
はじめに
システム運用では、監視アラートの一次対応が継続的な負荷になりやすい領域です。既知のエラーであっても調査に時間がかかる、ログの読解に手間取る、対応不要なアラートを手動でクローズしている――このような定型作業が積み重なると、運用品質と生産性の双方に影響が出ます。
そこで私たちは、監視アラートの一次切り分けをAIで自動化する仕組みを開発しました。本稿では、LLMとRAG(検索拡張生成)を組み合わせて、社内ナレッジを活用しながら一次対応を自動化した設計と評価結果、そして今後の展望を紹介します。
背景
筆者の所属チームでは、システム開発と並行して日々の運用も担当しています。運用業務の中には手順がある程度定型化されているものの、件数が多く、継続的に負荷が増えている作業がありました。特に監視アラートへの一次対応は大きな負担で、主に次の課題がありました。
- 対応負荷の増大
一次切り分け、原因調査、過去類似事象の検索に時間がかかり、担当者の負荷が増加していました。 - 定型作業の多さ
既知の手順で対応可能、または調査の結果「対応不要」と判断できるアラートも一定数ありました。 - 情報把握の難しさ
エラーログは情報量が多く、内容の理解と対応方針の決定までに時間を要するケースがありました。
これらを解決し、運用の効率化と品質向上を進めるため、有志メンバーでAIを活用した自動化プロジェクトを立ち上げました。
目的
本プロジェクトの目的は、監視アラートの一次切り分け(調査・情報集約・対応方針提示)を自動化することです。
具体的には、アラート受信時にシステムが自動で過去の類似事象を社内ナレッジ(Backlog Wiki)から検索し、関連する対応内容や調査結果をチケットに集約します。さらに、検索結果とエラーログの整合性が高く、過去事例から「特段の対応は不要」と判断できるアラートについては、自動で課題をクローズし、担当者の確認作業そのものを削減することを目指しました。
方針
1. RAGによる対応手順の提示
LLMでエラーログの内容を解析し、その結果を基に、ベクトル化した社内ナレッジ(Backlog Wiki)を検索(RAG)します。これにより、過去の類似事象や既知の対応手順を提示できる構成としました。
2. 「自信度」に基づく自動クローズ判断
LLMに対し、提示した対応手順の妥当性や自動クローズ可否を自信度(Confidence Score)として数値(0.0〜1.0)で出力させます。自信度が事前に設定した閾値を超えた場合のみ自動クローズし、それ以外は担当者確認に回すことで、誤クローズのリスクを抑えます。
3. 低コストモデルの活用
運用コストを抑えるため、プロンプト設計とRAGの工夫で精度を担保する前提のもと、Amazon Bedrockの低コストモデル Amazon Nova Micro を利用しました。
手法
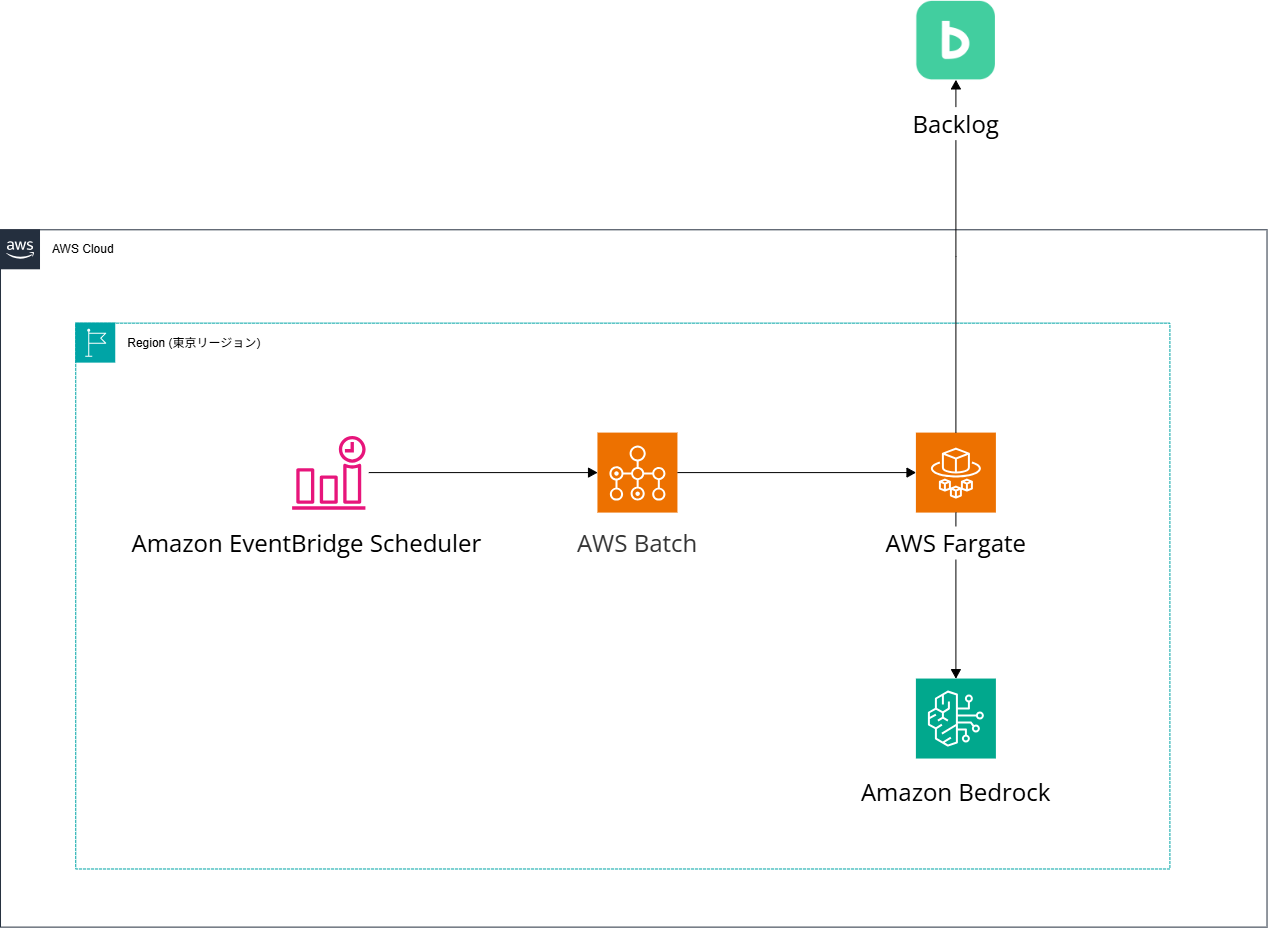
本システムは、AWS Batch上で動作するバッチアプリケーションとして構築しました。
【構成図】
【フロー図】
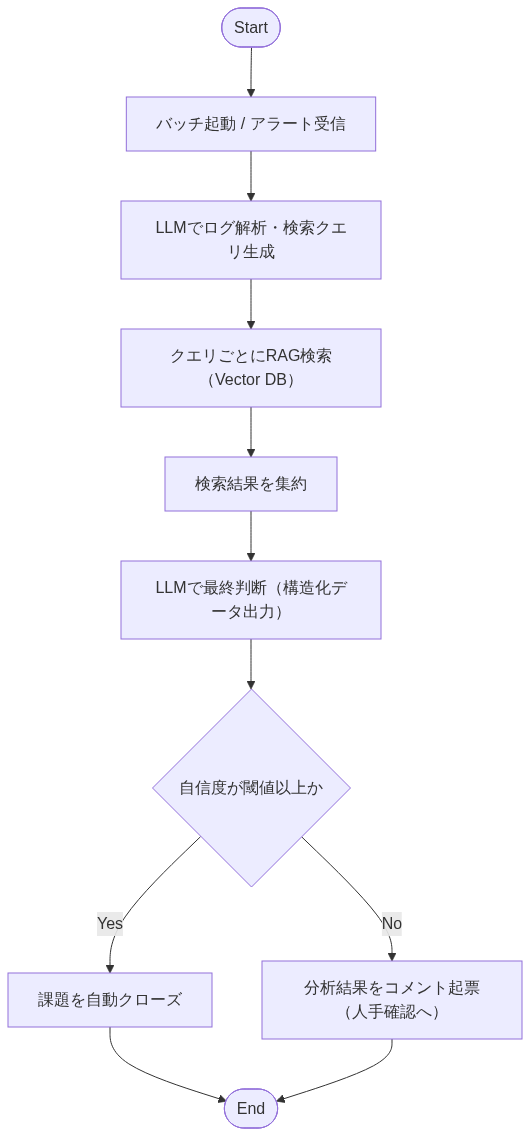
ポイント1:エラー特性に応じた検索クエリの生成
単純にエラーログ全文を検索語にするのではなく、「AIに検索クエリを作成させる」工程を挟むことでRAGの精度を高めました。
LLMに対し、ログからノイズ(タイムスタンプ、変動ID、リクエストIDなど)を除去し、検索に有効なキーワードを抽出するよう指示します。これにより表記ゆれや変動値の影響を受けにくくなり、本質的に類似した事象をヒットさせやすくなります。
▼ 検索クエリ生成プロンプト例
以下のエラー情報に基づいて、検索用のクエリを複数生成してください。
エラー情報:
{{ error_info }}
以下の指針で検索クエリを生成してください:
1. 具体的なエラー内容を優先する
- エラーメッセージの具体的な部分
- エラーが発生した処理の文脈
2. 汎用的なキーワードは避ける
- より具体的で識別しやすいキーワードを選択する
3. 検索のバリエーション
- 完全なエラーメッセージ
- エラー種別
- 関連する機能名
- 問題の症状
4. 3-5個の高品質なクエリを作成する
- 各クエリは具体的で検索しやすいキーワード2-4個で構成
- 重複や類似するクエリは避ける
各クエリは簡潔なキーワードリストとして表現してください。
生成したクエリを用いてベクトルデータベース(Chroma)を検索し、過去の対応事例や手順書を抽出します。
ポイント2:AIによる「解決可否」の判断と自信度
検索結果(社内ナレッジ)と元のエラーログを突き合わせ、AIに最終判断を行わせます。ここで重視したのは、解決策の生成だけではなく、判断の確からしさ(自信度)も同時に出力させることです。
システムはこの自信度を参照し、自信度が高い場合のみ自動クローズします。自信度が低い場合は、人手確認を前提にコメント起票へ切り替えます。
▼ 判断ロジック用プロンプト例
以下のエラー情報とWiki情報を基に、このエラーが解決可能か分析してください。
エラー情報:
{{ error_info }}
情報:
タイトル: {{ title }}
内容:
{{ content }}
以下の観点で分析してください:
1. このWikiの情報がエラーの解決に役立つか
2. 解決可能な場合、具体的な解決方法
3. 分析の自信度(0.0-1.0)
4. 判断の根拠
評価
対象データ
特定の1か月に発生した49件のアラートを対象に分析しました。
自動クローズ率
評価対象のうち、本システムが自動クローズまで実行した割合は 約60% でした(定義:判定結果に加え、自信度が閾値以上のものを自動クローズ)。初回リリースの段階で半数以上のアラートを自動処理できたことは、手作業の削減という観点で大きな成果です。
判定精度(対応不要/要対応)
自動クローズの前段として行っている「対応不要(処理済み)/要対応(処理中)」の判定精度を評価しました。結果は以下のとおりです。
- 正答率(Accuracy):81.63%
- 適合率(Precision)「処理済み」:86.05%
- 再現率(Recall)「処理済み」:92.50%
- F1スコア:0.892
混同行列は以下のとおりです。
| 予測: 対応不要 | 予測: 要対応 | |
|---|---|---|
| 実際: 対応不要 | 37 (TP) | 3 (FN) |
| 実際: 要対応 | 6 (FP) | 3 (TN) |
【各指標の参考】
正答率(Accuracy)81.63% は、全49件のうち正しく判定できた割合です。直感的でわかりやすい反面、今回のようにデータの偏りが大きい場合(対応不要40件 vs 要対応9件)、全部「対応不要」と予測するだけでも81.63%になるため、これだけでは判定の良さを測りにくいです。
適合率(Precision)86.05% は、システムが「対応不要」と判定したもののうち、本当に対応不要だった割合です。裏を返すと、約14%は本当は要対応だったのに「対応不要」と誤判定しています。自動クローズの文脈では、この誤りが誤クローズに直結しうるため、特に重要な指標です。
再現率(Recall)92.50% は、実際に対応不要だったもののうち、システムが正しく「対応不要」と拾えた割合です。これが高いほど自動化のカバー範囲が広いことを意味します。92.50%は高い値ですが、適合率とトレードオフの関係にあり、「とりあえず全部対応不要と判定する」と再現率は100%になる代わりに適合率が下がります。
F1スコア 0.892 は、適合率と再現率の調和平均で、両者のバランスを1つの数値で表したものです。ただし今回のようにクラスの偏りが大きい場合、多数派(対応不要)側のF1は高く出やすい傾向があります。
考察
一次対応の標準化と定型作業の削減
本システムの最も大きな成果は、一次対応の”調査手順”を標準化できた点です。RAGで過去事例を引き当て、対応方針をチケットへ集約することで、担当者の経験差に左右されにくい一定品質の初期案を素早く提供できるようになりました。
また、自信度を用いた閾値ベースの振り分けにより、自動クローズと人手確認の切り替えを機械的に実行できるようになりました。これは「自動化率を上げる」だけでなく、「安全に自動化する」ための重要な設計基盤です。
さらなる改善に向けて
今回の評価では「要対応」のサンプル数が少なく、この領域の判定精度をさらに高める余地があります。これは裏を返せば、対象期間のアラートの大部分が「対応不要」であり、本システムの自動化対象として適した領域であったことを意味しています。
今後は、プロンプトの改善、RAGの検索精度向上、ルールベースのガードレール追加、ナレッジ整備を組み合わせることで、より幅広いパターンに対応できるシステムへ進化させていく予定です。
まとめ
本稿では、LLMとRAGを活用して監視アラート一次対応を自動化する仕組みの開発事例を紹介しました。
検索クエリ生成によるRAGの精度向上と、自信度による安全な自動クローズ制御の組み合わせにより、評価対象49件のうち約60%を自動クローズできました。「対応不要」の判定では正答率81.63%・再現率92.50%を記録し、一定の実用性を確認できています。
一方で、要対応アラートのサンプルが少なく判定精度の検証は今後の課題です。加えて、自信度閾値を含めた自動クローズ全体としての誤クローズ率も、継続的に計測・改善していきます。

