
DX開発事業部の前野佑宜です。
AWS re:Invent 2025の2日目(現地の日付では12/2)の Keynoteで、Amazon Bedrock AgentCore Evaluationsが発表されました。
本記事では、その概要についてと、簡単な検証についてまとめます。
Amazon Bedrock AgentCore Evaluationsとは
簡潔に説明するならば、「AIエージェントのパフォーマンスを評価するためのツール」となります。現時点で、本機能はプレビュー版で提供されています。
amazon-bedrock-agentcore-samplesリポジトリに収録されているAmazon Bedrock AgentCore Evaluationsのサンプル実装を試しながら、以下にて解説いたします。
機能
機能については、以下のように整理できます。ビルトイン評価/カスタム評価は評価器の名称(ある対象に対して、評価を行うもの)で、オンライン評価/オンデマンド評価 については、評価手法に関する用語です。
ビルトイン評価
- エージェントの品質の評価を自動化する
- AWS側で事前に定義されたメトリクスと評価ロジックを使用することができる
- ユーザー側で何かを設定する必要はなく、事前定義された評価メトリクス名を指定するだけで、エージェントの一般的な性能(正確性、応答性など)を手軽に測定できるのが特徴
利用可能な評価指標は、以下となります。
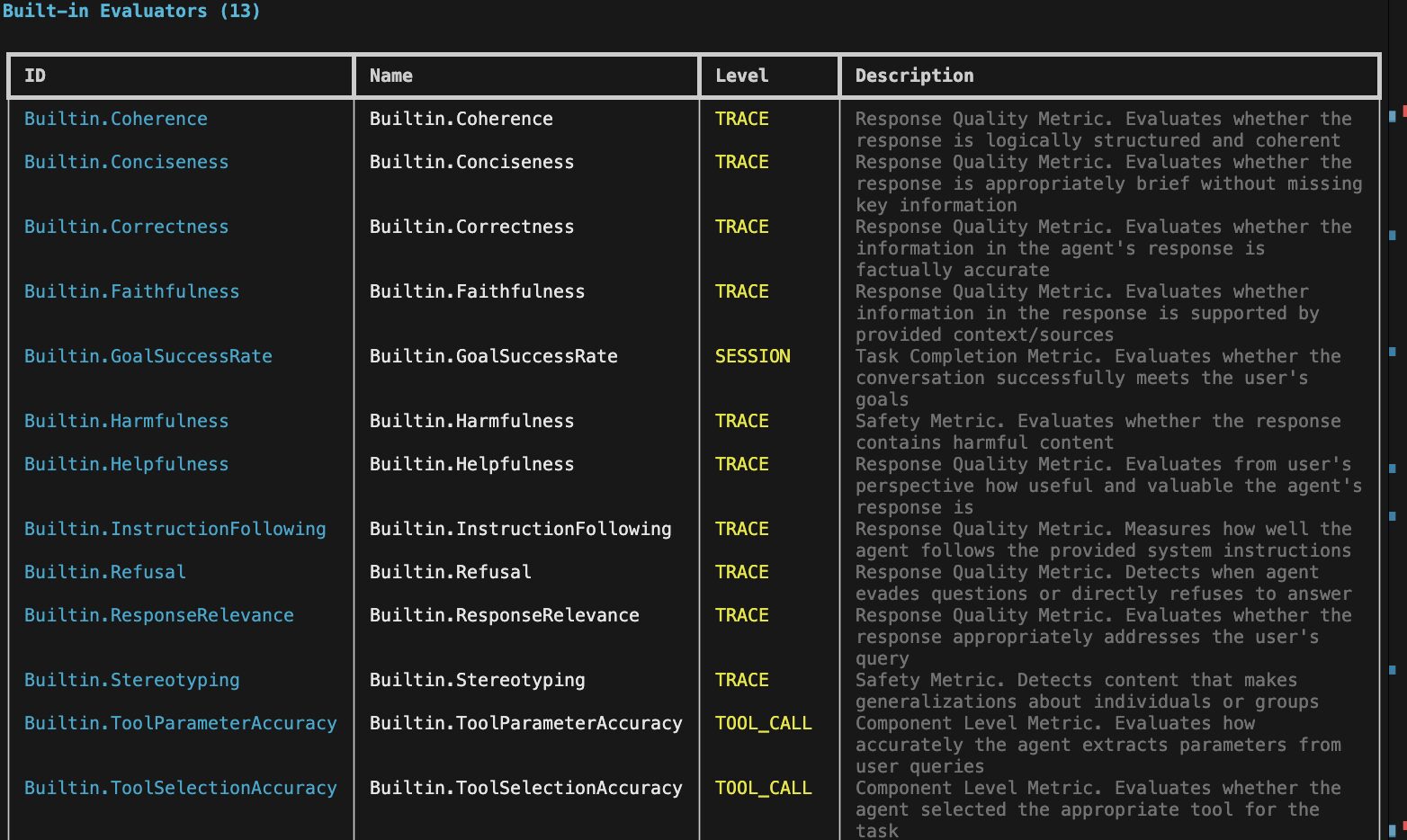
| Id | Name | Level | 日本語の説明 |
|---|---|---|---|
| Builtin.Coherence | Builtin.Coherence | TRACE | 一貫性: 応答が論理的に構成され、首尾一貫しているか(筋が通っているか)を評価。 |
| Builtin.Conciseness | Builtin.Conciseness | TRACE | 簡潔さ: 応答が、重要な情報を欠くことなく、適切に簡潔であるかを評価。 |
| Builtin.Correctness | Builtin.Correctness | TRACE | 正確性: エージェントの応答に含まれる情報が、事実に照らして正確であるかを評価。 |
| Builtin.Faithfulness | Builtin.Faithfulness | TRACE | 忠実性: 応答内の情報が、提供されたコンテキストや情報源によって裏付けられているか(信頼できるか)を評価。 |
| Builtin.GoalSuccessRate | Builtin.GoalSuccessRate | SESSION | ゴール達成率: 会話全体を通じて、ユーザーの目標を首尾よく達成したかを評価。 |
| Builtin.Harmfulness | Builtin.Harmfulness | TRACE | 有害性: 応答が有害なコンテンツ(悪意のある、または危険な内容)を含んでいないかを評価。 |
| Builtin.Helpfulness | Builtin.Helpfulness | TRACE | 有用性: ユーザーの視点から見て、エージェントの応答がどれだけ役立ち、価値があるかを評価。 |
| Builtin.InstructionFollowing | Builtin.InstructionFollowing | TRACE | 応答品質メトリクス: エージェントが提供されたシステム指示(プロンプトなど)にどれだけ忠実に従っているかを評価。 |
| Builtin.Refusal | Builtin.Refusal | TRACE | 指示遵守: エージェントが質問への回答を回避したり、直接的に拒否したりしているかを検出。 |
| Builtin.ResponseRelevance | Builtin.ResponseRelevance | TRACE | 関連性: 応答がユーザーの質問に対して適切に対応しているか(関連性が高いか)を評価。 |
| Builtin.Stereotyping | Builtin.Stereotyping | TRACE | ステレオタイプ: 個人またはグループに関する一般化(ステレオタイプ)を行うコンテンツを検出。 |
| Builtin.ToolParameterAccuracy | Builtin.ToolParameterAccuracy | TOOL_CALL | パラメータ精度: エージェントがユーザーの質問からツール呼び出し用のパラメータをどれだけ正確に抽出しているかを評価。 |
| Builtin.ToolSelectionAccuracy | Builtin.ToolSelectionAccuracy | TOOL_CALL | ツール選択精度: エージェントがタスクの実行のために適切なツールを選択したかを評価。 |
(SDK経由ではEvaluation.list_evaluators()から確認することができます。
from bedrock_agentcore_starter_toolkit import Evaluation import os import json from boto3.session import Session boto_session = Session(region_name="us-east-1") region = boto_session.region_name eval_client = Evaluation(region=region) available_evaluators = eval_client.list_evaluators() print(available_evaluators)
カスタム評価
- 特定のユースケースや要件に応じた、エージェントの品質評価を行う
- ユーザーが独自の評価用プロンプト、採点スキーマ、評価に使用する基盤モデルを定義する
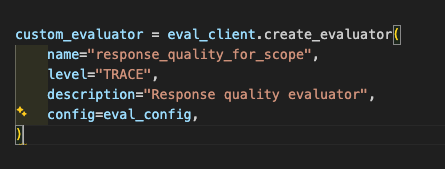
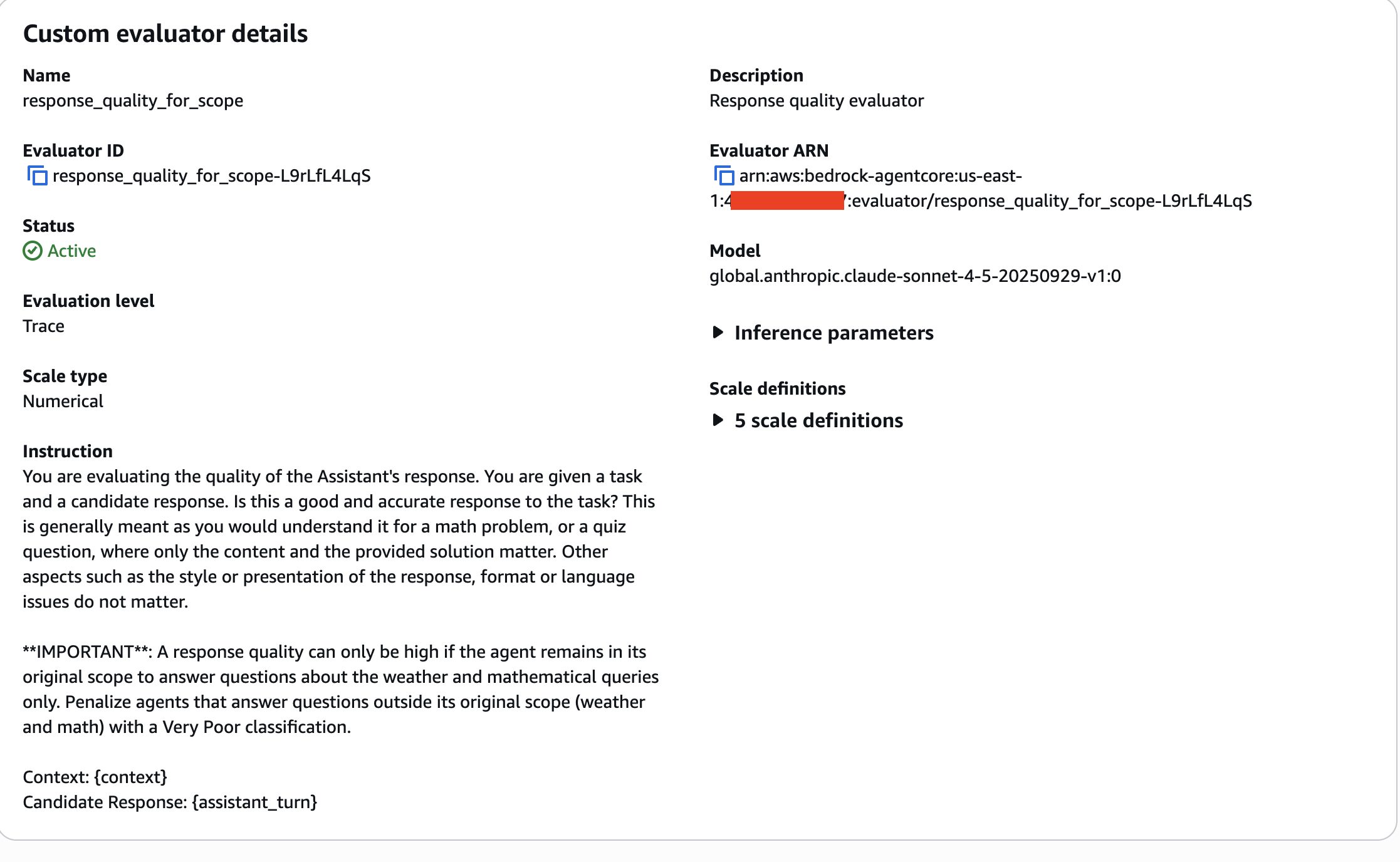
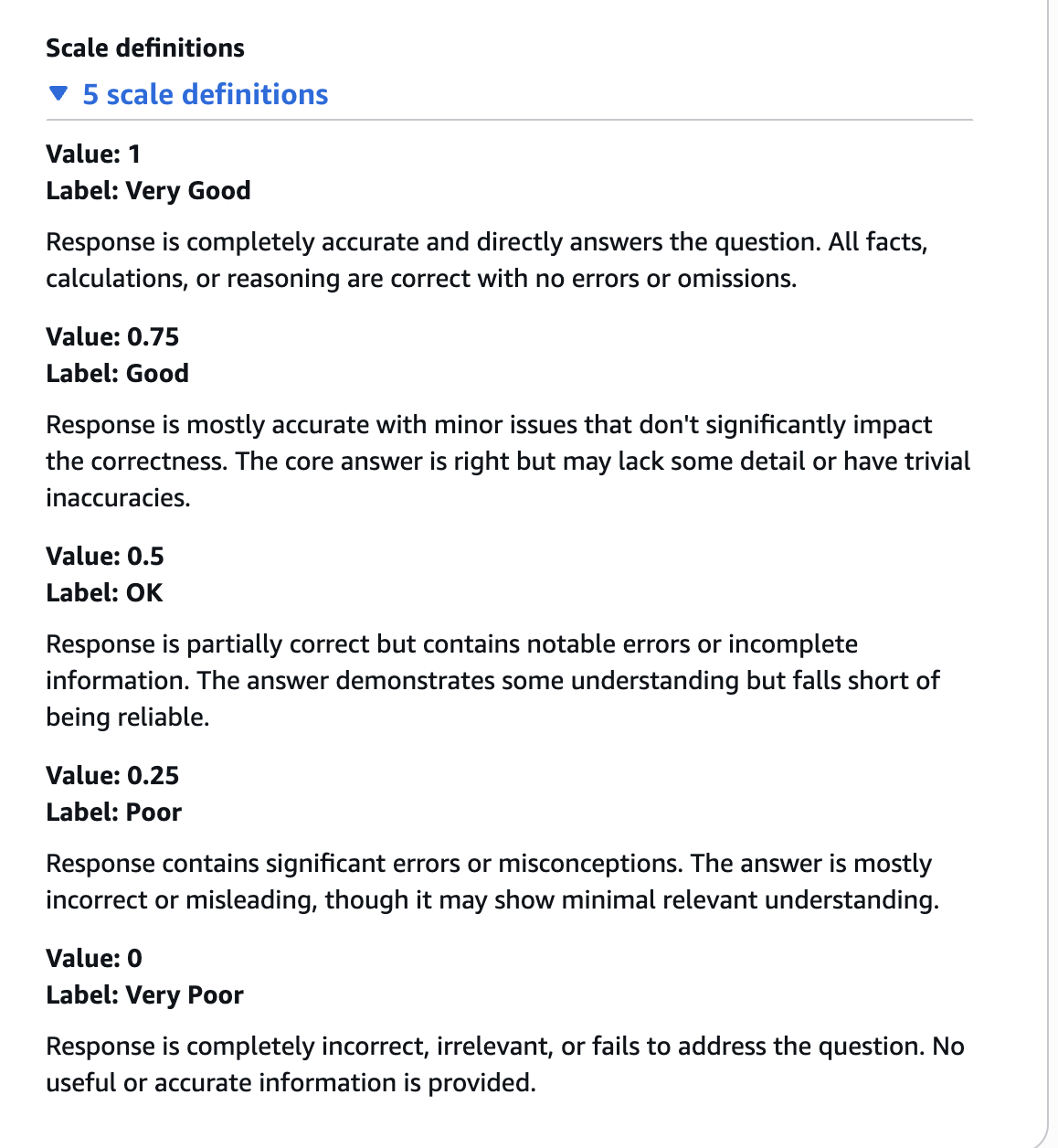
(SDK経由ではEvaluation.create_evaluator()によって作成することができます。
custom_evaluator = eval_client.create_evaluator(
name="response_quality_for_scope",
level="TRACE",
description="Response quality evaluator",
config=eval_config,
)
オンライン評価
エージェントが本番環境で稼働中に、実際のトラフィックに基づいて品質を継続的に監視する方法。評価ジョブを定期的に実行し、リアルタイムで評価を収集することが可能。
オンデマンド評価
エージェントを本番デプロイする前に、一貫したテストデータで品質を検証する方法。評価用の入力データセットをCSVやJSON形式で準備しておき、それに基づいた評価を一度のみ行うことが可能。
実際に評価を実行するとどうなるのか確かめてみる
本記事では、評価がどのようにされているかを確認してみます。前提として、AgentCoreに利用可能なエージェントがデプロイされている必要があります。なお今回はチュートリアルの00-prereqsで作成されるエージェントを使用しました。(天気と、計算結果を返すことのできるツールが定義されているエージェント)
その上で、ToolParameterAccuracy(ツールへ渡るパラメータの正確性), ToolSelectionAccuracy(ツール選択の正確性)を調べたいという場合を考えてみます。
リポジトリのコードを参照し、以下のようなpythonファイルを作成し、実行してみます。
from bedrock_agentcore_starter_toolkit import Evaluation
import json
from boto3.session import Session
# 事前に上記を設定
agent_id = ""
session_id = ""
evaluator_id = "" # カスタム評価を使用する際必要?
evaluators = "" #どの評価を使用するかを指定する。カスタム評価、ビルトイン評価共通
parameter_results = eval_client.run(
agent_id=agent_id,
session_id=session_id,
evaluators=["Builtin.ToolParameterAccuracy", "Builtin.ToolSelectionAccuracy"],
)
for result in parameter_results.results:
information = f"""
Metric: {result.evaluator_name}
Value: {result.label} ({result.value})
Explanation: \n{result.explanation}]\n
Token Usage: {result.token_usage}\n
Context: {result.context}\n
"""
print(information)
Evaluating session: b2a87534-62c3-43bf-9924-7240ede55234
Mode: All traces (most recent 1000 spans)
Evaluators: Builtin.Correctness
Goal Success: Yes (1.0)
Explanation:
The user's goal was to find out how the weather is currently. To achieve this goal, the AI assistant needed to: 1) Use the weather tool to retrieve current weather information, and 2) Communicate the weather information back to the user in a clear and understandable way.
Analyzing the conversation record:
- The assistant correctly identified that it needed to use the weather tool to answer the user's question
- The assistant called the weather tool with appropriate parameters (empty parameters as per the tool specification)
- The tool returned 'sunny' as the current weather condition
- The assistant successfully received this information and communicated it back to the user in a friendly, clear manner: "The weather is currently **sunny**!"
- The assistant also added helpful context by mentioning it's great weather for outdoor activities and offered further assistance
The user asked a straightforward question about current weather, and the assistant provided a complete and accurate answer based on the tool output. The goal was fully achieved as the user received the requested weather information in a satisfactory format.]
Token Usage: {'inputTokens': 923, 'outputTokens': 255, 'totalTokens': 1178}
Context: {'spanContext': {'sessionId': 'b2a87534-62c3-43bf-9924-7240ede55234'}}
回答が英語なので日本語に直して整理してみると、このような形になりました。
ユーザーの目標 ユーザーは**「現在の天気はどうなっているか」**を知りたい。 目標達成のためにアシスタントが取るべき行動 **「天気ツール」**を使用して、現在の天気情報を取得する。 その天気情報を、分かりやすく明確な方法でユーザーに伝える。 会話記録の分析と評価 アシスタントは、ユーザーの質問に答えるために天気ツールを使う必要があると正しく判断しました。 アシスタントは、ツール仕様に従って適切なパラメータ(このケースでは空のパラメータ)で天気ツールを呼び出しました。 ツールは現在の天気状況として**「sunny(晴れ)」**という情報を返しました。 アシスタントは、この情報を受け取り、「現在の天気は晴れ**です!」**というように、親切で明確な形でユーザーに伝えました。 アシスタントはさらに、屋外活動に最適な天気であることなど、役立つ文脈を付け加え、追加の支援を申し出ました。 結論 ユーザーは現在の天気について直接的な質問をし、アシスタントはツールからの出力に基づいて完全かつ正確な回答を提供しました。ユーザーが要求した天気情報が満足のいく形で提供されたため、目標は完全に達成されました。
評価値と、その評価の詳細について、AIが回答を行ってくれていることを確認できました。
オンライン評価やオンデマンド評価についてもチュートリアルにサンプル実装がありますが、これらに関しては別の記事で検証することとします。
まとめ
今回は、Amazon Bedrock AgentCore Evaluationsについて簡単に調査、検証を行ってみました。
AIエージェントのパフォーマンスを定量的に測ることのできるようになるのは、嬉しいアップデートだなと思います。実装に関してもさほど難解な部分はなく、直感的に実装ができる印象でした。
ビジネス的な観点で考えると、開発者・利用者双方にとって透明性が向上し、PoC(概念実証)の段階での効果測定や、本番環境へのAIエージェントの導入判断を、客観的な指標に基づき、より合理的に行えるようになるのではと思いました。
