
はじめに
Geminiの利用料金や応答速度に課題を感じていませんか?「毎回同じプロンプトを送っていてコストがもったいない」「重いファイルの読み込みが遅い」…そんな悩みを解決するかもしれないのが「コンテキストキャッシュ」です。 この記事では、Geminiのコンテキストキャッシュ機能について、料金と応答速度の2つの側面から徹底的に比較・検証します。導入を検討している開発者の方は必見です。
Geminiのコンテキストキャッシュとは?
コンテキストキャッシュ(Context Caching)とは、Geminiへの繰り返されるリクエスト(プロンプト)を一時的に保存しておく機能のことです。このキャッシュを利用することで、API利用料の削減と回答のレイテンシ(応答速度)削減が期待できます。
Geminiのリクエスト料金は、入力トークン数と出力トークン数の合計で決まります。毎回のように「あなたは〇〇です。~~~」といった定型文(システムプロンプト)を送ると、その分の料金と処理時間がかかってしまいます。
コンテキストキャッシュは、この定型部分をいわば「事前学習」させておくことで、コストと時間を節約する仕組みです。
コンテキストキャッシュの2つの種類
コンテキストキャッシュには、2つの種類があります。
1. 暗黙的なキャッシュ
特別なコード記述なしで、Google Cloudプロジェクトでデフォルトで有効になっている短時間のキャッシュです。(Gemini 2.5の一部モデルなど ※) 手軽に後述の「明示的キャッシュ」と同等の割引(キャッシュ部分のみ)を受けられる可能性がありますが、キャッシュの保持時間や利用が保証されるわけではありません。
2. 明示的なキャッシュ
開発者がコードでキャッシュの作成・管理(CRUD)を明示的に行う方法です。(Gemini 2.0, 2.5の一部モデルなど ※) キャッシュの有効期限(TTL)や内容を細かく設定でき、反復する大量のプロンプトや、重い動画・PDFファイルなどの読み取りで特に効果を発揮します。
※ 対応モデルは変更される可能性があるため、最新の公式ドキュメントをご確認ください。 Vertex AI ドキュメント: コンテキスト キャッシュの概要
【料金比較】コンテキストキャッシュは本当に安くなる?
「キャッシュを使えば安くなる」と聞くと魅力的に聞こえますが、注意が必要です。
料金の仕組みと割引率
キャッシュに保存されたプロンプト部分(トークン)を再利用すると、その部分のトークン料金が大幅に割引されます。
- Gemini-2.0モデル:75%割引
- Gemini-2.5モデル:90%割引 (2025年11月現在)
ただし、コンテキストキャッシュを「作成するとき」と「保存する時間」にも別途料金が発生します。
- 作成時: 通常の入力トークン料金
- 保存時間: 保存時間料金(例: 100,000トークンあたり$0.1/時間 ※Gemini-2.5-flash)
料金比較シミュレーション
安易に「キャッシュを使えば得」と判断すると、逆にコストが高くつく可能性があります。 以下の条件で、キャッシュの有無による料金を比較してみましょう。
【仮定条件】
- モデル: Gemini-2.5-flash
- 料金(100,000トークンあたり):
- 通常入力: $0.00375
- キャッシュ保存: $0.1 / 時間
- リクエスト内容: 毎回の呼び出しで101,000入力トークン
- キャッシュ設定: 100,000トークンをキャッシュし、1時間保存する
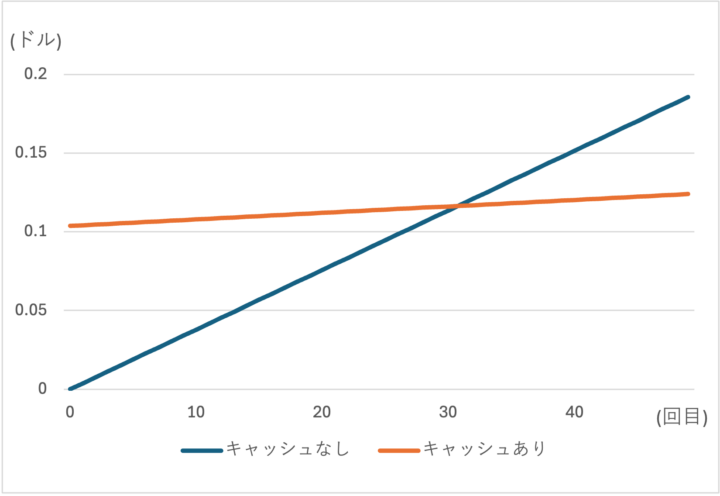
この図からも分かる通り、トークン数が10万程度で保存期間が1時間だと、30回程度キャッシュを呼び出さないとキャッシュ利用時の方が得にならないので、「コスパがいい」とは言えません。
金額差が明確になるよう、今回は1時間($0.1)を設定しましたが最低1分から設定ができるのでここは要件によって明確に決めておく必要があります。
また、コンテキストキャッシュには保存時間の更新ができるため、再利用されたときに動的に有効期限だけ伸ばすことも可能です。
※上記図はあくまで理想値です。実際には前述した暗黙的なキャッシュの利用もあるので「キャッシュなし」の料金は大きく変わる可能性があります。
結論:コスト削減は「条件次第」
料金面でのメリットを出すには、
- キャッシュするトークン数が非常に多い(例: 数十万〜数百万トークン)
- 短期間に集中して何度も再利用される
という条件が揃う必要があります。単に対話AIのシステムプロンプトをキャッシュする程度では、コストメリットは出にくい可能性が高いです。
【速度検証】応答速度はどれくらい速くなる?
様々なファイル形式のキャッシュでどこまで応答速度が変わるのかという検証を行いました。
※検証はローカル環境で行っています。クラウドとローカルの実行では応答速度は全体的に差が出ると考えられます。
【全体共通の条件】
- モデル: Gemini-2.5-flash
- ファイル保管場所: Cloud Storage
- 環境: ローカル (functions-framework使用)
検証1: テキストのみ (トークン数 ≒ 16,200)
| 1回目(s) | 2回目(s) | 3回目(s) | 4回目(s) | 5回目(s) | 平均(s) | |
| キャッシュなし | 34.31 | 37.71 | 25.73 | 38.28 | 38.37 | 34.88 |
| キャッシュあり | 21.90 | 16.65 | 15.84 | 08.44 | 12.24 | 15.01 |
テキストだけでも、平均して2倍以上高速化される結果となりました。
検証2: PDF (トークン数 ≒ 38,200 / 3本)
| 1回目(s) | 2回目(s) | 3回目(s) | 4回目(s) | 5回目(s) | 平均(s) | |
| キャッシュなし | 52.68 | 41.88 | 33.83 | 53.64 | 80.94 | 52.59 |
| キャッシュあり | 44.69 | 24.57 | 44.91 | 25.28 | 30.59 | 34.01 |
PDFでも明確な速度向上が見られます。
さらにトークン数を増やした検証(約144,000トークン/ 10本 )では、キャッシュなし平均147.09秒に対し、キャッシュあり平均62.89秒と、差がさらに開きました。
検証3: 画像 (PNG, JPG) (トークン数 ≒ 15,000 / 60枚)
| 1回目(s) | 2回目(s) | 3回目(s) | 4回目(s) | 5回目(s) | 平均(s) | |
| キャッシュなし | 40.50 | 37.13 | 26.78 | 27.53 | 34.02 | 33.19 |
| キャッシュあり | 46.21 | 35.41 | 46.60 | 31.92 | 37.58 | 39.54 |
意外なことに、画像ファイル(60枚)の検証では、キャッシュありの方が遅くなるという結果になりました。
これは、ファイル数が多く、個々のファイルサイズが比較的小さかったため、キャッシュ処理のオーバーヘッドが影響した可能性があります。
検証4: 動画 (MP4) (トークン数 ≒ 18,300 / 3本)
| 1回目(s) | 2回目(s) | 3回目(s) | 4回目(s) | 5回目(s) | 平均(s) | |
| キャッシュなし | 66.10 | 88.21 | 50.99 | 74.68 | 55.56 | 67.11 |
| キャッシュあり | 30.42 | 31.14 | 35.13 | 30.16 | 40.58 | 33.49 |
動画ファイルでは劇的な結果が出ました。キャッシュありの場合、応答速度が半分以下に短縮されています。
今回の検証に記載はありませんが、暗黙的なコンテキストキャッシュは6,70%程度使用されていたかなと感じます。
ですが、トークン数が多くなるにつれ、ヒット率も下がっていく印象でした。
また、驚いたことに暗黙的なコンテキストキャッシュの応答速度はキャッシュなしとほとんど変わらないことが多々あり、使用されたからと言って、応答速度の保証は全くできないです。
結論:速度向上は「ファイルサイズとトークン数」次第
検証結果から、コンテキストキャッシュは「1ファイルあたりのサイズが大きい(重い)」または「トークン数が多い」場合に、応答速度の向上に絶大な効果を発揮することが分かりました。 特にPDFや動画など、重いドキュメントを扱う場合には強力な武器となります。
⚠️ 知っておくべき「コンテキストキャッシュの制限」
非常に便利なコンテキストキャッシュですが、万能ではありません。特に注意すべき「制限」があります。
それは、「キャッシュ利用時にツールやシステム指示を動的に変更できない」ことです。
Geminiは、Google検索(グラウンディング)やVertex AI Searchなどを「ツール(Tools)」として設定できます。
# 通常のツール設定例
response = client.models.generate_content(
model='gemini-2.5-flash',
contents=contents,
config=GenerateContentConfig(
system_instruction="あなたは訊かれた質問にのみ答えてください。",
tools=[types.Tool(google_search=types.GoogleSearch())] # Google検索ツール
)
)
しかし、ツールを設定せずに作成したキャッシュを利用する際に、後からツールを追加しようとするとエラーになります。
# ツールなしでキャッシュを作成
# ... (create cache) ...
# キャッシュ利用時にツールを追加しようとするとエラー
response = client.models.generate_content(
model="gemini-2.5-flash",
contents='質問に答えてください。',
config=GenerateContentConfig(
cached_content=cache_name,
tools=[types.Tool(google_search=types.GoogleSearch())] # ← これがNG
),
)
# エラー: 'Tool config, tools and system instruction should not be set ...'
逆に、最初からキャッシュにツールを含めておくことは可能です。
# キャッシュ作成時にツールを含める
content_cache = client.caches.create(
model="gemini-2.5-flash",
config=CreateCachedContentConfig(
# ...
tools=[types.Tool(google_search=types.GoogleSearch())], # ← ここで設定
# ...
),
)
コンテキストキャッシュは、あくまで「静的なプロンプトと設定」を保管するためのもの、と覚えておく必要があります。
まとめ:コンテキストキャッシュの最適な活用シーン
今回の検証結果をまとめます。
- 料金削減
- 結論: 莫大なトークン数(数十万〜数百万単位)を、短期間に集中して再利用しない限り、大きなコストメリットは出にくい。
- 応答速度
- 結論: トークン数が多い、またはファイルサイズが大きい場合に絶大な効果を発揮する。
これらの特性を踏まえると、私が考えるコンテキストキャッシュが最も輝く活用シーンは「RAG (検索拡張生成)」であると思います。
社内ドキュメント、マニュアル、過去の動画アーカイブなど、「静的で莫大なデータ」をRAGの参照元としてコンテキストキャッシュに保管しておく。 こうすることで、ユーザーからの問い合わせ(プロンプト)のたびに重いファイルを読み込む必要がなくなり、応答速度の劇的な向上と、利用が集中した場合のコスト削減の両方を実現できる可能性があります。
Geminiのコンテキストキャッシュは、その特性を理解し、適切なシーンで利用することが成功の鍵となりそうです。
さいごに
最後まで読んでいただきありがとうございました!この記事が、あなたのGemini活用と開発の参考になれば幸いです。



