
はじめに
DX開発事業部の北村です。
2025年8月6日にGoogle Cloud Next Tokyo 2025に参加してきました。
『freee が目指す生成 AI 時代に向けた次世代データプラット フォームとガバナンスとは』というセッションを聴講しましたので、内容の一部と学びをまとめます。
セッション概要
タイトル:freee が目指す生成 AI 時代に向けた次世代データプラット フォームとガバナンスとは
登壇者:フリー株式会社 城谷 信一郎 氏、フリー株式会社 西 朋里 氏
公式より
生成 AI 時代においてデータの品質と多様性は不可欠です。しかし多くの企業では、安全性を優先するあまりデータ活用が制限されています。本稿では、この課題に対し、BigQuery と BigQuery Sharing(Analytics Hub)を活用したデータメッシュ アーキテクチャを提案します。さらに、Policy タグによるアクセス制御と Vertex AI を用いた自動リスク評価を導入することで、セキュリティとガバナンスを確保しつつデータ活用を推進する具体的な手法を解説します。
セッション内容
生成AI時代のデータ利活用とガバナンスの方法を詳しく解説いただきました。
生成AIがもたらしたデータ活用の変化と企業戦略
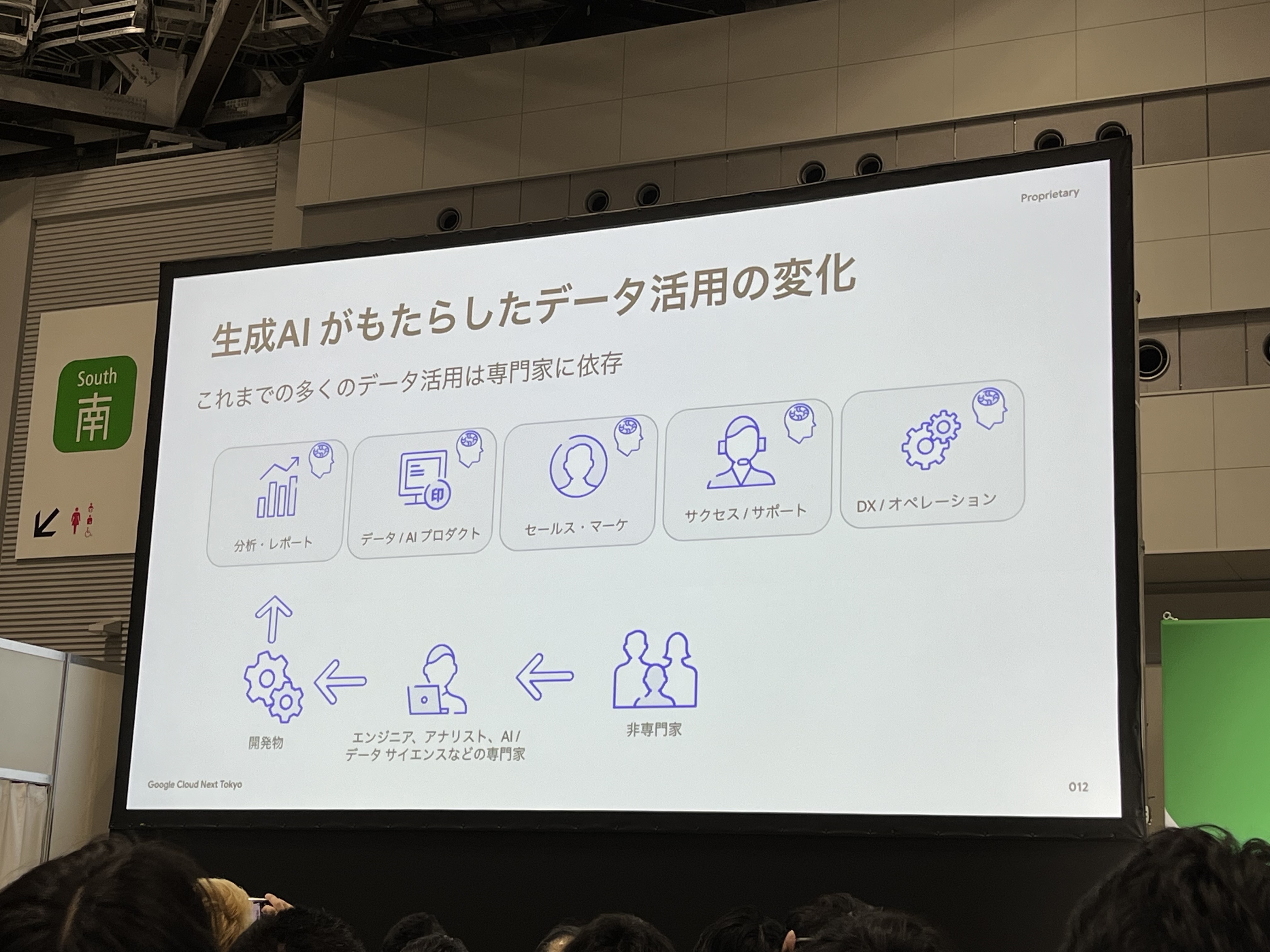
これまでは、多くのデータ活用は専門家に依頼し、開発などを経てデータ活用がされていました。
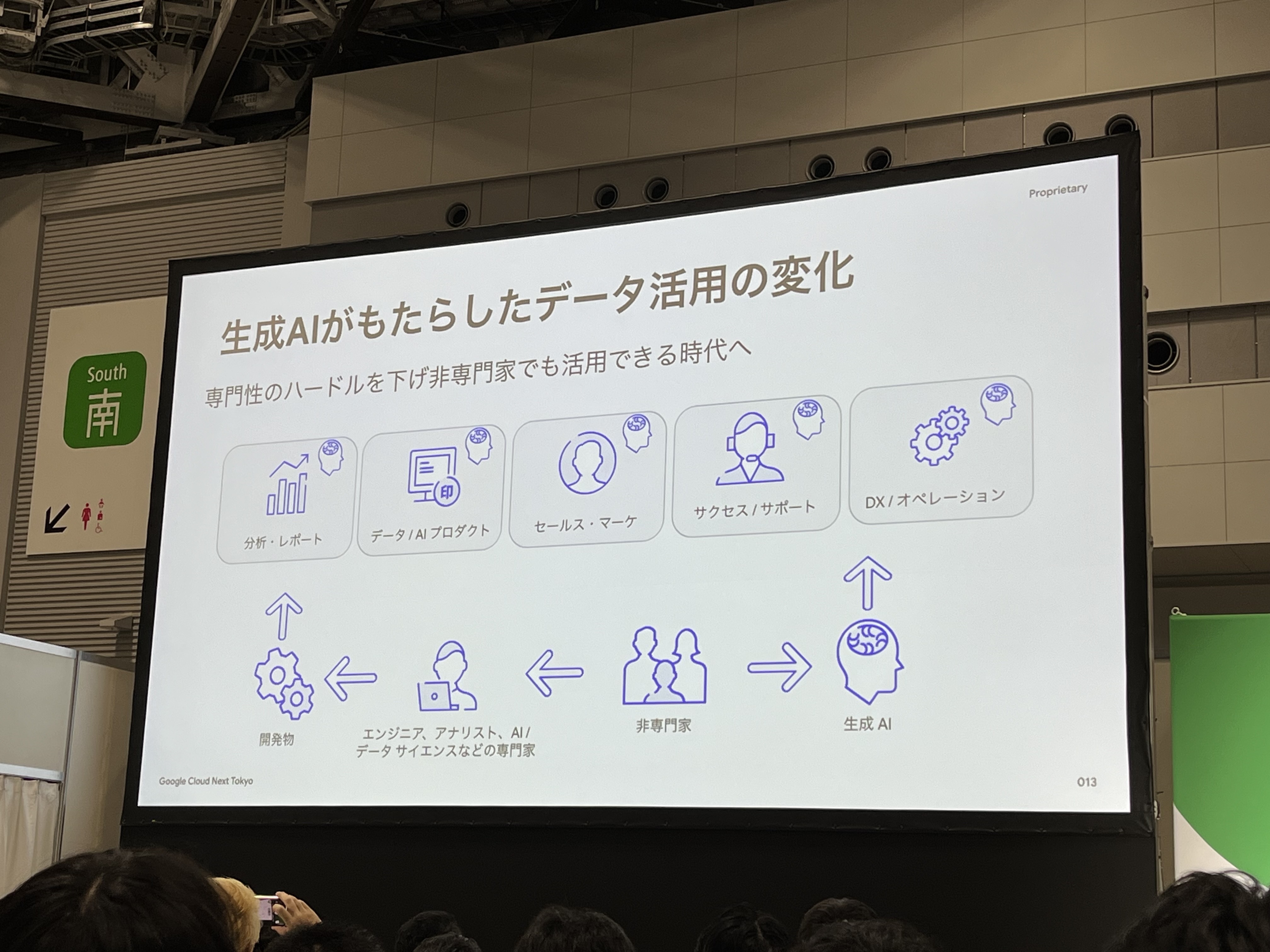
しかし、生成AIの登場で専門性のハードルが下がり、非専門家でもデータ活用できる時代となりました。
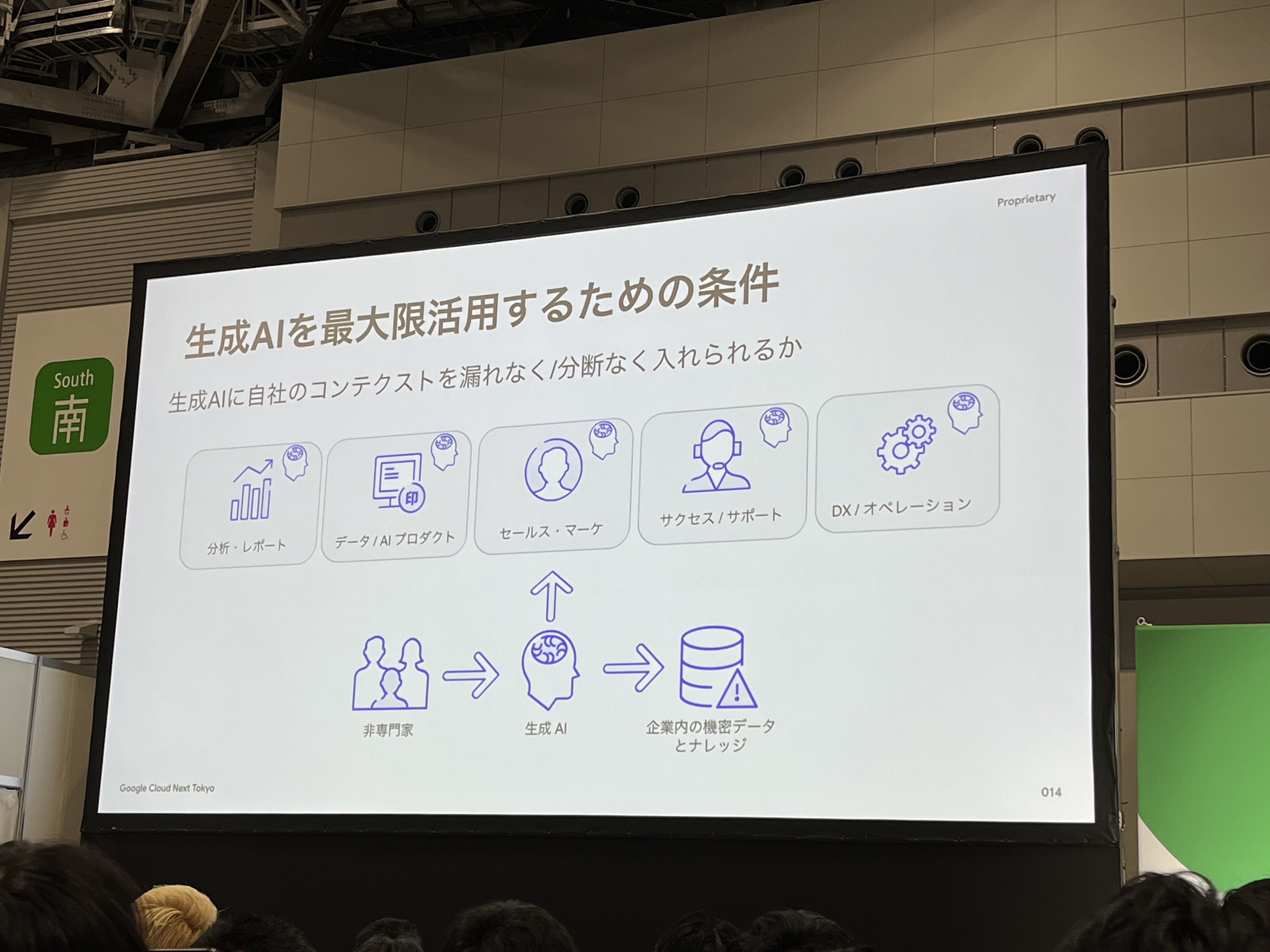
生成AIを最大限活用するためには、「生成AIに自社のコンテクストを漏れなく/分断なく入れられるか」が条件となります。機密データ・ナレッジも漏れなく入れることが重要になります。
そのために、以下のようなデータを取り込んだプラットフォームが必要となってきます。
- プロダクト/サービス(事業・サービスデータ、売上データなど)
- ビジネスデータ(顧客データ、商談データ、マーケティングデータなど)
- 社内データ(財務データ、人事データなど)
- マルチモーダル(画像、動画、音声など)
さらに、合理的なユースケースを限定しないアーキテクチャと開発体制が必要となってきます。
なぜフリーは次世代のデータアーキテクチャに取り組むのか?
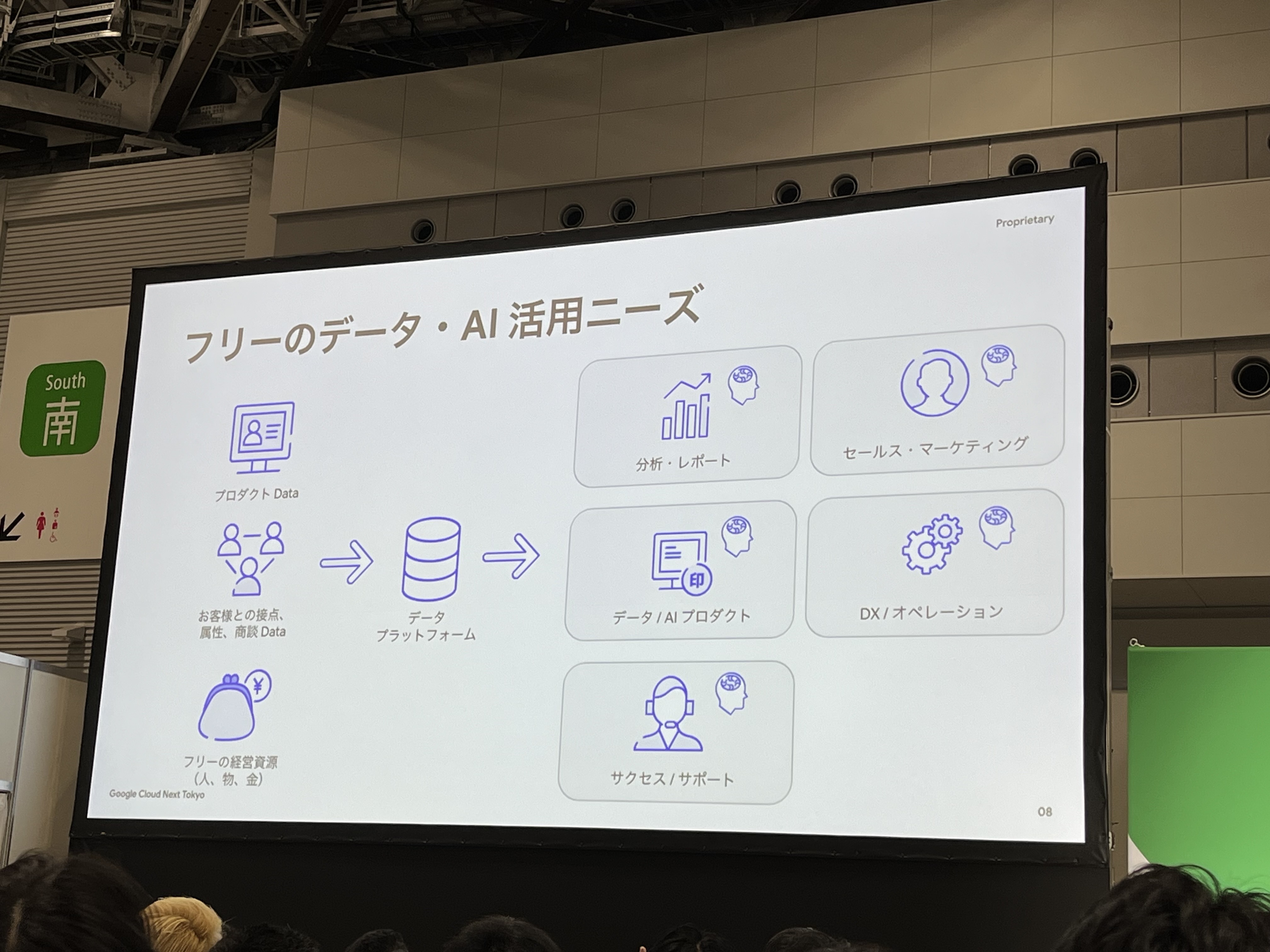

フリー様では、プロダクトのデータや顧客・商談データ、経営資源のデータを分析・レポートやセールス・マーケティングなど様々なユースケースでデータを活用したいというニーズがあります。さらに、既存のデータの規模は膨大です。あまりの規模の大きさに大変驚愕しました笑
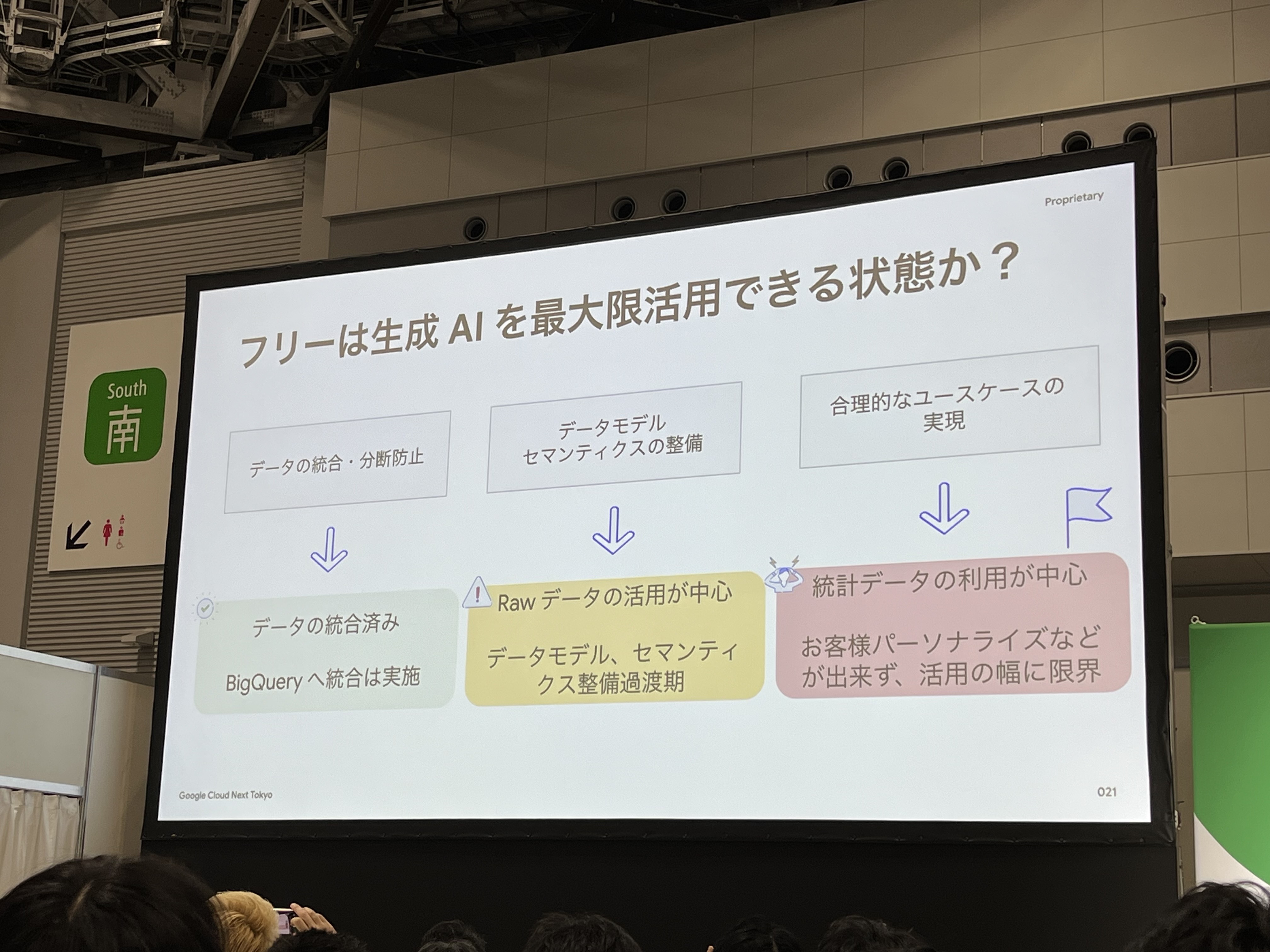
これらの既存のデータを活用して、生成AIを最大限に活用できる状態ではありませんでした。(データの統合・分断防止は完了済み)
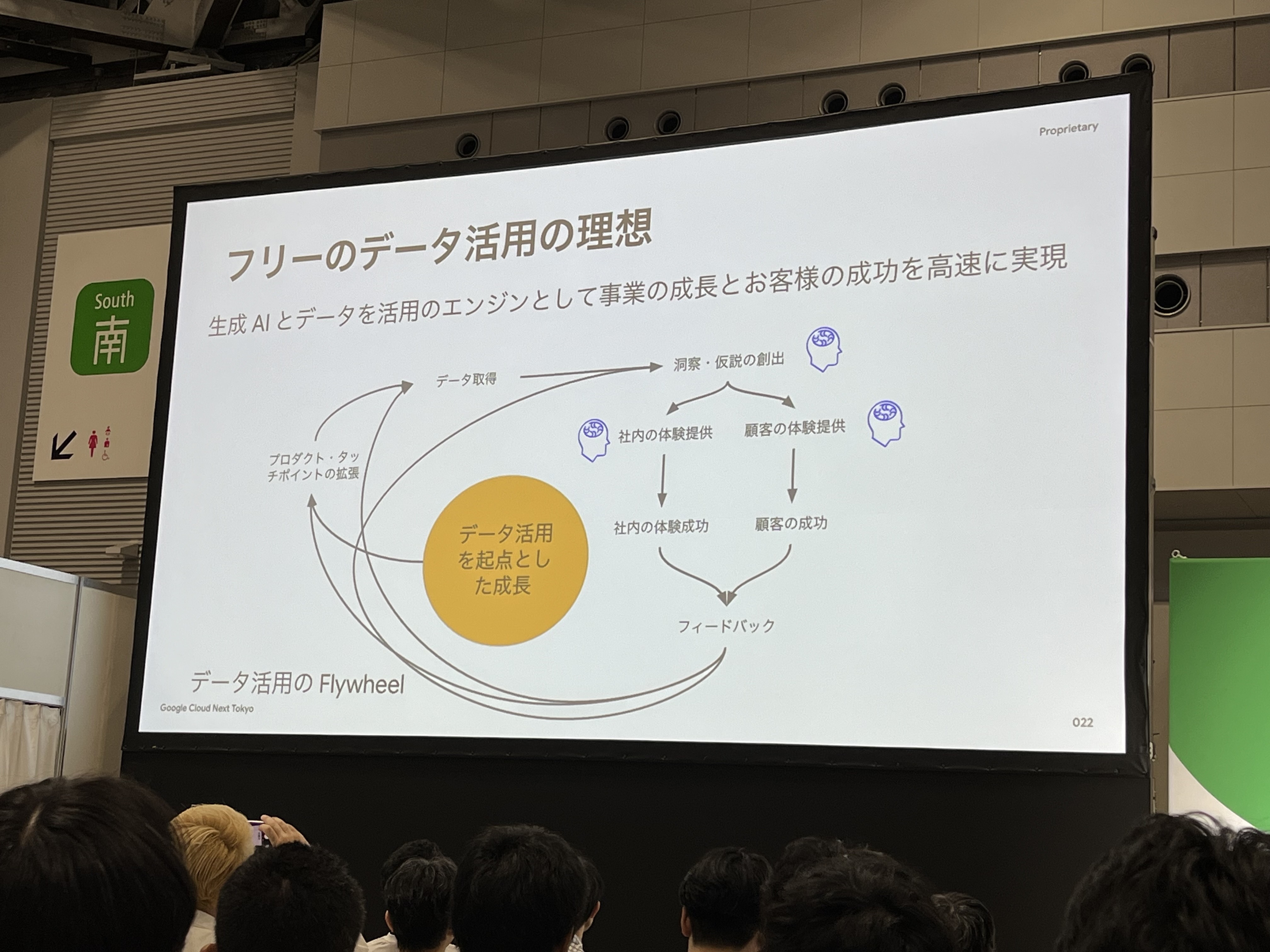
データ活用の理想は上記の通りです。データ活用をエンジンとして事業の成長とお客様の成功を高速に実現していくことが理想です。

しかし、理想状態へ向かうために壁がありました。
統計データの利用が中心でしたが、統計情報ではなく、具体的な機微情報の活用を可能にする必要性があります。そのために、プライバシーポリシー・法律と合理性判断を行う必要があります。さらに、一つの環境を様々な目的・組織が開発するのではなく論理的に自律させるために、利用する人・役割・リテラシーに応じた柔軟な開発環境とアクセスポリシーが必要になります。
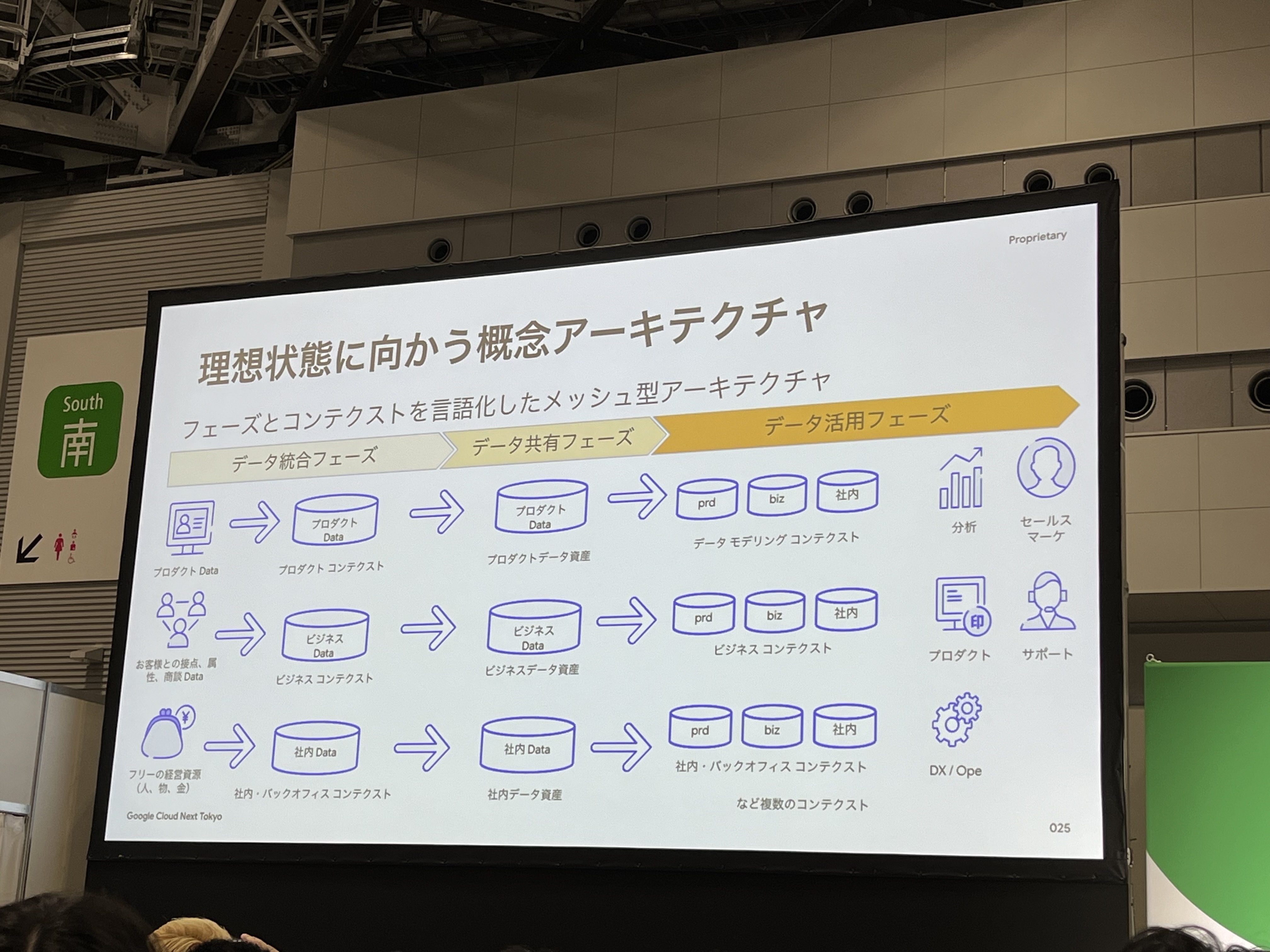
理想状態に向かうために上記のアーキテクチャを採用しています。以下のフェーズに分けてデータを管理しています。
- データ統合フェーズ:コンテキストごとにデータを統合し管理
- データ共有フェーズ:全社にデータを共有
- データ活用フェーズ:データ共有フェーズのデータを参照し、利用目的に合わせてデータを管理
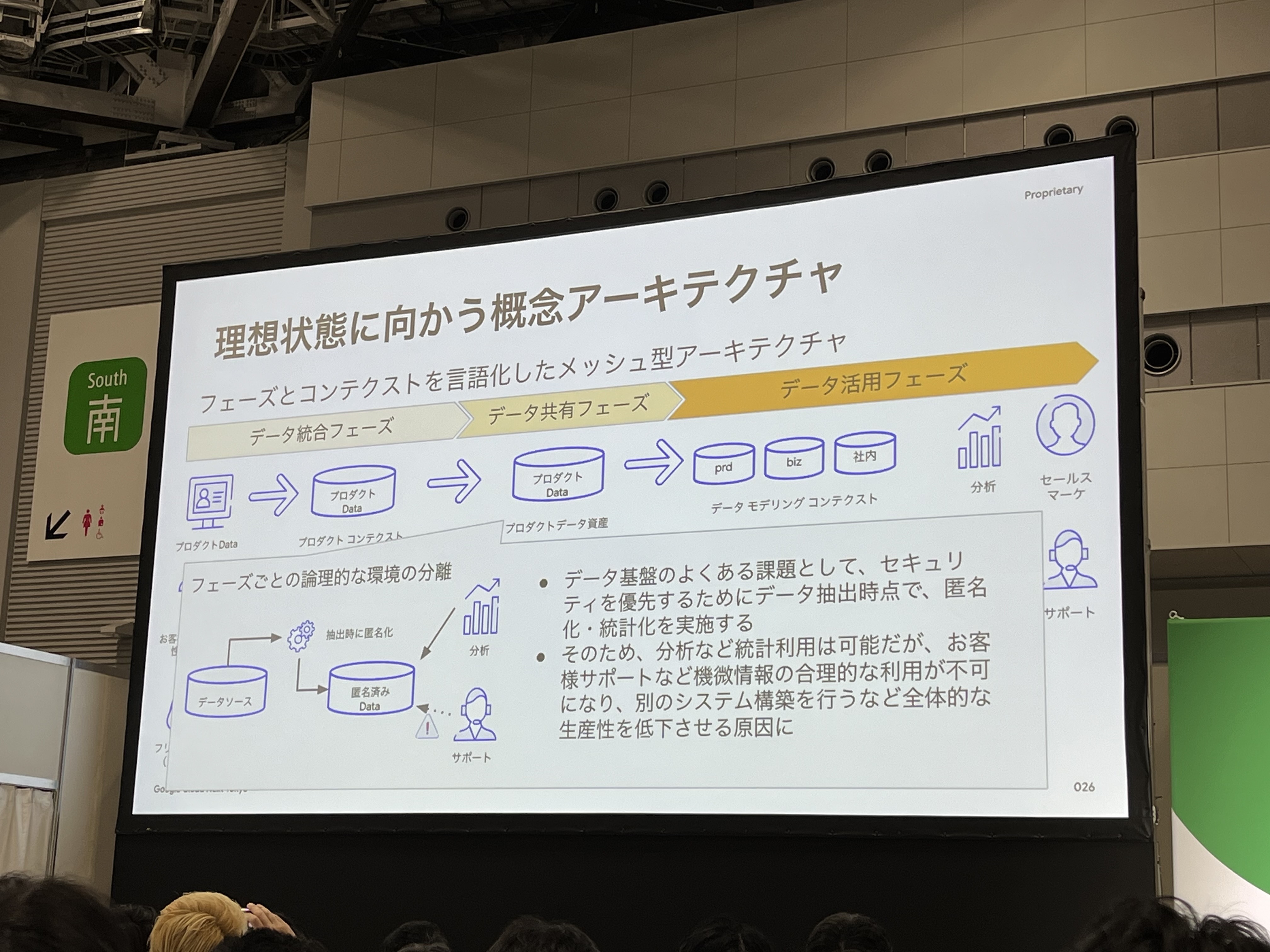
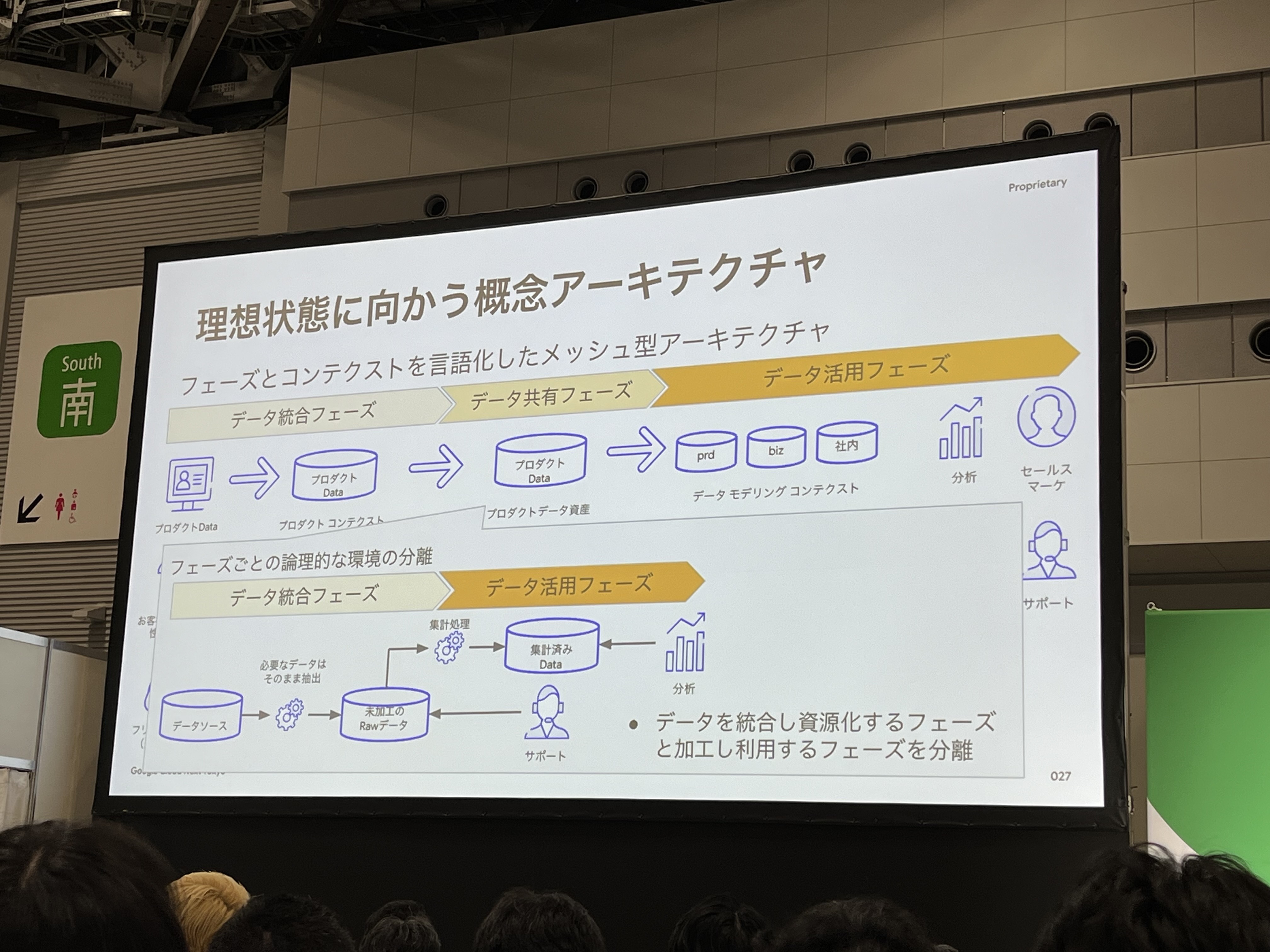
データを統合・共有する際のポイントとして、機密情報などのデータは必要なフェーズで匿名化などの加工を実施しています。データ基盤のよくある課題として、セキュリティを優先するためにデータ抽出時点で、匿名化・統計化を実施することで、分析などの統計利用などは可能だが、お客様サポートなど機微情報の合理的な利用が不可になり、全体的な生産性を下げる原因となります。そのため、このような工夫をしています。

さらに、データ統合フェーズでは、企業毎のコンテクスト(事業部や事業会社の単位など)を発見しデータを統合する開発チームや環境を分離しています。そうすることで、セキュアにデータを分離し開発スピードを向上させることができます。(例として、フリー様では、プロダクト・ビジネス・社内というコンテクストで分離)
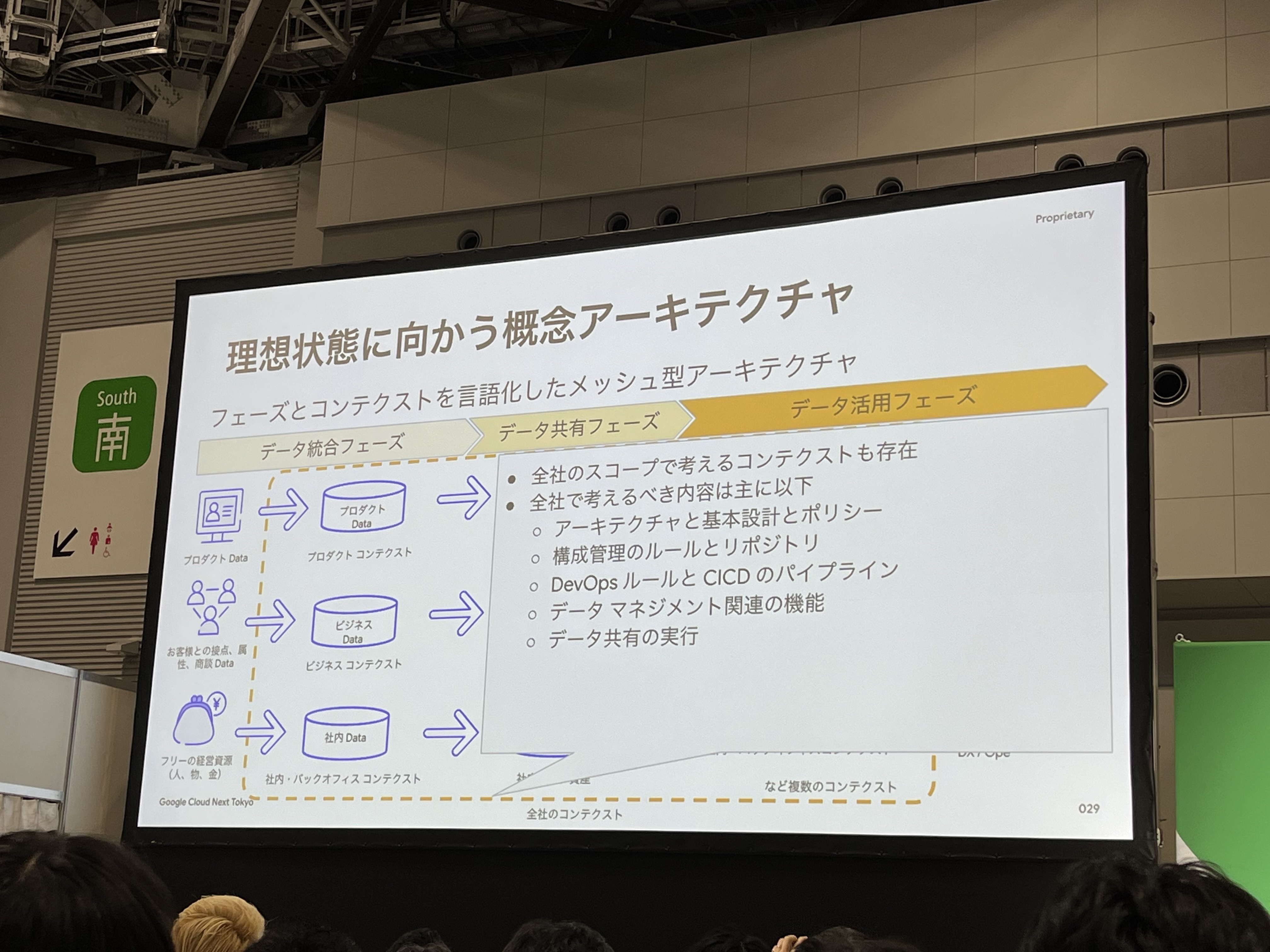
環境が分離することで非効率化する箇所は、以下のコンテクストを全社のスコープで考える必要があります。
- アーキテクチャと基本設計ポリシー
- 構成管理のルールとリポジトリ
- DevOpsルールとCICDパイプライン
- データマネジメント関連の機能
- データ共有の実行
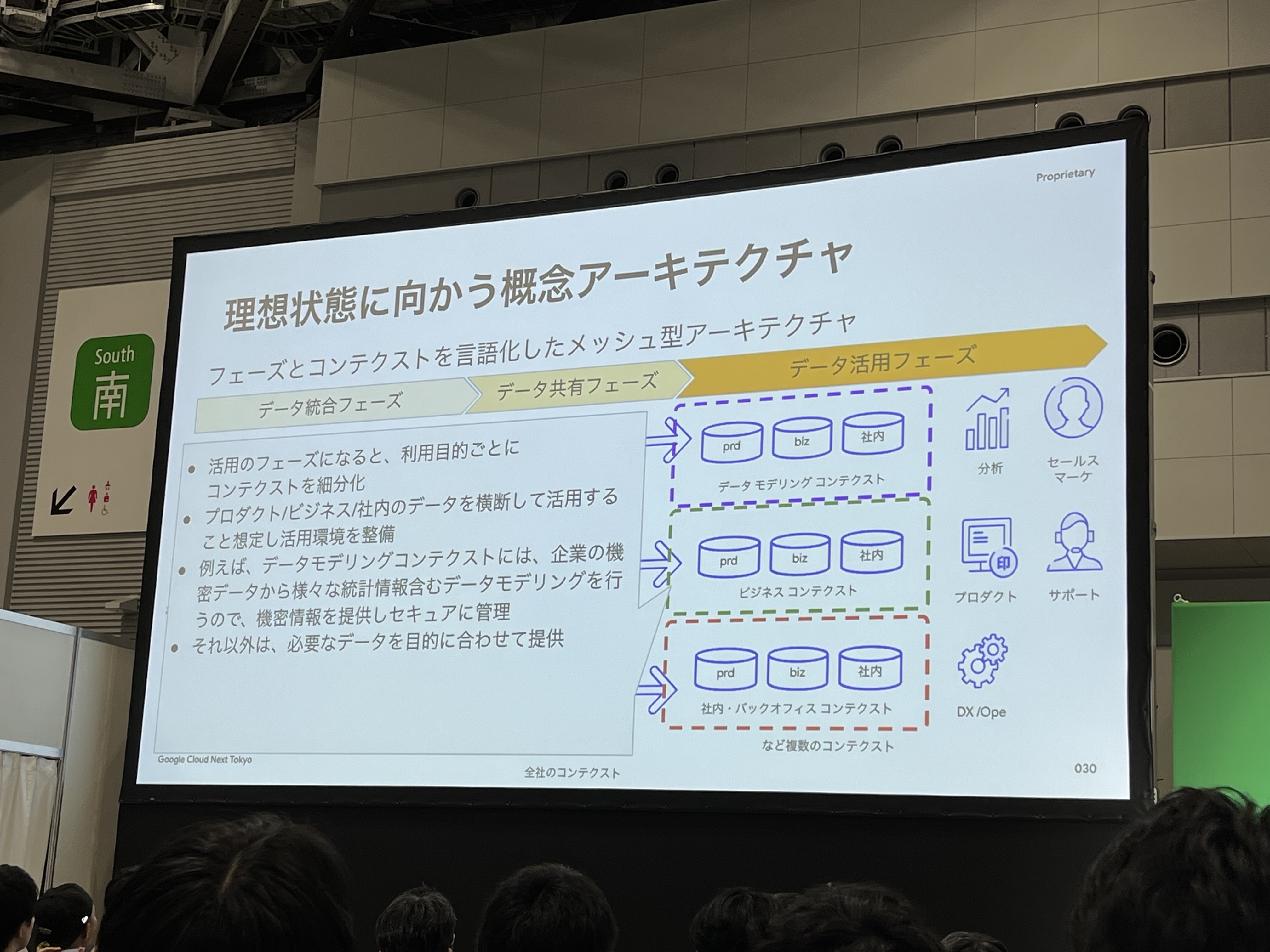
活用のフェーズになると、利用目的ごとにコンテクストを細分化します。データを横断して活用することを想定して活用環境を整備していきます。
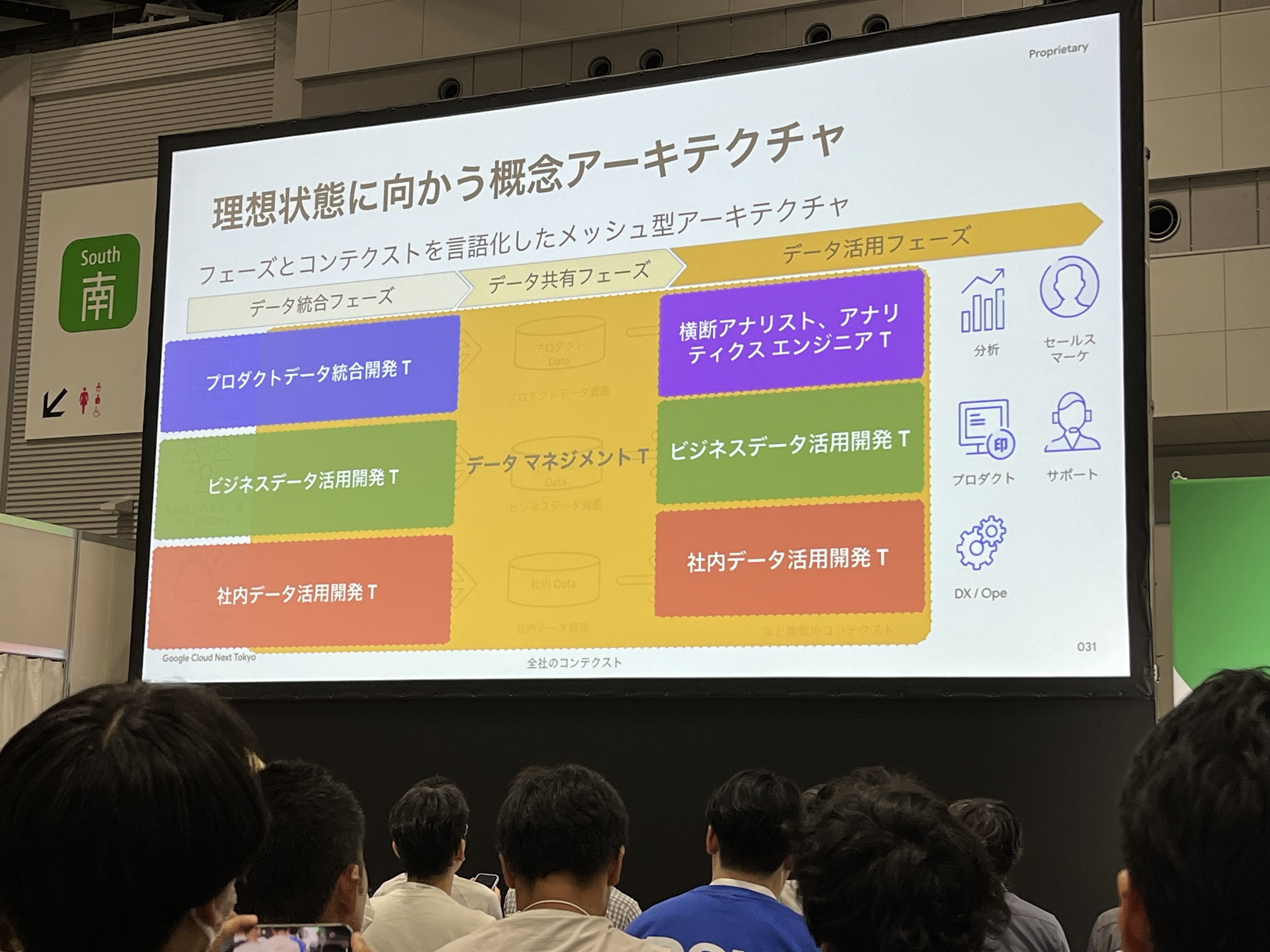
さらに、開発チームもコンテクストに合わせて構成することで、開発スピードを向上させることができます。
データの利便性とガバナンスの両立
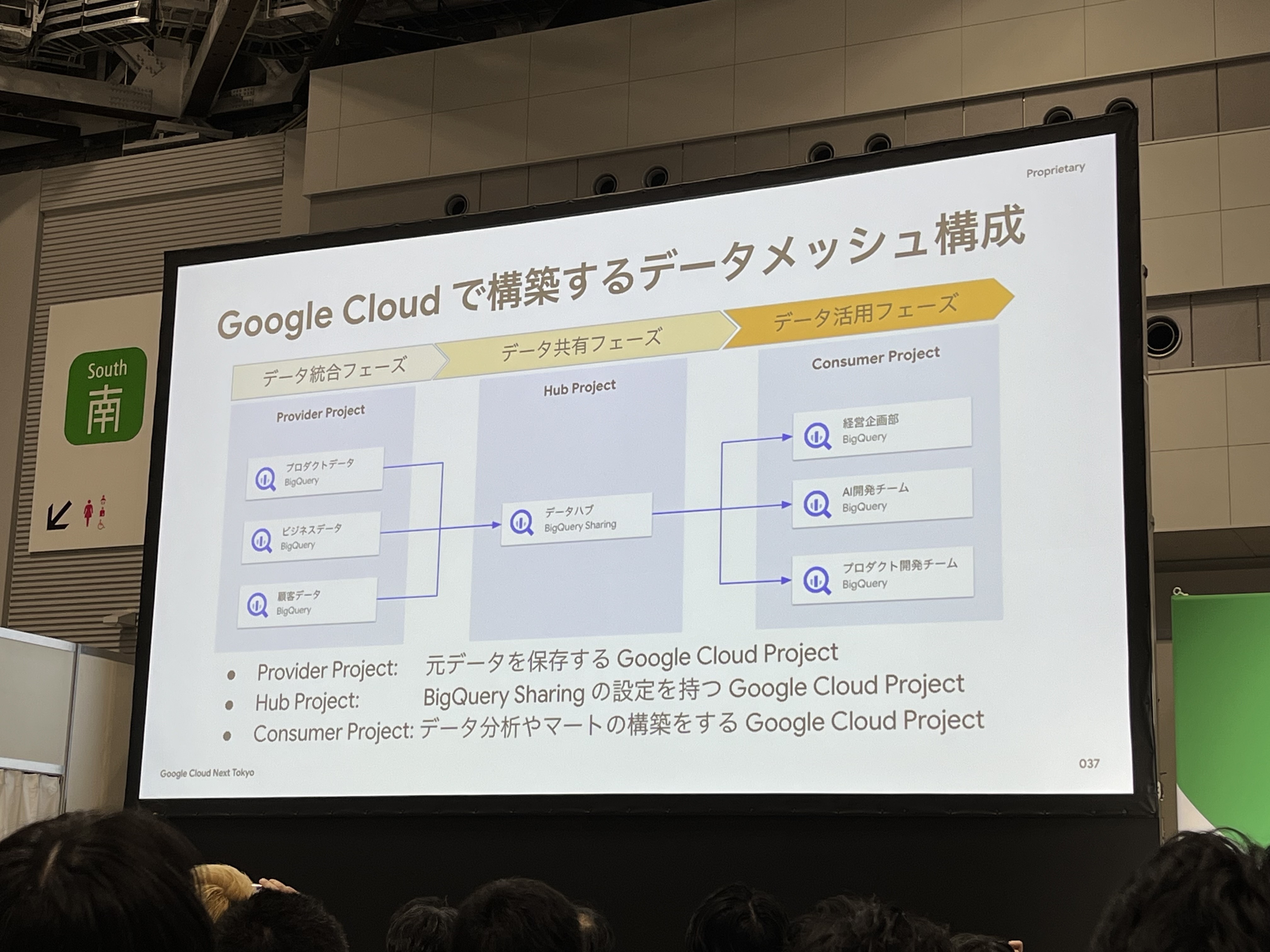
各フェーズをGoogle Cloudで構築すると、上記のようになります。各フェーズごとにGoogle Cloudのプロジェクトを構築し管理します。
データ共有の中核には、「BigQuery Sharing(旧Analytics Hub)」が担っています。
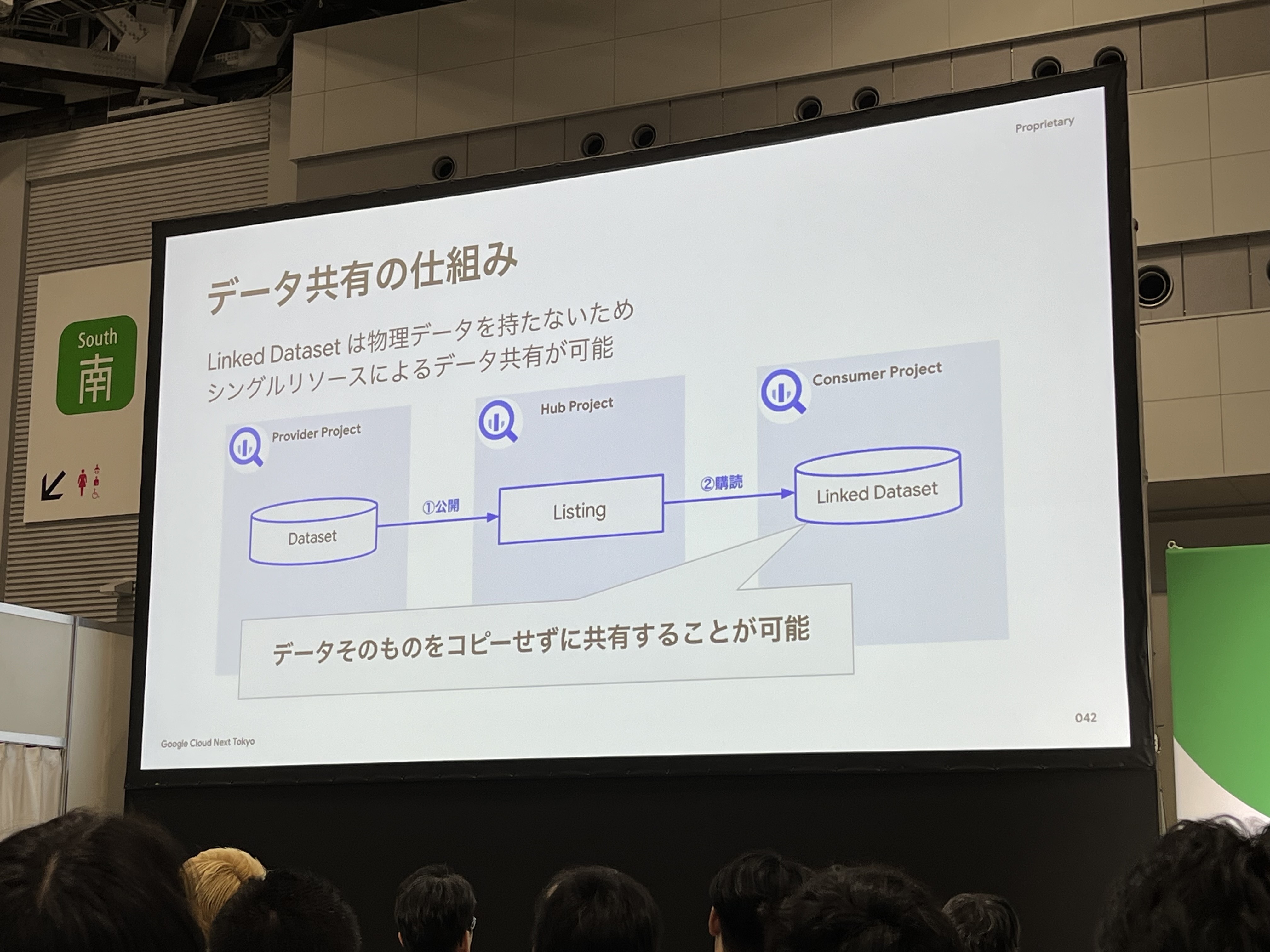
データ共有の仕組みは、Provider Projectで公開し、Hub ProjectのBigQuery Sharingで受け取り、Consumer Projectで購買して共有を行います。
しかし、このままだとデータセットの全てのテーブル・カラムが共有されてしまいます。
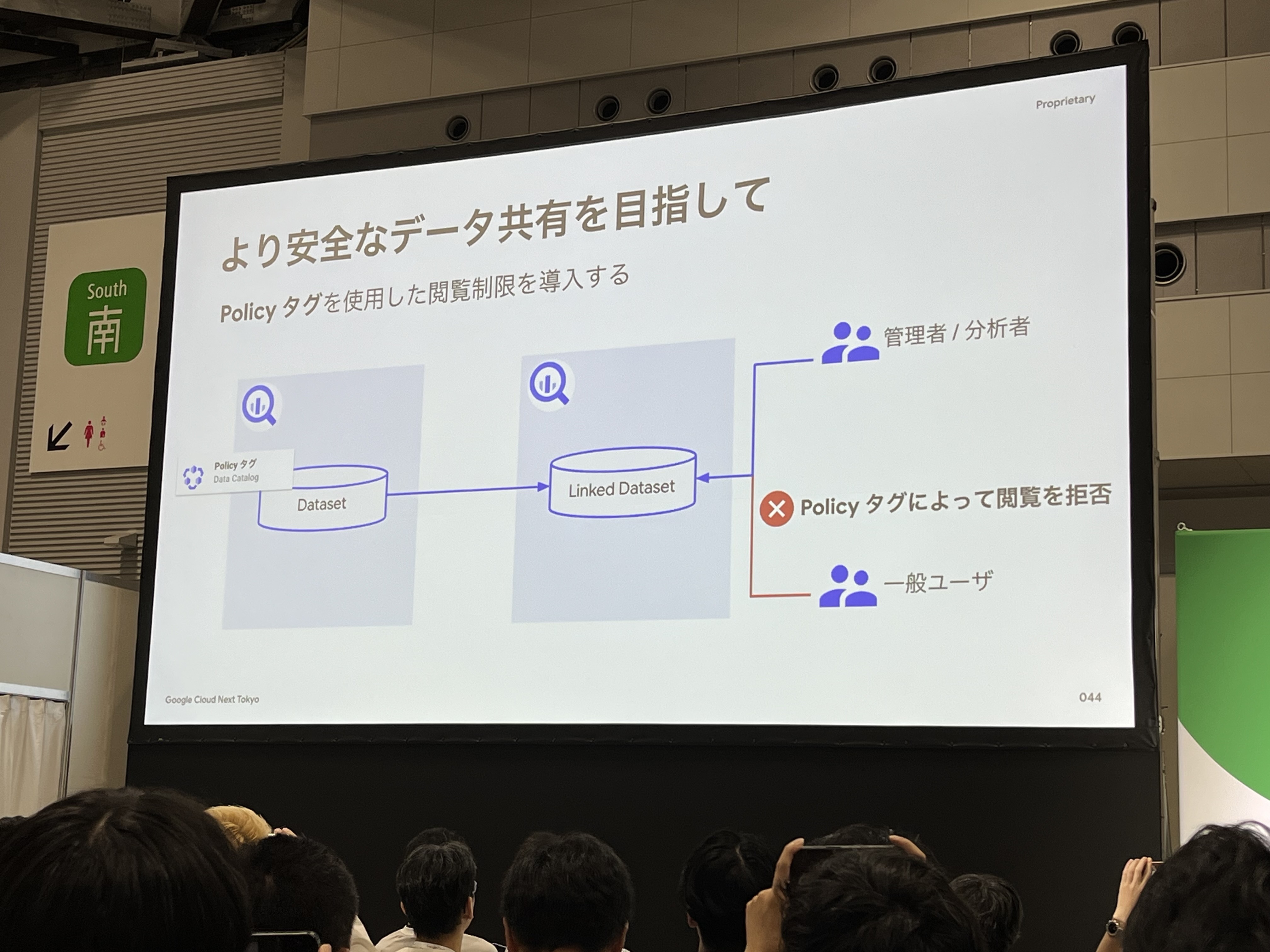
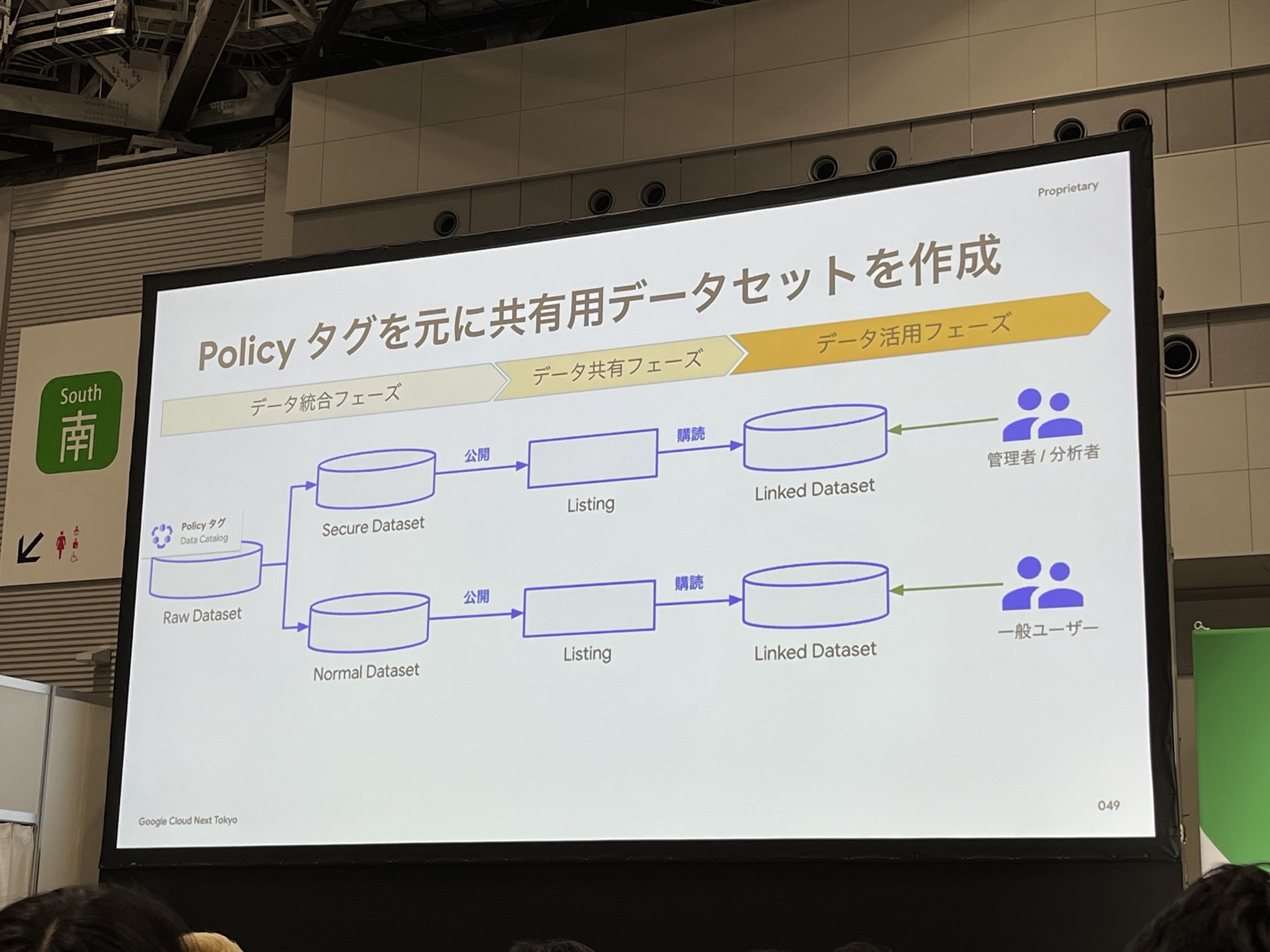
そこで、「Data CatalogのPolicyタグ」を使用して、動的なアクセスコントロールを行い、ガバナンスを高めます。
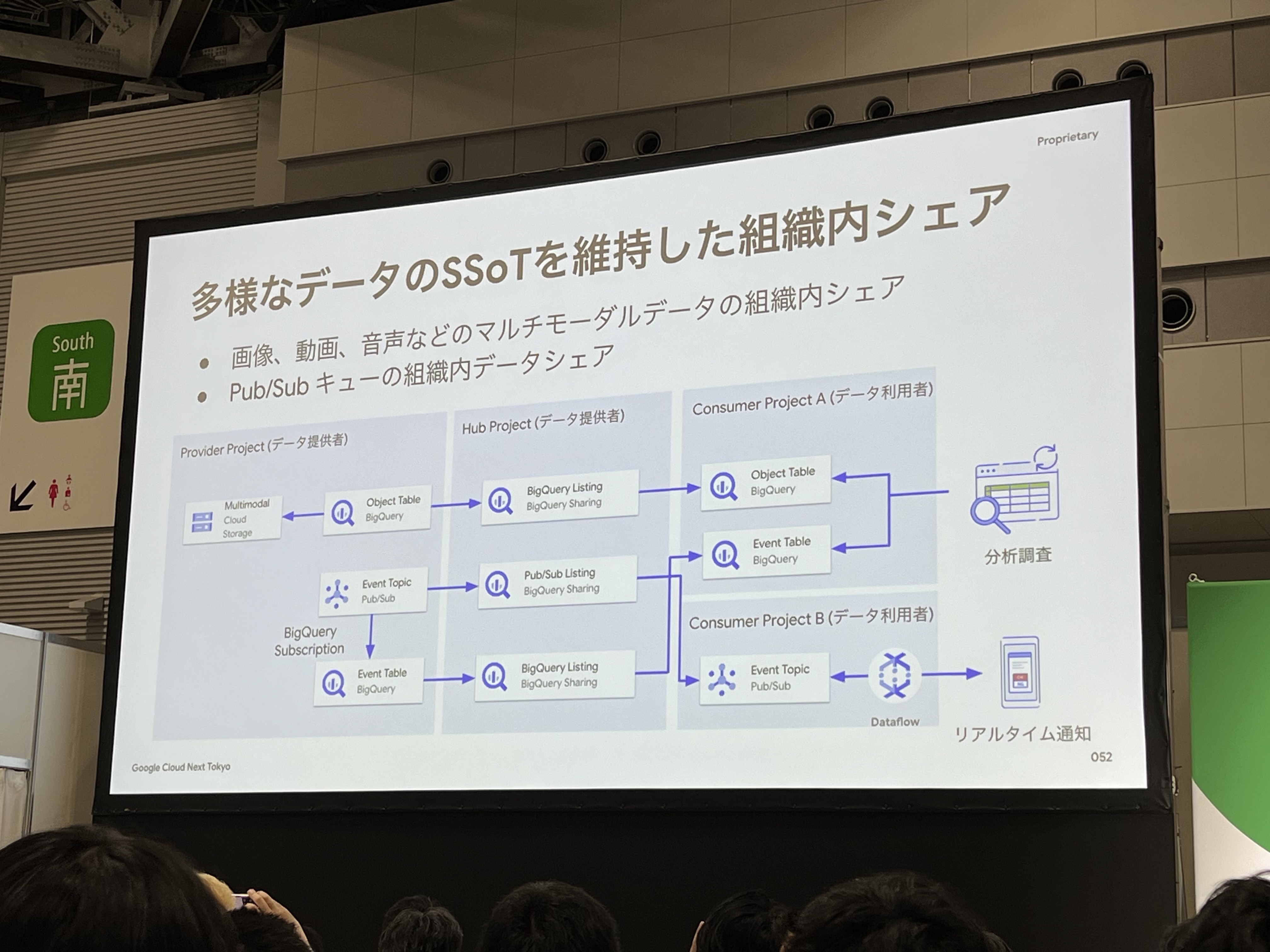
画像、動画、音声などのマルチモーダルデータの組織内シェアは、Pub/Subと組み合わせてシェアを行います。
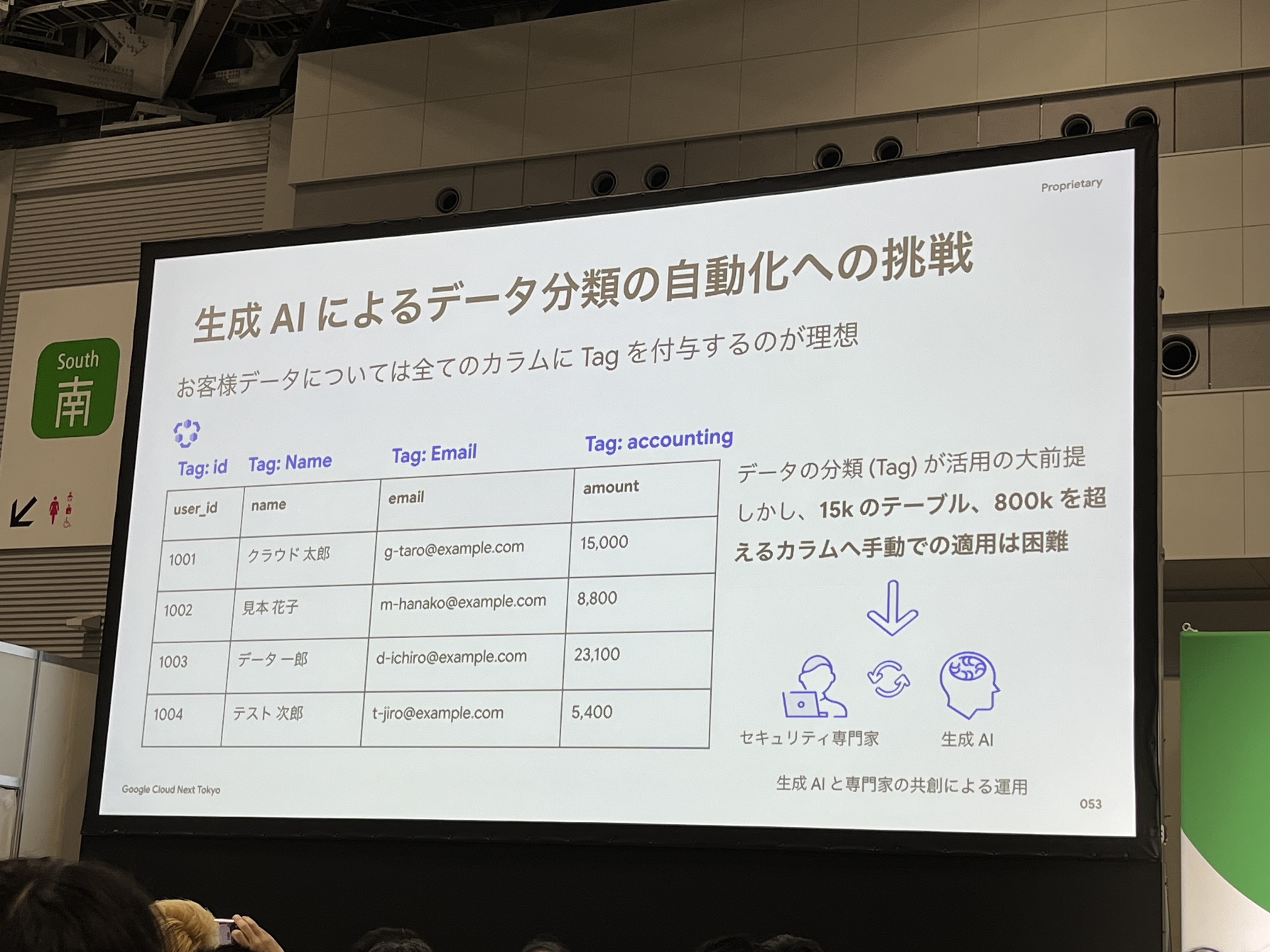
お客様データについては、全てのカラムにPlicyタグを付与しアクセスコントロールをすることが理想ですが、全てを手動で付与するのは困難です。(15kのテーブル、800kを超えるカラム数)そこで、生成AIによるデータ分類の自動化にも取り組んでいます。
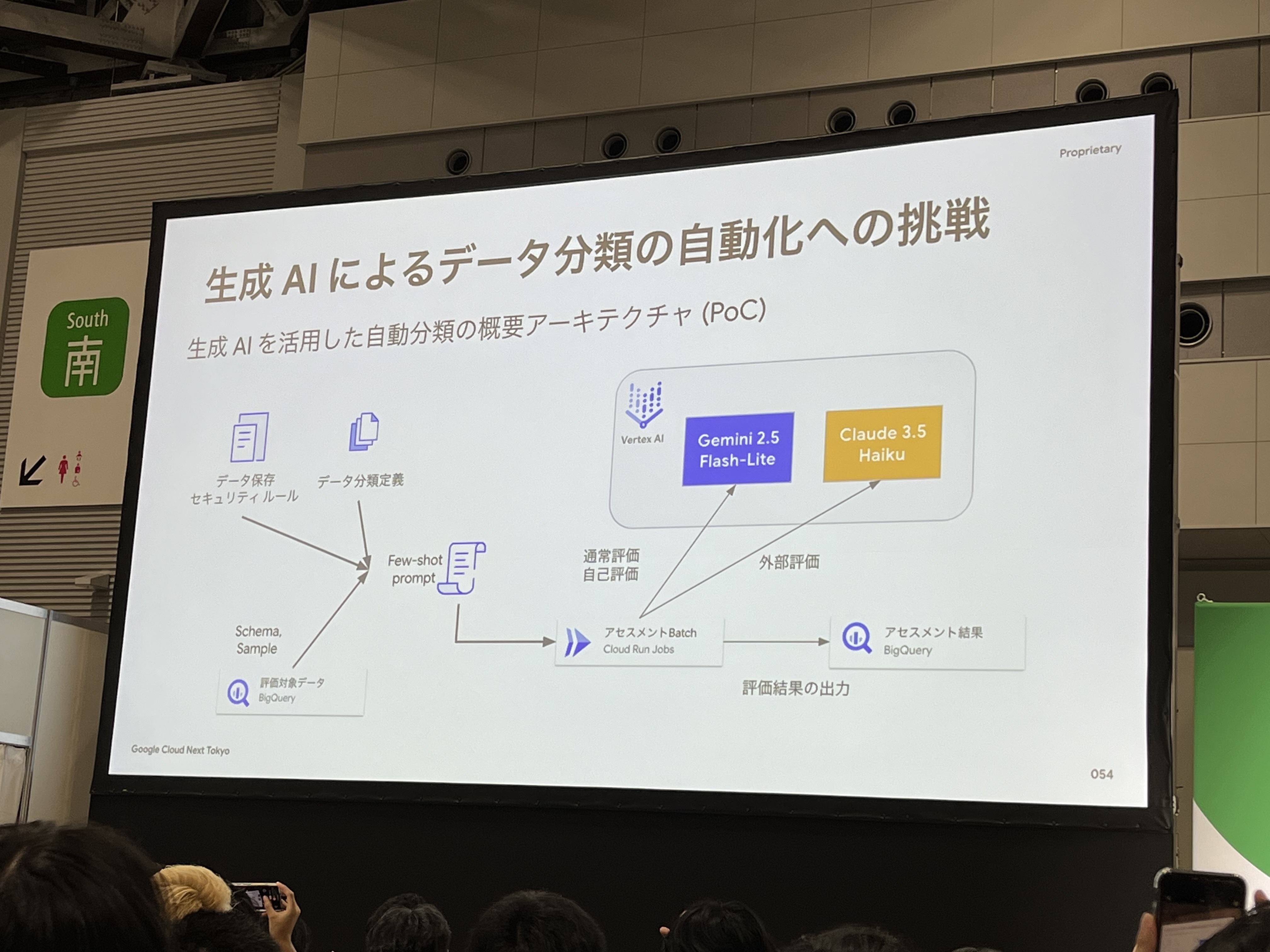

データ保存のセキュリティルール、データ分類定義、評価対象データをもとにいくつかのサンプルを作成する手法の「Few-shot prompt」を使用し、Vertex AIで評価するイメージです。
まとめ
今回のセッションはかなり楽しみにしていました。実際に聴講してみると、かなり濃密で大変勉強になる内容でした。
生成AIを最大限に活用するには、データ・ナレッジの整備がかなり重要だということが改めて実感できました。生成AIの登場以前からデータの整備は重要でしたが、生成AIの登場によって専門家でなくても専門の情報を扱えるようになったからこそ、データの整備などがより重要になり、データを最大限に活用するためには大前提になっていることを強く感じました。
また、データ統合フェーズ、データ共有フェーズ、データ活用フェーズとフェーズを分けることで、特定の目的に合わせてデータを加工する、しないを決めることができ、特定のケースでは活用できるが、その他のケースでは活用できないといった中途半端なデータ活用にならず、セキュリティを担保しながら、あらゆるケースに対応できる柔軟性・拡張性があるデータ基盤ができることを強く実感しました。そのアーキテクチャを実現するためにBigQuery と BigQuery Sharing(Analytics Hub)を使うことが効果的だと勉強になりました。
特に、BigQuery Sharing(Analytics Hub)に関して、データ提供者(Provider)は一元的に共有設定を管理でき、利用者(Consumer)は必要なデータセットをカタログから”購読”するだけで安全に利用を開始できます。この仕組みが、自律的なデータ活用と中央集権的なガバナンスの両立を実現する鍵となっていると実感できました。BigQuery Sharing(Analytics Hub)は、今回以外のケースでも色々な活用方法がありそうですので、より詳細にキャッチアップしていきたいと思いました!




