
AWS re:Invent 2025で開催されたワークショップ「Build an S3 time machine: Implementing advanced point-in-time recovery」に参加しました。

概要
本セッションのテーマは、Amazon S3における高度なポイントインタイムリカバリ(PITR)の実装です。ランサムウェア攻撃やアカウント侵害といったセキュリティ脅威が増加する中、単なるバックアップ取得だけでなく、特定の日時の状態へデータを正確かつ迅速に復元する能力が求められています。
このワークショップでは、S3レプリケーション、S3 Metadata、S3 Tables、S3 Batch Operationsといったマネージドサービスを組み合わせることで、過去の任意の時点のデータを特定し、復元する”S3タイムマシン”を構築しました。
アーキテクチャの概要
今回のワークショップでは、本番環境(us-east-1)とバックアップ環境(us-west-2)という2つの異なるリージョンを使用します。

本番環境のS3バケット上のデータがランサムウェア攻撃や誤操作によって損なわれた際に、バックアップ環境にあるデータを用いて、特定の時点の状態へ迅速に復旧させることを目的としています。
S3タイムマシンの基盤構築
S3タイムマシンを実現するためには、データの複製と状態管理が必要です。まず以下の主要な機能を設定しました。
- S3バージョニングの有効化
最初の手順として、本番用バケットとバックアップ用バケットの両方でS3バージョニングを有効化します。バージョニングは、意図しない削除や上書きからデータを保護するための基本機能であり、同じバケット内にオブジェクトの複数のバージョンを保持することを可能にします。 -
S3レプリケーション(CRR)の設定
次に、本番バケットからバックアップバケットへのデータ転送を自動化するために、S3レプリケーション(クロスリージョンレプリケーション)を設定します。設定における重要なポイントは以下の通りです。
Replication Time Control (RTC)
レプリケーションの遅延を最小限に抑えるため、RTCを有効にします。これにより、新しいオブジェクトの99.99%が15分以内に複製されることが保証され、SLAに基づいた運用が可能になります。
ソースバケットで削除操作が行われたことをバックアップ側にも反映させるため、削除マーカーのレプリケーションを有効化しました。
S3 MetadataとS3 Tablesの導入
従来のS3インベントリ等に代わる高度なメタデータ管理手法として、バックアップバケットに対してS3 Metadataの構成を行いました。
S3 Metadataは、S3バケット内のオブジェクトに関するメタデータを自動的に収集し、フルマネージドなApache Icebergテーブル(S3 Tables)に保存する機能です。これにより、以下の2種類のテーブルが作成されます。
- ジャーナルテーブル
- バケット内で発生したイベント(アップロード、削除など)をほぼリアルタイムで記録します。今回の設定ではレコードの有効期限を7日間に設定
- ライブインベントリテーブル
- バケット内の全オブジェクトとそのバージョンの最新状態を一覧化
Lake FormationとKiro CLIによるデータアクセス権限の管理
作成されたメタデータテーブル(S3 Tables)へのアクセス制御には、AWS Lake Formationを使用しました。復旧作業を行うEC2インスタンスに対し、メタデータテーブルの参照権限(SelectおよびDescribe)を付与することで、セキュアなアクセスを確立しました。
また、本ワークショップの特徴的な点として、AI搭載ターミナルツール「Kiro CLI」と「AWS S3 Tables MCP Server」の設定を行いました。これにより、自然言語を用いてS3メタデータを直感的にクエリができます。
S3メタデータの分析と活用
S3 Metadataによって蓄積されたデータは、緊急時に「いつ、何が起きたのか」を特定するために使用されます。本モジュールでは、2つのアプローチで分析を行いました。
SQLによる分析
Amazon Athenaを使用し、標準的なSQLクエリを実行して、特定の操作やオブジェクトの履歴を特定しました。
自然言語による分析
Kiro CLIとMCPを活用し、「最近の削除操作を表示して」「特定のアクティビティが多いIPアドレスを教えて」といった自然言語での指示により、SQLを記述することなく必要な情報を取得できることを確認しました。緊急時のオペレーションにおいて、この対話型分析は作業効率を大きく向上させる可能性があります。
ランサムウェア攻撃のシミュレーション
リカバリ体制が整ったところで、実際の脅威を模した攻撃シミュレーションを実施しました。

シナリオは、フィッシングメールに含まれる悪意あるURLをクリックしたことでスクリプトが実行され、S3バケット内の画像データが暗号化されるというものです。デモアプリケーション上では、正常な画像がビットコインの画像に置き換わり、身代金を要求する警告が表示される様子が確認できました。
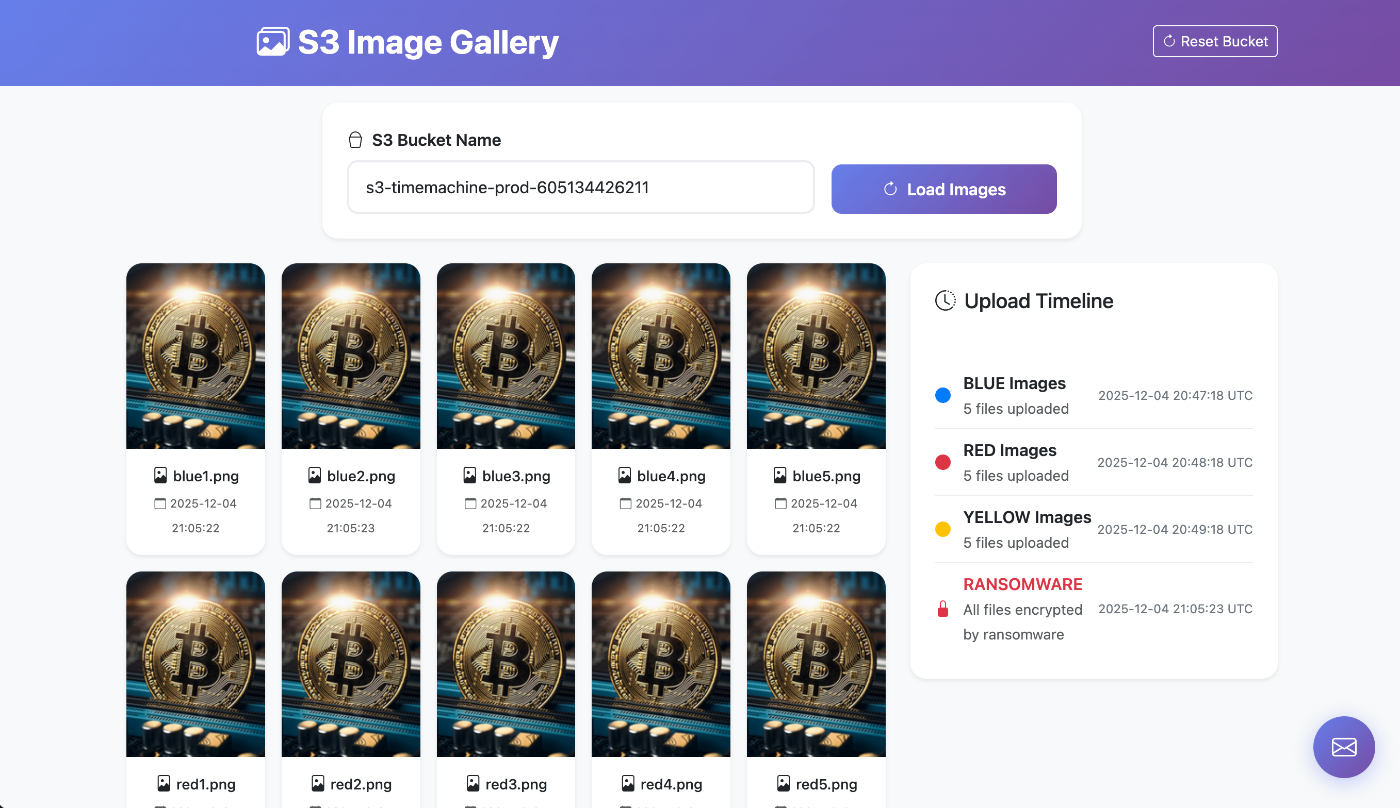
この際、S3上ではオブジェクトが上書き保存されていますが、事前に設定したバージョニング機能により、バックアップバケットには暗号化前の「古いバージョン」のデータが残存しています。
ポイントインタイムリカバリ(PITR)の実行
最終工程として、S3タイムマシンソリューションを用いたデータ復旧を行いました。今回の目標は、画像が暗号化される前、具体的には「青色の背景画像のみが存在していた時点」にバケットの状態を戻すことです。

- 復旧ポイントの特定
まず、Amazon Athenaを使用してメタデータ(ジャーナルテーブル)を分析し、ランサムウェア攻撃が発生した正確な時刻を特定しました。今回は、攻撃前の安全な時点として「2025-11-23 23:54:02」というタイムスタンプを特定し、その時点までに作成され、かつ削除されていないオブジェクトのリストを抽出するクエリを実行しました。
2.マニフェストファイルの作成
Athenaのクエリ結果(CSV)をダウンロードし、ヘッダー行を削除してマニフェストファイル(new_manifest.csv)を作成しました。このファイルには、復元すべきオブジェクトのバケット名、キー、そして特定のバージョンIDが含まれています。
3.S3 Batch Operationsによる復元
データの復元には、Amazon S3 Batch Operationsを使用しました。これは数十億のオブジェクトを一括処理できるマネージドサービスです。
作成したマニフェストファイルをソースとして、バックアップバケットに残っている「暗号化前のバージョン」のオブジェクトを、新しいリストア用バケットにコピーするジョブを作成・実行しました。
結果の確認
ジョブ完了後、リストア用バケットに接続された画像ビューアーを確認したところ、暗号化された画像は排除され、意図した通りの正常な画像データのみが復元されていることが確認できました。
まとめ
本ワークショップを通じて、S3 MetadataとS3 Tablesを活用することで、バケット内の操作履歴を詳細かつ高速に追跡できることを学びました。これらを従来のS3バージョニングやレプリケーションと組み合わせ、さらにS3 Batch Operationsで自動化することで、ランサムウェア攻撃のような深刻なインシデントからも、確実かつ迅速にデータを復旧させる仕組みが実現できそうです。
