
はじめに
こんにちは、一番好きなAWSサービスは「Amazon Athena」のMitsuoです。
Xでも話題になっているAmazon Athenaの新機能について検証してみました。
画期的な機能ではないものの、普段からAmazon Athenaを使っている方には待望のアップデートではないでしょうか。
Amazon Athena announces managed query results to streamline analysis workflows
新機能「マネージドクエリ結果(managed query results) 」について
以下は公式URLからの抜粋です。
AWS Big Data Blog:Introducing managed query results for Amazon Athena
That’s why we’re thrilled to introduce managed query results, a new Athena feature that automatically stores, secures, and manages the lifecycle of query result data for you at no additional cost. Managed query results simplifies your user experience by removing the need to create or choose an S3 bucket in your account to hold results before you run queries. It helps reduce your monthly cost by shifting temporary storage of query results from your S3 bucket to Athena, and eliminates the need for separate processes to delete query result data from your S3 bucket after it’s no longer needed. Now, Athena offers both service managed, temporary result storage and customer managed Amazon S3 storage options to meet different needs. What’s more, using managed query results doesn’t require complex changes to applications that read query results from existing Athena interfaces, and increases data security. Access to managed query result data is now associated with AWS Identity and Access Management (IAM) permissions scoped to individual Athena workgroups, instead of S3 buckets. Additionally, you can automatically encrypt result data with AWS Key Management Service (AWS KMS) using AWS owned or customer managed keys.
一言で言うと「初期設定で必要であったAmazon Athenaのクエリ実行結果のS3バケットを作成、設定しなくて良い機能」です。
クエリ実行結果がAWS側に管理されます。
上記に記載されている通り、クエリ実行結果を閲覧する権限がS3に対してではなくAthena側になっている事も特徴です。
また、AWS管理、顧客管理のKMSで暗号化、アクセス制限することも可能です。
Amazon Athenaを頻繁に利用される会社、アナリストであれば分析の種類に応じてワークグループ(分析するための論理的なグループ)を分割する事になります。従来の仕様では、ワークグループ単位でS3バケットの設定が必要ですが、これが不要になります。
加えて、S3バケットのリソース管理も必要なので、ログの保管料をおさえるためライフサイクルの設定等も勿論必要です。
ふとAmazon Athenaを使いたいとなった時に「S3バケットの設定してない、面倒だな」と感じた方はいらっしゃるのではないでしょうか。(僕だけですかね?贅沢?笑)
実際に確認してみる
具体的な操作手順を確認されたい方は、以前、私が投稿した記事澤田先輩と優しく学ぶAmazon Athenaをご参照ください。
ワークグループの作成手順は基本的に変更はありません。
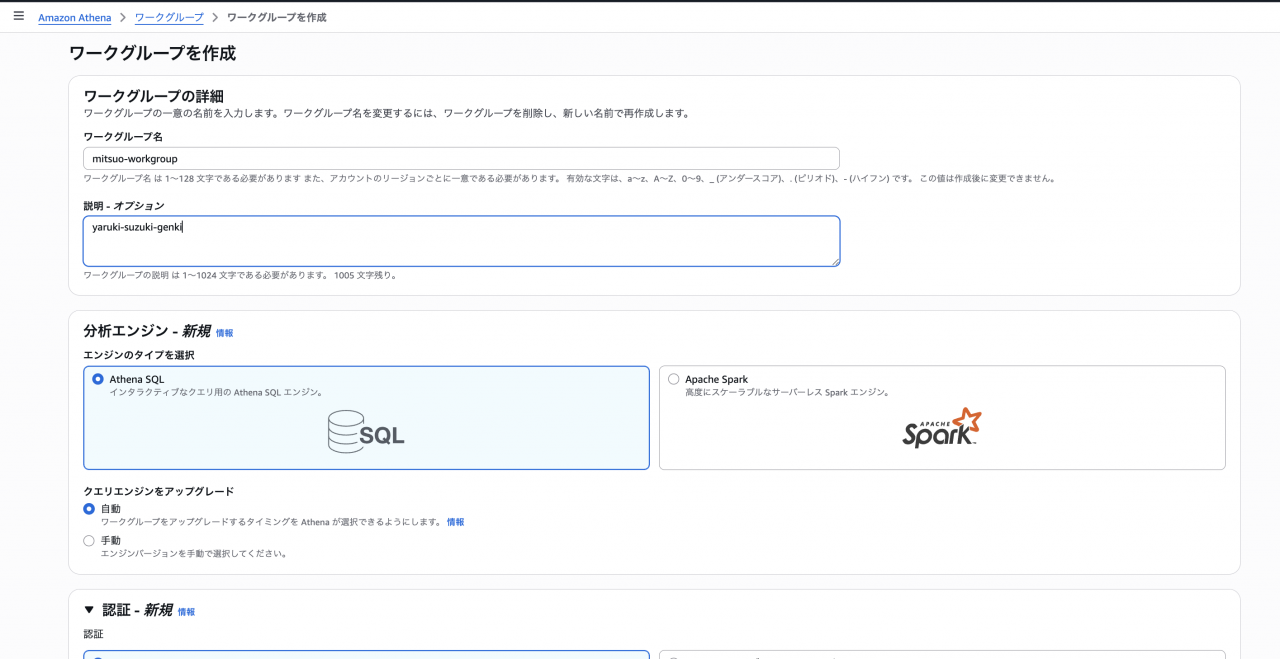
クエリ結果の設定で「Athenaマネージド」と「カスタマーマネージド」が選択できるようになっています。

この「Athenaマネージド」が新機能、「カスタマーマネージド」が従来型(S3を利用者が設定するもの)です!!
実際にクエリを実行できるかまで確認してみます。
CloudTrailの証跡用S3バケットを作成し、データソースとして使います。
データベースは「default」でProjection Partitionでリージョン、日付毎に論理分割できるテーブルを作成します。
サンプルクエリは以下の通り
CREATE EXTERNAL TABLE test_cloudtrail_logs(
eventVersion STRING,
userIdentity STRUCT<
type: STRING,
principalId: STRING,
arn: STRING,
accountId: STRING,
invokedBy: STRING,
accessKeyId: STRING,
userName: STRING,
sessionContext: STRUCT<
attributes: STRUCT<
mfaAuthenticated: STRING,
creationDate: STRING>,
sessionIssuer: STRUCT<
type: STRING,
principalId: STRING,
arn: STRING,
accountId: STRING,
userName: STRING>,
ec2RoleDelivery:string,
webIdFederationData: STRUCT<
federatedProvider: STRING,
attributes: map<string,string>
>
>
>,
eventTime STRING,
eventSource STRING,
eventName STRING,
awsRegion STRING,
sourceIpAddress STRING,
userAgent STRING,
errorCode STRING,
errorMessage STRING,
requestparameters STRING,
responseelements STRING,
additionaleventdata STRING,
requestId STRING,
eventId STRING,
readOnly STRING,
resources ARRAY<STRUCT<
arn: STRING,
accountId: STRING,
type: STRING>>,
eventType STRING,
apiVersion STRING,
recipientAccountId STRING,
serviceEventDetails STRING,
sharedEventID STRING,
vpcendpointid STRING,
eventCategory STRING,
tlsDetails struct<
tlsVersion:string,
cipherSuite:string,
clientProvidedHostHeader:string>
)
PARTITIONED BY (
region string,
`date` string)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://aws-cloudtrail-logs-mitsuo-XXXXXXXXX/AWSLogs/NNNNNNNNNNNN/CloudTrail/'
TBLPROPERTIES (
'projection.enabled'='true',
'projection.date.format'='yyyy/MM/dd',
'projection.date.interval'='1',
'projection.date.interval.unit'='DAYS',
'projection.date.range'='2023/01/01,NOW',
'projection.date.type'='date',
'projection.region.type' = 'enum',
'projection.region.values'='ap-northeast-1,ap-northeast-2,ap-northeast-3,ap-south-1,ap-southeast-1,ap-southeast-2,ca-central-1,eu-central-1,eu-north-1,eu-west-1,eu-west-2,eu-west-3,sa-east-1,us-east-1,us-east-2,us-west-1,us-west-2',
'storage.location.template'='s3://aws-cloudtrail-logs-mitsuo-XXXXXXXXX/AWSLogs/NNNNNNNNNNNN/CloudTrail/${region}/${date}')
作成したテーブルで6月7日に出力されたAPIアクションを出力するSECECTクエリを実行します。
SELECT eventTime, userIdentity.type, useridentity.arn, useridentity.username, eventSource, eventName, awsRegion, sourceIpAddress, userAgent FROM test_cloudtrail_logs WHERE eventTime between '2025-06-06T15:00:00Z' AND '2025-06-07T15:00:00Z' AND date = '2025/06/07' ORDER BY eventTime
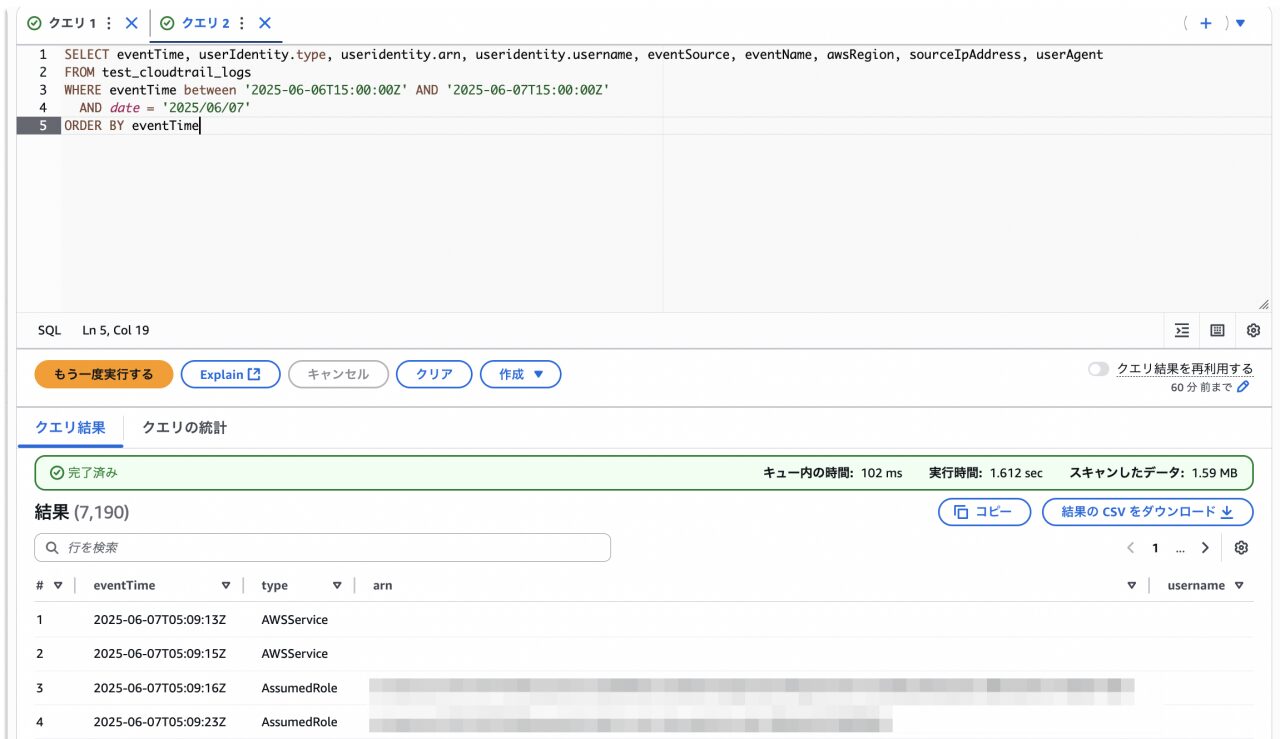
「結果のCSVをダウンロード」をクリックします。

ダウンロード画面に遷移し、しばらくするとダウンロードに成功したメッセージが表示されました。
モザイクをかけるところが多くスクリーンショットを添付していないですが、エディタで開くと今までと同様のフォーマットで出力を確認できました。
なお、マネージドクエリ結果はAPIにも対応しています。
CloudShellで実行したサンプルは以下の通りです。
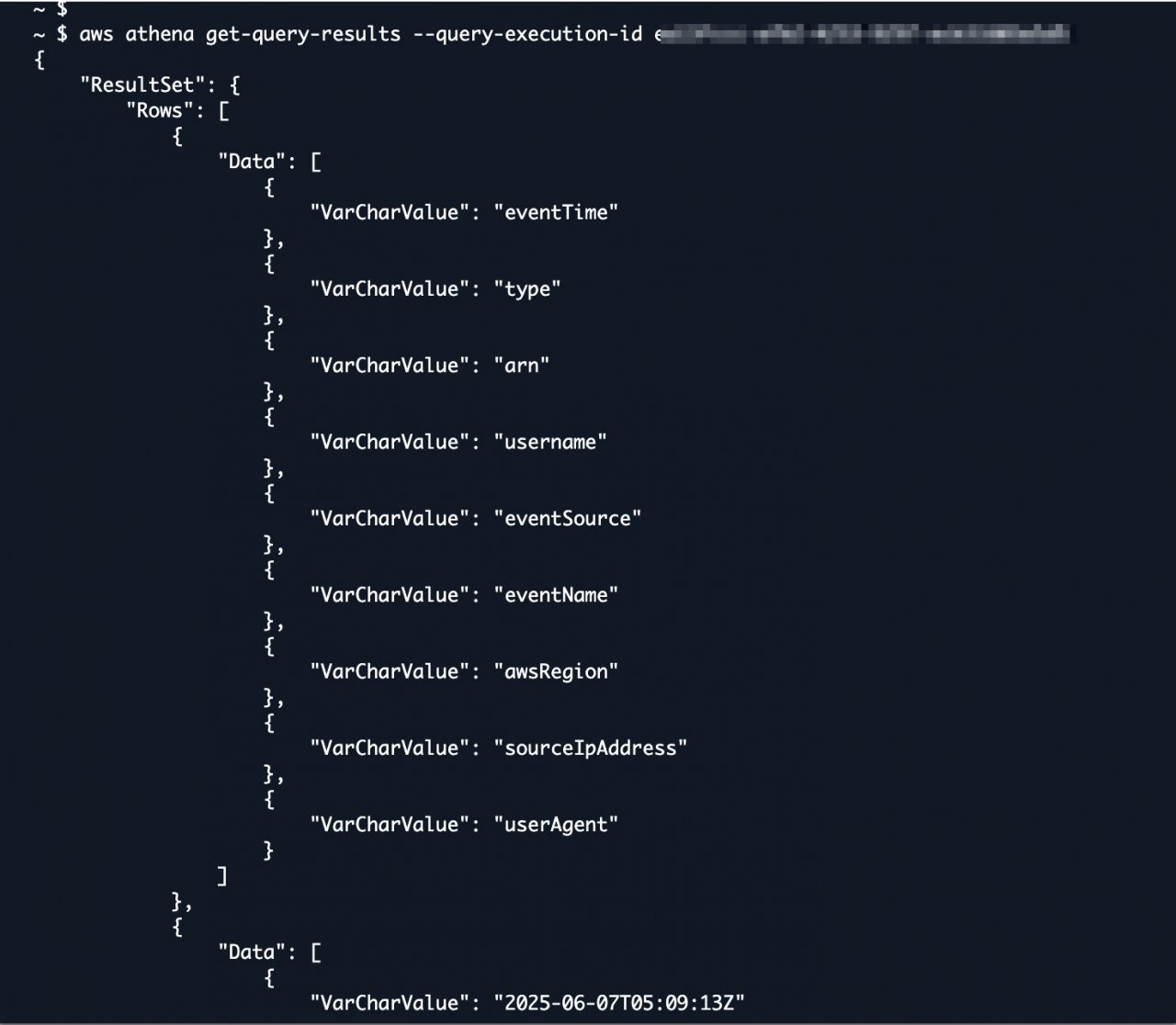
クエリ実行IDは、クエリエディタの最新のクエリから確認する事が可能です。
制約事項
公式ドキュメントのConsiderations and limitationsに記載があります。
Access to query results is managed at the workgroup level in Athena. For this, you need explicit permissions to GetQueryResults and GetQueryResultsStream IAM actions on the specific workgroup. The GetQueryResults action determines who can retrieve the results of a completed query in a paginated format, while the GetQueryResultsStream action determines who can stream the results of a completed query (commonly used by Athena drivers). You cannot download query result files larger than 200 MB from the console. Use the UNLOAD statement to write results larger than 200 MB to a location that you can download separately. Managed query results feature does not support Query result reuse. Query results are available for 24 hours. Query results are stored at no cost to you during this period. After this period, query results are automatically deleted. Athena ODBC 2.x drivers can't retrieve query results using the Amazon S3 result fetcher configuration. For ODBC 2.x drivers, you must disable the EnableS3Fetcher to work with managed query results.
冒頭に書いた通り、アクセス権限がAthena側のアクションに変わるため、GetQueryResultsとGetQueryResultsStreamの明示的な許可が必要です。
また、ここが大きいと思っていますが、200MBを超えるダウンロードやクエリの再使用は出来ません。
そのため、利用者の使用用途によっては該当しない場合があるため注意が必要です。
最後に
いかがだったでしょうか。利用者が使いやすくなるようなアップデートを定期的にかけてくれるAWSの魅力を改めて感じました。
Amazon Athenaを使った事ない人が興味を持つきっかけになる記事となれば幸いです。
勉強になります。Mitsuoでした。


