
前回のあらすじ
【連載第6回】 「クラウド貧乏」を卒業。コストを価値に変えるFinOps文化
前回、私たちはFinOpsという新しい市政運営の思想を学び、「クラウド貧乏」から脱却するための羅針盤を手に入れました。無計画な開発で財政が破綻する都市ではなく、データを元に賢い投資判断を下し、持続的に成長できる「豊かな都市」の礎を築いたのです。
堅牢なインフラ(SRE)と、健全な財政(FinOps)。私たちのクラウド都市の基盤は、かつてないほど強固になりました。しかし、都市の安全を守る警備隊(運用チーム)の詰め所に目を向けると、こんな声が聞こえてきませんか?
「深夜2時、鳴り響くアラート。結局、原因は些細な設定ミスだった…」
「大量の警告メールに埋もれて、本当に危険な兆候を見逃してしまった…」
「またモグラ叩きか…。根本原因を突き止める時間がないまま、次の障害がやってくる…」
これは、24時間365日、市民の安全を守るために奮闘するチームが直面する、痛ましい現実です。どれだけ強固な城壁を築いても、警備員が疲弊しきっていては、真の安全は守れません。
もし、事件や事故の発生を、事前に予測できるとしたら? もし、AIという名の名探偵が、膨大な監視カメラの映像から犯人の「予兆」を捉え、事件を未然に防いでくれるとしたら?
今回お話しするのは、そんな未来を実現するためのAIOpsという、新しい都市監視システムの思想です。
この記事でわかること
- なぜ従来の監視運用では、エンジニアが「アラート疲れ」に陥ってしまうのか、その構造的な限界。
- AIOps(AI for IT Operations)が、運用の常識をどう覆すのか。単なる「自動化」ではない、その本質。
- Amazon DevOps GuruのようなAIサービスが、障害の「予兆」を捉え、原因究明をどう支援してくれるのか、具体的な仕組み。
- ITILの問題管理プロセスがAIOpsと融合し、インシデントを「未然に防ぐ」プロアクティブな運用(To-Beモデル)へと進化する未来像。
なぜ、私たちの警備隊は疲弊するのか? – 人海戦術による監視の限界

私たちのクラウド都市が発展するにつれ、監視すべき対象は爆発的に増加します。無数のビル(サーバー)、複雑に行き交う交通網(ネットワーク)、そして絶えず変化する市民の活動(アプリケーションのログ)。これらすべてを、人間の目だけで24時間監視し続けることには、構造的な限界があります。
従来の監視システムは、いわば「煙が出たら鳴る火災報知器」です。しかし、現代のクラウド都市では、その報知器が何千、何万と設置され、ちょっとした料理の湯気でもけたたましく鳴り響く。
- ノイズの洪水
- 大量の無害なアラートの中に、本当に危険なシグナルが埋もれてしまう。
- 因果関係の分断
- CPU使用率の上昇、レイテンシの増加、エラーログの発生。これらは個別の事象として通知され、それらが「数日前のアプリケーションのデプロイ」という一つの根本原因に繋がっていることを見抜くのは、百戦錬磨のベテランが持つ「経験と勘」に頼らざるを得ません。
- 事後対応の連鎖
- 火事が起きてから出動するため、常に対応は後手に回ります。消火活動(インシデント対応)に追われ、火災原因の調査(問題管理)や、そもそも火事を起こさないための消防法改正(恒久対策)にまで手が回らないのです。
この「人海戦術」と「経験と勘」に依存した属人的な運用こそが、エンジニアを疲弊させ、イノベーションから遠ざける元凶なのです。
AIOpsという「未来の防災センター」の登場

この負のスパイラルに終止符を打つのが、AIOps (AI for IT Operations) という思想です。
AIOpsを難しく考える必要はありません。これは、都市のあらゆる場所から集まる膨大なデータ(メトリクス、ログ、トレース情報)を、AIが24時間365日分析し、人間の認知能力を超えたレベルで「異常の予兆」を検知し、「根本原因の有力な手がかり」を示唆してくれる、いわばAIを搭載した未来の防災センターです。
火災報知器が鳴ってから動くのではなく、壁の中の配線が異常な熱を帯び始めた「予兆」の段階で警告を発し、「原因はこの漏電の可能性が高い」と報告してくれる。これがAIOpsがもたらす変革の本質です。
AWSという都市の名探偵:Amazon DevOps Guru
このAIOpsの思想を、AWS上で具現化してくれる強力なサービスが Amazon DevOps Guru です。彼は、私たちのクラウド都市に常駐する、極めて優秀な「AI探偵」です。
出典:Amazon DevOps Guru (機械学習を利用したアプリケーションの可用性向上)
DevOps Guruの仕事は、主に3つあります。
異常の予兆を検知する(Detect)
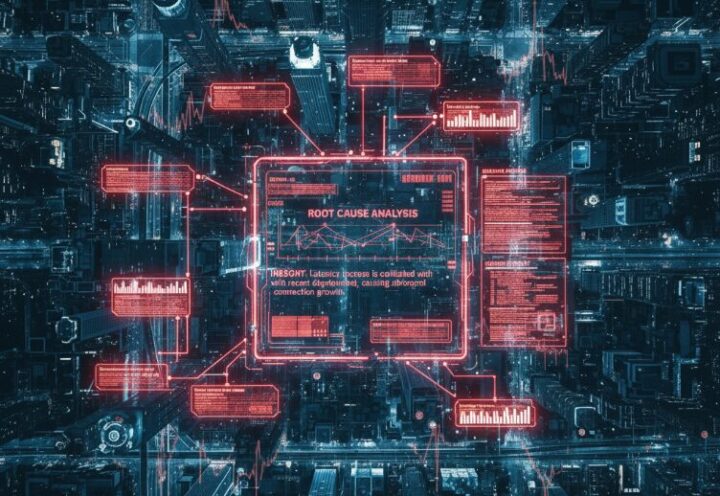
DevOps Guruは、Amazon CloudWatchのメトリクスやAWS CloudTrailのログ、AWS Configの変更履歴といった膨大な情報を常に学習し、アプリケーションの「正常な状態」を機械学習モデルとして理解しています。そして、「いつもと違う、些細な振る舞いの変化」を捉えます。例えば、「新しいコードがデプロイされた後、特定のエラーログがわずかに増加し始めた」といった、人間が見過ごしがちな異常の予兆を検知します。
原因を分析し、洞察を提示する(Insight)
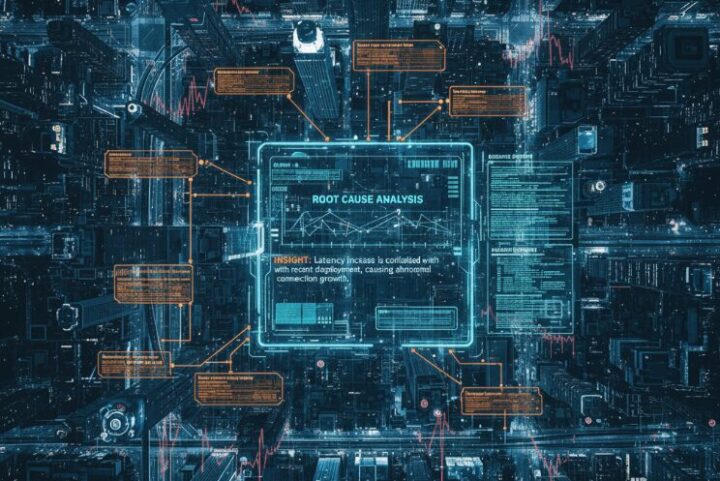
ここからがDevOps Guruの真骨頂です。DevOps Guruは、バラバラに見える複数の事象を関連付け、一つのストーリーとして再構成します。 「このレイテンシの悪化は、30分前にあったあのデプロイが原因で、データベースへのコネクション数が異常に増加していることと関連している可能性が高い」 このように、根本原因に関する「洞察(インサイト)」を、豊富な証拠データと共にレポートしてくれるのです。これはもはや単なるアラートではなく、詳細な「捜査報告書」と言えるでしょう。
解決策を推奨する(Recommend)

さらに、彼は経験豊富なコンサルタントのように、AWSのベストプラクティスや過去の障害事例に基づいた、具体的な「解決策」を推奨してくれます。「関連するドキュメントはこちらです」「この設定値を見直すことを推奨します」といった具合に、私たちが次に取るべきアクションの方向性を示してくれるのです。
ITILとの融合:次世代MSPが描く「予知保全」という未来
さて、この強力なAI探偵の能力を、私たちの都市運営(ITサービスマネジメント)にどう組み込むか。ここで再び、私たちの思考OSであるITIL 4が登場します。
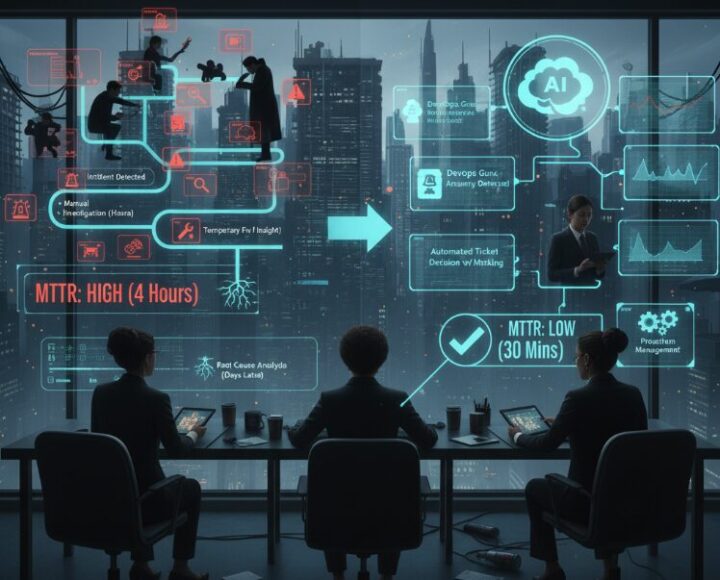
従来の運用プロセス(As-Is)は、こうでした。
- インシデント発生
- 人間がアラートに気づく
- 担当者が必死に調査(数時間)
- 暫定的な復旧
- (数日後)根本原因を特定し、問題管理プロセスへ
これでは、平均修復時間(MTTR: Mean Time To Repair)は短縮できず、同じ過ちを繰り返すことになります。
これに対し、DevOps Guruを組み込んだ次世代MSPの運用プロセス(To-Be)は、インシデント対応の「始まり方」を根底から覆します。
深夜に鳴り響くアラートに叩き起こされ、無限に広がるログの海でたった一つの原因を探し続ける…。そんな孤独な戦いのような初動は、もう過去のものです。次世代のプロセスでは、エンジニアの一日はこのように変わります。
- AIによる「予兆」の自律検知
- 人間がサービス影響に気づく前に、DevOps Guruがシステムの異常な振る舞いを捉えます。
- 分析レポート付きの課題が自動起票される
- ITSMツールには、単なるアラートではなく、関連する事象や推奨アクションがまとめられた「分析レポート」へのリンクが付与された課題が自動で起票されます。
- 仕事の起点が「調査」から「議論」へ
- 担当者の仕事は、ゼロからの原因調査ではなく、AIが提示したインサイト(洞察)が妥当かを評価し、チームで解決策を議論・意思決定することからスタートします。
- MTTR(平均修復時間)の抜本的な改善
- 洞察を得たことでこれまで時間を要していた原因特定フェーズを大幅に圧縮することで、MTTRの劇的な短縮を目指します。
- 「学び」を次に繋げる文化の醸成
- なぜ予兆が生まれたのか、という深い洞察が得られるため、場当たり的な対応(モグラ叩き)に終わらず、恒久対策を講じるプロアクティブな問題管理へとスムーズに移行し、組織のナレッジ蓄積を目指します。
これは、単なるインシデント対応の高速化ではありません。エンジニアの役割を、孤独な「火消し役」から、チームで未来をより良く設計する「戦略的な建築家」へとシフトさせる、働き方のパラダイムシフトの可能性を秘めています
次世代MSPは、この未来像を実現するための「仕組み」を構築します。例えば、Amazon EventBridgeでDevOps Guruが生成したインサイトを検知し、それをトリガーとしてAWS Lambda関数を実行。LambdaがITSMツールなどのAPIを呼び出し、原因分析レポートへのリンクを含んだチケットを適切な担当チームへ自動で起票します。こうした自動化されたワークフローを整備することで、個人の英雄的な活躍に頼ることなく、組織全体として、例えば「インシデント発生率を半減させる」「主要な運用タスクの対応工数を月間80時間削減する」といった、野心的でありながらも測定可能なビジネス価値を生み出すことを目指します。
※これらは、業界の先進的な事例や私たちがお客様と描く未来像を基にした目標値(To-Beモデル)であり、何らかの効果をお約束するものではありません。しかし、このような具体的な目標を共有し、そこへ向かう道筋を共に設計することこそが、変革への最も重要な第一歩になると私たちは確信しています。
私たちの役割は、もはやアラートの監視員ではありません。AIOpsという強力なエンジンから生み出されるデータを分析し、お客様のビジネスを止めないために次の一手を提案する「データサイエンティスト」であり「戦略アドバイザー」なのです。
まとめ:「アラートに追われる日々」から「価値を創造する未来」へ

AIOpsは、私たちを深夜のアラート対応という苦役から解放する魔法の杖ではありません。それは、人間の経験や直感を、データとAIによって拡張し、エンジニアが本来向き合うべき、より創造的で価値のある仕事に集中するための、強力なパートナーです。
最後に、少しだけ想像してみてください。
もしあなたの組織が、AIOpsという新しい力でインシデント対応の時間を劇的に削減できるとしたら、その解放された時間は、どんな新しい価値を生み出すために使われるでしょうか?
それは、新しいサービスの企画かもしれません。革新的な顧客体験の創出かもしれません。あるいは、チームメンバーのスキル向上や、より深い技術探求の時間になるかもしれません。
私たちの役割は、もはや「モグラ叩き」の対応に追われることではありません。お客様のビジネス価値を最大化するために、データを読み解き、次の一手を提案する戦略的なアドバイザーへと進化することなのです。
次回予告
強固な基盤(SRE)、賢明な財政(FinOps)、そして未来を予測する防災センター(AIOps)。私たちのクラウド都市は、強固で賢く、そしてプロアクティブなインフラを手に入れました。
しかし、それでもシステムは完璧ではありません。人間が気付かないようなわずかな異変や、予測不可能な事象は、時に障害へと発展します。もし、そんな時でも、警備隊が駆けつける前に、システム自身が問題を検知し、自ら修復を開始できるとしたら?
次回は、ITILの「インシデント管理」とSREの「自動化」を融合させ、システムが自律的に問題を解決する「自己修復アーキテクチャ」という概念に迫ります。Amazon CloudWatchやEventBridge、Systems Manager AutomationといったAWSのサービスを組み合わせ、インシデントを未然に防ぎ、エンジニアをさらにクリエイティブな仕事に集中させるための具体的な設計図をお見せします。
【第8回】システムが自分で治す。AWSで実現する「自己修復アーキテクチャ」の作り方
過去の連載はこちら
これまでのバックナンバーを見逃した方は、こちらからご覧いただけます。
- 【連載第1回】AWSという都市は、なぜ“カオス”と化すのか?
- 【連載第2回】ITILはクラウド運用の「標準OS」。AWS公式が示す、その深い関係性
- 【連載第3回】あなたのMSPは「サポーター」? それとも「戦略的パートナー」? 未来を共創する関係性の見極め方
- 【連載第4回】ITILの心臓部「SVS」をAWSで動かす設計図
- 【連載第5回】なぜ障害対応は「モグラ叩き」で終わるのか? 災害に強い都市を造るITILインシデント管理術
- 【連載第6回】 「クラウド貧乏」を卒業。コストを価値に変えるFinOps文化
クラウド運用に関するお悩みや、これからのパートナーシップのあり方にご興味をお持ちでしたら、どうぞお気軽にお声がけください。あなたのビジネスが直面している課題について、ぜひお聞かせいただけませんか。


