
はじめに
当ブログは2025/8/5,6に東京ビッグサイトにて行われたセッションレポートとなります。
タイトル:ZOZOTOWNの大規模マーケティングメール配信を支えるアーキテクチャーについて
登壇:株式会社ZOZO 田島 克哉氏、富永 良子氏
セッション概要
ZOZOTOWNのメール配信のリアーキに関するお話しとして、リアーキ前の課題、課題解決できるためのアーキテクチャ、そのアーキテクチャに関する技術解説について主にお話されておりました。
セッションの内容前半(アーキテクチャ及び処理概要)
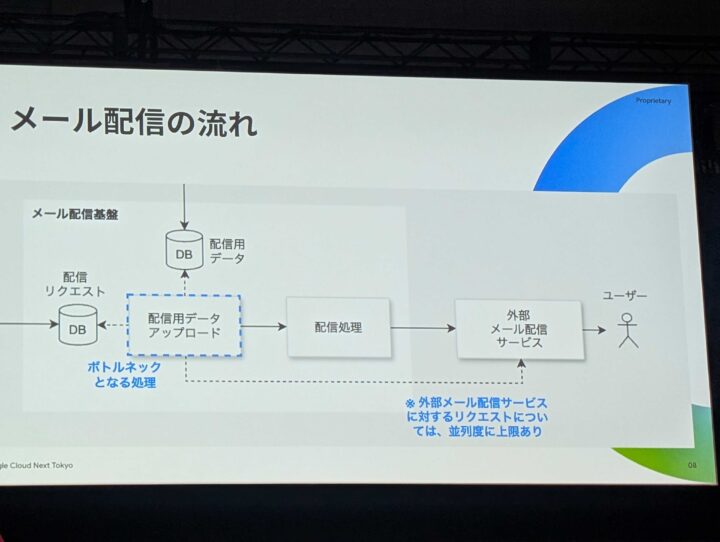
メール配信の目的
ZOZOTOWNの中ではメール配信として以下2種類が行われており、それぞれ満たすための要件として以下があるのことです。
- バッチ配信
- 対象ユーザに一斉送信するようなもの
- 決まった時間でメールが配信され開始時間は決まっているが終了は余裕があるようなメール
- 例:セールのお知らせなど
- 時間最適化配信
- 通知される配信が遅れるとデメリットになるようなもの
- 例:お気に入りの商品が1個になったなど
既存のアーキテクチャ
既存の方法だと、時間最適化配信を追加することで、効率化が必要になることが想定され、実現できない可能性が出てきたとのことです。
並列処理数に上限を設けていたため、これにより、待ちが発生してしまう懸念があったとのことです。

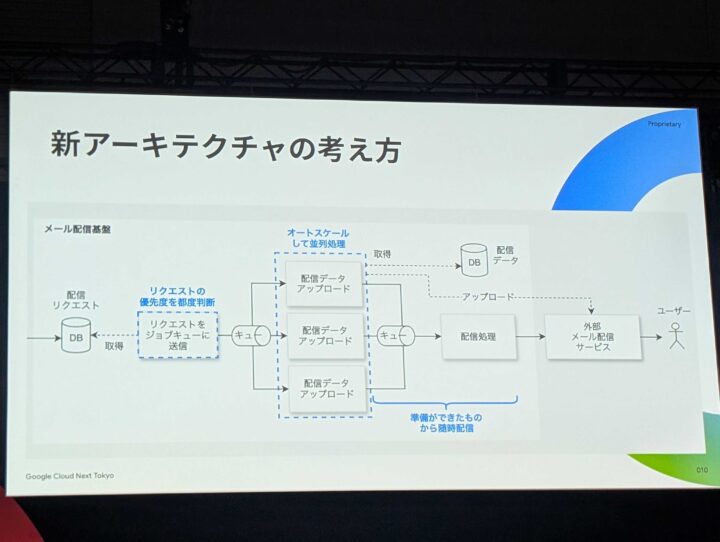
新アーキテクチャの考え方
リクエストの優先度を都度判断し、準備できたものから配信できる仕組みに変更されたとのことでした。
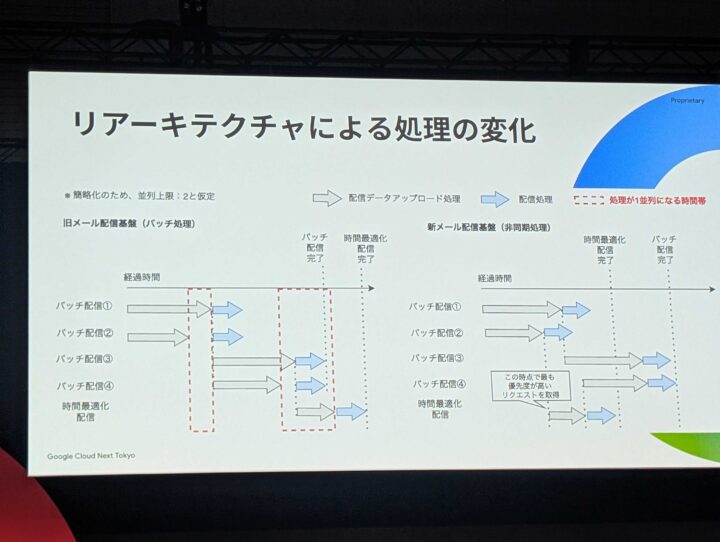
リアーキ前後の変化
- リアーキ前の課題
- 時間最適化配信により、同時に走る時間にばらつきが多くなり、リソースが無駄になりやすくなった
- 並列数が並ぶまでまつので、優先度が高いものがきたときに、まってしまう可能性があった
- リアーキ後
- 配信が非同期になることで、空きがあればすぐ配信できるようになった
- 溜まったものに対処していたものから処理していましたが、優先度が高いものが先に配信できるようになった
セッションの内容前半(技術内容詳細)
新アーキによる変更点
以下の内容を行うことで、重複したメール配信を行わず、優先度付けに従い、Pull することで、優先度に応じた配信が行われているとのこと。
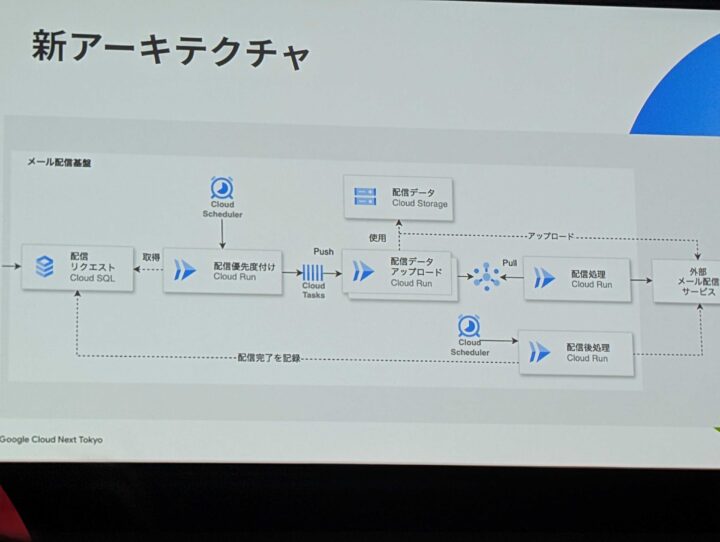
- 新アーキの内容
- 配信優先度付けの Cloud Run が Cloud Tasks に送っている
- 配信用 Cloud Run に渡して Cloud Storage からメール配信にアップロード
- Pub/Sub から、Cloud Run で Pull して、外部メールサービスに配信していないことを確認して、送信 API を実行する
- スケジューラから配信処理結果を確認し、 Cloud SQL へ配信実績を投入する
選定理由

Cloud Run を選定した理由について以下の通り触れられておりました。
- 学習コスト、管理コストの観点でインフラ管理が不要
- ステートレス、リクエストドリブンのサービス、関数実行に最適
今回の選定がほぼ Cloud Run で解決できるところが多く、改めて守備範囲の広さを感じました。
Cloud Run の使い分け

ただ Cloud Run を利用されるだけでなく、各処理内容に応じて適切に使い分けられており、我々としても見習うポイントが詰まっていたと考えています。
Cloud Run 種別
Cloud Run Services、Jobs を活用しそれぞれ要件にあった処理を適用しているとのことで、機能毎の処理やアーキテクトロジックについて細かく解説されておりましたので、そちらも以下に纏めます。
配信優先度付け

Cloud Scheduler からのリクエストを受けて、Cloud Run を動作しており、Cloud SQL へアクセスしている間はレコードをロックしている関係上、Cloud Run への同時リクエストを1にしているなど、要件を満たすために、ただマネージドを使っているだけでなく、細かな調整がされていることがお話からわかりました。また高頻度でここの実行を行うことで、優先度が高いものを処理できるような工夫もされているとお話されておりました。
配信データアップロード

Cloud Tasks からの実行にあたり、0スケールを採用し、アクセスが無い場合、処理が走らないような工夫をされておるとのことで、ここでは費用削減の取り組みも見られました。ここではボトルネックとなっていた処理でもあったことから、流量制限しての並列処理を実行するなど、最大限効率化するための工夫がされていると感じました。
配信処理

Pub/Sub から Pull 型でデータを取り出しており、ここでは、1回配信したものを再配信しないようにしているとのことで、exactly once を利用されており、将来的には Cloud Run Worker Pools を採用していく検討をされているとのことでした。
配信後処理

ここでは Cloud Run Jobs を5分おきに実行することで冪等性を担保し、また失敗時にも再実行することで再処理ができるような仕組みとなっているということで、ここで Cloud Run Jobs を選定されているところが、単純にマネージドサービスを利用するだけでなく、エンジニアリングの中で選定された結果であるように感じました。
セッションのまとめ
要件であった配信優先度を柔軟に決定できるようなロジック、配信速度改善、Kubernetes の学習コストがなくなり、運用の負担を大幅に軽減されたとのことで、リアーキによる効果が多くあったことが挙げられておりました。
また、Cloud Run の学習コストが低いこと、サービスとして瞬時にコンテナの起動、高トラフィックから0スケールにも対応していることなど、Cloud Run によるメリットが多くあったことが挙げられておりました。


まとめ
私も Cloud Run を触れる機会は案件の中で多くあり、アーキテクトなどを検討する機会もあるため、ここまでの検討の苦労や検討ポイントについて、スムーズに理解できました。また、各種サービスの選定ポイントについては、こういった非同期での処理を行うことも機会としてはあると思うので、私も今回の選定ポイントにおける、Cloud Run Service or Jobs の選定、同時接続数、常時 CPUの活用など、参考になる部分が多くありました。また、Cloud Tasks については活用する機会もなかったので、これからの提案に活用できそうなポイントだなと感じ、とても参考になるセッションでした。




