
セッションタイトル: Build highly scalable generative AI apps with Vector Search and RAG
スピーカー: Arindam Bhattacharya, Josh Goldenberg, Clarence Kwei, Eran Lewis
この記事は?
今何かと話題のRAGシステム。
そんなRAGをGoogle CloudのVertex AI Searchを使って、どうやって作るんだね?というセッションの内容まとめです。
エンタプライズとしてのRAGパイプラインについてもお話がありました。
早速セッション本編です
そもそも検索と生成AIは一緒に使われがちだね?
最近、よくRAGシステムという名前をよく耳にしますよね。
そして、RAGでよく使われるのが検索RAG。
そもそも、元来の検索と生成AIは相性がよく、お互いがお互いを強化してくれます。
メリットを一言で言うと、検索と要約・複雑なクエリ処理を素早く改善することができるようになったから。
左側:
「検索が生成AIによって強化される」
生成AIは、要約・複雑なクエリ処理を迅速に改善してくれる!
右側:
「生成AIが検索によって強化される」
RAGはエンタープライズアプリでLLMを使用する際には、もはや不可欠!
じゃあRAGはどのユースケースに使ってるんだろう?

上記画像の緑部分がRAGです。
顧客向け
– マーケティング
– Webサイトを最新へ
– 顧客サービスを最新へ
社内ユーザ向け
– 社内ナレッジ共有
– 開発の効率化
情報を貯めて、人間の言語で欲しい情報を取り出すってことですね。
他には、貯めた情報をもとにマーケティングしていこうよ。というところでしょうか。(レコメンド系ですね)
生成AIを使うと向上したこと
AIとカスタマーサービス機能の連携することで、生産性を30~45%向上させる。
一般的なAIは、人的コストを50%削減する。

おかげで我々人間は、もっとクリエイティブな仕事をできるってわけですね。
でもAIアプリケーションの構築って複雑じゃないか…
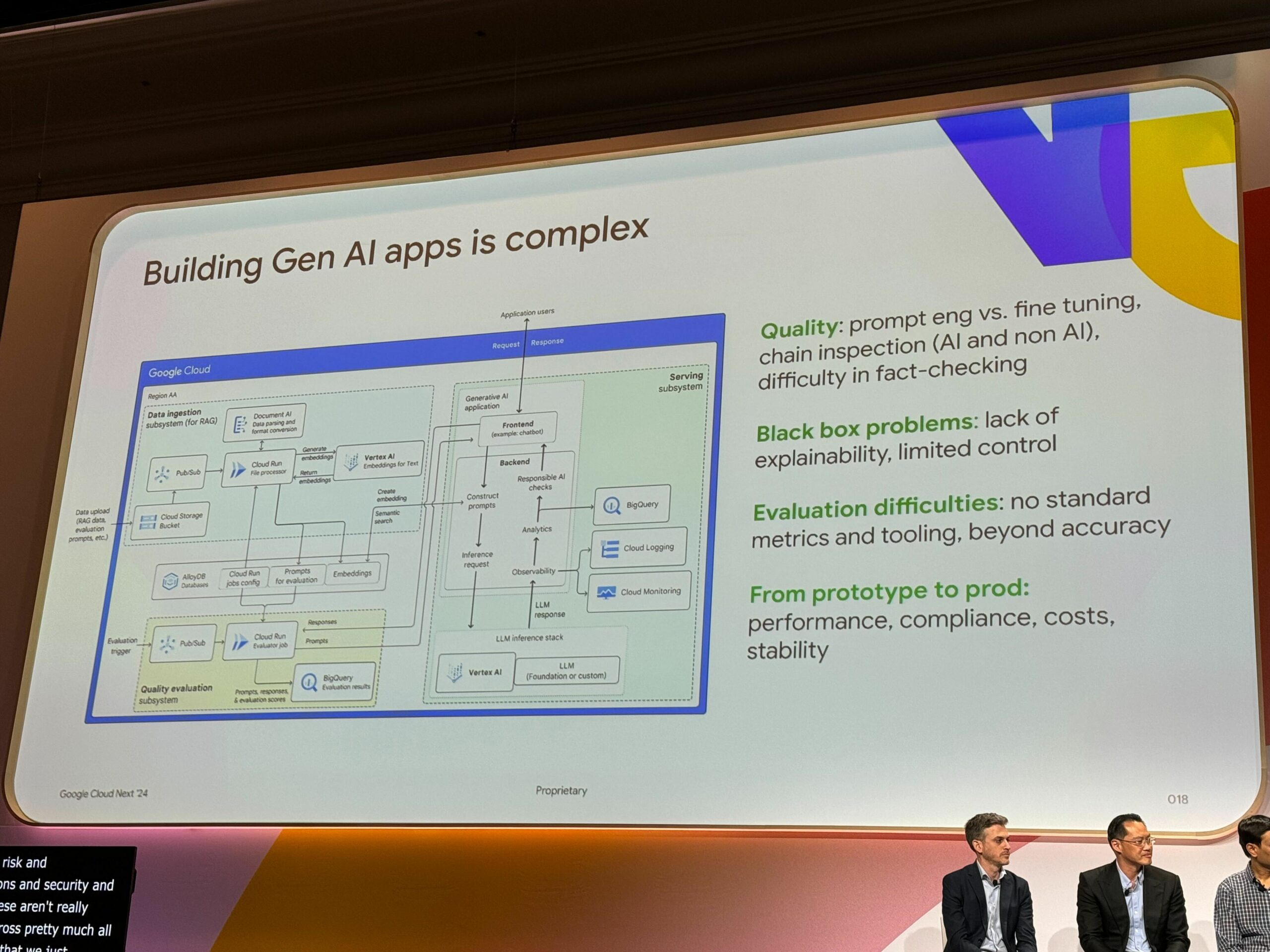
そもそもAIアプリケーションの構築が複雑なことに加えて、以下の困難も待ち受けてます。
– 品質はまだまだ課題が山積み
– ブラックボックスな面が多い
– 評価方法が難しすぎる
– 今までのアプリとは全く別のパイプラインが必要
く、くそう。ここでAIアプリケーションは諦めないといけないのか…
お待ちかね。そこでAgent Builder!
Agent Builderを使うと、そんな複雑なAIアプリケーションを早く手軽に構築できる。
ノーコードから、ごりごりコードまで自由自在。便利ですね。

なぜかというと、開発者ジャーニーを、簡単に合理的にするためなんだとか。
たしかに、実際に作りたいアプリや周辺のアーキテクチャによって、どこまでコードを書きたいか手間をかけられるか変わってきますよね。

人生皆ジャーニー。
RAGベースのアプリケーションのメリットは?

- 事実性と根拠:コンテキストを提供し、証拠に基づいた精度で、一般的なLLMを超える。
- より良いコンテキスト:一般化されたLLMのデータよりもコンテキスト的に詳細なデータを含むことができる。
- 最新のデータ:トレーニングに使用されたデータよりも最近のデータへのアクセスが可能。
- データの迅速な更新:大きなコストをかけずに、RAGのデータを継続的に更新することができる。
- 安価:実装が速く、ファインチューニングやクイッカーよりも比較的安価。
- ガバナンス:アクセス管理と権限を実装することで、誰がアクセスしているかに基づいてLLMの応答を制御する。
まとめると、従来のAIより簡単に!素早く!精度のよい!AIアプリケーションが作れる
RAGパイプラインをGoogle Cloudで!
作るだけ作ってあとは放置…というのは朽ちていく一方なので、Google CloudでRAGパイプラインを作りましょう。

まるっと作れて非常に便利ですね!
そして、それぞれのAPIも日夜新しくなっているようです。
実際の構築時もこのスライドをカンニングしようと心に誓いました。
newなAPIはうれしいものです。
とはいえ、なんでVertex AI Searchなの?
- とても早い、大規模にスケーリングもできる
- ScaNNアルゴリズムを使用しているため、コスト効率がとてもよい
- アクセスコントロールなど、セキュリティも安心
- ウルトラ最高に簡単に使い始めることができる

ちなみに、ScaNNというのは、数年前にGoogleが発表したアルゴリズムのことです。

Google検索やYouTubeの内部でもScaNNというものが使われています。
な、な、なんとVertex AIを使うとScaNNアルゴリズムもフル活用できるだとか。
さすがVertex AI!しびれる!
まとまらない感想(まとめ)
なぜ?から具体的にどうする?までわかりやすいスライド&説明だったので、とても満足感のあるセッションでした。満腹です。(でも、いくらでも聞きたい気持ち)
個人的には、RAGパイプラインの各コンポーネント・流れがとても勉強になりました。
ついついPoC段階では、おざなりにしがちなパイプラインですが、当然ながら、情報の鮮度、ユーザに満足してもらうために日々進化が必要がありますよね。
また、標準的な?のRAGパイプラインと違った新しいコンポーネントを使った構成が印象的でした。
ちなみに…今までは、以下が主流だったようです。
Cloud StorageにPDFなどのデータをアップロードしたタイミングでCloudRunなどでジョブを起動させ、Embeddingsに変換し各データストアに保存する。
(もちろんデータストアの違いなどによって構成は変動します)
今回のRAGパイプラインが主流になっていくんですかね!楽しみですね!わくわくしますね!
と、興奮したところで、以上とさせていただこうかと思います。
ぜひ、皆様もEnjoy RAGパイプライン
(終)




