。
ここで、トレーニング クラスターについて少し詳しく説明していきたいと思います。
Falcon のトレーニングのために、500 以上 (24 個のスラッシュ インスタンス) からなる sage Maker クラスターを構築しました。
これらの各インスタンスには 8 つの 100 Nvidia GPU チップが搭載されており、単一インスタンス内に 8 つの GPU チップがあります。
これによりスループットの利点が得られました。
それは、100GPU チップのインターコネクトには、同じインスタンス内の他のすべての GPU と毎秒 600 ギガバイトの速度で通信できる スイッチ インターコネクトがあるためです。
また、これらすべてのインスタンスの通信に役立つ エラスティック ファブリック アダプターもあります。
Optimizing machine learning training with AWS. (29:50)
Using AI model Falcon for natural language processing tasks.
結果としてかなりの数のサイレント GPU 障害が発生しました。
ネットワークのタイムアウトが発生し、その他にもクラスターのさまざまな部分で障害が発生しました。
そのため、最初はワシントンの GPU 使用率を低く設定し始めましたが、最終的にすべての問題を検出することはできませんでした。
そのため、私たちは 3 つの次元で考え、、
新しい GPU 使用率、トレーニング、機会損失関数を使用し、ネットワーク インターフェイスからのスループットを調べました。
3 つすべてを組み合わせると、これらのコンテナ間で何かが起こっているかどうかの情報が得られます。
一部のインスタンスでは、GPU の構成が非常に高いことがわかりますが、何も起こっていません。
また、SageMaker ジョブは、私たちがベースとしているジョブの中で最大の時間を費やしており、それが私が構築した理由であるカスタマー エージェントが処理したものであることにも注目する価値がありました。
そのため、ラムダ関数を使用してジョブをデータ損失チェックポイントにチェーンしていました。
そして最後に、バースト性のワークロードに備えるために、s3 バケットとしてスケーリングとパーティション化を行なう必要があります。
つまり、基本的にモデルをトレーニングするときに最も重いタスクの 1 つを実行することになります。
これは、モデルの状態を保存し、チェックポイントを作成して、そのチェックポイントをストレージにアップロードすることです。これは、Falcon のトレーニング結果ですが、
その中には約 4 テラバイトのチェックポイントがありました。
これらは2 時間ごとにチェックポイントを保存していました。
これにネットワーク インターフェイスを通過するトラフィックの量は想像できるでしょう。
ありがたいことに、これらのベストプラクティスはすべて AWS 共通ランタイムに組み込まれています。
したがって、基本的に、AWS SDK の多くを支えるネイティブ ツールとライブラリのセットがあり、自動リクエスト、リクエスト タイムアウトの再試行、および接続リードを実装するネイティブ s3 クライアントも含まれています。
これは、ネットワーク インターフェイスの過負荷を避けるのに役立つため、非常に重要です。
たとえば、再開する必要があるチェックポイントのような非常に大きなオブジェクトがあり、クライアントを使用してこれをダウンロードするとします。
クライアントは、そのファイルの複数のバイト範囲を自動的に並行してダウンロードするため、スループットと使用量が増加します。

ネットワーク インターフェイスを完全に飽和させて、ネットワーク インターフェイスを最大限に活用できるようにします。
また、私たちは数日前に Amazon s3 コネクタを発表したことにも非常に興奮しています。
これは、pytorch コンテナがある場合に発生するこれらのタスクの多くを支援し、最適化するものでもあります。
つまり、トレーニング ジョブの一部にチェックポイントを設定します。
内部ストレージに送信してから s3 にアップロードするのではなく、S3に直接実行されるようになりました。
確認すると、最大 40% または最大 40% 高速になっているようです!

アーキテクチャや基礎的な部分をカバーするだけでなく、AI がモデルのパフォーマンスと精度をどのように評価したかを理解することが非常に重要です。
つまりはモデルの評価は、機械学習モデルのトレーニングにおいて非常に重要な部分です。
モデルがどれほど優れているかを理解するために人間による評価も行ないました。
モデルの技術的な部分だけでなく、モデルがどれほど倫理的に健全であるかを評価する必要があったため、これは非常に重要です。
そこで、ここでは非常にシンプルなアーキテクチャを構築し、Slack チャネルを活用しました。 そこで何が起こっていたかというと、私たちはエンドポイントを使用してバックグラウンドでモデルをホストし、毎日モデルにリクエストを送信し、レスポンスを生成し、Slack チャネルに送信し、TI インタビュー チームの数人にも調査してもらいました。
いくつかの応答を評価し、それらを評価します。
そこで私たちはそれらを 1 から 5 まで再トレーニングし、それが適切であるか、捏造されているかどうかも確認します。 つまり、それは評価プロセスの非常に重要な部分でした。
最後にこれらは、
Falcon をトレーニングするために TI と AWS の間で行なわれたコラボレーションを要約したものです。
ご清聴ありがとうございました。

