
はじめに
Google Cloud Next Tokyo ’24 の 「Google Cloud の AI Hypercomputer で学習を加速させる」のセッションレポートです。
Google Cloud の片岡 義雅 氏 と 東京工業大学 藤井 一喜氏 によるセッションとなります。
主に Google Cloud で LLM 開発をする際のインフラ面での利用にあたって、どういった構成でできるのか、実際に使ってみてどうだったのか、がわかるセッションになっておりました。
AI Hypercomputer のアーキテクチャ
Google Cloud の AI Hpyercomputer では、以下に示されるようなアーキテクチャで動作しております。
ハードウェア:自社開発していて、Compute に乗せているTPUをはじめとして、ストレージ製品、またもちろん回線において自社開発しているものを利用しています。
ソフトウェア: OSS 製品が利用できる状態になっており、今までに慣れ親しんで使い方で利用することが可能です
利用形態:予約をして確保することはもちろん可能ですし、昨今確保が困難な中で、DWS と呼ばれる方法で効率的に確保する仕組みも準備されています。

AI インフラに関する Google の位置づけ
インフラではリーダーとして位置づけられており、19の評価項目のうち、17項目で満点を獲得しているということで、評価が高いことがうかがえます。

ポートフォリオ
以下のような様々な GPU インスタンスがあり、A3、A3 Mega、G2 VM、TPU v5p が紹介されておりました。

その中から今回は A3、A3 Mega について記載します。
A3 VM
NVIDIA H100 が搭載されている VM となります。Anthropic の Claude の開発に利用されているとのことで、そういった企業にも選ばれているという点でも信頼性が高さがわかります。
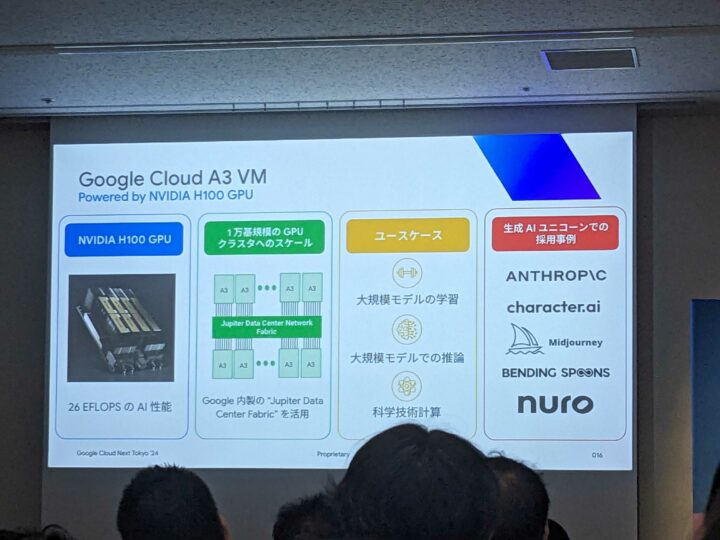
A3 Mega VM
NVIDIA H100 が搭載されている VM となりますが、大きな違いは帯域が A3 の2倍となり、より高速な NW 帯域を利用した学習が可能になります。

A3 及び A3 Mega VM については、既に東京リージョンでも利用可能になっているとのことで、GPU の稼働先を検討されている場合は、ぜひ Google Cloud の東京リージョンをご利用ください。
AI Hypercomputer の Compute サービスの選択肢
GCE を利用するか、GKE を利用するか、選択することが可能です。
GCE を利用する場合、Cluster Toolkit を利用して、Slurm を容易に導入 することが可能であり、その他慣れ親しんだ OSS を導入することも可能です。GKE を利用する場合、Kubernetes を利用したコンテナでの学習となり、15,000 ノードまで実行が可能です。

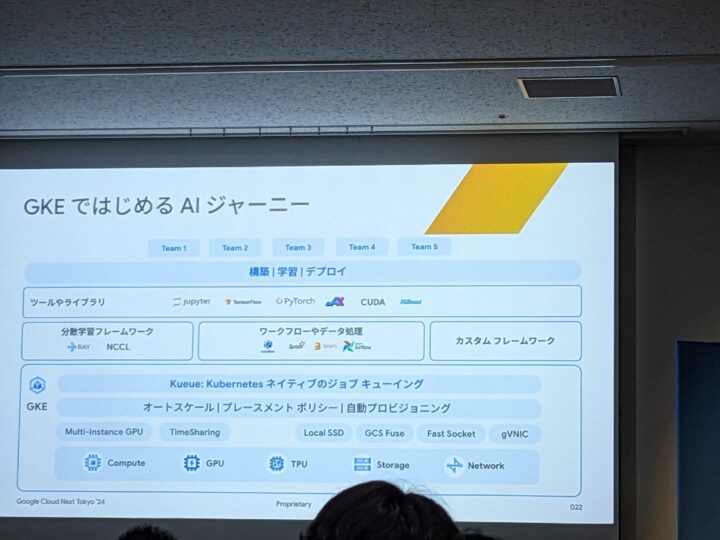
GKE ではじめる AI ジャーニー
GKE でも以下にある通り、基本的な OSS を動作させることが可能になっており、その他、AI Hypercomputer として利用するための機能や新たにサポートされたサービス等の紹介がありました。
セカンダリブートディスク
コンテナのイメージ、重いライブラリなどをキャッシュしておくことで、AI/ML ワークロードを行ううえでコンテナのサイズが大きく、ロードに長い時間かかっていたものが、 Google Cloud の計測で 29倍の速度で 16GB のコンテナが Runnning ステータスへ変わったとのことで、ちょっとこの機能で変わり過ぎじゃない?と思うくらい、改善されてて、ちょっとびっくりしました。。

Kueue のサポート
GPU / TPU はコストの観点から複数チームで共有するケースがあり、それをこの Kueue 機能によって、公平に利用するために、実行順序の制御や使用量を制御することが可能になったとのことです。
GCE でいう、Slurm でジョブ管理するイメージになるのでしょうか。

GKE Autopilot
インフラ担当がいないような場面であったり、管理するコストを削減するような場合に、インフラ管理から解放され、Pod のマニフェストを記載するのみで、GPU のワークロードを実行できるようになるとのことです。

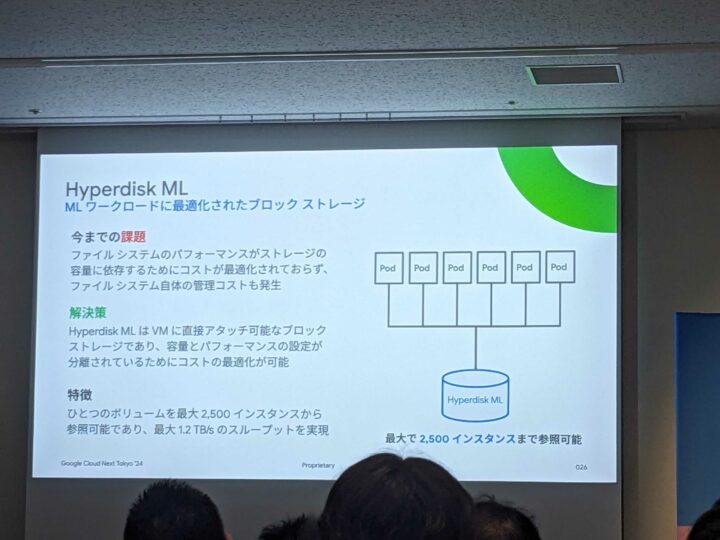
Hyperdisk ML
今までは IOPS をだそうと思う場合、ボリュームサイズを大きくする必要があり余計なコストがかかっていましたが、当該機能により、サイズと切り離して IOPS を調整することが可能になるため、その分コスト削減が見込めます。
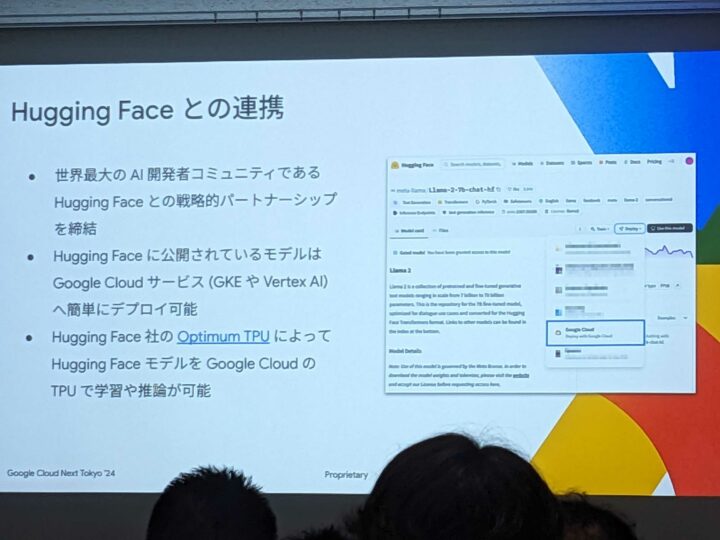
Hugging Face との連携
Hugging Face に公開されているモデルは、Google Cloud (GKE など)へ簡単にデプロイできるとのこと。
Dynamic Workload Scheduler (DWS)
確保が困難だった GPU に対して、DWS の機能を利用してリクエストをかけておき、デプロイの順番待ちをしておくことが可能な機能です。機能としては実は簡易的にチェックするなどではなく、手順がありますので、その点は注意が必要ですが、時間的に余裕があるバッチ処理などに向いている機能とのことです。

もしよろしければ以前に纏めた予約とDWSに関してご覧いただければ通常の予約フローとDWSでの利用について違いがご理解いただけるかと思います。
実際に A3 を利用して
上記 DWS までが片岡氏によるセッションでここから藤井氏による、実際に利用した経験についてお話されていました。
リソースの利用
先に記載したCluster Toolkit を利用することで、Slurm をデプロイでき、リソースを有効活用し、リソースの半自動実行することができたとのことで、Cluster Toolkit を利用することで、構築する際のコストを大幅に削減できたとのことでした。

故障率の低さ
今までの経験の中でもかなり故障率が低かったとのことです。NW 障害やノード障害により、学習を動かしていた、1台でも障害がある場合、その時点で学習が止まってしまい、仮にチェックポイントを設けていても、そのチェックポイント以降の学習が無駄になってしまうため、この故障率の低さにより学習が大きく捗ったとのことでした。
冒頭で記載していたインフラの信頼性について、実際に様々な場面でご利用になられた方のご意見が伺え、参考になりました。

Megatron-LM on A3 Instance
Megatron-LM がスパコンで利用していた際と同様に、A3 でも動作させることができたとのことで、慣れた方法で利用ができたとのことです。

まとめ
GPU を用途に応じて利用可能であり、確保の面でも DWS を利用し確保するためのハードルは少し下がっているとのこと。
また、上記でご紹介した通り、通常で学習を進めているとのオーケストレーターやフレームワークは利用可能になっており、それが信頼性の高いインフラである、Google Cloud で動作できるということで、今後、GPU を Google Cloud で扱おうと思っている人にとっては、安心して利用できる材料になるようなセッションでした。
また、LLM のモデルに注目が集まりがちですが、LLM 開発者側にも視点があたっているセッションであり、この他にもそういったセッションがあり、モデルだけでなく、LLM 開発者という点についても、Google Cloud の注目度の高さがうかがえる内容でした。





