
クラウドインテグレーション事業部の石川優です!
このセッションでは、実際のアーキテクチャ失敗事例を3つ取り上げ、それぞれから学べる教訓と予防策について解説されました!!
セッション概要
Some of the best lessons come from failures – but it’s better to learn from someone else’s. In this session we will dissect three real-world AWS architecture failures, exploring what went wrong, the business impact, and how they were fixed. You’ll learn the patterns and anti-patterns behind each case, and walk away with actionable insights to avoid similar pitfalls in your own mission-critical workloads.
最高の教訓は失敗から得られるものですが、他人の失敗から学ぶのが賢明です。本セッションでは、実在する3つのAWSアーキテクチャ障害事例を分析し、問題点、ビジネスへの影響、および修復方法を検証します。各事例に潜むパターンとアンチパターンを学び、ミッションクリティカルなワークロードで同様の落とし穴を回避するための実践的知見を得られます。
キーメッセージ:
“Every architecture looks perfect — until it meets reality”

すべてのアーキテクチャは現実に直面するまでは完璧に見えるという前提のもと、実際の失敗から学ぶことの重要性が強調されました。
Failure Lesson 1: Resilience(レジリエンス)
事例: E-commerce 3-tier web app

アーキテクチャの概要:
- E-commerce fulfillment company
- 2つのモバイルクライアント
- 平均3k/日のトラフィック
- 基本的な3層アプリケーション(Load balancer, web layer/app layer, database)
理想のアーキテクチャ(The perfect 3-tier app)
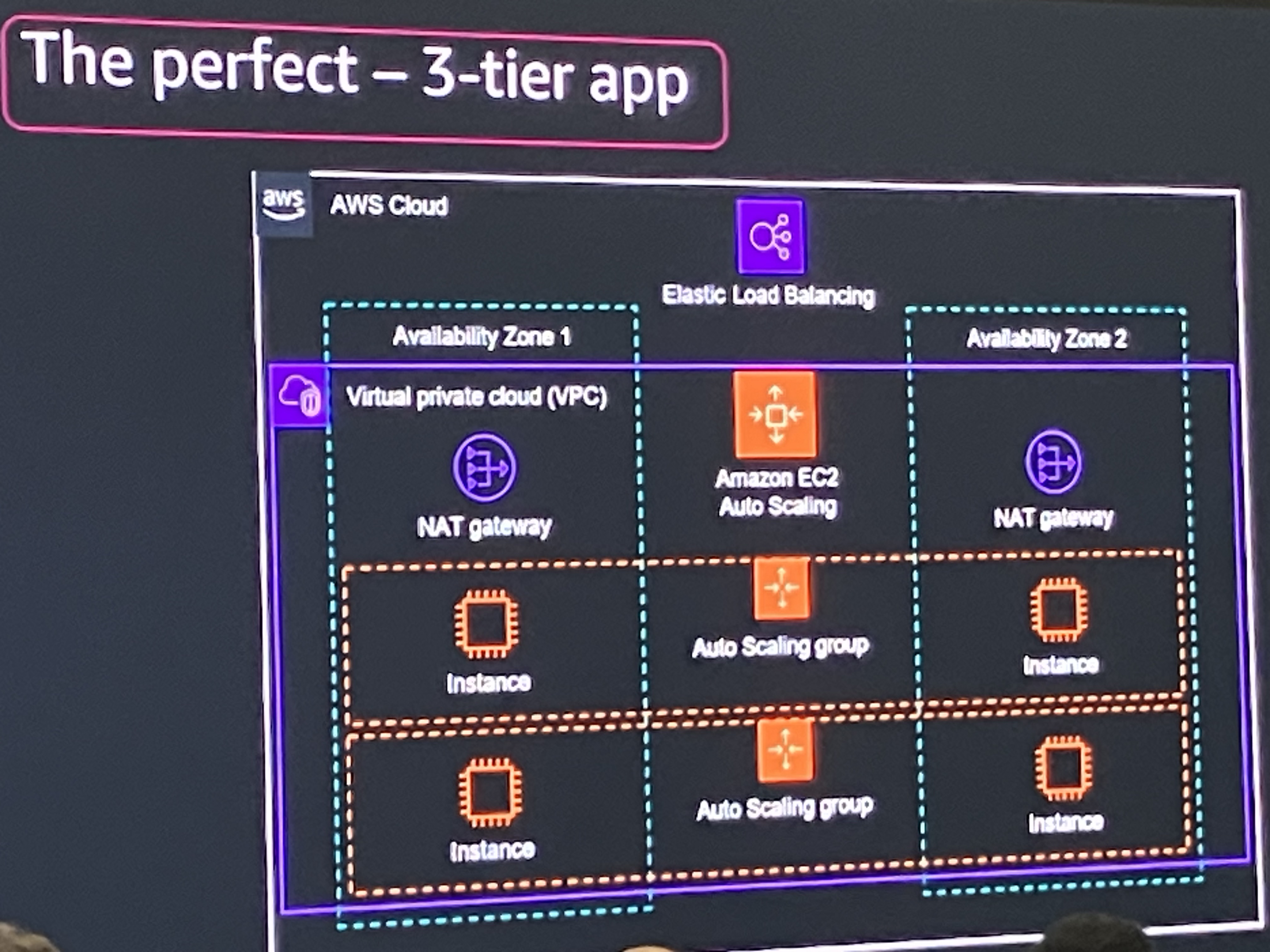
- Elastic Load Balancing
- 2つのAvailability Zoneに分散
- VPC内にNAT gateway
- EC2 Auto Scalingグループ
- マルチAZ構成
現実のアーキテクチャ(The reality 3-tier app)
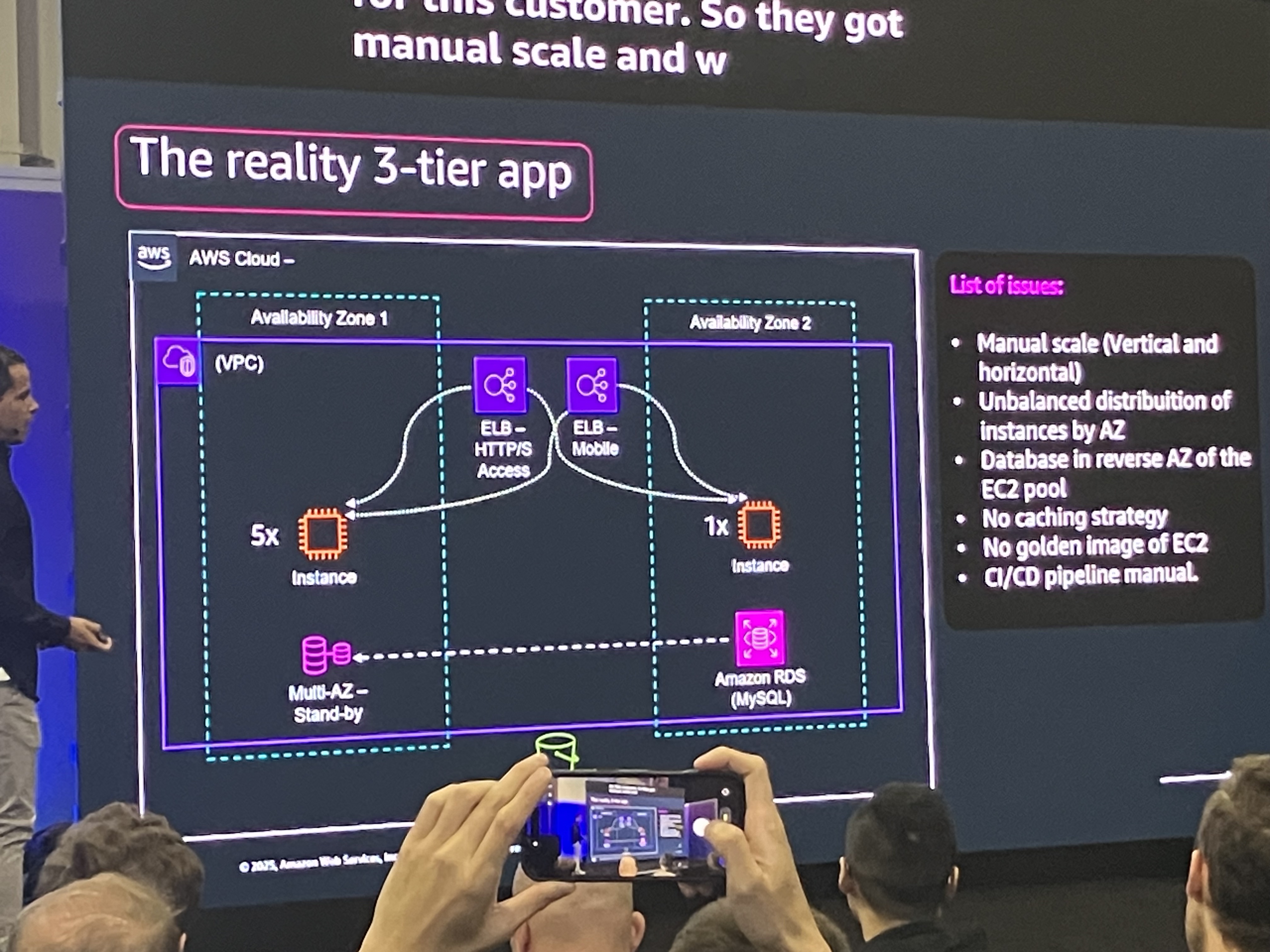
問題点:
- Manual scale(垂直・水平スケーリングが手動)
- AZ間でインスタンスの配置が不均衡(AZ1に5インスタンス、AZ2に1インスタンス)
- データベースがEC2プールとは逆のAZに配置
- キャッシング戦略なし
- EC2のGolden Imageなし
- CI/CDパイプラインが手動
改善策(Modifications)
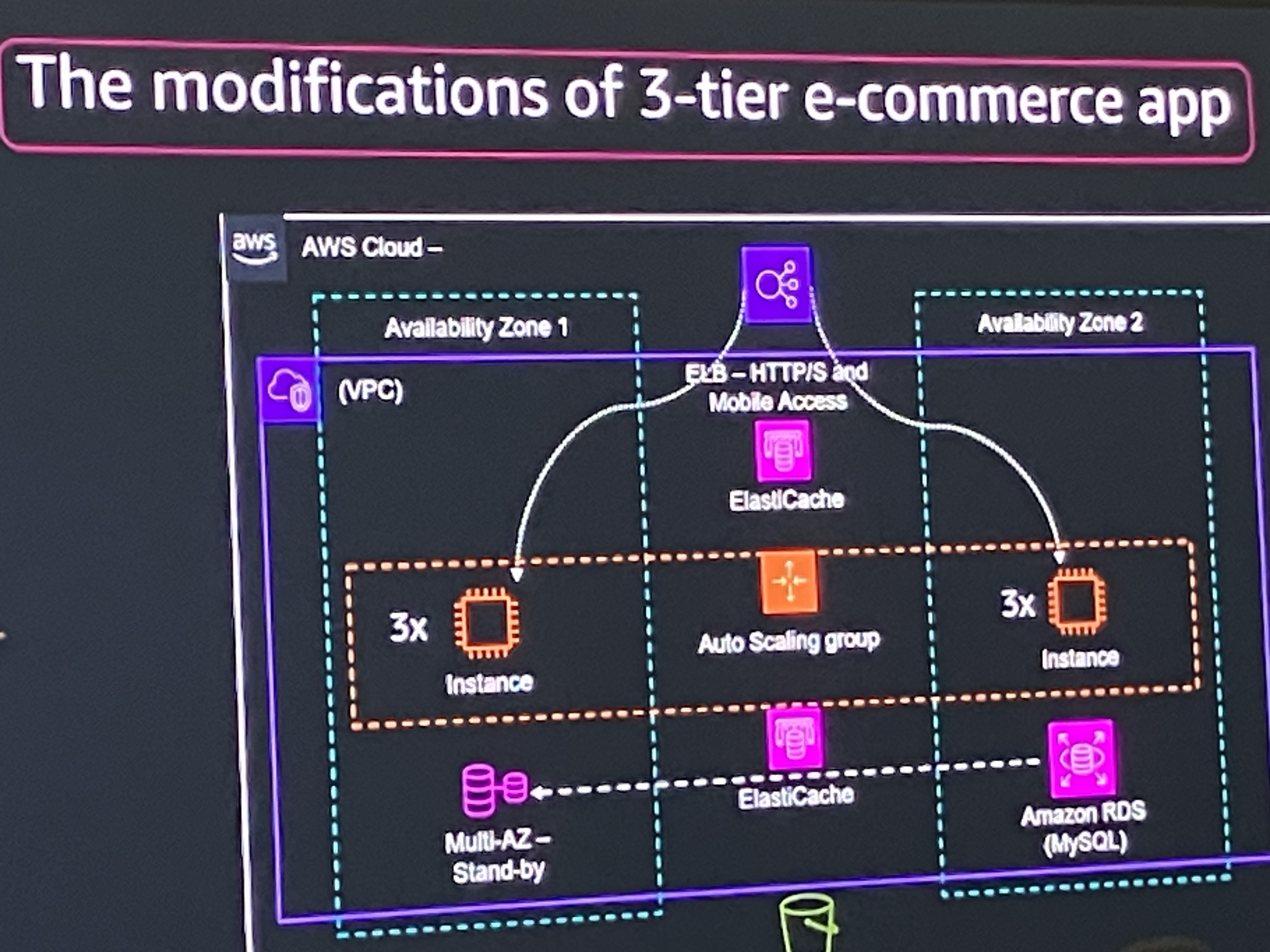
実施した改善:
- Golden ImageとEC2 Auto Scalingのブートストラップ自動化
- AZ間でWebアプリのバランス調整
- ロードバランサーの統合
- データベース層とWeb層のキャッシュ導入(ElastiCache)

改善後、マーケティングキャンペーンやブラックフライデーにも対応可能なプラットフォームになりました。
教訓

“Availability is an architectural decision, not a checkbox. Do your trade offs!”
可用性はチェックボックスではなく、アーキテクチャ上の意思決定である。トレードオフを考慮すべき。
事例2:大手銀行のEKS更新遅延による障害

アーキテクチャの概要:
- エンタープライズ銀行
- 銀行の主要な顧客サービスプラットフォームという、極めてクリティカルなワークロード
- Amazon EKS(Kubernetes)クラスターを使用。
- AWS Security Hubを有効化し、セキュリティのベストプラクティス(CISなど)を監視。
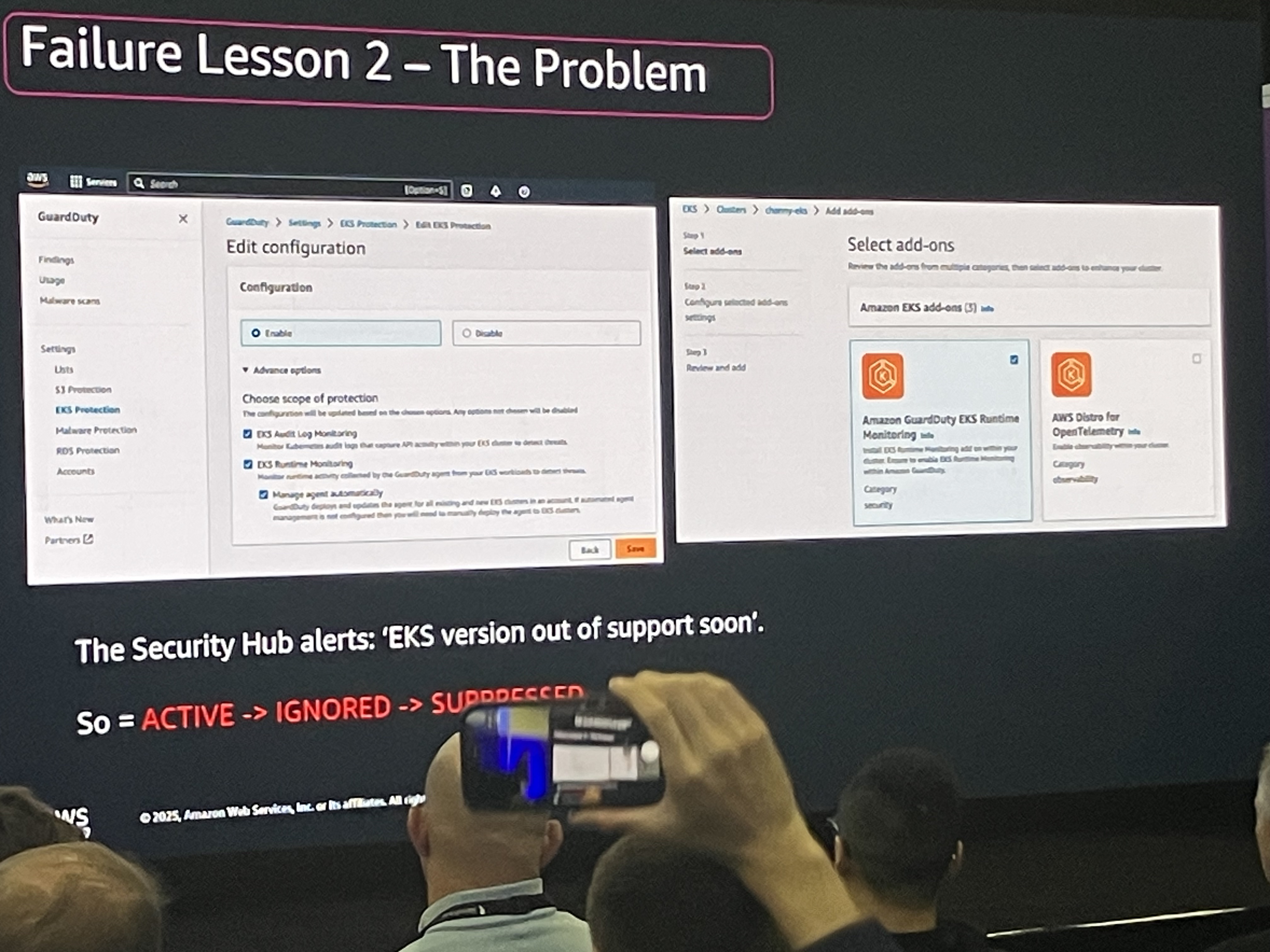
問題の発生プロセス
警告: Security Hubから「EKSのバージョンがまもなくサポート切れになる」というアラートが出ていました。
チームはこのアラートを「Active(検知)」→「Ignored(無視)」→「Suppressed(抑制/非表示)」というフローで処理しました。

破綻の瞬間
そしてサポート終了期限が到来しました。
セキュリティチームがコンプライアンス遵守のため、アプリケーションの互換性検証を行わないままEKSのアップデートを強行しました。
EKSの仕様上(ライフサイクルポリシー)、一度アップグレードしたクラスターのバージョンをダウングレード(ロールバック)することはできませんでした。

根本原因: “The problem wasn’t the update, it was the delay.”(問題はアップデートそのものではなく、それを遅らせたことにある)。

どうすれば回避できたか?
A. EKSバージョン検証パイプラインの構築
手動ではなく、自動化されたパイプラインで安全性を担保します。
- Preview環境: 本番相当(ステージング)のミラー環境を用意する。
- ツール活用: kube-score、conftest、pluto(APIバージョンの廃止チェック)などで自動チェックを行う。
- Dry-run: クラスターアップグレードの予行演習を行う。
- IaC: Terraformやeksctlを使用し、バージョンをコードで固定・管理する。
B. ガバナンスの強化
- Security Hubへの対応義務化: 検知事項に対する回答を必須にする。
- SLAの設定: クリティカルな検知事項に対する修正期限(SLA)を設ける。
C. アーキテクチャの工夫
- Blue/Greenアップグレード: 既存クラスターを更新するのではなく、新しいバージョンのクラスター(Green)を作って切り替える方式にする(これならロールバックが可能)。
- GitOps: クリティカルなコンポーネントをGitOpsで管理する。

被害と教訓
被害:
- 6時間のダウンタイムが発生。
- R$1.2 million(約120万レアル)の損失およびSLA違反によるペナルティが発生。
最大の教訓:
“Architectures fail when processes fail. Technology is predictable, humans are not.” (プロセスが失敗するとアーキテクチャも失敗する。テクノロジーは予測可能だが、人間はそうではない。)
事例3:開発環境の過剰スペックによるコスト浪費

アーキテクチャの概要:
- AWSへの移行を進めているエンタープライズ企業。
- マルチアカウント構成を採用し、AWS OrganizationsでDev(開発)、QA(検証)、Prod(本番)を管理。
- ワークロードの70%は「非本番環境(Non-Production)」にある状態。

問題点
企業はすべての環境を「本番環境(Production)と同じSLA(サービス品質)」として扱っていました。
開発環境にも関わらず、以下のような過剰な構成がとられていました。
- すべてオンデマンド: EC2、EKS、ECSなどを定価(オンデマンドインスタンス)で利用。
- 過剰な冗長化: 開発環境のデータベース(RDS)にMulti-AZ(マルチアベイラビリティゾーン)構成を採用。
- 垂れ流しの稼働: シャットダウンのポリシーがなく、営業時間外も24時間365日フル稼働。
- サイジング不足: リソースの適正化(Rightsizing)が行われていなかった。

コストの肥大化
開発環境が本番環境と同じコストで稼働しており、無駄な出費が積み重なっていました。
どうすれば回避できたか?(実施された改善策)
本番環境には手を触れず、非本番環境の運用を見直すだけで劇的な改善が可能でした。
- 購入オプションの変更: オンデマンドからスポットインスタンスやSavings Plansへの切り替え(推測)。
- 稼働時間の制御: 業務時間外(夜間・休日)の自動停止(Shutdown automation)。
- 冗長性の排除: 開発環境でのMulti-AZ廃止。
- リソースの適正化: インスタンスサイズの最適化(Rightsizing)。
被害と改善結果
改善による効果:
- 月間削減額: R$ 60,000(約11,000米ドル)。
- 年間削減額: R$ 720,000(約130,000米ドル)。
- インパクト: 生産環境にリスクを与えることなく、シニアエンジニア2名分の雇用コストに相当する節約を達成。
教訓

“The cloud is elastic. Costs should be too.”
(クラウドは伸縮自在である。コストもそうあるべきだ。)
まとめ

決定の欠如が失敗を招く:
技術そのものではなく、技術導入前の「意思決定の欠如」が失敗の原因となる。
アクションこそが事故を防ぐ:
警告(Warning)が出ているだけでは事故は防げない。具体的な行動(Actions)だけが事故を防ぐ。
可視化なくして最適化なし:
可視性(Visibility)がなければ、最適化ではなく「推測」しかできない。そして推測は高くつく。
おわりに
このセッションでは、以下の3つの重要な観点から実際の失敗事例を通じて学びました:
- Resilience(レジリエンス): 可用性は設計段階での意思決定が重要
- Security + Operational Excellence: ツール導入だけでなく運用プロセスが重要
- Multi-account + Cost efficiency: マルチアカウント戦略とコスト最適化
実際のアーキテクチャは理論通りにはいかないことが多く、現実に即した設計と継続的な改善が必要ですね。
