
はじめに
この記事は、ラスベガスで開催されているGoogle Cloud Next 2025のセッション聴講記事です。
セッションタイトル:
How good is your AI? Evaluate it at every stage.
Vertex AIを使用した評価方法、Google Cloudの評価ツールについての内容です。
AI評価をしたい…でも…
猫も杓子も生成AI!のこの時代。生成AIアプリの本番運用もとてもとても増えてますよね。
とはいえ…、大変恐縮ですが、生成AIの評価、きちんとできてますでしょうか…?
アプリを開発したはいいものの、作りっぱなしで改善方法がわからない…そんな状況になっているところも少なくないと思います。
AIの評価の必要性はいくら強調しても足りない。というか、みなさん必要だと強く感じているかと思います。
とはいえ、AIの評価…どうするの?メトリクスは?LLM as a Judge?そもそも、どうやって組み込むの?
などなど、悩みは尽きないと思います。
Google CloudのAI評価ツール
そうです!そんな悩みを解決してくれるのが、Gen AI Evaluation Service!です。
Gen AI Evaluation Serviceは、その名の通り、生成AIの評価をしてくれるサービスです。
どんなサービスでも、どんなモデルでも、APIを呼び出すだけで、自分のデータセットを使って、評価できちゃう優れもの。

- 評価できるモデル
- Googleモデル
- オープンモデル
- 独自モデル(クローズドモデル)
- カスタムモデル
- 利用できる評価モード
- オンライン
- 利用できる基準
- ポイントワイズ
- 個々の出力を評価する方式
- ペアワイズ
- 2つの出力を比較評価する方式
- ポイントワイズ
- 利用できる手法
- 計算ベース
- 指標メトリクス(BLEU、ROUGEなど)を自動計算する手法
- 自動評価者 (Autorater)
- AIを利用した自動評価の手法(LLM as a Judge)
- 計算ベース
また、生成AIの評価フローは以下のように進めていきます。
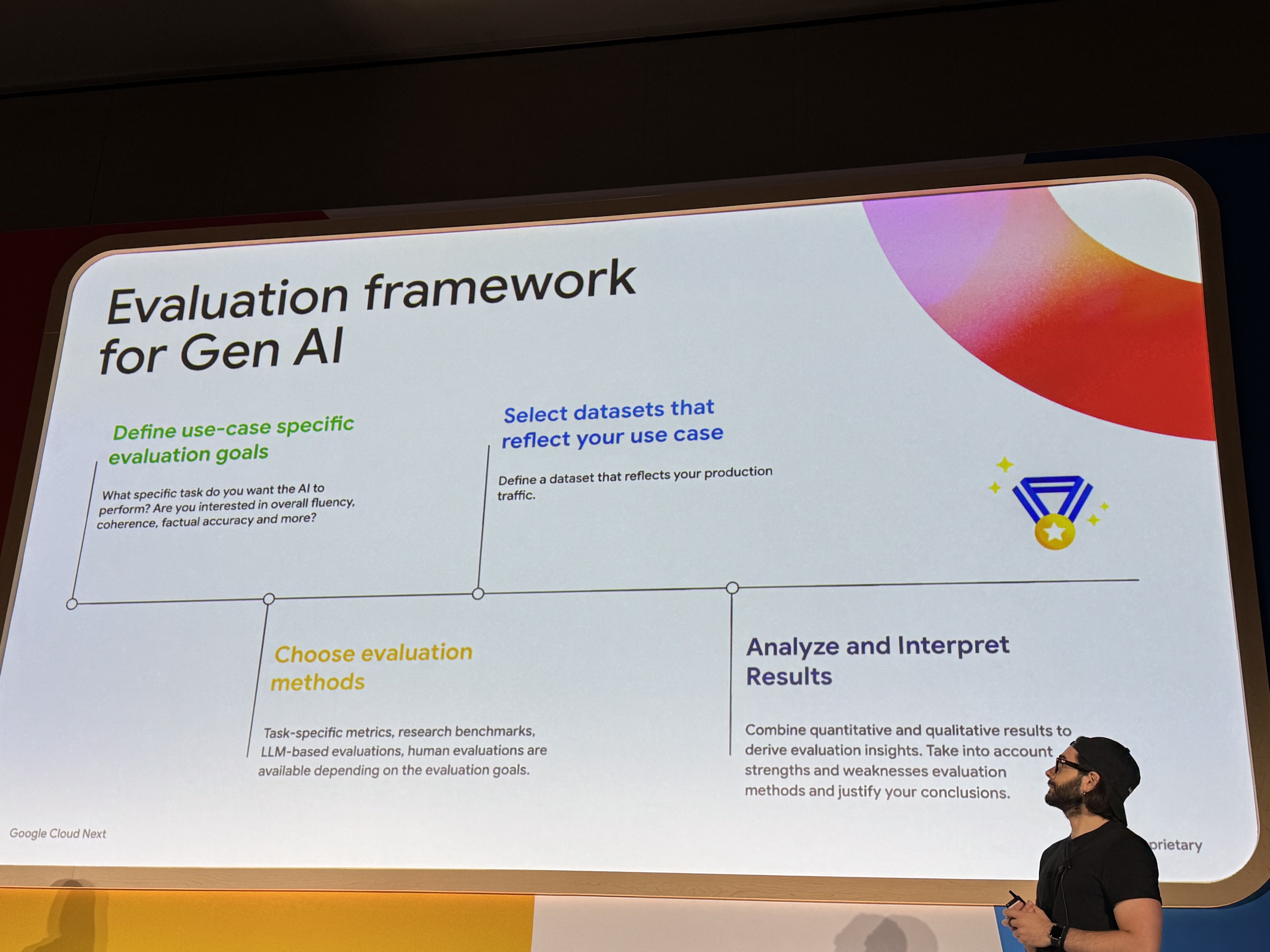
- ユースケース固有の評価目標を定義する
- ユースケースを反映したデータセットを選択する
- 評価手法を選択する
- 結果を分析・解釈する
※従来のAIではなく生成AI向けのサービスです
※一部プレビュー機能もあります。詳しくはこちらからご確認ください
そして、今回のセッションのポイントは以下の3つです。
1. バッチ評価
2. Autorater(LLM as a Judge)のカスタマイズ
3. Agentの評価
1. バッチ評価
そもそも、なぜ今回バッチ評価に焦点を当てるのでしょうか…?
それは、従来API問題点として、スケールすることができない(=大量のデータセットを使用するのが困難)という問題がありました。
また、従来のAPIの処理は非同期処理ではないため、非同期処理として後ほど通知を受け取る。そんな仕組みにする場合には、自分で手作業で、オーケストレーション、パイプラインなど作成する必要がありますが、これにより、管理コストや、運用コストなどが増えてしまいます。
そんな中、待望のバッチ評価ができるようになりました!わーい!
処理方法は、Cloud Storageの評価したいデータセット、諸々を指定するだけ!
あとは、茶をしばいている間に、指定したCloud Storageバケットに評価結果を出力してくれます。か、かんたんすぎる…。
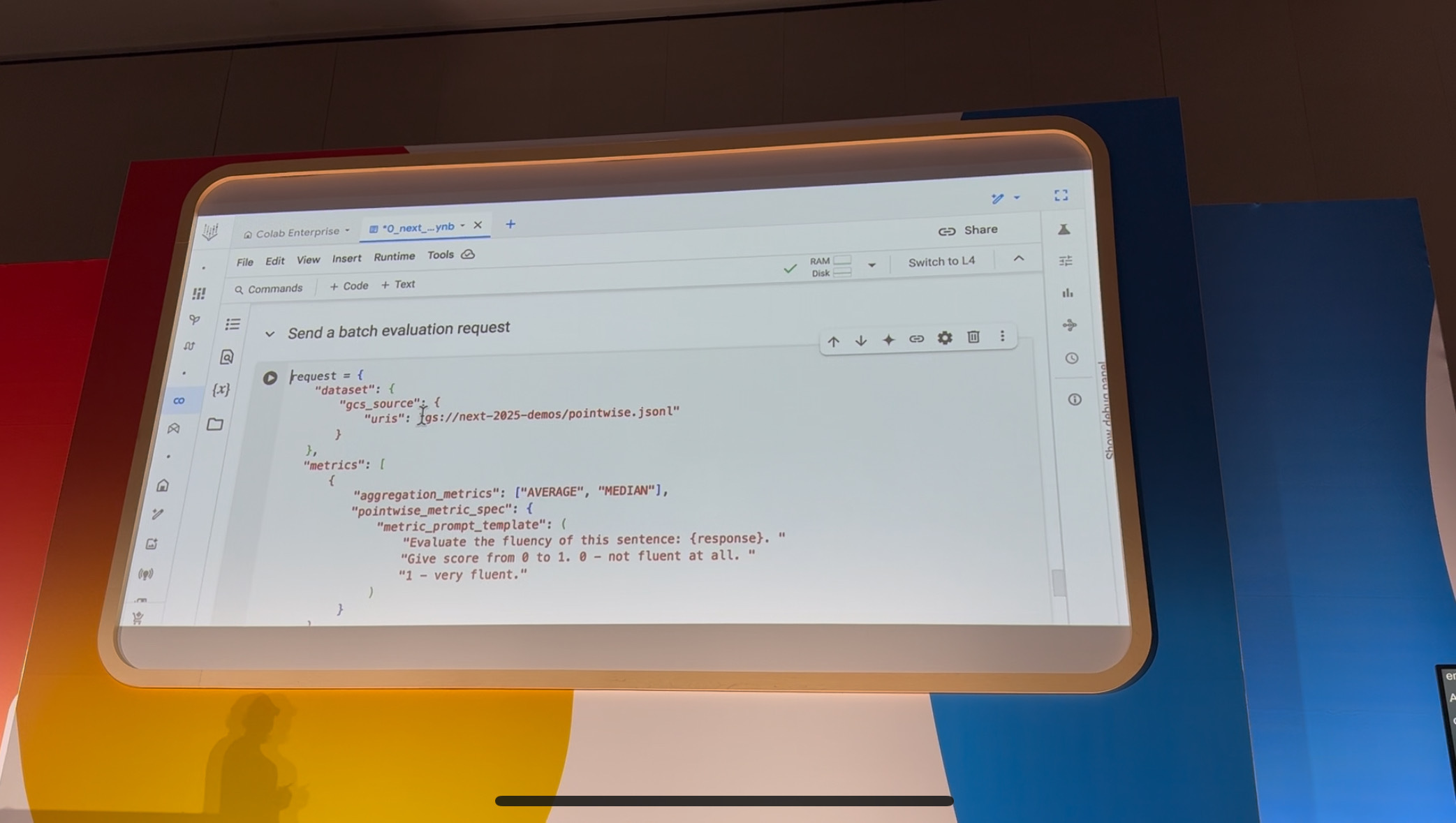
データセットを指定して…
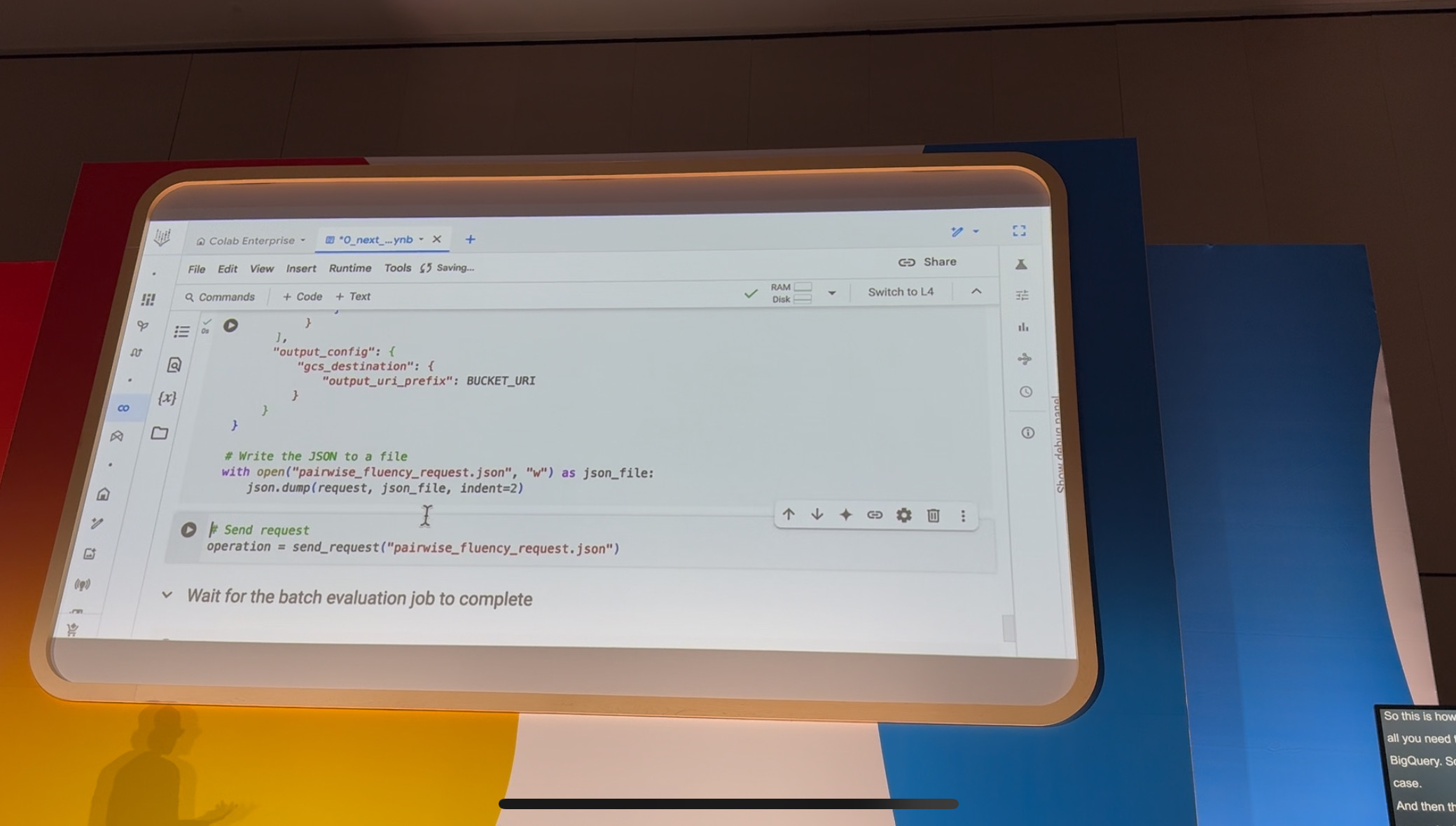
出力先のCloud Storageバケットを指定して、リクエスト…
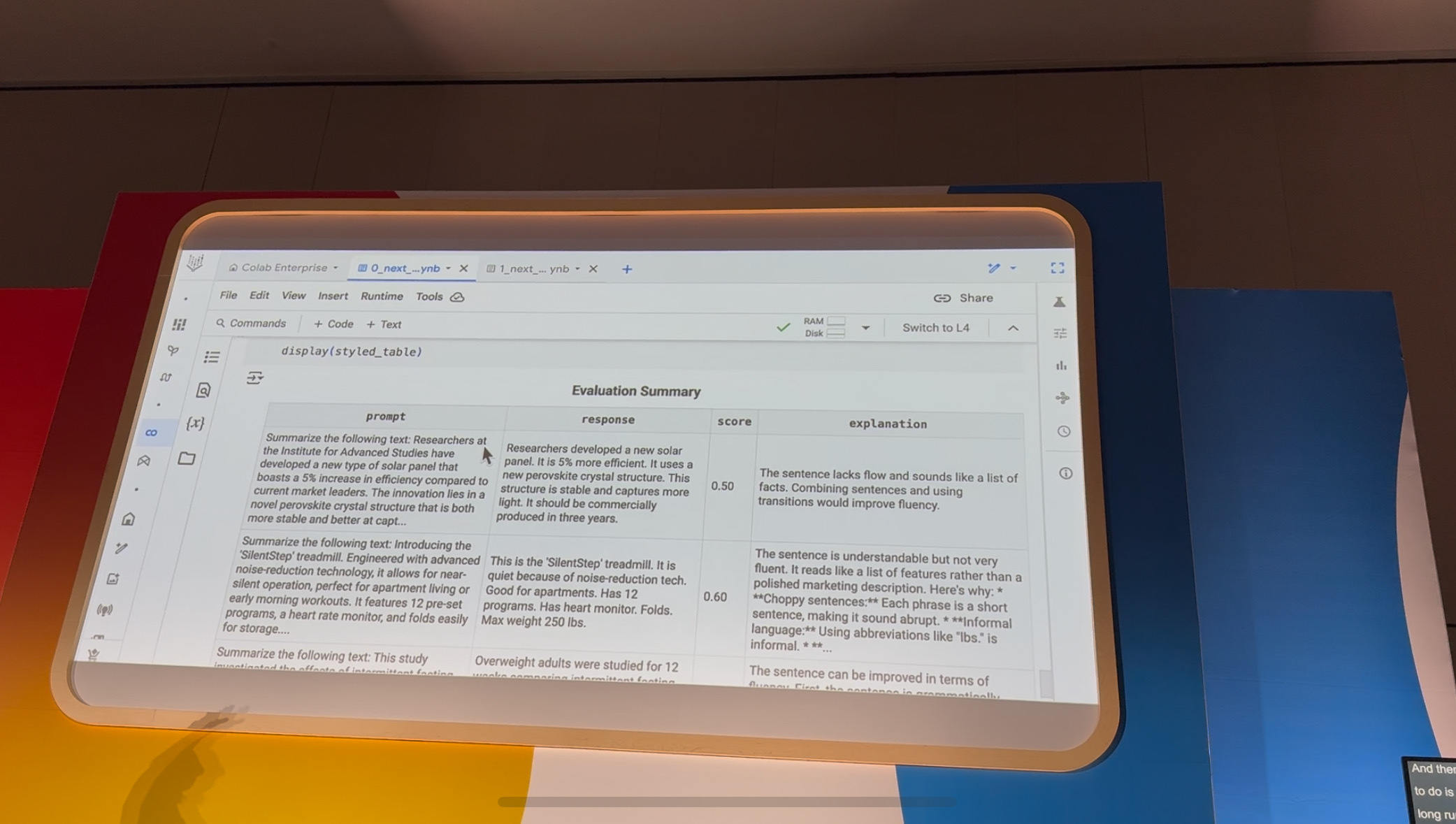
すると、あら不思議。上記画像のような素敵な評価結果が!
2. Autoraterのカスタマイズ
Autorater、いわゆるLLM as a Judgeとは、その名の通りLLMを使用して評価する手法です。
このとき、評価LLMのプロンプトで、どんな評価基準にするかなどを指定します。
ただし、Autoraterにも問題点があり…
Autoraterのメリット
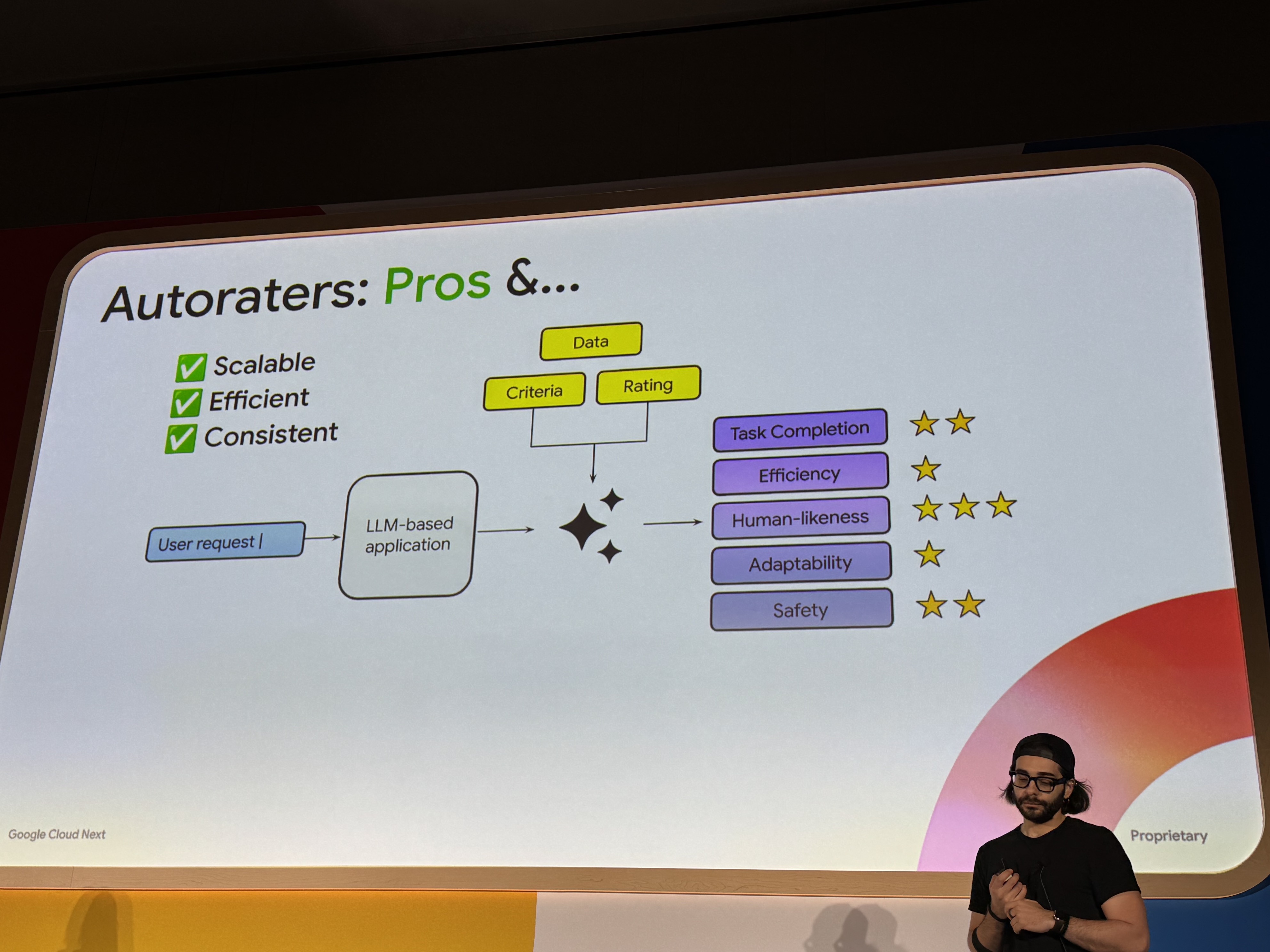
- 拡張性がある
- 効率的
- 一貫性がある
Autoraterの問題点

- LLMの能力に制限される?
- 堅牢性に欠ける?
- Autoraterの評価自体を信頼できるか?
このうち、Autoraterの評価の信頼性を向上させるための大まかな流れは以下!
Autoraterの品質を評価して -> Autoraterの品質を改善する!

ステップ1
Autoraterの調整や性能測定を行うために、まず人間が評価したサンプルを集めて、基準となるデータセットを作成する

ステップ2
- Autoraterへのプロンプトを改善する
(評価基準の明確化、CoTの導入、など) - Autoraterの設定を微調整する
(マルチサンプリング、レスポンス反転、など) - 実際のお手本(評価したい課題、模範解答、採点基準)を使って、Autoraterを独自の目的に特化させる
…
…
…
…
…
え?とはいえ、具体的な改善手法は、どうすればいいの…?え…
それは、主に2つ!
- 評価プロンプトの改善(プロンプトエンジニアリング)
- Autoraterの設定調整
このうち、セッションでは、Autoraterの設定調整の中のマルチサンプリング、という手法について紹介されました。
そもそも、デフォルトで評価は1つに4回行います。これは、生成AIという特性上試行回数を増やすのは、よく聞くと思います。
そして、Gen AI Evaluation Serviceなら、引数の値を変更するだけ!なんて簡単なんでしょう。しあわせってこういうこと。
より厳密にチェックしたい場合は、16回など回数を増やしたり、逆にコスト効率を考えるなら、2回など、回数を減らしたり…変幻自在ですね!
設定値の調整は、ほんとーーに、手軽にできるため、まずはマルチサンプリングの設定調整から始めて、徐々に複雑な設定、手間暇のかかるプロンプトエンジニアリングなどを試してみる。のが良いかもしれませんね!
※マルチサンプリングについて、詳しくはこちら
つづきに
Part2へ続く!




