
はじめに
この記事は、ラスベガスで開催されたGoogle Cloud Next 2025のセッション聴講記事です。
セッションタイトル:
Productionizing OSS agents: Best practices for agent frameworks and Vertex AI
セッション内容は、「OSSを用いたエージェント開発についてのビルドとデプロイという2つの視点の課題とGoogle Cloudでの解決策方法」という内容です。
うち、この記事は、デプロイについての記事です。
ビルドについて記事はこちら
課題は何か?
手元で開発したはいいものの、実際に本番向けにデプロイするとなると…たくさんの課題が…!
手動でちまちまセットアップが必要となりますし、複雑なスケーリングも求められます。
また、いままでの汎用的なインフラでは、エージェント特有のニーズあり、うまく動作しない場合があります。
さらに、エージェントは状態を保持する必要があり、長時間にわたるモデルの呼び出しや予測不可能なツールとの連携が、スケーリングをさらに難しくします。
極め付けに、セキュリティも重要な懸念事項であり、生成されたコードの実行やデータベース、APIへのアクセスを安全に管理する必要があります。
うわーーーー、考えることが多すぎて頭が爆発します。ぐぬぬ。
そして、個々のより具体的な課題には、以下のようなものがあります。
デプロイフェーズ

AIエージェントに関しては、「私のマシンでは動く」では通用しません。
エージェントのデプロイには、厄介な依存関係、ステートフルスケーリングの悪夢、セキュリティリスクが伴い、専門的なインフラが必要です。多くの場合、手作業で、退屈で、壊れやすいものです。
- パッケージングの問題: Pythonのバージョンが衝突し、requirements.txtはカオス状態、コンテナは肥大化します。一貫性が必要です!
- ステートフルスケーリング: エージェントはメモリ/コンテキストを必要とします。従来のステートフルなアプリのスケーリングは困難ですが、エージェントはさらにLLMの呼び出しや長時間かかるタスクを追加します。
- セキュリティリスク: エージェントはコードを実行したり、ツールを介して機密データにアクセスしたりする可能性があり、認証情報の管理が必要です。リスクが高いです!
- 汎用インフラでは不十分: 標準的なデプロイツール(基本的なコンテナ、関数など)は、多くの場合エージェントのワークロード(非同期フロー、リソースの急増)に最適化されていません。
日々の開発から感じることは、特に、ライブラリの依存関係がつらいです。AIライブラリのバージョンアップ頻度がすさまじいため、しょっちゅうエラーが出ます。
それを手作業でちまちま修正していく…そしてどんどんカオスになっていきますね。
アプデ対応に追われ、エージェント自体の追加開発が滞る、なんてこともしばしば。
しかも、Python本体のバージョンアプデなんてものもあるので、さーたいへん。
ほかに、エージェントがコード実行や外部アクセスを行う際のセキュリティは最重要課題ですが、汎用インフラではタイムアウトやリソース管理の限界がありますし、
手作業が多く脆弱なため、本質的なエージェント開発を妨げる可能性があります。
そのため、エージェント固有のニーズに対応したインフラが必要ですよね…。
そうだ!Google Cloudで解決しよう!
安心してください!Google Cloudが解決します!再び。
そこで登場!Vertex AI Agent Engine!
Agent Engineは、まさに、エージェントのためのインフラ基盤です。
OSS エージェントの煩雑なデプロイメントを劇的に効率化し、セキュアでスケーラブルなエンタープライズ対応のエンドポイントへのデプロイを容易にします。
LangGraph、LangChain、Agent Development Kit (ADK) などフレームワークに依存せず、独自のコードも持ち込み可能で、Cloud Run ベースのフルマネージド環境がスケーリングやセキュリティの課題を解消します。
さらに、セッション管理、評価ストア、メモリオプションといったエージェント固有の機能や、統合された可観測性を提供し、より良いエージェント開発に注力できるようになります。
そうです、Agent Engineなら、Google純正のAgent Development Kitだけでなく、好きなフレームワークでじっそうできてしまうのだ!
懐が広い、かっこいい、Agent Engine、そんなところにシビレます。らぶ。
エージェントデプロイの合理化

Agent Engineは、OSSおよびカスタムエージェントを、Google Cloud上の安全でスケーラブルなマネージドエンドポイントにデプロイする作業を簡素化します。
基盤整備ではなく、あなたのエージェントに集中してください。
- フレームワーク非依存: LangGraph、LangChain、ADK、CrewAI、カスタムコードなどで構築されたエージェントをデプロイ(BYOF!)。
- マネージドランタイム: Cloud Run上に構築。スケーリング、セキュリティ、ネットワーキングに関する懸念事項を処理します。
- エージェント固有の機能: セッション管理、サンプルストア、マネージドメモリの組み込みサポート。
- 統合されたオブザーバビリティ(可観測性): 可視性を高めるため、Cloud Trace、Logging、Monitoringとのネイティブな統合。
Agent Engineまわりのつながり
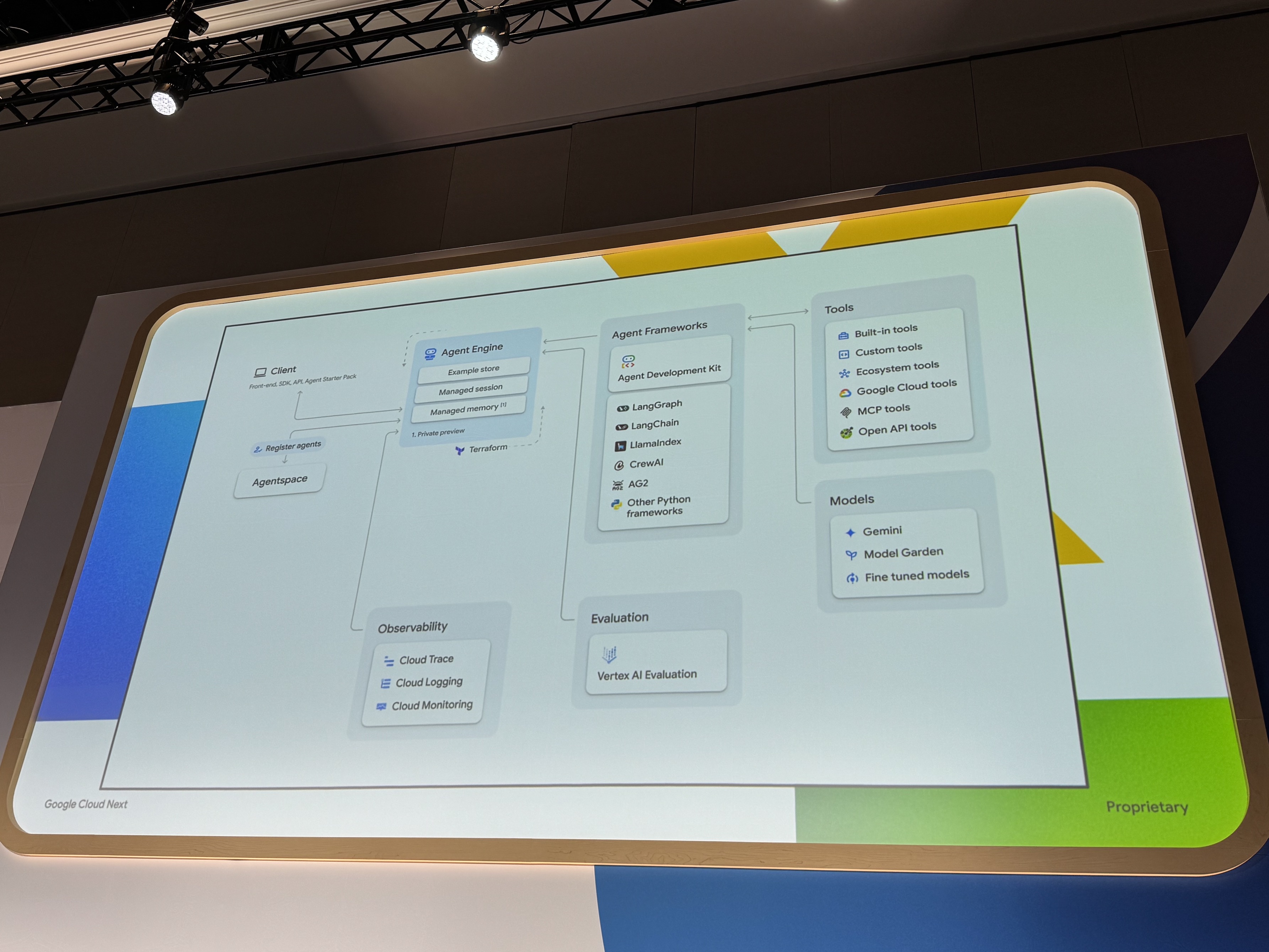
Vertex AI Agent Engineは、クライアントとデプロイされたエージェントの架け橋となり、多様なフレームワークで構築されたエージェントコードをスケーラブルかつセキュアな環境で実行・管理します。
また、Agent Engineは、Geminiなどの基盤モデルや各種ツールとの連携をオーケストレーションし、CI/CD、監視、評価といったGoogle Cloudの幅広い運用ツールとシームレスに統合され、エージェントロジックを本番環境のサービスとします。
Agent Engineならどんなフレームワークでも!

Agent Engineは、ADK、LangGraph、Vertex AI Search and Conversation、LangChainといった多様なツールで構築されたエージェントを、フレームワークに依存せず柔軟にデプロイできます。ユーザーはコードと依存関係をパッケージ化するだけで、Agent Engineがデプロイとサービングを自動的に処理します。これにより、選択したフレームワークに関わらず、一貫したデプロイ環境が提供されます。
Agent Engineワークフロー
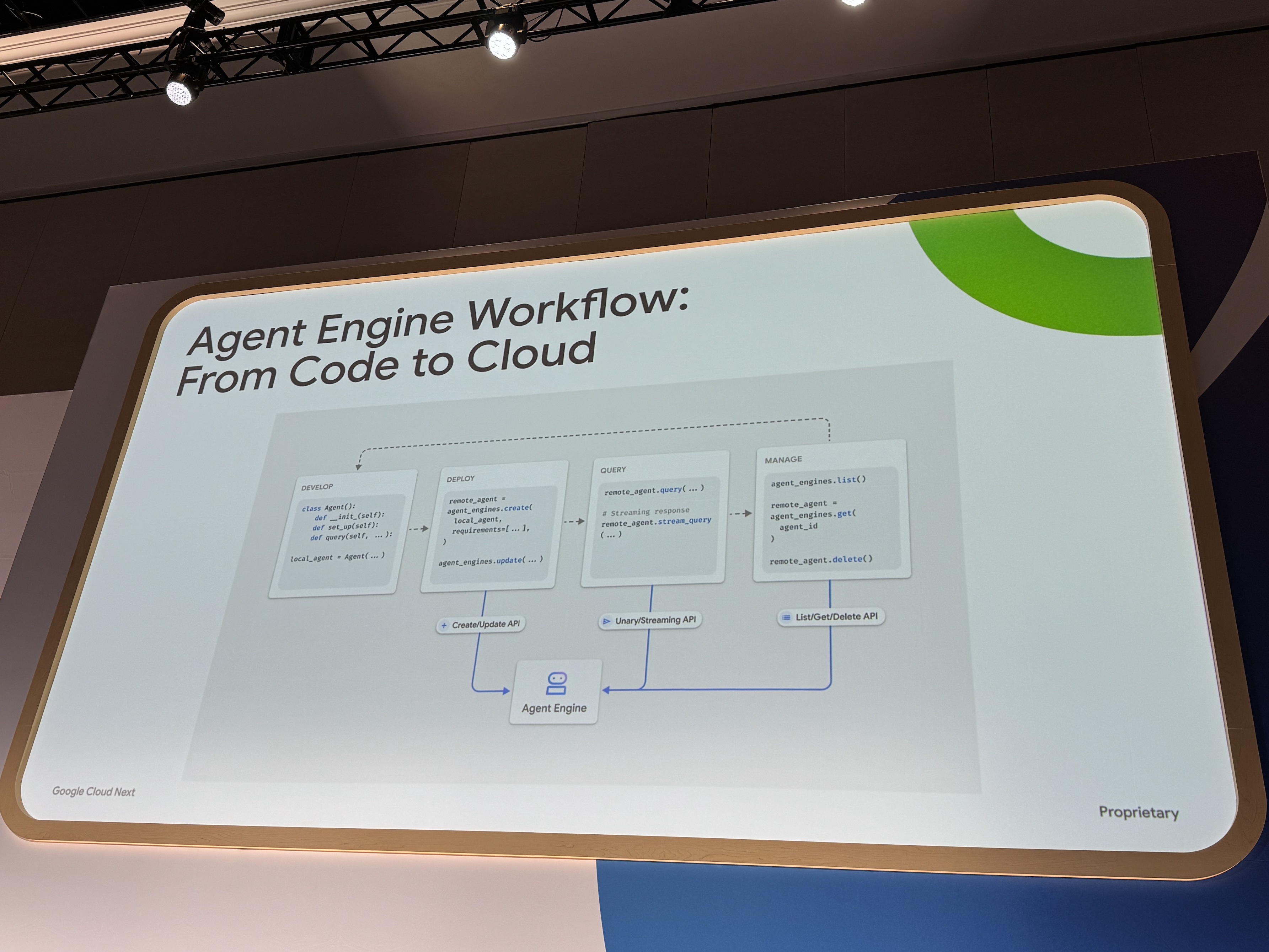
Agent Engineを利用して開発する際は、まずローカルでエージェントオブジェクトを開発し、次にSDKまたはAPIを使用してエージェントコードと設定を提供することで簡単にデプロイできます。
Agent Engineはコンテナ化とCloud Runへのデプロイを自動で行い、デプロイ後は簡単なAPIコールを通じてエージェントのクエリや管理が可能です。これにより、複雑なインフラ管理から解放され、エージェントロジックの開発に集中できます。
デプロイ、その後の運用

- ユーザーセッション
- レプリカ間で、ユーザーごとのコンテキストと状態を管理します。
- 評価とフィードバックループ
- 品質とリグレッションを監視するために評価(Vertex Eval、OSSツール)を設定します。フィードバックループを完成させます。
- モニタリングとトレース
- Cloud Logging/Traceを使用して、レイテンシ、エラー、コストを把握し、エージェントの動作(ツールの呼び出し、中間ステップ)を理解します。
- マネージドランタイム
- Agent Engineが、基盤となるインフラ、パッチ適用、基本的な可用性を処理します。
- 自動スケーリング
- Cloud Run基盤が、トラフィック量に基づいて自動スケーリングを提供し、状態管理の複雑さに対処します。
- セキュリティとガバナンス
- IAMを活用し、ツール向けの安全な認証情報管理やネットワーク制御を行います。
エージェントの安定稼働には継続的な運用が不可欠ですよね。
Agent Engineは複数のユーザーを処理するセッション管理、品質維持のための評価とフィードバックループを提供します。
また、詳細な監視とトレース機能により、エージェントの内部動作やコストを把握でき、マネージドランタイムはインフラ管理を自動化し、標準的なGoogle Cloudツールによる堅牢なセキュリティを実現します。
これにより、開発者はエージェントの運用負荷を軽減し、開発に集中できます。
す、すごいぞ、至れり尽くせり of つくせり。
OSSプロトタイプから本番環境まで、全体フロー

プロトタイプ
* ローカルテスト
* モデル比較
* フレームワーク比較
構築
* ユーザーテスト
* 評価
* コスト分析
デプロイ
* デプロイテスト
* コンテナ化
* スケーリング
監視
* トレース実装
* 評価実行の設定
* コスト分析
OSSエージェントの開発は、ローカルでのプロトタイピングから始まり、様々なフレームワークやモデルの比較、コアロジックとツールの統合、テストを経て、デプロイメント段階に入ります。
このデプロイメントには、適切なパッケージング、Agent Engineのようなターゲット設定、アクセス制御が含まれており、その後はロギング、トレース、評価による継続的な監視と改善が行われます。
Agent Engineは、このデプロイと監視の段階を大幅に効率化し、リスクを軽減することを目指しています。
Walmart社事例
Walmart社は、およそ2〜3年前から生成AIの可能性に着目し、プロンプトエンジニアリングを中心としたアプローチで活用を模索していました。外部データや独自のデータセットを活用することで、一定の成果は得られたものの、動的なコンテンツの生成や、世界知識の活用には限界を感じていたそうです。

背景: 生成AIの導入以前は、顧客向け製品はウォルマート独自のデータを使用しており、事前学習済みのembeddings以外の世界の知識は限られていました。
これにより、1) 動的なコンテンツ生成、および 2) さらに強力な機械学習(ML)駆動ソリューションの構築 が制限されていました。生成AIはこれらの問題を解決する道筋を提供しました。しかしながら…
制約:
- 製品目標
- 我々は望む製品を構築しているか?
- ブランドガイドライン
- 製品がウォルマートらしく聞こえる/感じられるようにする
- ビジネスKPIの改善
- 我々は状況を改善することも重視する
- スケーラビリティ
- 1億人以上の顧客にスケールする製品を構築する
- 正確性
- 結果は事実として正確である必要がある
これらを既製のLLMを使用してバランスさせるのは困難でした。
また、コンテキストウィンドウだけで解決策にたどり着くことはできません!
より高度な活用を目指す中で、Walmart社は多くの制約と課題に直面しました。
単純にAIを導入するだけでなく、プロダクトの目標達成に貢献すること、ブランドイメージを維持し、Walmartらしい品質のコンテンツを提供すること、そして何よりもビジネスKPIを改善することでした。
さらに、数億の顧客に対応するための高いスケーラビリティ、それを支える高精度かつ高性能なモデルも不可欠でした。
初期には、コンテキストウィンドウの拡大が有効と考えられていましたが、実際には処理時間の遅延やコストの増大、そしてAIが事実に基づかない情報を生成するハルシネーションのリスクも顕在化しました。
これらの課題に対し、Walmart社はプロンプトエンジニアリング、Chain of Thought、強引なルールコーディング、ファインチューニングなど、様々なアプローチを検討しました。しかし、これらの手法では複雑な制約を満たすことが難しく、スケーラビリティにも課題が残りました。
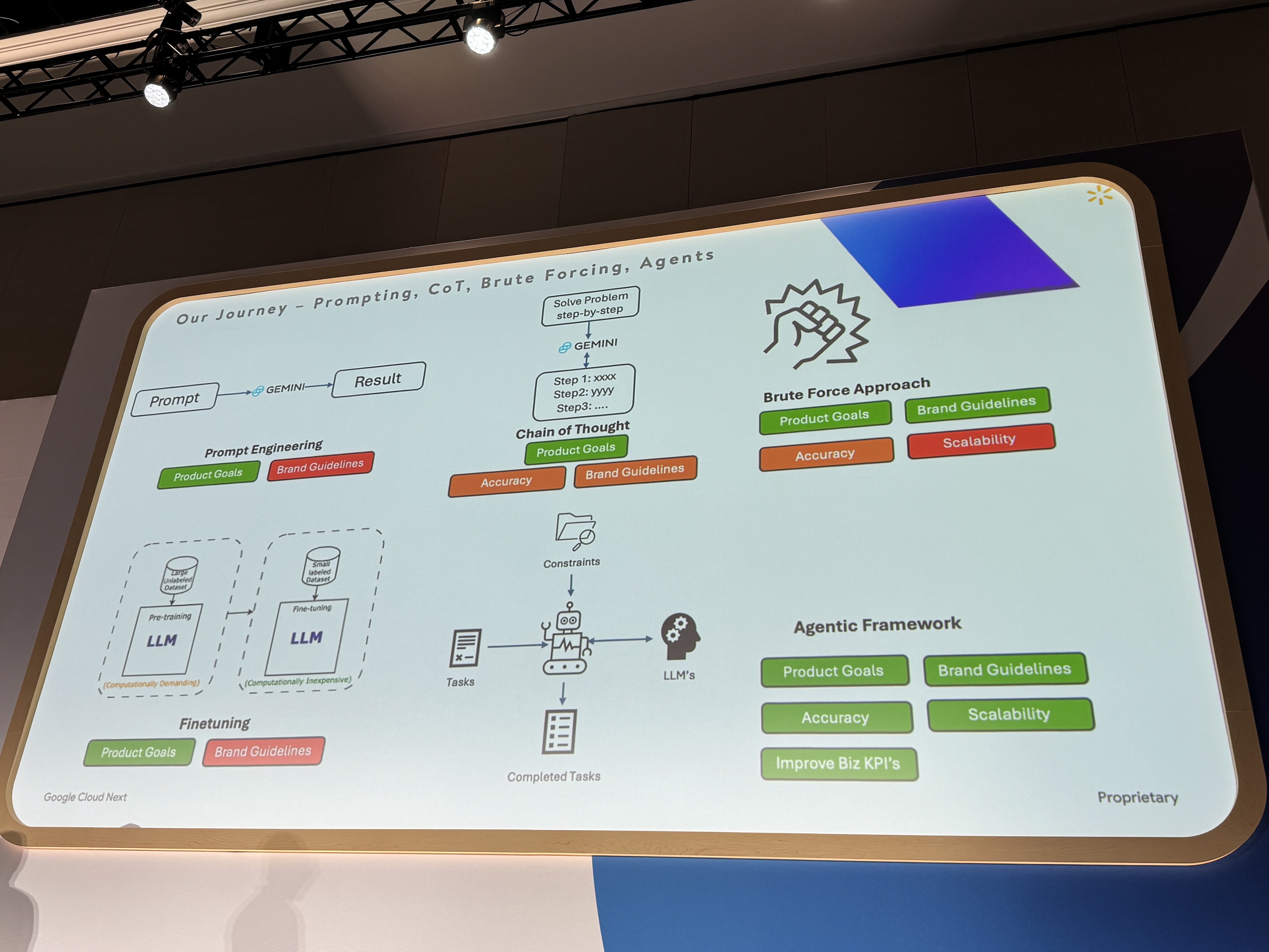
- プロンプトエンジニアリング (Prompt Engineering):
- 製品目標の達成には役立ったが、ブランドガイドラインの遵守にはあまり効果がなかった。
- 思考の連鎖 (Chain of Thought):
- プロンプトエンジニアリングよりは進歩したが、まだ十分ではなかった。
- ブルートフォースアプローチ (Brute Force Approach):
- ブランドガイドラインは比較的うまく扱えたが、制約間の優先順位付けや順序付けに慎重なハードコーディングが必要で、スケーラブルではなかった。
- ファインチューニング (Fine-tuning):
- 多少は役立ったが、主にデータセットや意味的な関連性の理解に使われ、制約の遵守を保証するものではなかった。
- エージェントフレームワーク (Agent Framework):
- 最終的に採用されたアプローチ。包括的なタスクを達成しつつ、多くのビジネス制約や創造的な制約を満たすのに役立つ。
そこでWalmart社が着目したのが、マルチエージェントフレームワークでした。
マルチエージェントとは、ご存知の通り、複数の独立したAIエージェントが連携し、一つの大きな目標を達成するために協調してタスクを実行するアプローチです。
Walmart社はこのフレームワークが、多くのビジネス上の制約や創造的な制約を満たし、全体的なタスク達成に貢献できると判断しました。
特に、複数のサブタスクを協調的に解決し、個々のサブタスクの制約を効率的に調整できる点、そしてプロダクトの複雑化に対応してサブタスクエージェントを柔軟に追加できる点が魅力でした。

次の課題として、
エージェント設計パターンの選択において、サブタスクの制約を満たしつつ包括的な目標達成が課題でした。
ツーリングエージェント、プランニングエージェント、ヒューマンインザループ、その他多くの種類のエージェントなどの設計パターンが存在します。
最終的には、すべてのサブタスク、サブタスクの制約が満たされることを保証できるように、達成できる包括的な目標を持つように決定したそうです。

開発開始時は、当時利用可能だったフレームワーク「AutoGen」を採用しました。
AutoGenは、新しいエージェントアーキテクチャの迅速なプロトタイピングや、エージェント間の連携方法を柔軟に定義できる点が魅力でした。
ラウンドロビンや順次実行、手動設定など、様々な会話パターンを試すことが可能です。
※AG2はAutoGenの派生フレームワークです
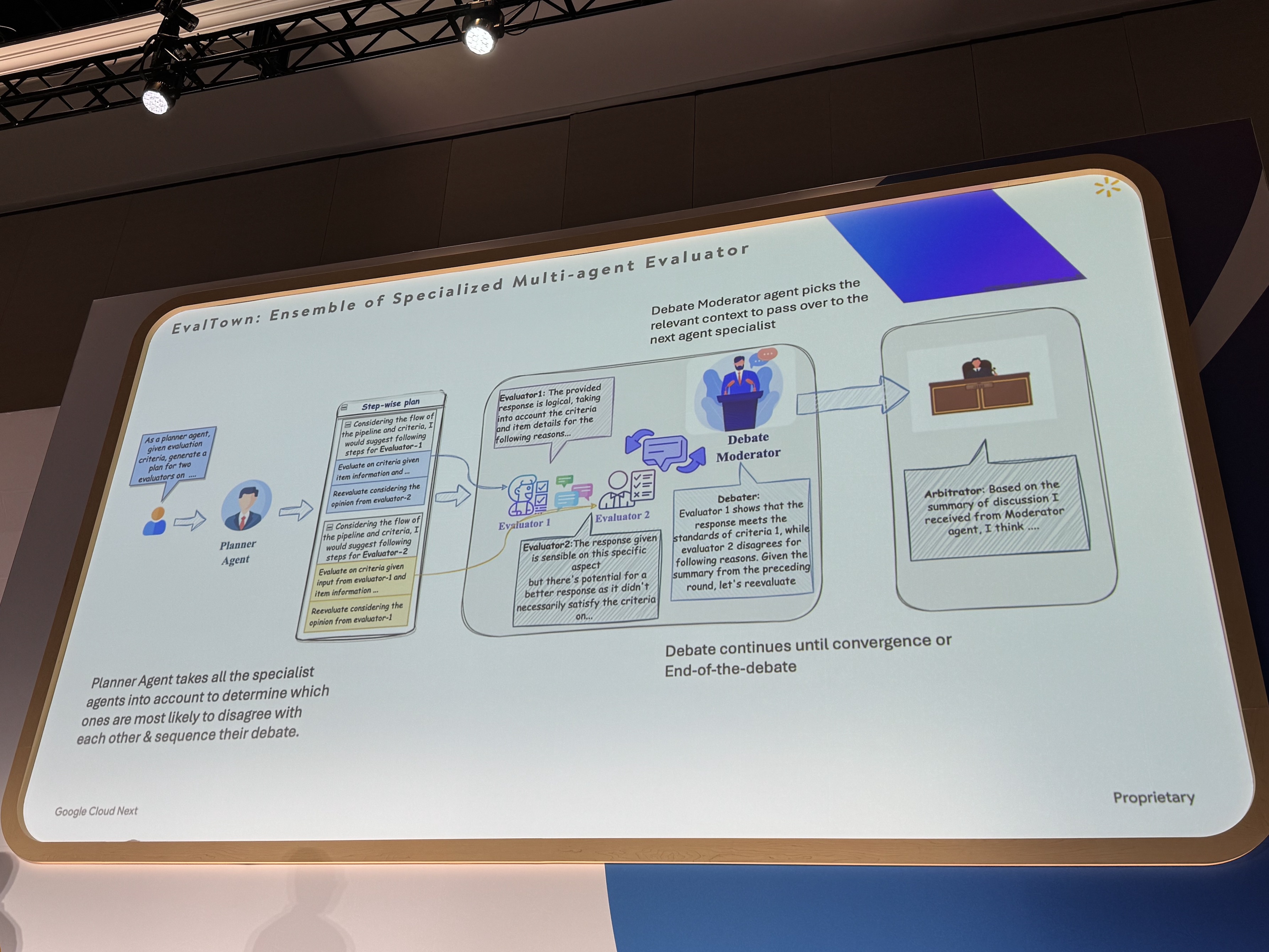
サブタスクの制約を確実に満たすため、新たにフレームワークを開発しました。
このシステムでは、プランナーがタスク順序を決定し、モデレーターが担当者と情報量を調整、最後にアービトレーターが成果を評価します。これにより、各専門家が必要な情報に集中でき、企業のように効率的かつ高品質なタスク遂行を実現します。
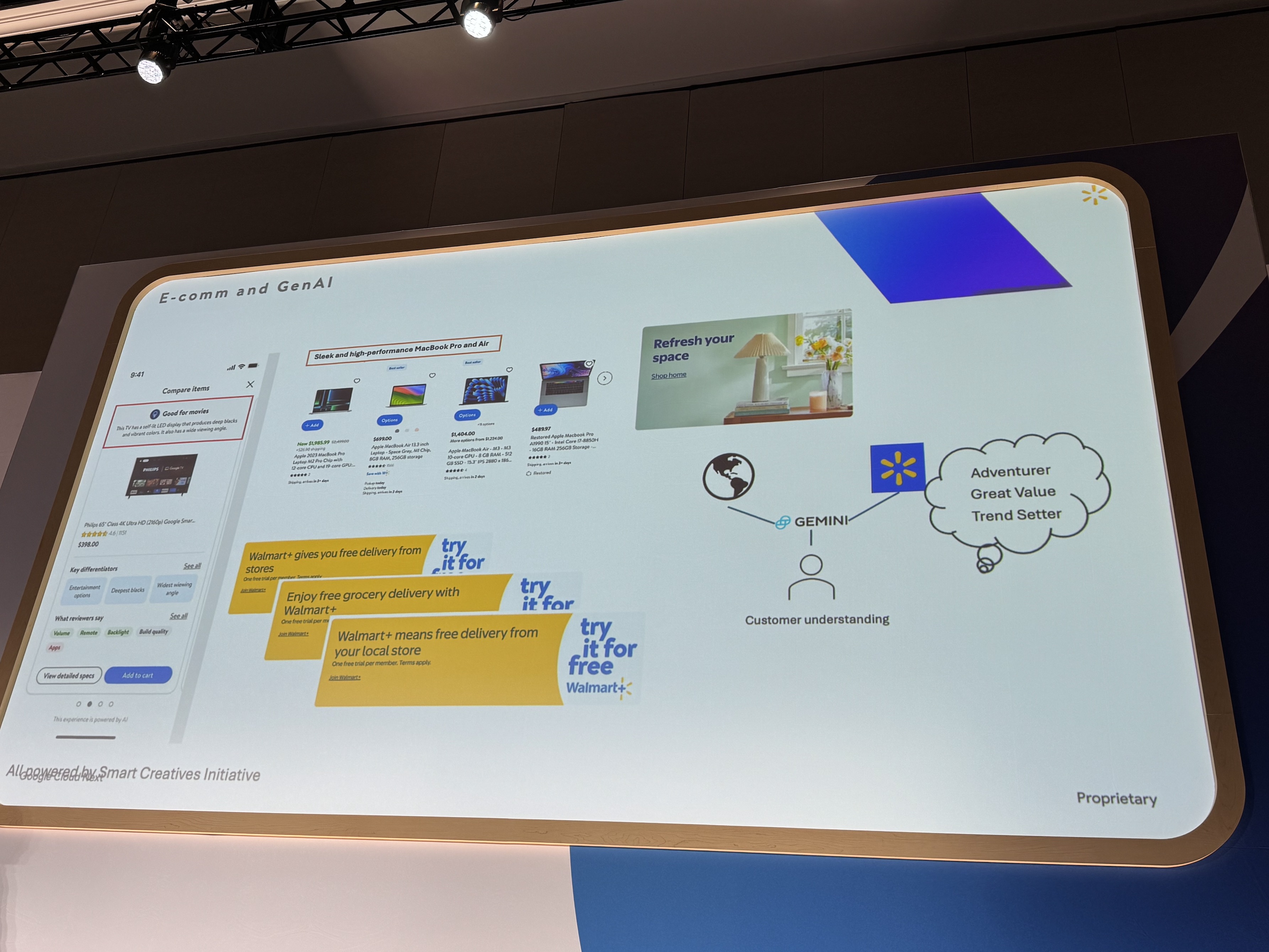
具体的な成果は、例えば、顧客が商品を購入する理由の分析、パーソナライズされた製品推奨タイトルやコンテンツの動的生成などです。
さらに、効果測定データに基づき、画像とテキストを組み合わせた新しいマーケティング資料を作成し、顧客理解を深めることにも成功しました。
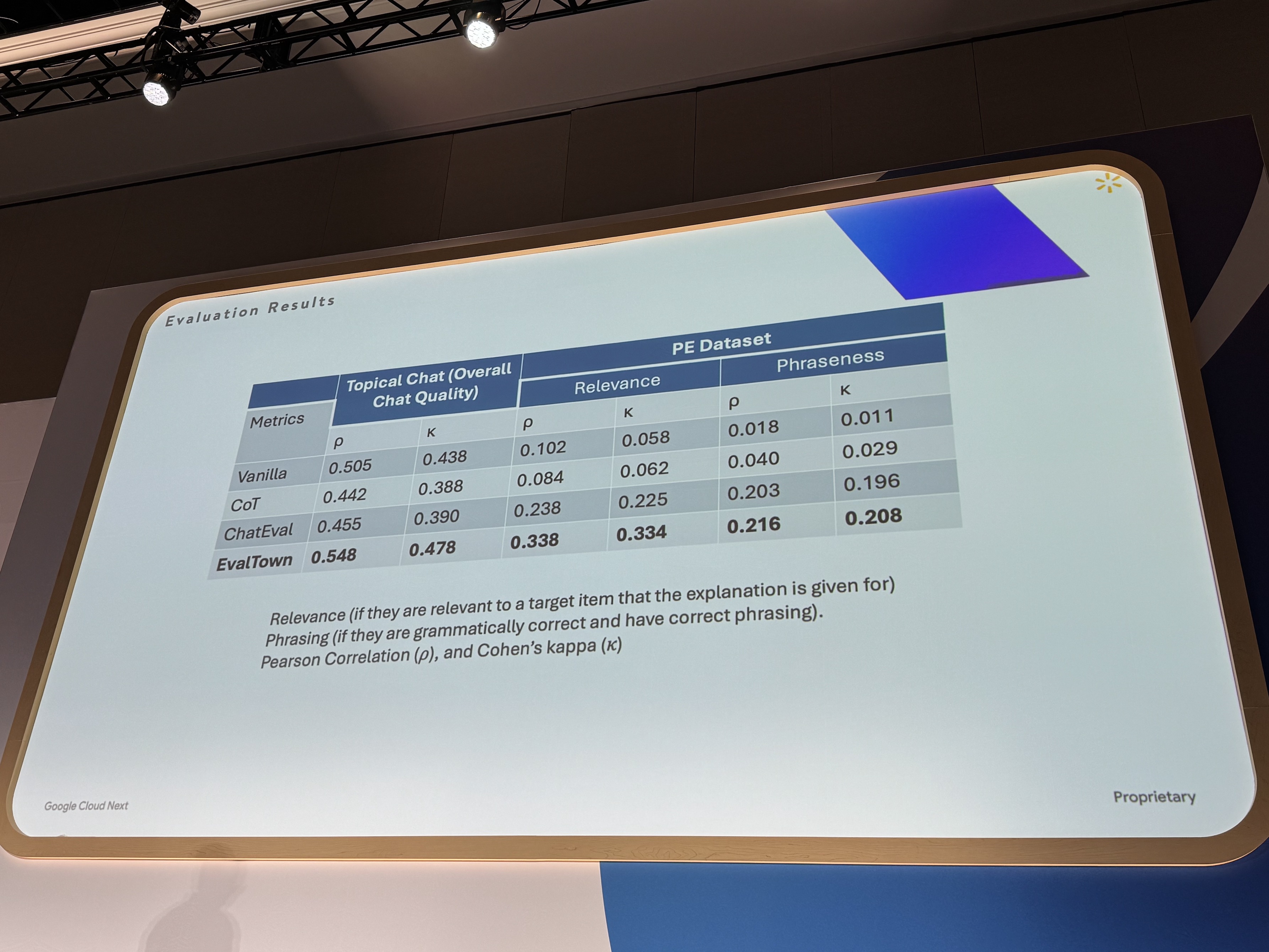
オフライン評価でオリジナルモデルを他モデルと比較したところ、興味深い結果が得られました。基盤となる言語モデル自体はよりシンプルであるにも関わらず、オリジナルモデルはいくつかのより複雑なモデルを上回る性能を示したのです。これは、コストが制約となる場合でも、エージェントフレームワークを活用することで、比較的シンプルなモデルでも高い性能を引き出せる可能性を示唆しています。
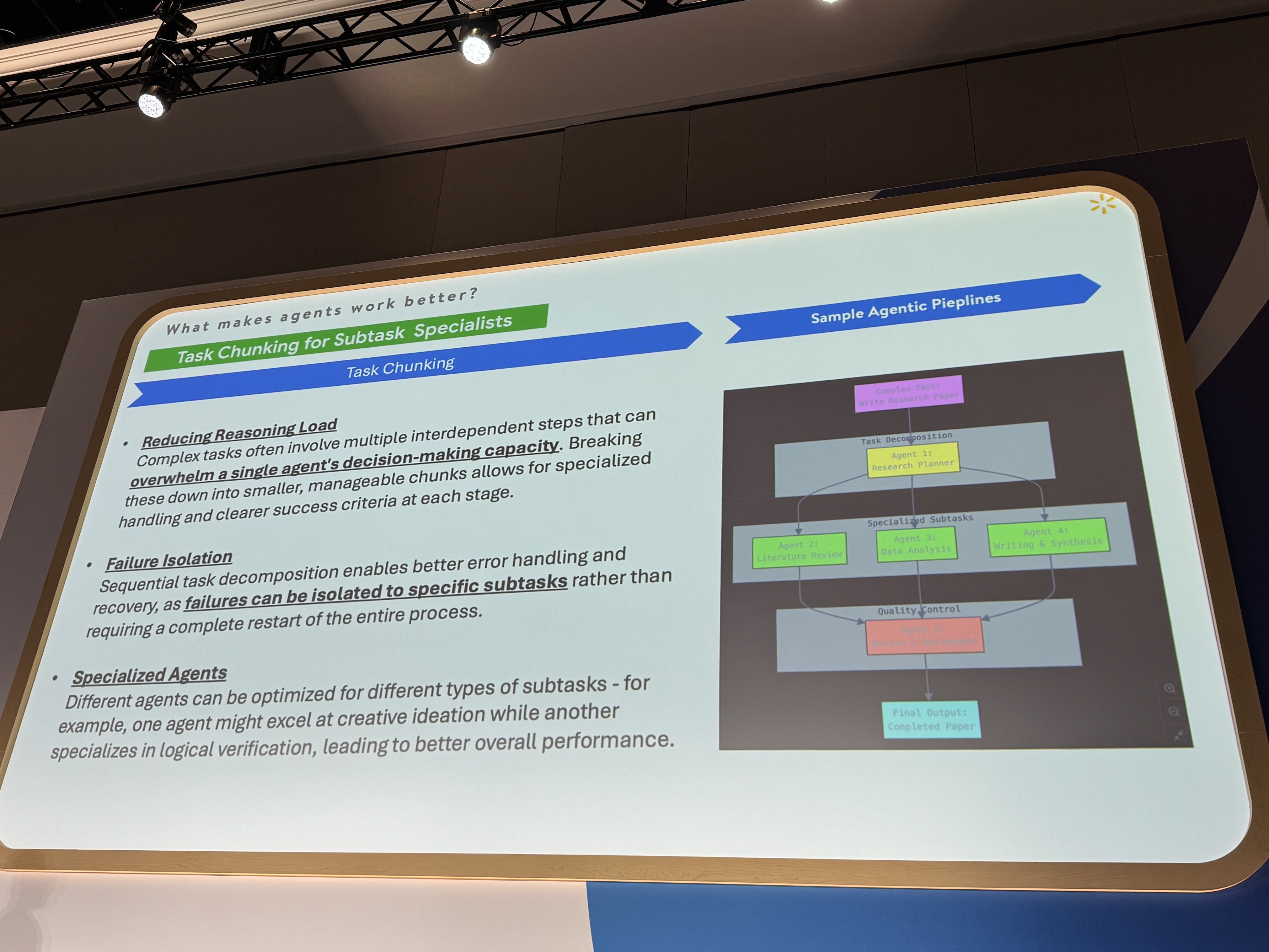
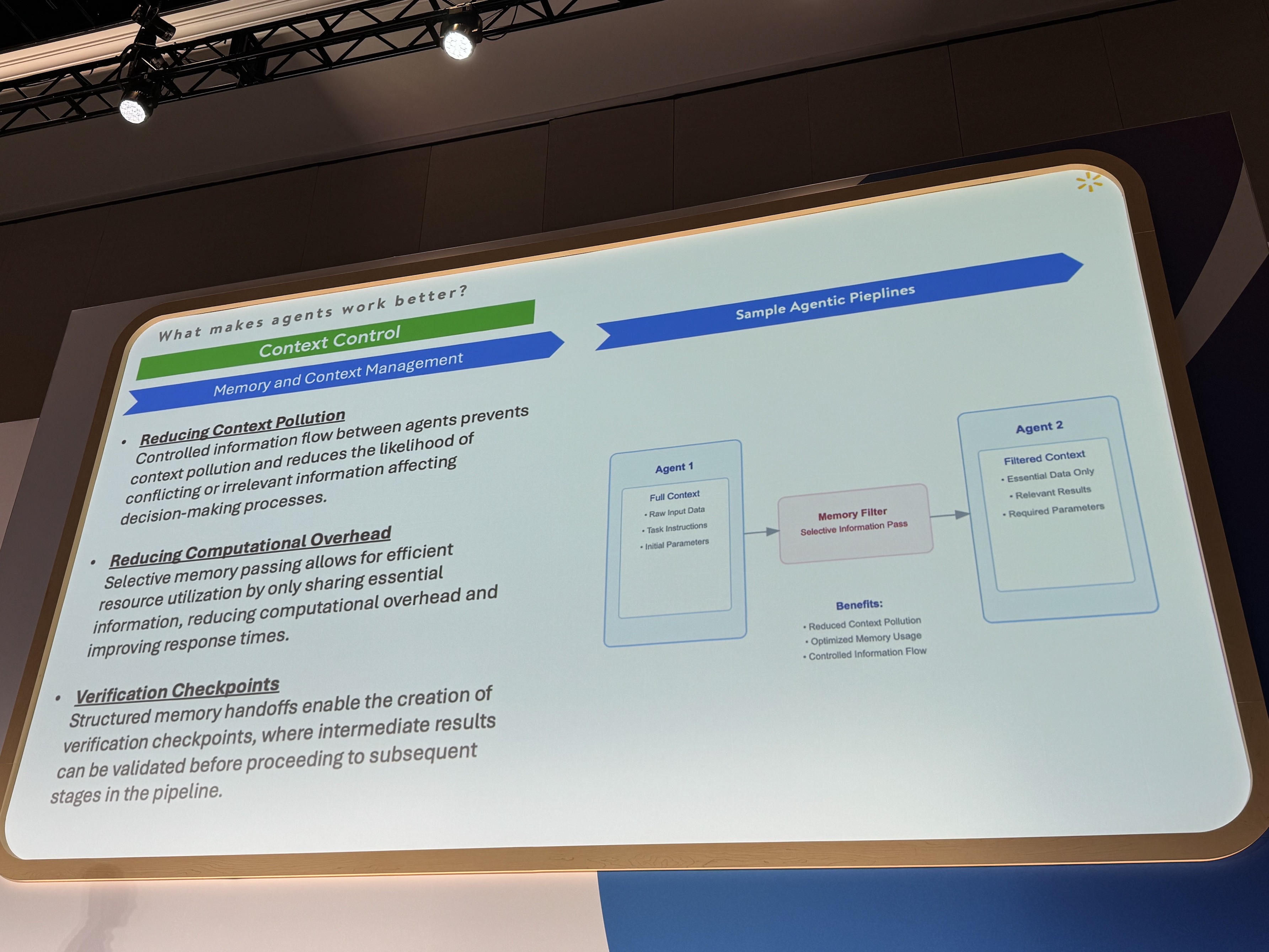

高性能なマルチエージェントフレームワーク、特に、Agent Engineのようなシステムを構築する上で、重要な学び、成功の鍵となるポイントは以下の3つです。
- タスクの分割: 大きな目標を、管理しやすいサブタスクに明確に分解すること。
- コンテキスト管理: 各スペシャリストエージェントに渡す情報量を適切に制限し、情報過多によるハルシネーションを防ぐこと。
- ツールとインフラ: 優れたツーリングとインフラ基盤を整備すること(Agent Engineがこれを容易にします)。
これらの原則に従うことで、より効率的で信頼性の高いエージェントシステムの構築が可能になります。
さいごに
AIエージェントのデプロイに関する課題や、Agent Engineに関する素晴らしいポイントを中心に見てきました。
インフラの設定に時間をかけず、やりたいアイデアをすぐに具現化できる、しかも好きなように開発できる、Agent Engine!の素晴らしさが身に沁みましたね。
また、Walmart社の事例では、マルチエージェント構築に関する、タスクの適切な分割、コンテキスト管理の最適化、そして堅牢なツールとインフラの整備が重要であること、…などなどの貴重なヒントが得られました。
Google Cloudならエージェント開発も怖くない!ですね!




