
DX開発事業部の前野佑宜です。
AWS re:Invent 2025の2日目(現地の日付では12/2)の Keynoteで発表された、Amazon Nova 2 Omniに関するワークショップ(12/2 15:30-17:30実施)に参加してきました。
本記事ではそのレポートの位置付けとしつつ、Nova2 Omniに関する情報を記載いたします。
アジェンダ

進め方として、、最初に Nova2 ファミリーのモデルの概要についての説明があり、、その後実際にハンズオンで手を動かす、という進め方でした。
事前にワークショップ用のアカウントが用意されており、SageMaker Code Editor上のJupiterLabの事前作成済みノートブックを使用しながら進めました。
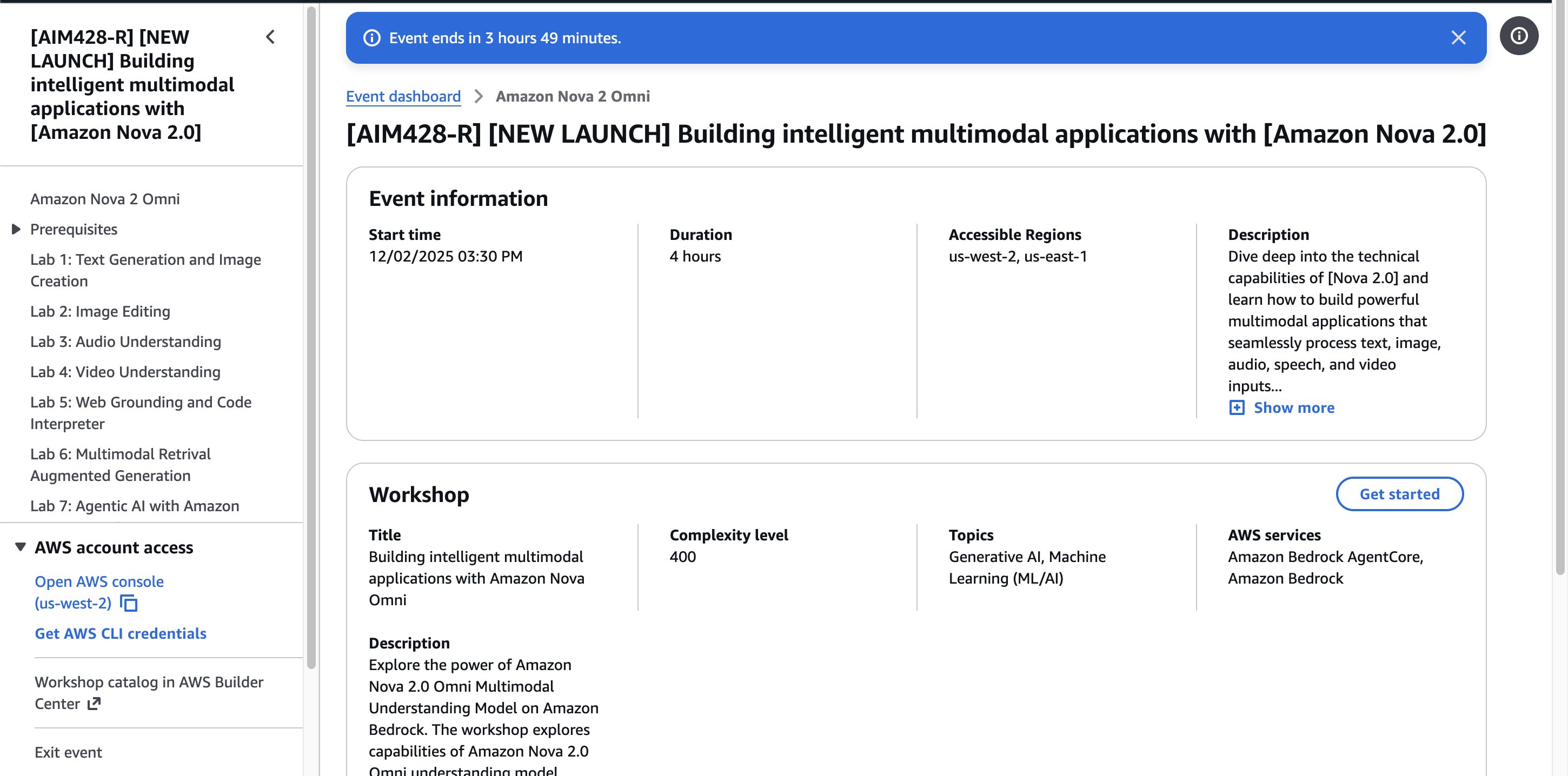
Amazon Nova2 Omni概要
Nova2 ファミリーについて説明があり、その中でハンズオン内で登場するNova2 Omniに関する説明がありました。

説明を踏まえて、Nova2 Omniの特徴は以下であると整理できました。
- マルチモーダルな理解が可能
- テキスト、画像、動画、音声が入力として対応しており、テキストと画像が出力に対応している
- 高度な画像生成能力がある
- 1M(100万)トークンのコンテキスト長をサポートしている
※Introducing Amazon Nova 2 Omni in Previewに記載があるように、現在ではNova Forgeを利用しているユーザーにおいて利用可能とのことで、現在(記事執筆時点:2025/12/3)では利用できるユーザーが限定されていることにご注意ください。
Nova 2 Omni is in preview with early access available to all Nova Forge customers, and to authorized customers. Please reach out to your AWS account team for access.
ハンズオンの内容
上記特徴を活かしたユースケースが多数ノートブックに収録されており、それを各人のペースで進めながら、不明点があれば質問する、といった進め方でした。
例えば、音声の会議データから要約した内容を検出する、動画からシーンを抽出する、Strands Agentsと組み合わせたマルチエージェントシステムを作成する、といったものがありました。
全てのユースケースを実際に体験しましたが、本記事では、上記記載の「高度な画像生成能力の部分」に係る部分に焦点を当てて説明することとします。
「画像の一部を編集する」機能を体感
サンプルコードを使用して、Nova Omniの画像編集能力について体感してみました。
既存の画像に、要素を追加する
REGION_ID = "us-west-2"
MODEL_ID = "us.amazon.nova-2-omni-v1:0"
BEDROCK_ENDPOINT_URL = "https://bedrock-runtime.us-west-2.amazonaws.com"
READ_TIMEOUT_SEC = 3 * 60
MAX_RETRIES = 1
import boto3
from botocore.config import Config
import json
import timeit
from botocore.exceptions import ClientError
from IPython.display import Image, display
import base64
def analyze_image(image_path, text_input):
"""Analyze an image with text input using Amazon Bedrock Nova model."""
# Read and encode image
with open(image_path, "rb") as image_file:
image_data = image_file.read()
# Determine image format
import os
ext = os.path.splitext(image_path)[1].lower()
image_format = 'jpeg' if ext in ['.jpg', '.jpeg'] else 'png' if ext == '.png' else 'jpeg'
# Create Bedrock client
config = Config(
read_timeout=READ_TIMEOUT_SEC,
retries={"max_attempts": MAX_RETRIES},
)
bedrock_runtime = boto3.client(
service_name="bedrock-runtime",
region_name=REGION_ID,
#endpoint_url=BEDROCK_ENDPOINT_URL,
config=config,
)
# Prepare request
request = {
"modelId": MODEL_ID,
"messages": [
{
"role": "user",
"content": [
{"image": {"format": image_format, "source": {"bytes": image_data}}},
{"text": text_input},
],
}
],
"inferenceConfig": {"temperature": 0.1, "maxTokens": 10000},
}
# Make API call
response = bedrock_runtime.converse(**request)
return response
def process_response(response, input_image_path):
"""Process and display response content with input and output images."""
# Display input image first
print("== Input Image ==")
display(Image(filename=input_image_path))
response_content_list = response["output"]["message"]["content"]
# Extract image content block
image_content = next(
(item for item in response_content_list if "image" in item),
None,
)
# Extract text content block
text_content = next(
(item for item in response_content_list if "text" in item),
None,
)
if text_content:
print("== Text Output ==")
print(text_content["text"])
if image_content:
print("== Output Image ==")
image_bytes = image_content["image"]["source"]["bytes"]
display(Image(data=image_bytes))
INPUT_IMAGE_PATH = "img/1-kitchen-granite-island-empty.png"
TEXT_INPUT = "You are given realestate listing image of an empty kitchen. Add bar stools to island, fruit bowl and some ceremic containers to kitchen for virual staging"
try:
start = timeit.default_timer()
response = analyze_image(INPUT_IMAGE_PATH, TEXT_INPUT)
elapsed = timeit.default_timer() - start
print(f"Request took {elapsed:.2f} seconds")
process_response(response, INPUT_IMAGE_PATH)
except ClientError as err:
print("Error occurred:")
print(err)
if hasattr(err, "response"):
print(json.dumps(err.response, indent=2))
以下のpythonコードが使われており、Bedrock Converse APIを使って モデルを呼び出す、というシンプルな作りでした。プロンプトでは、「バーチャルステージングのため、何もないキッチンに
バースツール、フルーツボウル、そしていくつかの陶器製の容器を追加してください」という指示を与えて、キッチンの画像をINPUT_IMAGE_PATHで指定してあげると、指示通りの出力がされていることを確認できました。
指示を出した部分以外は画像が変わっていない部分がポイントですね。指示を出す度に微妙に画像のテイストが変わってしまう、という経験は過去にあったのでこれは便利だと感じました。


背景の修正

既存の画像はそのままに、画像の背景だけ変更する、といったことも可能でした。以下では、背景以外のものはそのままに、ダークな空の色を青色にして、という指示を投げた結果です。指示通りの画像が出力として返ってきていることが確認できます。

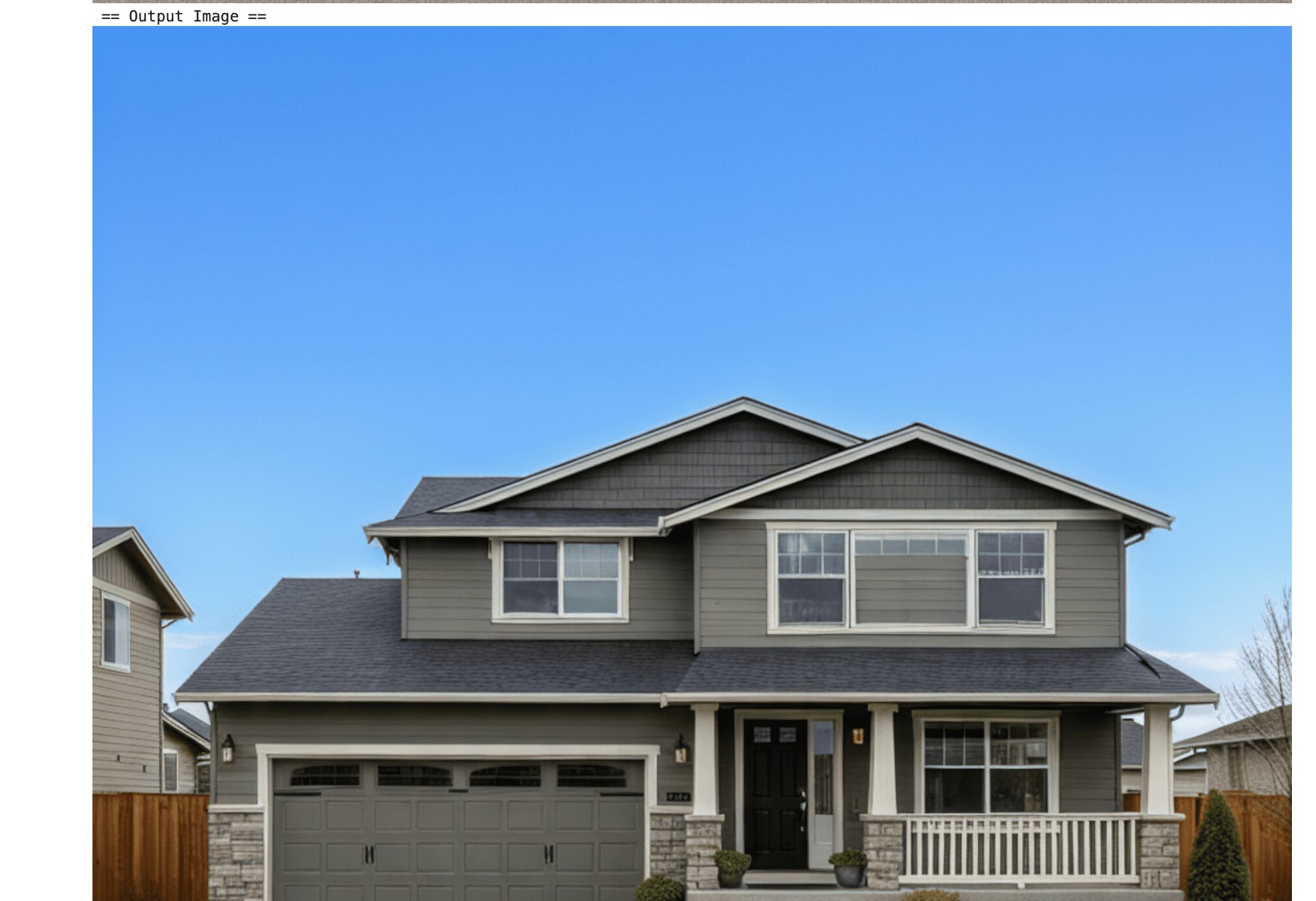
資料には、以下のような画像の修正に対応している、との記載がありました。and possibly moreと記載があるので、プロンプトの出し方次第で、柔軟な制御が期待できます。

- 要素の追加・削除・置換
- 要素の入れ替え(例:「彼のシャツを赤に変更して」)
- 背景の変更
- 画像内の要素を抽出する
- 被写体の同一性を変えずに、動作やポーズを変更する(例:「この人を笑顔にして」「男性を左側を見ているようにして」)
- 要素の位置を変更する(例:「りんごを画像の左半分に移動して」)
- 画像のスタイルを変更する
- 画像内の文字を変更する
料金体系
ワークショップ内では説明されていませんでしたが、料金体系について調べてみました。
Standard Tierにおいては、以下であるようでした。(※)
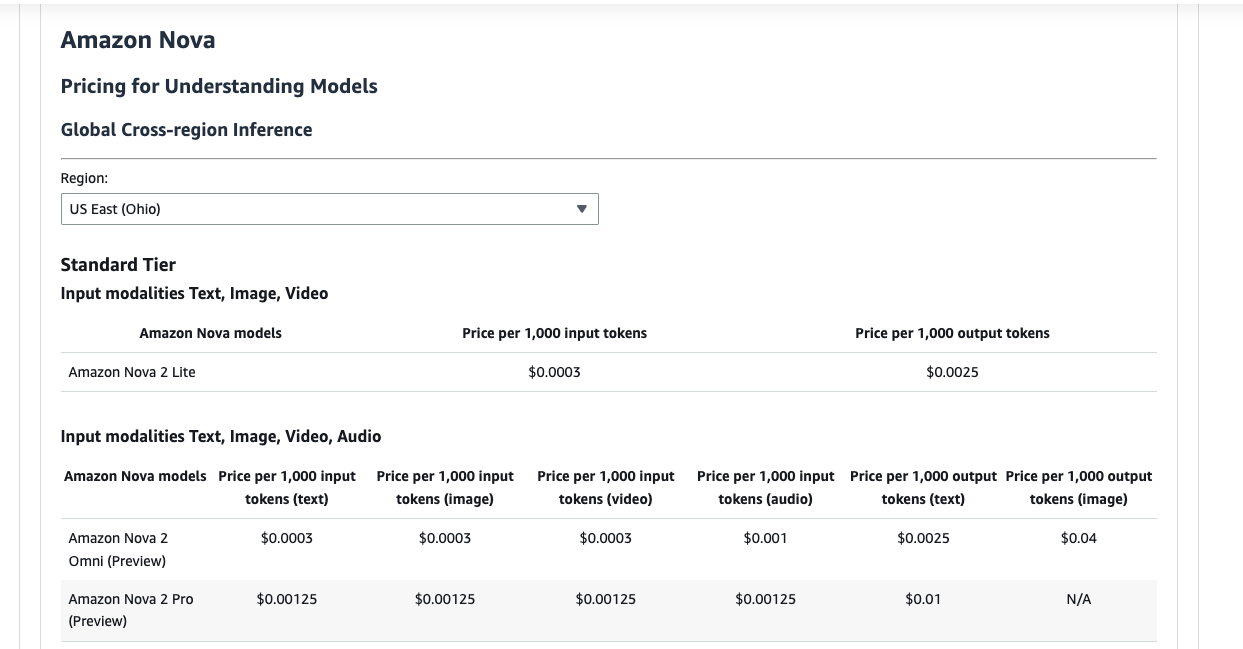
- 入力: 1,000入力トークンあたり $0.0003
- 出力: 1,000出力トークンあたり $0.0025
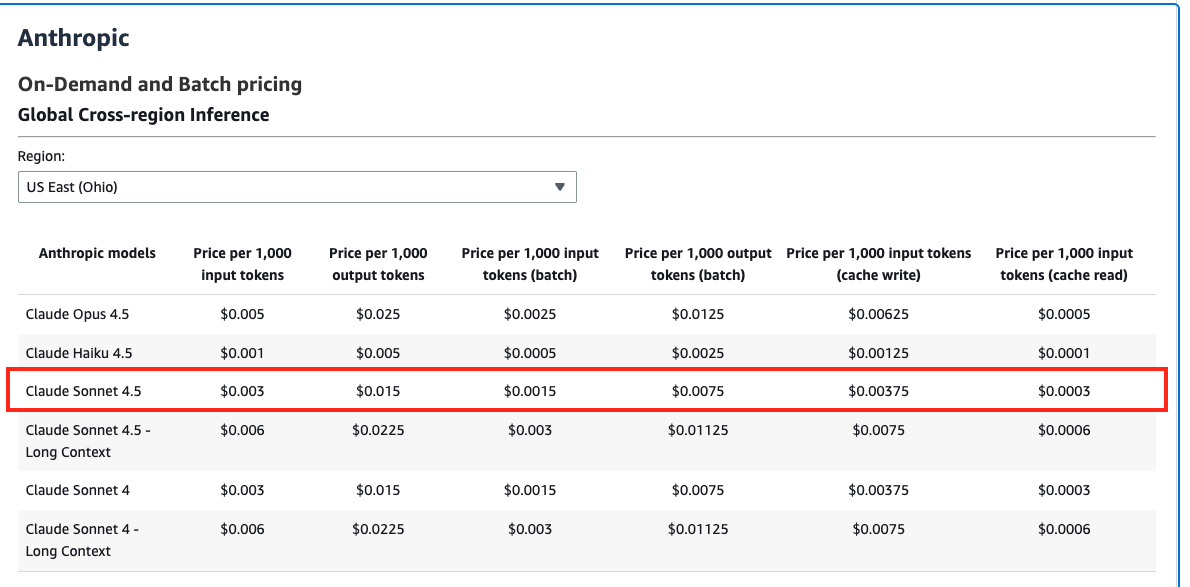
比較として、Anthropic社のClaude Sonnet 4.5モデルは(参照)
- 入力: 1,000入力トークンあたり $0.003
- 出力: 1,000出力トークンあたり $0.015
なので、ある程度安価に利用できるのかな、という印象です。
※ Tierの概念について
Standard Tier・Priority Tier・Flex Tierという概念が2025年11月、Bedrockにおいて発表されています。参照
詳しくはBedrockの料金ページに記載があるのでご覧いただければと存じますが、以下のようなユースケースとのことでした。
- Flex Tier: 非時間的制約のあるアプリケーションに対してコスト効率の良い価格設定を提供
- Priority Tier: ミッションクリティカルなアプリケーションに対して優先的な処理と優れたパフォーマンスを提供
まとめ
簡単ではありますが、セッションの内容をご紹介しつつ、Amazon Nova 2 Omniの特徴について触れてみました。
画像編集については、かなり精度が高いなと実感しました。
ここではご紹介しきれませんでしたが、他にもWebグラウンディング機能なるものもあり、機能が充実していた印象です。
現時点で非常に便利なモデルだなと実感はしつつ、プレビュー版での提供、ということで、今後のアップデートにも期待していきたいと思います。
また、今回新たなモデルがローンチ直後に、すぐにこういったワークショップがオープンして実践的に学べる点はre:Inventに参加していて良いな、と感じております!
