
はじめに
前回の記事では、PDFドキュメントをベクトル化してOpenSearchに格納する処理を実装しました。今回は、RAGシステムの最も重要な部分、ユーザーの質問に対して適切な情報を検索し、LLMで自然な回答を生成する処理を実装していきます。
この処理は、RAGの「Retrieval(検索)」と「Generation(生成)」の両方を含む、まさにシステムの心臓部です。
実装する機能の全体像
今回実装するRAGハンドラーの処理フローは以下の通りです。
[ユーザー入力] 質問文を受け取る
↓
[DynamoDB] ユーザー情報を取得
↓
[Bedrock: Titan Embeddings] 質問をベクトル化
↓
[OpenSearch] kNN検索で類似ドキュメントを取得
↓
[Lambda: build_prompt] ユーザー情報 + 参考文書 + 質問を統合
↓
[Bedrock: Claude 3.5 Sonnet v2] LLMで回答を生成
↓
[レスポンス] パーソナライズされた回答を返す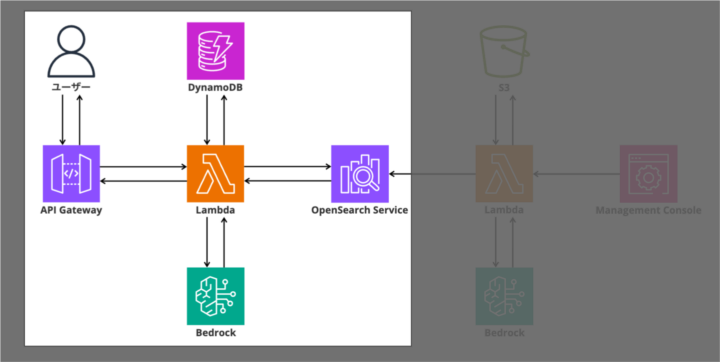
Step 1: 初期化とインポート (rag_handler)
これから、ユーザーの質問に対して検索と回答生成を行うrag_handlerというLambda関数を作成します。まずは、必要なライブラリのインポートとAWSクライアントの初期化から見ていきましょう。
import json
import os
import boto3
import requests
from requests_aws4auth import AWS4Auth
# クライアント初期化
dynamodb = boto3.resource("dynamodb")
bedrock = boto3.client("bedrock-runtime")
session = boto3.Session()
credentials = session.get_credentials().get_frozen_credentials()
service = "es"
# 環境変数から設定を取得
CLAUDE_INFERENCE_PROFILE_ID = os.environ["BEDROCK_CLAUDE_INFERENCE_PROFILE_ID"]
TITAN_MODEL_ID = os.environ["BEDROCK_TITAN_MODEL_ID"]
TABLE_NAME = os.environ["DYNAMO_TABLE"]
OPENSEARCH_ENDPOINT = os.environ["OPENSEARCH_ENDPOINT"]
OPENSEARCH_INDEX = os.environ.get("OPENSEARCH_INDEX", "documents")
region = os.environ["AWS_REGION"]
awsauth = AWS4Auth(
credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token
)
ファイルの冒頭では、DynamoDB、Bedrock、OpenSearchへのアクセスに必要なクライアントを初期化しています。
HTTPリクエストにはrequestsライブラリを使用し、OpenSearchへの署名付きリクエストにはAWS4Authを使用します。環境変数から各種設定を取得することで、デプロイ時にCDKから値を注入できるようにしています。
Step 2: Lambda関数のエントリーポイント (rag_handler)
def lambda_handler(event, context):
try:
body = json.loads(event["body"]) if "body" in event else event
user_id = body.get("user_id", "default")
user_input = body.get("query", "")
# 1. DynamoDBから状況コンテキストを取得
table = dynamodb.Table(TABLE_NAME)
response = table.get_item(Key={"user_id": user_id})
item = response.get("Item", {})
context_lines = [f"{key}: {value}" for key, value in item.items()]
context_text = "\n".join(context_lines)
# 2. Bedrockで埋め込みベクトル作成
vector = get_embedding(user_input)
# 3. OpenSearchでベクトル検索
similar_contents = semantic_search(vector)
# 4. プロンプトを構築
prompt = build_prompt(context_text, similar_contents, user_input)
# 5. Bedrock で応答を生成
answer = generate_response(prompt)
return {
"statusCode": 200,
"body": json.dumps({"prompt": prompt, "answer": answer}, ensure_ascii=False),
}
except Exception as e:
return {"statusCode": 500, "body": json.dumps({"error": str(e)}, ensure_ascii=False)}
lambda_handlerは、RAGシステムの全体フローを制御するメイン関数です。
入力の処理では、API Gateway経由の場合はevent[“body”]にJSON文字列が入り、Lambda直接呼び出しの場合はevent自体がdictになるため、両方に対応しています。
コメントで明示している5つのステップを順番に実行し、最後にプロンプトと回答の両方を返すことで、デバッグやログ確認が容易になります。5つのステップの詳細な処理については以降で説明します。
Step 3: DynamoDBからユーザー情報を取得 (rag_handler)
lambda_handler内の1番目の処理を詳しく見ていきます。
# 1. DynamoDBから状況コンテキストを取得
table = dynamodb.Table(TABLE_NAME)
response = table.get_item(Key={"user_id": user_id})
item = response.get("Item", {})
context_lines = [f"{key}: {value}" for key, value in item.items()]
context_text = "\n".join(context_lines)
なぜユーザー情報が必要なのか
今回のRAGシステムは生命保険のプラン提案を行うため、以下のような個人情報が重要です。
- 年齢
- 家族構成
- 職業
- 収入
- 現在の保険状況
- 将来の不安
事前に、DynamoDBに以下のような形式でユーザーデータを格納しておいてください。
{
"user_id": "user_001",
"age": 35,
"family": "妻・子供2人",
"occupation": "会社員",
"income": "600万円",
"current_insurance": "なし",
"concerns": "家族の将来が心配"
}このデータをkey: value形式の文字列に変換し、改行で結合することで、プロンプトに埋め込みやすい形式にしています。
なぜDynamoDBを選んだのか
今回は以下の理由でDynamoDBを選択しました。
- サーバーレス – インフラ管理が不要
- 低コスト – 少量のアクセスであればほぼ無料
- 高速アクセス – ミリ秒単位でのレスポンス
- スケーラビリティ – 将来的な負荷増加に対応可能
他のデータベースでも代替可能
ユーザー情報の取得部分は、データベースの種類に依存しません。本番環境や既存システムとの統合を考慮する場合、以下のようなデータベースでも問題なく利用できます。
- Amazon RDS(PostgreSQL、MySQL) – リレーショナルデータベースでの管理が必要な場合
- Amazon Aurora – 高可用性とパフォーマンスが求められる場合
- Amazon Redshift – データウェアハウスと統合する場合
- 既存のオンプレミスDB – VPN接続やAWS Direct Connect経由でアクセス
データベースを変更する場合は、lambda_handler内のDynamoDBクライアントの部分を該当するデータベースのクライアントに置き換えるだけで対応できます。
# DynamoDBの場合(現在)
table = dynamodb.Table(TABLE_NAME)
response = table.get_item(Key={"user_id": user_id})
item = response.get("Item", {})
# RDS(PostgreSQL)の場合(例)
# import psycopg2
# conn = psycopg2.connect(database=DB_NAME, user=DB_USER, password=DB_PASSWORD, host=DB_HOST)
# cur = conn.cursor()
# cur.execute("SELECT * FROM users WHERE user_id = %s", (user_id,))
# item = dict(cur.fetchone())Step 4: ユーザーの質問をベクトル化 (rag_handler)
def get_embedding(text):
payload = {"inputText": text}
response = bedrock.invoke_model(
modelId=TITAN_MODEL_ID,
body=json.dumps(payload),
contentType="application/json",
accept="application/json",
)
body = json.loads(response["body"].read())
vector = body.get("embedding")
if not vector:
raise ValueError(f"Empty embedding from Bedrock: {body}")
return vector
ユーザーの質問(例: 「私に最適な保険のプランはどれですか?」)をTitan Embeddingsで1536次元のベクトルに変換します。
レスポンスボディからembeddingフィールドを取得し、空の場合はエラーを発生させることで、確実にベクトルが取得できたことを保証しています。
このベクトルを使って、インデックス処理で登録したドキュメントとの類似度を計算します。
Step 5: OpenSearchでベクトル検索 (rag_handler)
def semantic_search(vector):
url = f"https://{OPENSEARCH_ENDPOINT}/{OPENSEARCH_INDEX}/_search"
payload = {"size": 3, "query": {"knn": {"vector": {"vector": vector, "k": 3}}}}
headers = {"Content-Type": "application/json"}
response = requests.post(url, auth=awsauth, json=payload, headers=headers)
if response.status_code != 200:
raise ValueError(f"OpenSearch error: {response.status_code} - {response.text}")
res_json = response.json()
if "hits" not in res_json:
raise ValueError(f"Invalid OpenSearch response: {res_json}")
return [hit["_source"]["content"] for hit in res_json["hits"]["hits"]]
k近傍法(kNN)による検索
OpenSearchのkNN検索により、質問ベクトルと最も近い上位3件のドキュメントを取得します。
payloadの構造を見ると、size: 3で最大3件、k: 3でk近傍法のk値を3に設定しています。
エラーハンドリングを2段階で行っています。
- HTTPステータスコードが200以外の場合
- レスポンスにhitsフィールドが含まれない場合
最後に、リスト内包表記で各ヒットのcontentフィールドのみを抽出して返しています。
検索結果の例
[ "プランA: 死亡保障3000万円、月額保険料8000円...", "プランB: 死亡保障5000万円、月額保険料12000円...", "プランC: 医療保障重視、月額保険料6000円..." ]
これらの関連ドキュメントが、LLMへの入力となります。
Step 6: プロンプトの構築 (rag_handler)
def build_prompt(context_text, docs, user_input):
doc_section = "\n\n".join(docs)
return f"""あなたは、生命保険に精通した信頼できるアドバイザーです。
ユーザーは、年齢・家族構成・職業・収入・現在の保険状況・将来の不安などをもとに、最適な生命保険プランを探しています。
あなたの役割は、ユーザーの状況と意図を正確に汲み取り、最適な提案を行うことです。
【方針】
- 専門用語は必要に応じてわかりやすく説明してください
- 勧誘は行わず、常に中立的・顧客本位の視点で提案を行ってください
- ユーザーの目的(例:家族の安心、老後の備え、万が一の保障など)を特に重視してください
- 不足情報がある場合は、適切な質問で補うようにしてください
- 「おすすめプランA」のように明確に提案し、理由を簡潔に説明してください
【状況】
{context_text}
【参考文書】
{doc_section}
【ユーザからの質問】
{user_input}
【回答】
"""
ユーザー情報、検索で取得した参考文書、ユーザーの質問を統合して、LLMに渡すプロンプトを構築します。RAGシステムの品質を左右する最も重要な部分です。
プロンプト設計のポイント
プロンプトは以下の構造になっています。
- 役割の明確化 – 「生命保険に精通した信頼できるアドバイザー」として振る舞うよう指示
- 方針の指定 – 中立的、顧客本位、わかりやすく説明するよう指示
- ユーザー情報 – DynamoDBから取得した個人情報(context_text)
- 参考文書 – OpenSearchから取得した関連ドキュメント(docs)を改行2つで結合
- ユーザーの質問 – 実際の入力(user_input)
この構造により、事実に基づいた、パーソナライズされた回答が生成されます。
箇条書きの方針を明示することで、LLMの出力を制御し、勧誘的な表現を避け、常に顧客本位の提案を行うよう誘導しています。
Step 7: Claude 3.5 Sonnet v2で応答を生成 (rag_handler)
def generate_response(prompt: str) -> str:
"""Bedrock の生成系モデルにプロンプトを渡して応答を得る"""
payload = {
"anthropic_version": "bedrock-2023-05-31",
"messages": [{"role": "user", "content": prompt}],
"max_tokens": 1024,
}
response = bedrock.invoke_model(
modelId=CLAUDE_INFERENCE_PROFILE_ID,
body=json.dumps(payload),
contentType="application/json",
accept="application/json",
)
body = json.loads(response["body"].read())
return body["content"][0]["text"]
構築したプロンプトをBedrockのClaude 3.5 Sonnet v2に渡して、自然な回答を生成します。
Claude 3.5 Sonnet v2の呼び出し
payloadの構造を見ると、Anthropic Claude APIのフォーマットに従っています。
- anthropic_version – APIのバージョン指定
- messages – 会話履歴(今回はユーザーの1メッセージのみ)
- max_tokens – 最大1024トークンの応答を生成
レスポンスは、body[“content”][0][“text”]でテキスト部分のみを取り出しています。Claudeは複数のcontentブロックを返す可能性がありますが、今回はテキストのみなので最初の要素を使用しています。
なぜClaude 3.5 Sonnet v2を選んだのか
Claude 3.5 Sonnet v2は、2024年10月にリリースされたAnthropicのモデルです(2025年12月現在、最新の高性能モデルの一つです)。今回採用した理由は以下の通りです。
- 最新の性能 – Claude 3.5 Sonnet v1の2倍の処理速度を実現
- 高い推論能力 – 複雑な情報を整理して的確な提案ができる
- 優れた日本語対応 – 保険のような専門分野でも自然で正確な説明が可能
- Cross-Region Inference対応 – APACリージョンの推論プロファイルで東京リージョンから利用可能
- コスト効率 – 高性能ながら従来のClaude 3 Sonnetと同等の価格
推論プロファイルの活用
今回は以下の推論プロファイルを使用しています。
CLAUDE_INFERENCE_PROFILE_ID = "apac.anthropic.claude-3-5-sonnet-20241022-v2:0"
推論プロファイルを使用することで、複数のリージョンに自動的に負荷分散され、高い可用性とパフォーマンスを実現しています。
将来的なモデル更新
Claude 4シリーズなど、より新しいモデルがリリースされた場合、環境変数BEDROCK_CLAUDE_INFERENCE_PROFILE_IDを変更するだけで簡単に移行できる設計になっています。
# 現在(Claude 3.5 Sonnet v2) CLAUDE_INFERENCE_PROFILE_ID = "apac.anthropic.claude-3-5-sonnet-20241022-v2:0" # より新しいモデルに移行する場合(将来) # CLAUDE_INFERENCE_PROFILE_ID = "apac.anthropic.claude-4-xxxxx-v1:0"
コードの変更は不要で、CDKスタックの環境変数を更新して再デプロイするだけでモデルをアップグレードできます。
全体の処理フロー (rag_handler)
ここまでで実装した関数の呼び出し関係を整理すると、以下のようになります。
lambda_handler ├─ DynamoDB操作(ユーザー情報取得) ├─ get_embedding(質問のベクトル化) ├─ semantic_search(OpenSearch検索) │ └─ requests.post(HTTP API呼び出し) ├─ build_prompt(プロンプト構築) └─ generate_response(Claude呼び出し)
実際の動作例
入力
{
"user_id": "user_001",
"query": "私に最適な保険のプランはどれですか?"
}DynamoDBから取得されたユーザー情報
user_id: user_001 age: 35 family: 妻・子供2人 occupation: 会社員 income: 600万円 current_insurance: なし concerns: 家族の将来が心配
OpenSearchから取得された関連ドキュメント
プランA: 死亡保障3000万円、月額保険料8000円、家族向け プランB: 死亡保障5000万円、月額保険料12000円、高額保障 プランC: 医療保障重視、月額保険料6000円、医療費カバー
LLMが生成した回答(例)
35歳で会社員、妻とお子様2人をお持ちの方には、 「プランA」をおすすめいたします。 理由 家族構成に適した死亡保障3000万円 月額8000円で家計に無理のない範囲 万が一の際に、お子様の教育費と生活費をカバー 補足 お子様の年齢や将来の教育方針によっては、 プランBの高額保障も検討の価値があります。 より詳しくお話を伺えれば、精密な提案が可能です。
RAGの効果を実感したポイント
ハルシネーション(幻覚)の抑制
RAGなし(LLMのみ)の場合
- 存在しない保険プランを提案してしまう
- 具体的な金額や条件が不正確
RAGあり(今回の実装)の場合
- OpenSearchから取得した実在のプランのみを提案
- 正確な保険料や保障内容を提示
パーソナライゼーション
DynamoDBのユーザー情報により、同じ質問でもユーザーごとに異なる回答が生成されます。
情報の鮮度
PDFドキュメントを更新してインデックスを再作成すれば、LLMの再学習なしで最新情報を反映できます。
ハマったポイントと対処法
Cross-Region Inferenceの設定
問題: 東京リージョンでClaude 3.5 Sonnet v2を直接利用したい
原因: 一部のBedrockモデルは特定のリージョンでのみ直接利用可能
対処: Inference Profileを使用してAPACリージョンの推論プロファイルを利用
CLAUDE_INFERENCE_PROFILE_ID = "apac.anthropic.claude-3-5-sonnet-20241022-v2:0"
プロンプトの過負荷
問題: 取得したドキュメントが長すぎてトークン制限を超える
原因: チャンクサイズが大きすぎる、または検索結果が多すぎる
対処:
- 検索結果を上位3件に制限(size: 3)
- チャンクサイズを500文字に調整
OpenSearchの検索精度
問題: 関係ないドキュメントが検索される
原因: ベクトルの次元数の不一致、またはインデックス設定の不備
対処:
- ベクトルの次元数を1536に統一
- インデックス作成時にkNN設定を有効化
エラーハンドリングの重要性
問題: OpenSearchのレスポンス構造が想定と異なる場合にクラッシュ
原因: OpenSearchがエラーを返した際の処理が不足
対処: if “hits” not in res_jsonで検証を追加し、適切なエラーメッセージを返す
まとめ
今回は、RAGシステムの核心部分を実装しました。
実装した内容は以下の通りです。
- ライブラリのインポートとクライアント初期化
- ユーザー情報の取得(DynamoDB)
- 質問のベクトル化(Titan Embeddings)
- 類似ドキュメントの検索(OpenSearch)
- プロンプトの構築(RAGの肝)
- LLMでの回答生成(Claude 3.5 Sonnet v2)
rag_handler/main.pyの全5つの関数を実装し、ユーザーの質問から自然な回答を生成する完全なRAGパイプラインが完成しました。
次回は、AWS CDKを使ってこれまで実装したすべてのコンポーネントをコードで管理し、一括デプロイできるようにします。インフラをコードで定義していきましょう!


