
こんにちは、アジャイル事業部のみちのすけです。AWS re:Invent 2025 に現地参加しています!
この記事は「Optimize for AWS with intelligent automation (AIM235-S)」のセッションレポートです。
IBM の Turbonomic チームが、Agentic AI のリソース最適化とコスト削減について紹介しました。
概要
セッションでは、Agentic AI や AI アプリケーションがもたらす予測不能なリソース需要の課題と、それを解決するインテリジェントな自動化の手法が語られました。特に印象的だったのは、GPU インスタンスを自動で適切なサイズに調整することで月額 $13,800 のコスト削減を実現した事例、そして IBM 内部チームが GPU のヘッドルームを 3 から 16 に拡大し、13 個の GPU を他のワークロードに再配分できた実績です。
こんな方におすすめ
- Agentic AI や AI アプリケーションを本番環境で運用している、または運用を検討している方
- GPU インスタンスのコスト最適化に課題を感じている方
- AWS 環境でのリソース自動最適化に興味がある方
- FinOps や可観測性ツールだけでは解決できない課題に直面している方
登壇者
- Chris Zaloumis さん(IBM, Director of Product Management)
Agentic AI がもたらす隠れたコスト
Chris さんはまず、Agentic AI の採用状況について会場にアンケートを取られました。

- 探索中(学習段階): 数名
- PoC 実施中: かなりの数
- 早期プロダクション: 数名
- ビジネスクリティカル: ほぼゼロ
ビジネスクリティカルなレベルまで到達している組織はまだほとんどないという結果でした。これは IBM の顧客でも同様の傾向だそうです。
オーバープロビジョニングとリソースの無駄
Agentic AI や AI アプリケーションの大きな課題は、リソースの使用が予測不能であることです。従来のアプリケーションは線形にリソースを消費しますが、Agentic AI は異なります。
Chris さんの説明によると、Agentic AI は以下のような特徴があるとのことです。
- 計画を立て、分岐し、数百のマイクロワークロードを生成する
- Agentic AI が別の Agentic AI と通信したり、複数の API を呼び出したりする
- 1 つのユーザーリクエストが数百の下流タスクを生成することがある
この予測不能な動作により、多くの組織はパフォーマンス低下を恐れてリソースを過剰にプロビジョニングするという選択をしてしまいます。

具体的には、
- GPU インスタンスの過剰なサイジング
- RAM ファームの過剰割り当て
- ストレージの過剰プロビジョニング
これにより、高額なリソースがアイドル状態のまま放置されるという事態が発生しています。
Chris さんが示した事例では、以下のような状況があったとのことです。
- GPU 使用率が 30% しかない
- 必要量の 10〜20 倍の GPU 時間を確保している
こうした組織では、パフォーマンスリスクを恐れるあまり、リソースがアイドル状態で放置され、隠れたコストとして組織に負担をかけています。
正直、この問題は実感できますね。Agentic AI のような予測不能なワークロードに対して、「とりあえず大きめに確保しておく」という判断は理解できますが、コスト面では大きな課題になると思います。

静的なスケーリングポリシーの限界
多くのチームは静的なスケーリングポリシーを設定していますが、これにも問題があると Chris さんは指摘しました。
- リアクティブ(事後対応型): ピークが発生してからスケールするため、すでに手遅れ
- 人的介入が必要: スケーリングポリシーの継続的な監視と調整が必要
Agentic AI のような予測不能なワークロードでは、静的なポリシーでは対応しきれないということですね。
洞察とアクションの間のギャップ
Chris さんは、既存の可観測性ツールや FinOps ツールの限界についても言及されました。

可観測性ツールの課題
可観測性ツールは以下のような情報を提供してくれます。
- CPU スロットリングが発生しているか?
- GPU の競合が起きているか?
- レイテンシーのスパイクはあるか?
しかし、これらのツールは「何が起きているか」は教えてくれますが、「それに対して何をすべきか」は教えてくれません。RCA(根本原因分析)を事後に行うことはできますが、リアルタイムでのアクションは取れません。
FinOps ツールの課題
FinOps ツールは以下のような機能を提供します。
- コスト支出の可視化
- レポート作成
- ショーバック/チャージバック
しかし、FinOps ツールは主にレポーティングに焦点を当てており、GPU のリサイジングや動的なシナリオへの対応はできません。コスト配分は得意ですが、問題の解決には至らないということですね。
結果として、多くの組織では、
- パフォーマンスと SLO 維持のためにオーバーサイジングがデフォルトになる
- 静的なスケーリングに頼らざるを得ない
この課題は、正直なところ多くの組織で共通していると思います。可観測性と FinOps だけでは、動的なリソース最適化までは実現できないんですね。
Turbonomic によるリアルタイム最適化
Chris さんは、IBM の Turbonomic がこれらの課題をどのように解決するかを説明されました。

Turbonomic の仕組み
Turbonomic は以下のようなアプローチでリアルタイム最適化を実現しています。
- 継続的な分析: GPU インスタンス、vCPU、vMEM の飽和度、ストレージとネットワークのスループットを時系列で分析
- 環境全体のサプライチェーン分析: Agentic AI アプリケーションだけでなく、それをサポートするリソース全体を見る
- リアルタイムなスケールアップ/ダウン: 需要に応じて動的にリソースを調整
- EC2、GPU、EKS、ハイブリッド環境に対応: AWS だけでなく、オンプレミスや他のクラウドにも対応
重要なのは、パフォーマンスを維持しながら SLO を満たし、コストを効率的に管理するという点です。
GPU 最適化の具体例
Chris さんは、実際の Turbonomic の画面を見せながら、具体的な最適化アクションを説明されました。
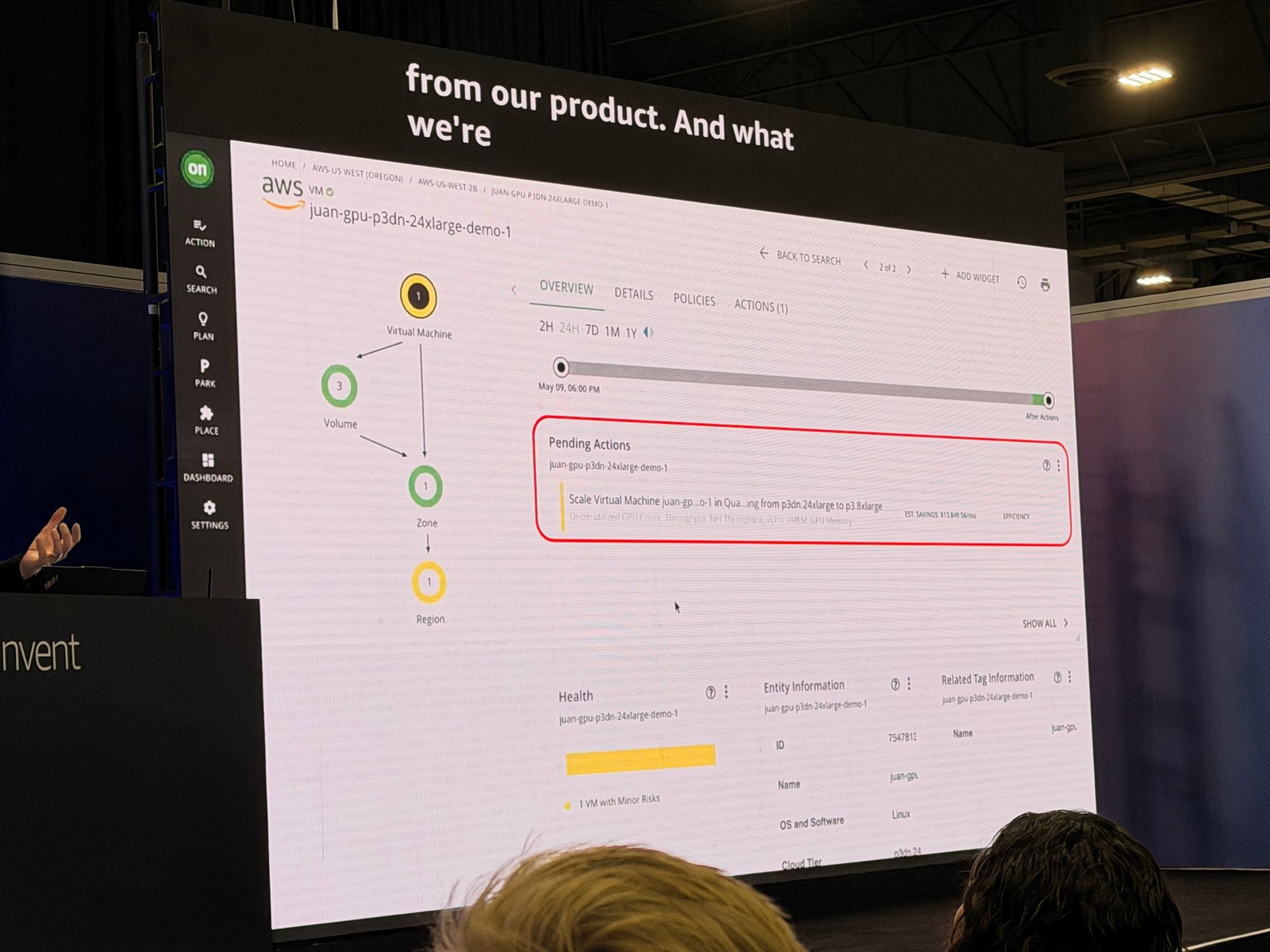
事例: P3DN.24xlarge GPU インスタンスの最適化
- 現在のインスタンス: P3DN.24xlarge(高額な GPU インスタンス)
- 推奨アクション: P3.8xlarge にスケールダウン
- 月額コスト削減: $13,800
この推奨は、GPU 使用率、GPU メモリ、インスタンスサイジング、全体の使用率を分析した結果です。
詳細な分析データ
- GPU カウント使用率: 約13%(8個の GPU のうち、ほとんど使われていない)
- GPU メモリ使用率: 約22%
- vCPU 使用率: 3〜4%
この状況から、Turbonomic は以下のような推奨を行っています。
- GPU カウント: 8 → 4 に削減
- 予測される GPU 使用率: 13% → 26%(安全な範囲内)
- GPU メモリ: 32GB → 16GB
- 予測されるメモリ使用率: 22% → 44%(安全な範囲内)
- vCPU: 13% 程度に上昇(安全な範囲内)
コスト削減の詳細
- オンデマンド料金: $31.21/時間 → $12/時間
- RI(リザーブドインスタンス)や Savings Plans も考慮
- 月額削減額: 約 $13,800
これはたった1つの GPU インスタンスからの削減額なので、複数のインスタンスがあればさらに大きな節約になるということですね。
Chris さんは、オペレーターがこのアクションを信頼できるように、詳細なメトリクスを提供している点を強調されました。パフォーマンスが維持されることを確認できるので、自信を持ってアクションを実行できるとのことです。
この取り組みは、コスト削減とパフォーマンス維持のバランスが素晴らしいと思います。特に、オペレーターが判断できるように詳細なデータを提供している点が実用的ですね。
Turbonomic の主要機能
Chris さんは、Turbonomic が提供する主要な機能についても説明されました。

スマート GPU 最適化
- GPU を自動的にチューニング
- 需要が増加するとリアルタイムでリソースを追加
- 需要が減少すると効率化のためにリソースを削減
- アイドル容量を排除
リアルタイム可視性
- すべてのリソースをリアルタイムで監視
- ビジネスアプリから物理リソースまでのサプライチェーンをマッピング
- EC2、EKS、GPU 環境など、さまざまなリソース間のメトリクスを相関分析
- 潜在的な問題やボトルネックを特定し、プロアクティブに対処
オーケストレーション統合
- Pod の配置、アフィニティ、リソースクォータ、スケジューリングを理解
- コンテナインフラと従来のインフラレイヤーを一緒に最適化
プロアクティブな自動化
- 単一のアクションだけでなく、完全な自動化が可能
- 人的介入なしで最適化を実行
- 潜在的な問題を特定し、インシデントが発生する前に対処
- 事後の RCA や問題解決が不要
ROI の可視化
- 個別のアクションの効果を集計
- すべての自動化による全体的な ROI を提示
- ビジネス価値を明確に示す
この機能セットは、FinOps と可観測性のギャップを埋めるものだと感じました。特に、プロアクティブな自動化により、問題が発生する前に対処できる点が素晴らしいですね。
IBM 内部での実績: BAM チーム
Chris さんは、IBM 内部の Big AI Models チーム(BAM)の事例も紹介されました。

BAM チームは watsonx の背後にある LLM をサポートしているチームで、以下のような課題を抱えていたとのことです。
- 環境を管理するための手動チューニングを減らしたい
- 数百のコンテナと約 100 個の NVIDIA A100 GPU を Kubernetes で運用
- GPU の密度を高めて ROI を向上させたい
Turbonomic 導入後の成果
Turbonomic を導入した結果、以下のような成果が得られたとのことです。
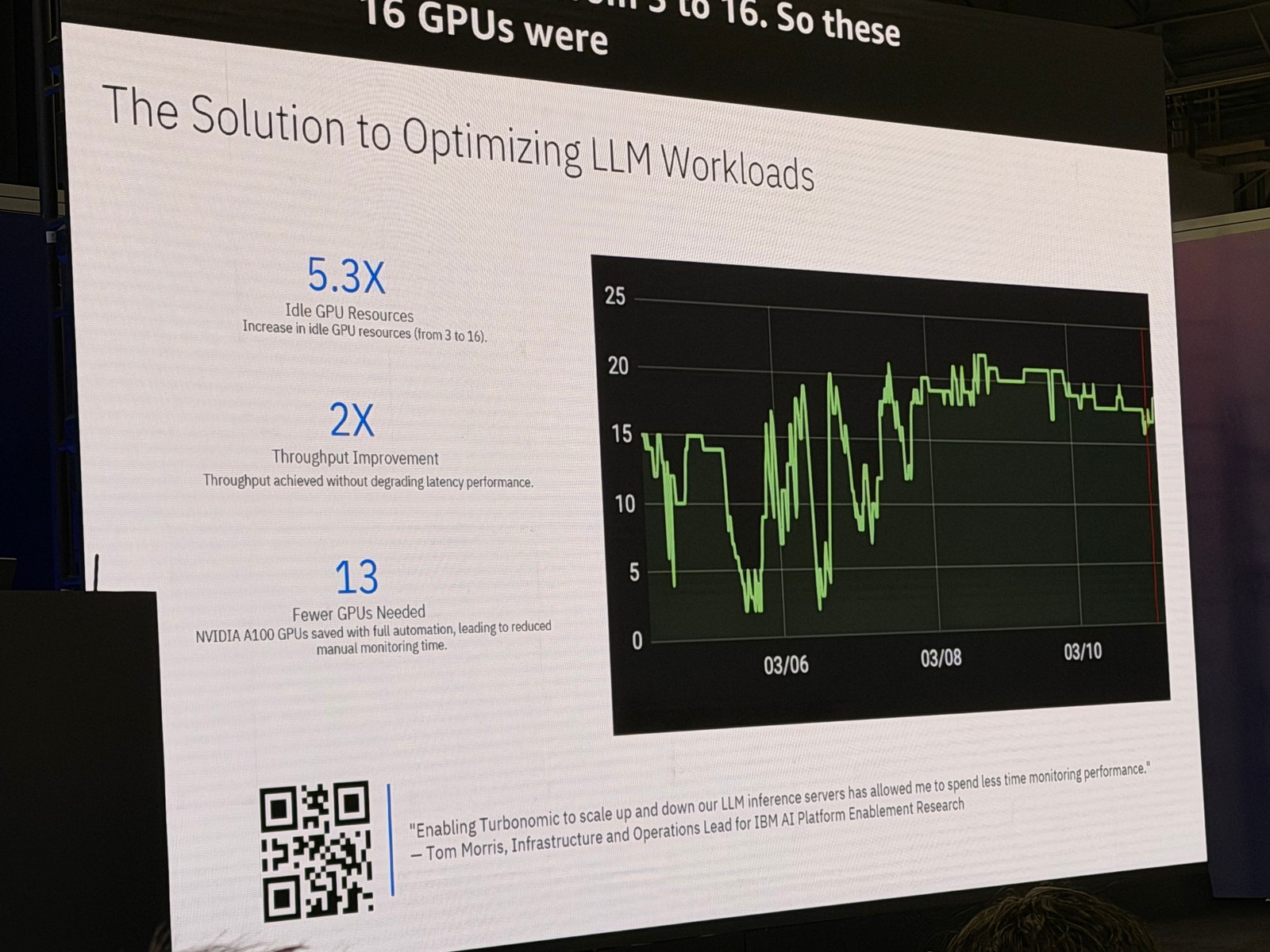
- アイドル GPU リソースが5.3倍削減: ヘッドルームが3から16に拡大
- スループットが2倍向上: レイテンシーに影響なし
- 13個の GPU を削減: これらの GPU を他のワークロードに再配分
13個もの GPU を他のワークロードに割り当てられたというのは、大きな成果ですね。既存の GPU をより密に活用することで、新しい AI ワークロードにリソースを割り当てられるようになりました。
この事例は、コスト削減だけでなくリソースの有効活用という観点でも素晴らしいと思います。
まとめ: 覚えておくべき3つのこと
Chris さんは、セッションの最後に3つの重要なポイントを強調されました。

1. Agentic AI は予測不能でリソース集約的
- 線形にスケールしない: 従来のアプリケーションとは異なる動作
- バースト性が高く予測不能: リソース需要が急激に変化する
- 成熟度曲線を意識する: Agentic AI プロジェクトを進める際は、この特性を考慮する必要がある
2. 可視性だけでは不十分
- 可視性だけでは手動作業が増える: 問題を見つけても、対処には手動作業が必要
- 洞察を継続的なアクションに変換する: リアルタイムでリソースを適正化し、アプリケーションに必要なリソースを確保するソリューションが重要
3. 高価値なワークロードから始める
- 1つの高価値ワークロードをターゲットにする: パフォーマンスを維持しながら GPU を効率化できることを証明
- それをスケールアウトする: 成果を確認してから展開を広げる
小さく始めて検証してから広げる、というアプローチは当たり前のようで、実際にやるのは難しいですよね。でも、この慎重なステップが成功の鍵になると思います。
全体を通しての所感
Agentic AI のリソース最適化という、まさに今ホットな課題に対して、具体的なソリューションと実績を示していたセッションでした。
特に印象的だったのは、可観測性と FinOps のギャップを埋めるという明確なポジショニングです。多くの組織が「何が起きているかは分かるが、何をすべきか分からない」という状況に陥っている中で、Turbonomic はそのギャップを埋めるソリューションとして位置づけられていました。
また、$13,800/月のコスト削減や、13個の GPU の再配分といった具体的な数字が示されていた点も説得力がありました。単なる理論ではなく、実際に成果が出ているという点が重要だと感じました。
Agentic AI や AI アプリケーションの本番運用を検討している方、特に GPU コストに課題を感じている方には、非常に参考になる内容だったと思います。


