
はじめに
この記事は、ラスベガスで開催されているGoogle Cloud Next 2025のセッション聴講記事です。
セッションタイトル:How good is your AI? Evaluate it at every stage
スピーカーは、Irina Sigler氏、Ivan Nardini氏、Nicolas Venegas氏の3名でした。
近年、AIを活用したプロトタイプの構築はかつてないほど容易になりました。
しかし、そのAIを本番環境に投入し、信頼性の高いアプリケーションとして運用していくためには、
依然として多くの課題が存在します。特に、生成AIにおいては、その出力の多様性や複雑性から、従来の評価手法だけでは不十分なケースも少なくありません。
本セッションでは、Gen AI Evaluation Serviceが、AIの開発ライフサイクルのあらゆる段階で、品質を評価し、改善するための羅針盤となることが強調されました。
セッションの内容
あらゆる段階での評価の重要性
セッション冒頭で、Irina Sigler氏は、「AIパワードプロトタイプを構築するのはかつてないほど容易になったが、AIを本番環境に投入する際には依然として同じ課題が存在する」と述べ、評価の重要性を改めて強調しました。
Gen AI Evaluation Serviceは、モデルの選定から、プロンプトエンジニアリング、ファインチューニング、蒸留、そしてデプロイ前後の評価に至るまで、開発のあらゆるステップで活用できることが紹介されました。
まるでコンパスのように、開発の方向性が正しいかどうかを常に確認し、意味のあるガイダンスを提供することが期待されています。
また、評価はタスク固有であるべきであり、実際のプロダクション環境のトラフィックと相関性の高い独自のデータセットで行うことの重要性が語られました。
データセットは必ずしも巨大である必要はなく、利用ケースを代表する意味のあるデータであることが重要です。
そして、評価システムは、単なる標準的な指標だけでなく、アプリケーションのユーザーにとって重要な基準に基づいて行うべきだと指摘されました。
生成AI評価の進化
プロダクトマネージャーであるSiglar氏は、過去1年間のフィードバックに基づき、Gen AI Evaluation Serviceの主要なアップデートとして以下の4つのポイントを発表しました。
1. バッチ評価 (Batch Evaluation):大規模データセットでの評価を効率的に
従来のGen AI Evaluation ServiceのAPIは、プロンプトやアプリケーションを個別に評価するのに適していましたが、数万もの大規模なデータセットを効率的に評価したいというニーズが高まっていました。
開発者は、スケーラブルに評価を行うために、コードをリファクタリングしたり、Apache BeamやDataflow、Vertex AI Pipelinesなどのサービスを組み合わせて独自のパイプラインを構築する必要があり、開発コストや運用コストがかかるという課題がありました。
これに対し、新たに発表されたGen AI Batch Evaluation Serviceは、非常にシンプルなAPIを通じて、大規模なデータセットでの評価ジョブを簡単にスケールできるようになります。既存のリアルタイムAPIと同じ指標と手法をサポートしており、より安価で効率的に、大規模なデータセットでの評価が可能になります。
デモでは、Cloud Storageにアップロードされた評価用データセット(ユーザー入力、参照、応答を含む)を基に、APIリクエストを送信するだけで、非同期の評価ジョブが実行される様子が紹介されました 。ジョブ完了後には、定義したCloud Storageのバケットに、個々の入力に対する評価結果と、指標ごとの集計結果がJSON形式で出力され、簡単に確認できるようになります。
2. 自動評価器(Auto-Rater)の信頼性向上:LLMによる評価をより確実に
LLMがLLMを評価するというコンセプトに対して、信頼性への懸念の声が上がっていました。
自動評価器(LLM Evaluator)は、ユーザーが定義した評価基準(良いとされる定義、安全性、タスク完了度など)に基づいて、候補モデルの出力を評価し、スコアを割り当てるものですが、その評価結果をどのように信頼すればよいのかという疑問です。
この課題に対し、Gen AI Evaluation Serviceは、自動評価器のパフォーマンスを検証し、改善するためのツールセットを提供します。
自動評価器の評価:
まず、少量のプロンプトに対して人間の評価と自動評価器の評価を比較し、評価のずれがないかを確認できます

プロンプトの改善:
評価のずれが見られた場合、自動評価器に与えるプロンプト(評価基準、ガイドライン、参照回答など)を改善するためのツールとガイダンスが提供されます 。
設定の調整:
自動評価器の設定(マルチサンプリング回数など)を調整することで、評価の一貫性を高めることができます。
例えば、デフォルトでは4回評価を行うところを、より厳密な評価のために16回に増やしたり、バッチ評価の際にはコストを抑えるために2回に減らしたりすることが可能です 。
カスタムモデルの利用:
デフォルトの評価モデルだけでなく、別のモデルを評価器として利用したり、独自のデータセットでファインチューニングした評価モデルを利用したりすることも可能です。
オープンソース評価モデルの活用: デモでは、Vertex AIのエンドポイントにデプロイしたオープンソースの評価モデルを利用し、人間の評価との比較を通じて、そのモデルの妥当性を検証する様子が紹介されました。
これらのツールを活用することで、自動評価器の挙動を深く理解し、その評価結果に対する信頼性を高めることができます。
3. マルチモーダル評価 (Multimodal Evaluation):テキスト、画像、音声、動画など多様なデータを評価
近年、生成AIの活用範囲はテキストだけでなく、ビデオ、画像、音声などのマルチモーダルなデータに広がっています。このような多様なデータを適切に評価するためのニーズが高まっています。
この課題に対し、Gen AI Evaluation Serviceは、ルーブリクス駆動評価 (Rubrics Driven Evaluation) という新しいアプローチを導入しました。
従来の評価では、ユーザーが評価基準を詳細に定義する必要がありましたが、特に多様なデータセットや複雑なタスクにおいては、適切な評価基準を作成することが難しいという課題がありました。
ルーブリクス駆動評価では、ユーザーは入力データセットのみを提供します。
Gen AI Evaluation Serviceは、この入力データセットに基づいて、データポイントごとに評価のためのルーブリクス(質問)を自動的に生成します。
これにより、ユーザーは詳細な評価基準を定義する手間が省け、データセットの多様性やタスクの複雑さに応じた、よりきめ細やかな評価が可能になります。
デモでは、自動車の損傷評価を例に、前後の画像を入力データセットとして提供し、システムが自動的に「特定の場所に損傷はあるか?」「修理は適切に行われているか?」といった具体的な質問を生成し、評価を行う様子が紹介されました。
このアプローチにより、評価の透明性が高まり、なぜそのような評価になったのかを理解しやすくなります。
現在、インストラクションフォロー、テキスト品質、マルチモーダル理解のタスクで利用可能です。

4. エージェント評価 (Agent Evaluation):複雑なAIエージェントの振る舞いを評価

AIエージェントは、オーケストレーションレイヤー、ツール利用、API連携など、非常に複雑なシステムであり、その評価は単に応答の品質だけでなく、問題解決能力や適切なツールの選択といった多岐にわたる側面を考慮する必要があります。
Gen AI Evaluation Serviceは、このような複雑なAIエージェントを評価するための初期的なサポートを提供します。
具体的には、エージェントの応答の品質だけでなく、ツールの利用能力(正しいツールを適切なタイミングで選択できるかなど)を評価するための指標を提供します。
また、ユーザーは独自のカスタムメトリクスを定義することも可能です。
評価結果は、他の評価と同様に、個々のインスタンスレベルと集計レベルで確認できます。
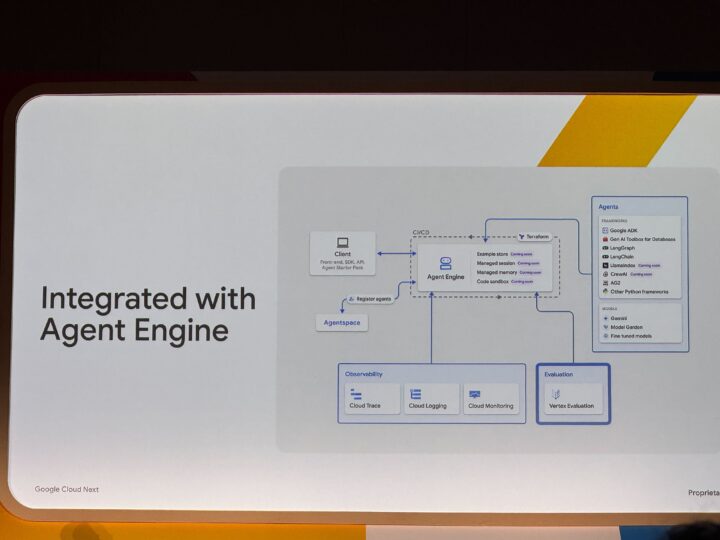
このサービスは、Agent Engineとも統合されており、LangChainなどのフレームワークで構築されたエージェントアプリケーションの評価にも活用できます。
LATAM航空の事例紹介:評価をビジネスの意思決定に活かす
セッションでは、南米最大の航空会社であるLATAM航空の事例が紹介されました。
LATAM航空は、AIとデータプロダクトを構築するためのエコシステム「Cosmos」を数年前に構築し、その中でGen AI Evaluation Serviceを活用しています。
具体的な事例として、パイロットの休息時間違反の早期発見や、顧客からのフィードバックの優先順位付けなどが紹介されました。
以前、乗務員計画を最適化するプロダクトが、休息時間を満たさないパイロットをフライトに割り当てる提案をしたことがありましたが、Cosmos Evaluatorが早期にこの問題を検知し、本番環境へのデプロイを阻止しました。これにより、運航の混乱や安全性の低下を防ぐことができました。
LATAM航空は、Gen AI Evaluation Serviceを活用することで、生成AIモデルの品質を保証し、ビジネス上のリスクを低減しています。
Cosmosは、低コストでの機能提供、スケーラビリティ、生産性向上を実現しており、多くのAIプロダクトの開発と運用に貢献しています。
また、LATAM航空は、「cost library」 という独自の評価ライブラリを開発し、Gen AI Evaluation Serviceと連携させて利用しています。
このライブラリを通じて、Coherence(一貫性)、Bias(偏り)、Adaptability(適応性) など、様々な評価指標を用いてモデルの性能を評価しています。
チャットボットなどのアプリケーションにおいては、質問と回答の比較、期待される回答と実際の回答の比較、コンポーネントと回答の比較といった評価を行っていることが紹介されました。
事例紹介の最後に、「評価はオプションではなく必須である」と力強く述べ、AIプロダクトをビジネスに導入する際には、常にGen AI Evaluationをコードの一部として組み込むべきだと強調しました。
まとめと今後の展望
本セッションを通してGen AI Evaluation Serviceが、生成AIの開発者にとって不可欠なツールへと進化していることが明確になりました。
バッチ評価による大規模データセットへの対応、自動評価器の信頼性向上、マルチモーダル評価による多様なデータ形式への対応、そしてエージェント評価の初期サポートにより、より複雑で高度な生成AIアプリケーションの開発と運用を支援することが期待されます。
特に、LATAM航空の事例は、早期の評価と継続的な監視が、ビジネス価値の創出とリスク軽減に繋がることを具体的に示していました。
そして、セッションの最後に発表されたGenAI Evaluation Serviceの価格引き下げは、より多くの開発者が評価を容易に導入できるようになるという点で、非常に大きなニュースと言えるでしょう。
信頼性の高い生成AIアプリケーション開発のために、Gen AI Evaluation Serviceを積極的に活用していくことを推奨します。



