
クラウドインテグレーション事業部の石川優です。
クラウド環境におけるFinOpsプラクティスをAIが変革する方法について。断片化されたコストデータと最適化プロセスに取り組むインテリジェントエージェントについてのセッションレポートです!!
セッション概要
AI is transforming FinOps practices in complex multi-account cloud environments. This chalk talk explores building intelligent agents that tackle fragmented cost data and optimization processes. Learn to architect solutions using Amazon OpenSearch for data aggregation and Amazon Bedrock for contextual reasoning, enabling autonomous cost analysis and recommendations. Examine proven implementation patterns for data ingestion workflows, financial prompt engineering, and human-in-the-loop processes. Discover how to design secure, scalable FinOps solutions that continuously optimize costs while maintaining performance and compliance.
AIは、複雑なマルチアカウントクラウド環境におけるFinOpsの実践を変革しています。このチョークトークでは、断片化されたコストえー他と最適化プロセスに対処するインテリジェントエージェントの構築について考察します。Amazon OpenSearchによるデータ集約とAmazon Bedrockによるコンテキスト推論を活用し、自律的なコスト分析と推奨を実現するソリューションの構築方法を学びます。データ取り込みワークフロー、金融プロンプトエンジニアリング、そして人間参加型プロセスにおける実証済みの実装パターンを検証します。パフォーマンスとコンプライアンスを維持しながら、継続的にコストを最適化する、安全でスケーラブルなFinOpsソリューションを設計する方法を学びます。
チョークトークというセッションでホワイトボードを使うことと、参加者と議論があったりするのが特徴です!

会場の雰囲気
内容


FinOps に関わる人がそれぞれどのような課題を抱えているか。
- FinOps/財務マネージャー: 数百のアカウント全体のコストを俯瞰し、詳細まで掘り下げたい。財務チームとエンジニアリングチームの両方が理解できるレポートが必要。
- エンジニアリングマネージャー: 環境ごとの支出を把握し、リアルタイムで暴走コストを特定したい。週末や月末のレポートでは遅すぎる。
- プロダクトオーナー: 新機能リリース後の支出変化を知りたい。過去との比較分析や、隠れたピーク容量やオートスケールの機会を見つけたい。
異なる課題を持っているからダッシュボードで一元化するのが難しく、レポート作成に時間を取られたりする。

データ、プロセス、ツールの3つの課題がある。
データの課題:
- データが断片化している。Cost and Usage Report、CloudWatchアラーム、Compute Optimizerの推奨事項など、様々なソースからデータが来る。
- データ品質の問題。タグ付けが不完全だったり、異なる部門が同じリソースに異なるタグを付けたりする。
- これらのデータソース間の関係性をモデル化することが難しい。
プロセスの課題:
- ダッシュボードをペルソナごとにカスタマイズするリソースがFinOpsチームにない。
- 開発者やエンジニアリングチームもFinOps以外の業務に追われている。
ツールの課題:
- ペルソナごとに異なるツールやフレーバーが必要になる。
- 進化するアプリケーションに対してリソースを最適化し続けることが複雑。
参加者から「ビジネスユーザーはPower BIのようなツールを使いたがり、AWSコンソールのコストレポートを見たがらない」という意見が出ました。
「それもプロセス、ツールの課題の一つとのことでした」

それに対してAIエージェントがどのように役立つか。
- 自律的な監視: CloudWatchログやCURログを常時監視し、アクションを実行。
- インテリジェントな最適化: 監視の中で最適化の機会を発見し、アラートを生成したり、人間が承認した後に是正措置を取る。非本番環境であれば、誤った判断の影響が限
定的なため、エージェントに自動対応させることも可能。
- 自然言語での質問応答: ビジネスユーザーがダッシュボードに表示されていない追加の質問を自然言語で投げかけられる。「どの事業部がこのコストを発生させたのか」「なぜこの日にスパイクが起きたのか」といった質問にエージェントが答える。
- 予測とフォアキャスティング: MLモデルと連携し、将来のコストを予測。月末の請求書を待つのではなく、事前にコストを把握できる。
AIエージェントは「プロセス」と「ツール」の課題を解決します。「データ」は?
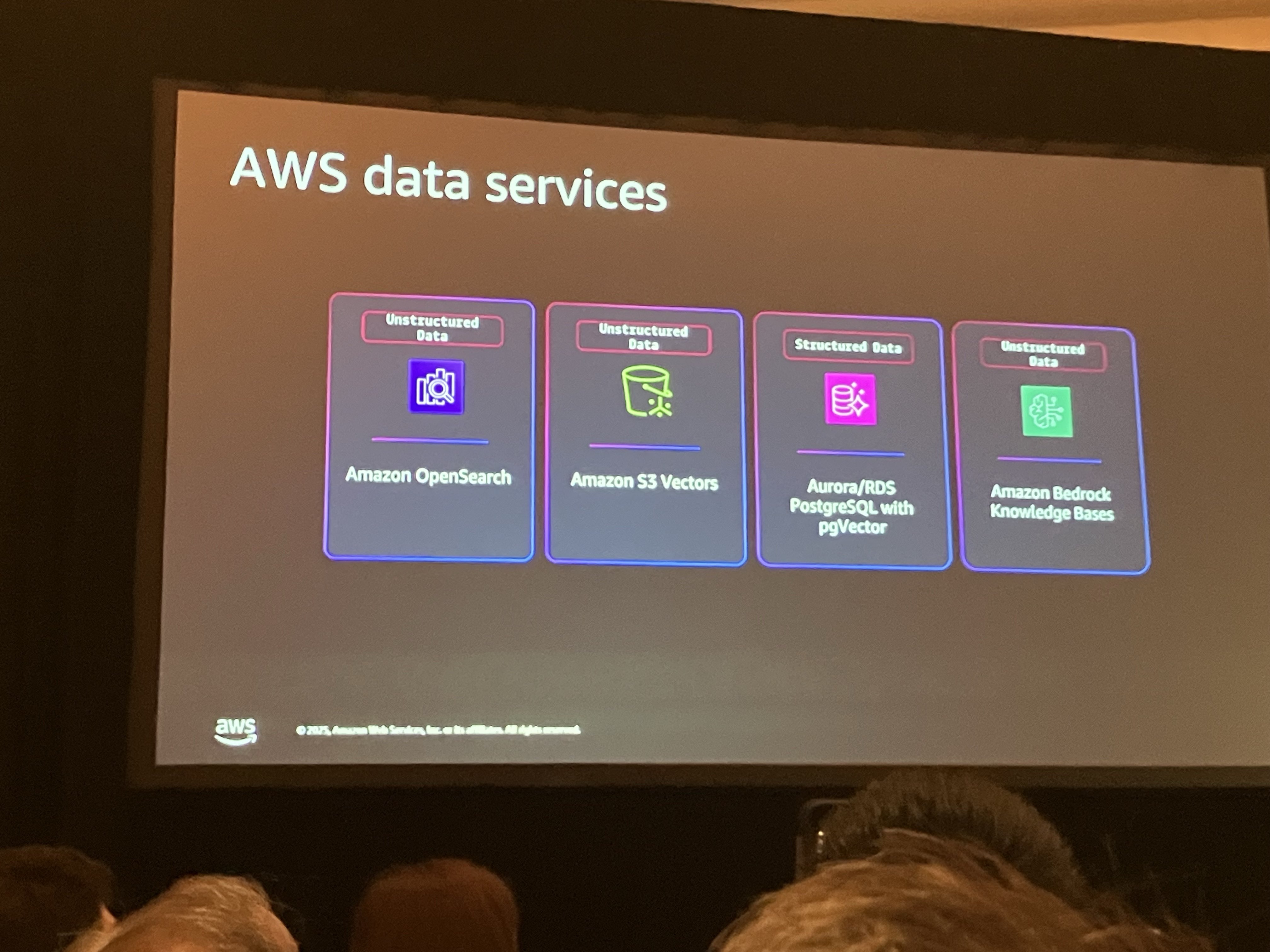
データはAIが参照できるように、ベクトル化できるサービスに保存しましょうとのことでした。


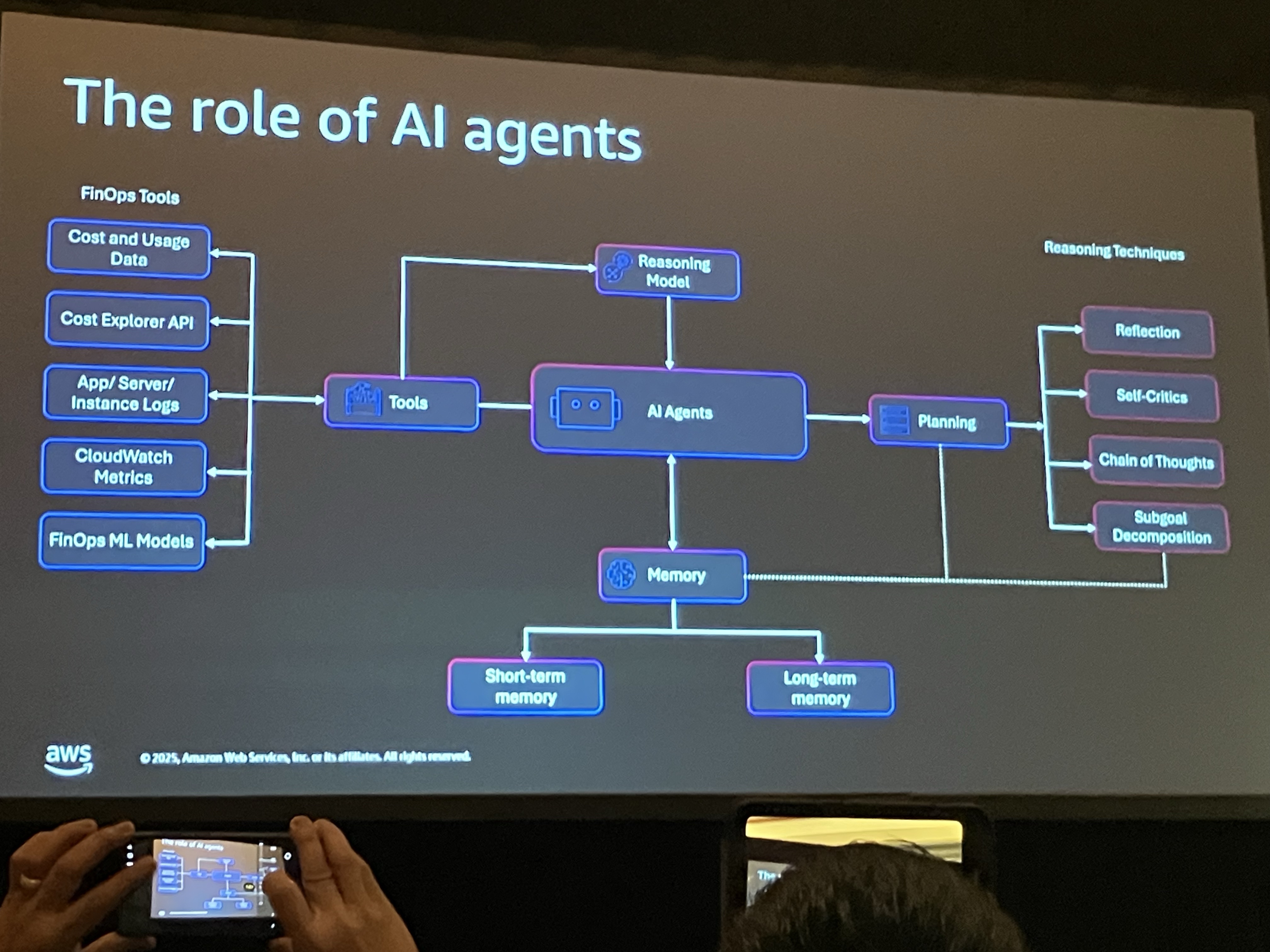
エージェントを本番環境で動かすには、セキュリティ、スケーラビリティ、ツールへの接続、監視が必要で、エージェントコアはそれら全てを賄うフルマネージドサービス。
- Agent Core Runtime: セッションレベルの分離を提供し、ユーザー間のクロスコンタミネーションを防ぐ。最大8時間の長時間非同期ジョブに対応し、最大100MBのデータソースをサポート。サーバーレスで、インフラ管理が不要。
- Agent Core Gateway: ツールへのアクセスを標準化。既存のAPIやLambda関数をMCP(Model Context Protocol)互換のツールとして公開し、エージェントが安全に利用できるようにする。
- Agent Core Identity: 認証情報の一元管理を提供。ユーザーが認証した後、そのパーミッションをエージェントに委譲し、エージェントがAWSリソースにアクセスする際にIAMやOAuthトークンを使用。
- Agent Core Memory: LLMはステートレスなため、会話を記憶するためのメモリコンポーネントを提供。短期メモリ(セッション内の会話)と長期メモリ(過去の会話のサマリー)を管理。
- Agent Core Observability: OpenTelemetryロギングを提供し、エージェントが適切なツールを呼び出しているか、正しいゴールに従っているか、適切なプランニングをしているかを監視。
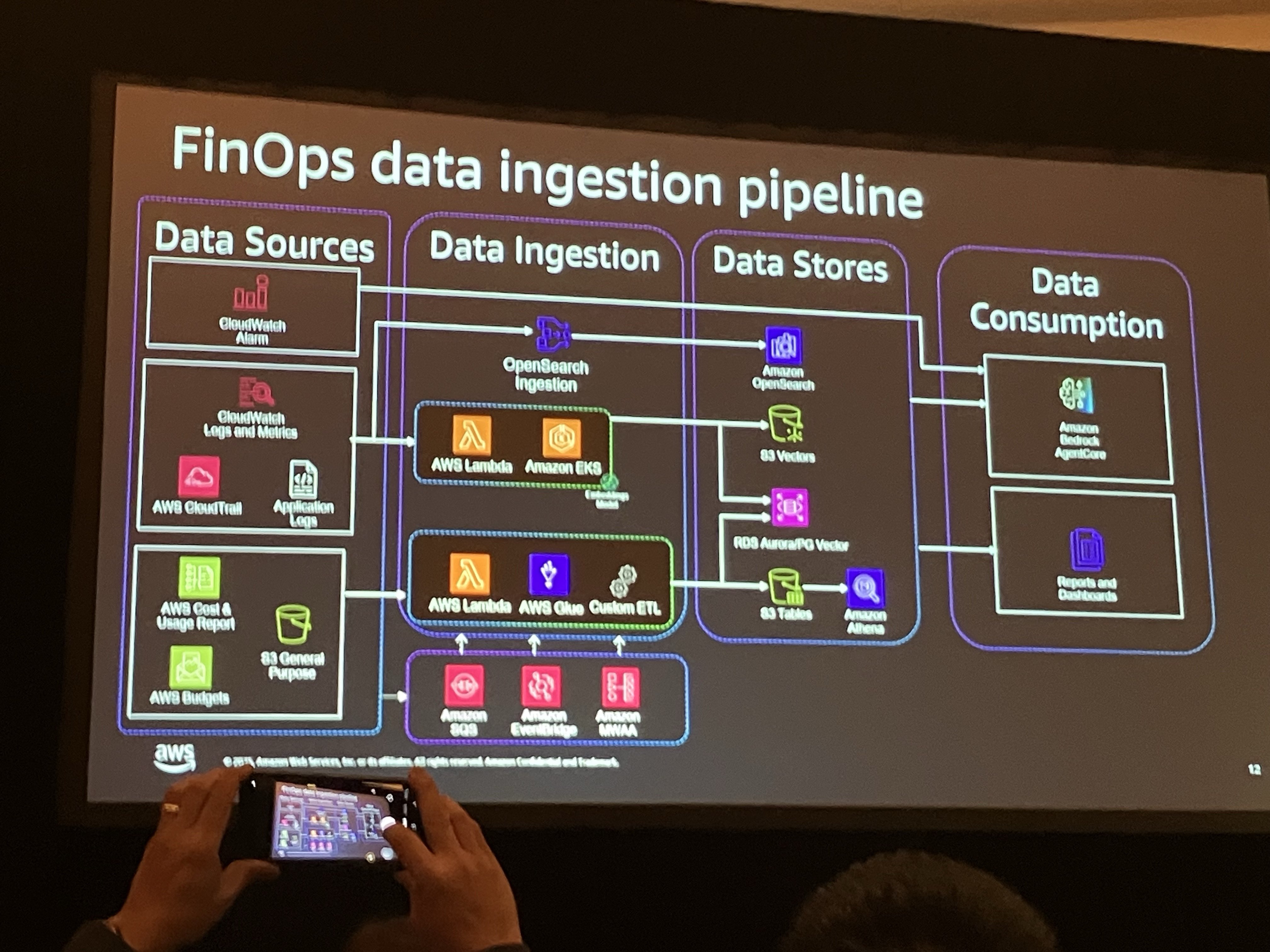
FinOps でどのようなデータパイプラインが必要か。
データソースと保存方法:
- 非構造化データ: CloudWatchログ、推奨事項など。これらはベクトル化してベクトルストアに保存。Amazon OpenSearch、Aurora PostgreSQL(pgvector拡張)、Amazon Bedrock Knowledge Basesなどが利用可能。
- 構造化データ: Cost and Usage Report、予算データ、CMDBなど。S3にParquet形式で保存し、Amazon Athenaでクエリするか、Aurora PostgreSQLなどのRDBMSに取り込む。
- リアルタイムアラート: CloudWatchアラーム、EventBridgeイベント、アプリケーション内のカスタムアラート。これらはSNS/SQSを経由してイベント駆動でトリガー。
ベクトル化の際はメタデータをタグづけするのが重要とのことでした。
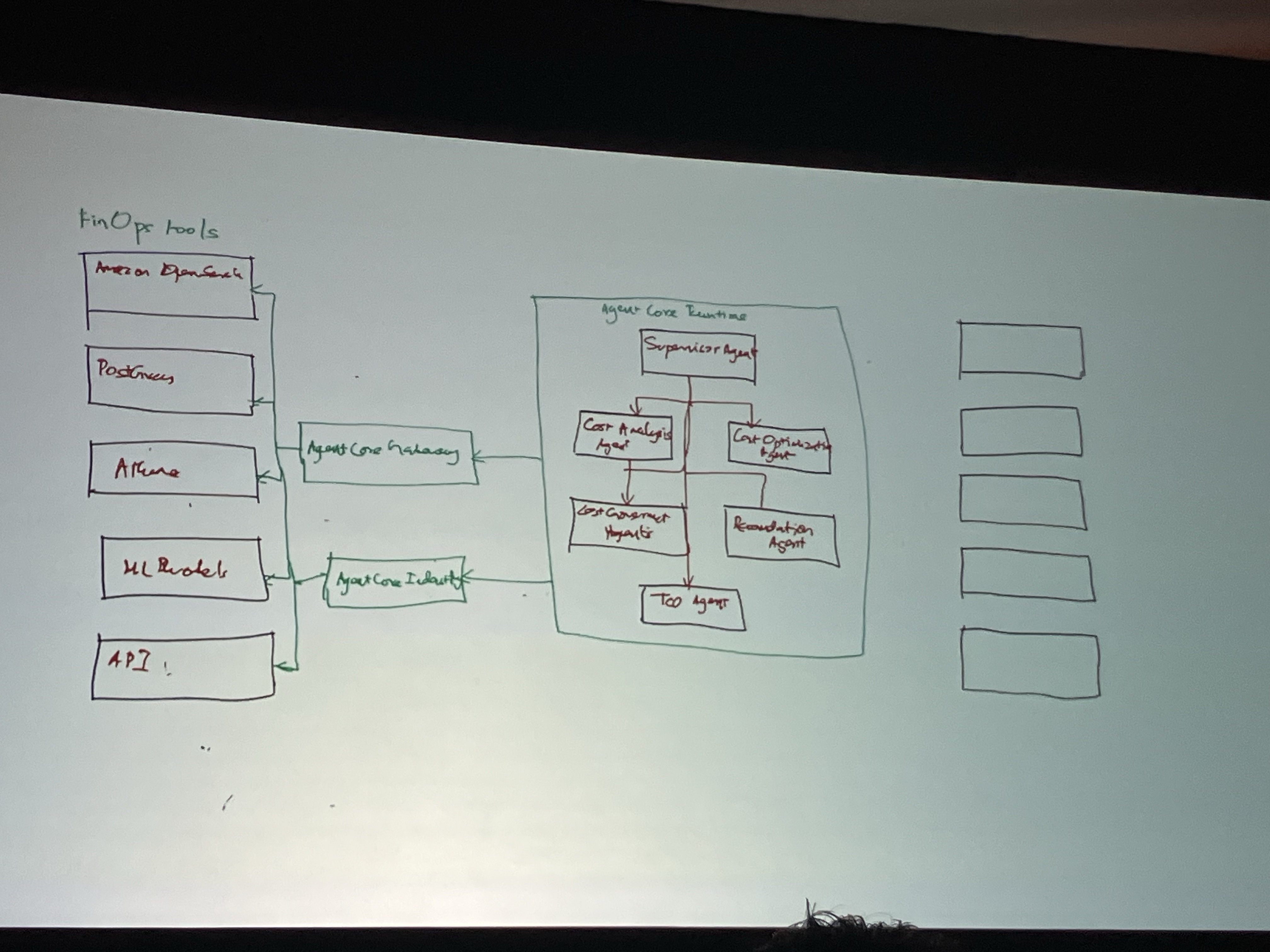
次に、ホワイトボードで、FinOps でどのようなマルチエージェントシステムを構築したら良いかの解説がありました。
これは、ホワイトボードでやる必要あるのか?と思ったのですが、一通り描き終わったらスライドに綺麗にまとめたもの↓が出てきて、かなりウケてました。
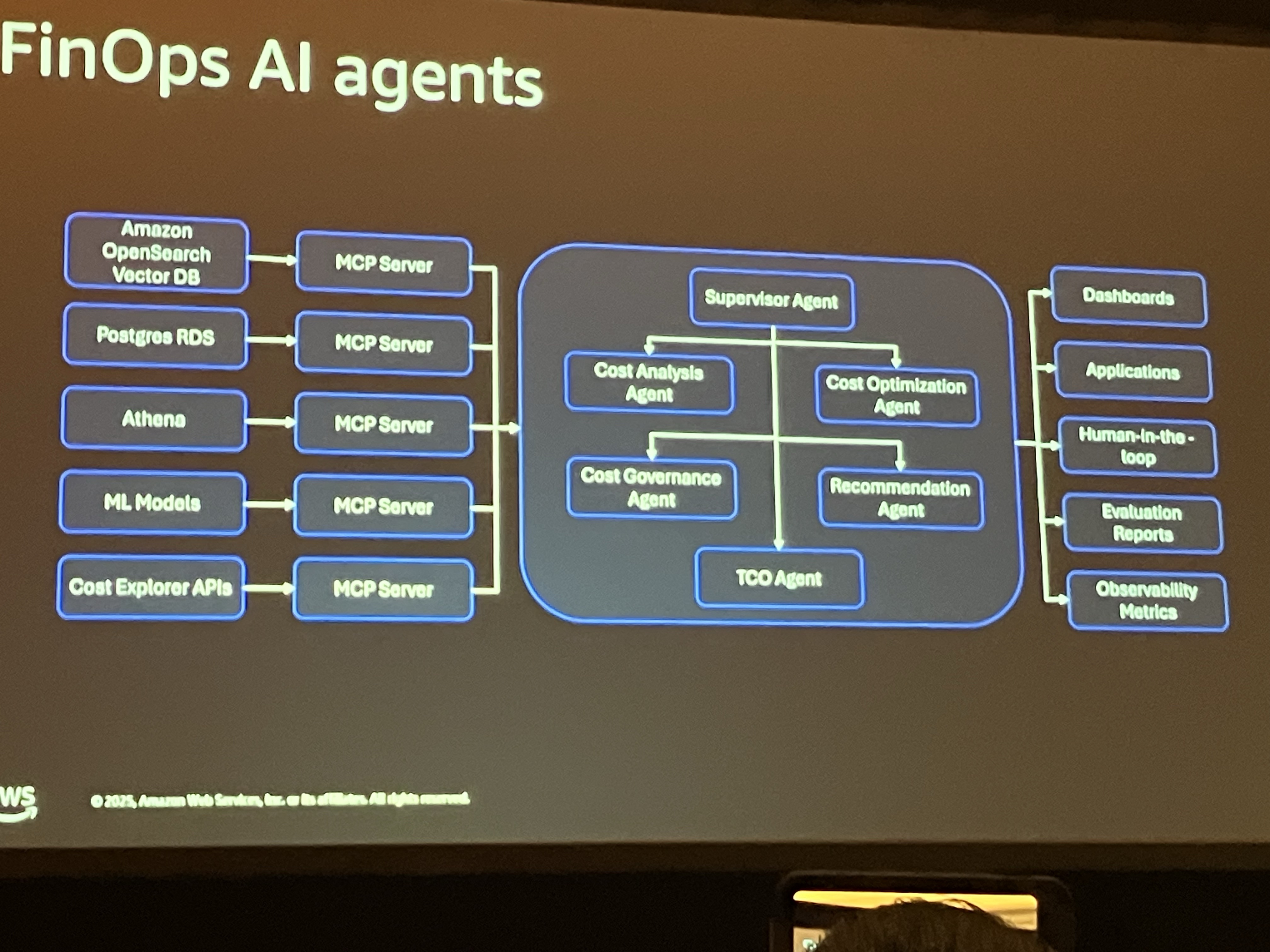
- スーパーバイザーエージェント: オーケストレーターとして機能。エンドユーザーからの質問を受け取り、適切な専門エージェントにタスクを振り分け、結果を統合して返す。
- コスト分析エージェント: データベースサービスやEC2などのサービス別の支出を分析。異常を検知し、コスト増加の根本原因を特定。
- コスト最適化エージェント: 価格ティアの変更、インスタンスタイプの最適化、トークン消費の最適化など、コスト削減の推奨事項を提供。
- コストガバナンスエージェント: ポリシーや予算要件を監視。「チームの予算が50kドルだが、週の初めで50%に達しており、数週間後に閾値を超える可能性がある」といったアラートを出す。
- TCO/推奨エージェント: MLモデルを呼び出し、フォアキャスティングや最適化の推奨を提供。
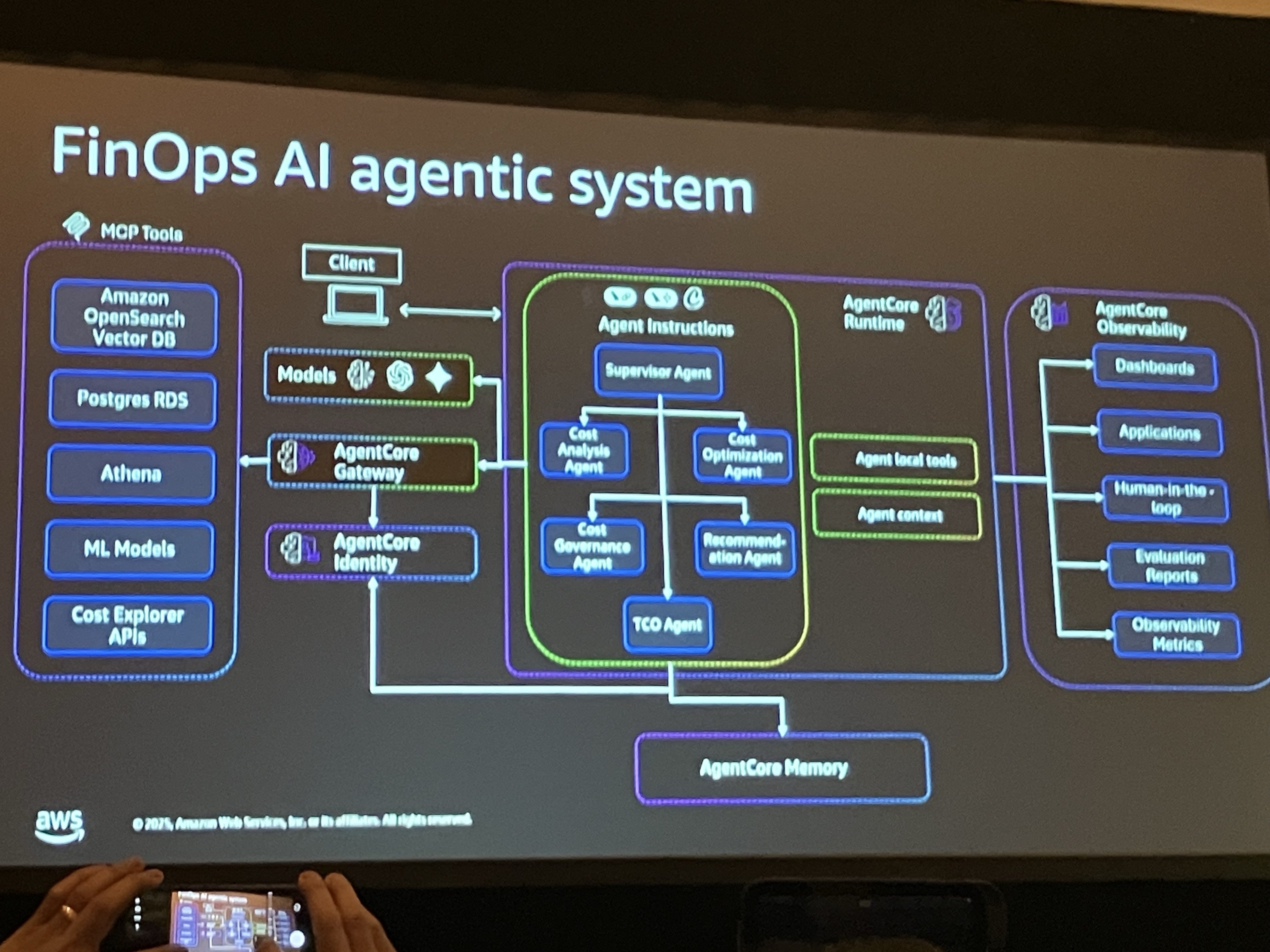
AgentCore で実装するとこのようなアーキテクチャになります。

FinOps のベストプラクティス
- エージェントの性能は消費するデータによって決まるため、クリーンでリアルタイムのデータ(AWS CUR,Cost Explorer API,CloudWatch logs)を用意する。
- エージェントができることできないことを明確にする。それに基づいて承認ワークフロー、ポリシーを作成する。
- 全てを自動化しようとしない。「ゾンビリソースの排除」「リザーブドインスタンスの最適化」などから始める。
- エージェントによる運用ができる組織に変革することが必要。
- エージェントには最小権限の原則を守ってアクセスを適用する。

AgentCore のベストプラクティス
- セッション分離を活用して、複数チーム環境におけるテナント間のデータ漏えいを防ぎ、長時間実行されるコスト分析には非同期ワークロードを使用し、リアルタイムアラートには同期実行を予約する。
- 各エージェントに最小権限を持つワークロードIDを割り当て、内部クラウドアクセスにはIAMを使用し、サードパーティ統合にはOAuthを使用し、委任認証を有効にしてエージェントが適切なトークンを使用してユーザーに変わって行動できるようにする。
- OpenTelemetryログを有効にして全てのエージェントの決定を追跡し、CloudWatch を使用してFinOpsスタック全体を集中監視する。
- セマンティック検索を活用して、関連するかこのコストパターンと以前の推奨事項を明らかにし、マルチAGメモリ共有を有効にしてコスト分析からの洞察を最適化エージェントにフィードする。
- FinOpsエコシステム全体で標準化されたツールアクセスにMCPプロトコルを使用し、柔軟性と異色性を実現するためにツールをビジネスロジックから分離し、エージェントが利用可能なリソースを発見できるように検索可能なツールレジストリを維持する。
まとめ
AgentCore で マルチエージェントシステムを構築することで、FinOps の課題が解決できるようです。その上で何より重要なのが、データの質とのことでした!!
個人的には、組織の変革も必要という部分が印象に残りました!!
最後に質問タイムがあったのですが、8割ぐらいすぐ立ち上がって帰っており、文化の違いを感じました。
