
はじめに
本記事では、Amazon Bedrock AgentCore(以下AgentCore、InvokeInlineAgent API)を使い、クラウドデザインパターンである Scatter-Gather と Saga Orchestration で複数Agentを連携させるアーキテクチャを紹介します。
なぜAgentCoreで複数Agent連携なのか
単一Agentの限界
単一の大きなAgentにすべてを任せると、以下の問題が発生します。
- 処理時間の増大 ― 逐次処理で応答が遅い
- コスト非効率 ― すべてのタスクに高コストモデルを使用
- 専門性の不足 ― 1つのプロンプトで多領域をカバーしきれない
- 障害耐性の欠如 ― 途中で失敗すると全体がやり直し
なぜAgentCoreなのか ― 他のAgent構築ツールとの違い
複数Agentの連携といえば、DifyやLangGraphなどGUIベースのワークフロー構築ツールを思い浮かべる方もいるでしょう。これらは「プレハブキット」のように手軽にAgentを組み立てられる反面、オーケストレーションのカスタマイズには限界があります。
AgentCoreはそれらとはレイヤーが異なります。APIレベルのプリミティブとして、呼び出しごとにモデル・指示・アクショングループを動的に指定でき、AWS Lambda(以下Lambda)・AWS Step Functions(以下Step Functions)・Amazon DynamoDB(以下DynamoDB)等のAWSサービスとネイティブに統合できます。いわば「レンガとセメント」です。自由度は高い代わりに、自分で設計する部分も多くなります。
本記事で紹介するScatter-GatherやSagaのような低レベルのオーケストレーションパターンを、AWS Identity and Access Management(以下IAM)によるきめ細かいアクセス制御やAmazon CloudWatch(以下CloudWatch)による監視と組み合わせて構築できるのは、このアプローチならではの強みです。
AgentCoreが解決すること
AgentCoreの InvokeInlineAgent APIは、マネージドなAgent(高レベルAPI)と異なり、呼び出しごとにモデル・指示・アクショングループを動的に指定できます。これにより、以下が可能になります。
- タスクごとに最適なモデルを選択 ― 財務分析にはOpus 4.6、通知生成にはHaiku 4.5
- カスタムオーケストレーション ― 並列実行や条件分岐を自由に設計
- セッション状態の細かい制御 ― ステップ間でのコンテキスト引き継ぎ
# 例:タスクの性質に応じてモデルを使い分ける
financial_agent_config = {
'foundationModel': 'anthropic.claude-opus-4-6-v1', # 高精度
'instruction': '財務分析の専門家として...'
}
notification_agent_config = {
'foundationModel': 'anthropic.claude-haiku-4-5-20251001-v1:0', # 高速・低コスト
'instruction': '通知文を生成してください'
}
期待できる効果
- 処理時間の短縮 ― 並列実行により、逐次処理と比べて大幅に高速化
- コストの最適化 ― タスクごとに適切なモデルを選択し、不要な高コストモデルの使用を回避
- 保守性の向上 ― Agent単位での独立した開発・テスト・デプロイが可能に
パターン1:Scatter-Gather ― 並列実行で高速化
概要
Scatter-Gatherは、AWS Prescriptive Guidanceでも紹介されているクラウドデザインパターンの1つです。1つのリクエストを複数の処理ノードに同時に送信し(Scatter)、すべての結果を集約する(Gather)という構成を取ります。
このパターンが有効なのは、以下のような場面です。
- 1つのリクエストに対して、複数の独立した処理を並列に実行したい
- 各処理の結果を統合して最終的な応答を生成したい
- 一部の処理が失敗しても、成功した結果だけで応答を返したい
AgentCoreとの組み合わせでは、各Agentが独立して動作するため、全体の処理時間は概ね最も遅いAgentの処理時間に収束します。さらに、Agentごとに異なるモデルを割り当てることで、精度とコストのバランスを最適化できます。
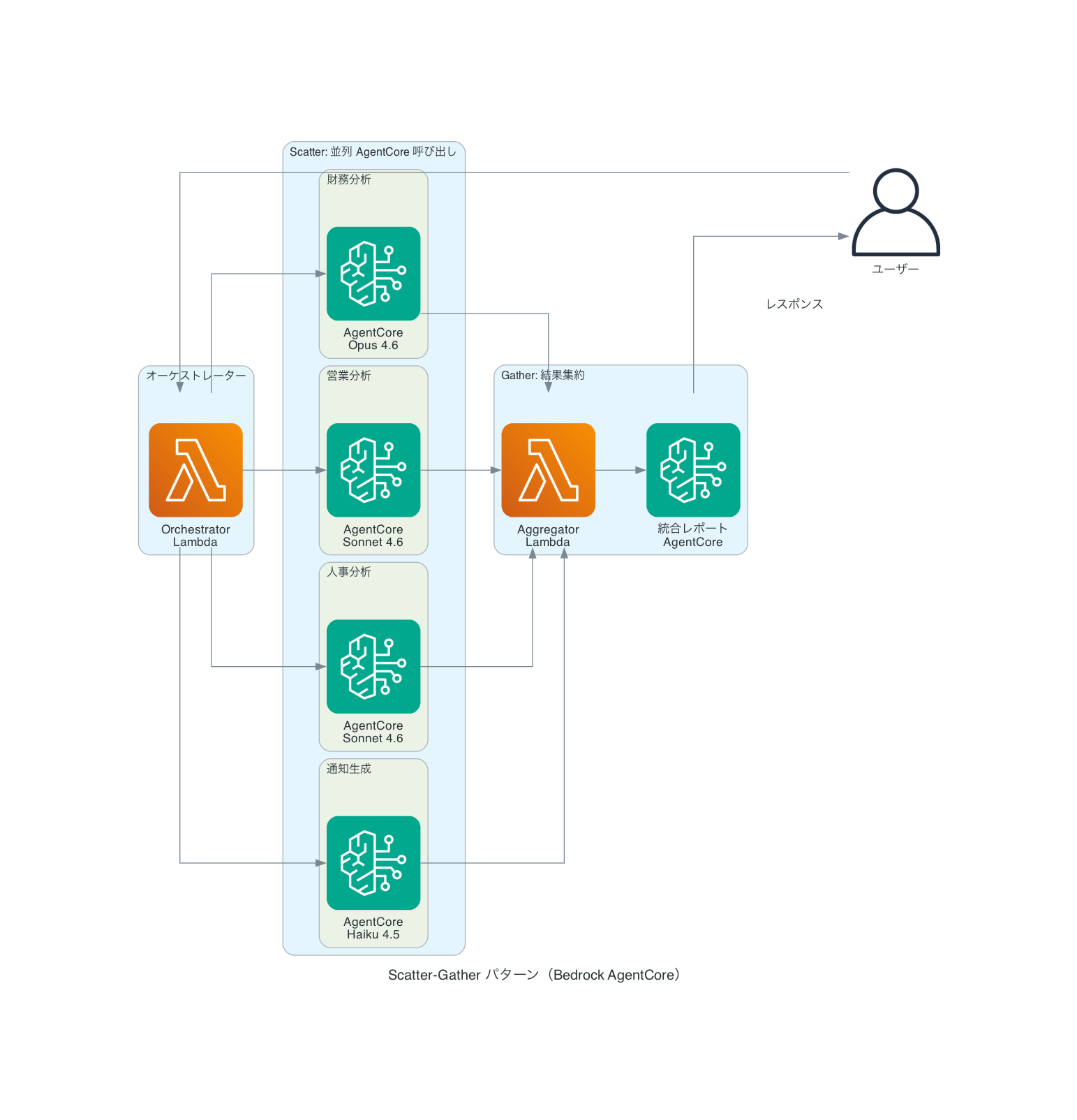
実装
Pythonの ThreadPoolExecutor を使い、複数のAgentCoreを並列に呼び出します。
from concurrent.futures import ThreadPoolExecutor, as_completed
import boto3
import time
import uuid
class AgentCoreScatterGather:
def __init__(self):
self.bedrock = boto3.client('bedrock-agent-runtime')
def scatter_gather(self, agent_configs, input_text):
results = []
with ThreadPoolExecutor(max_workers=len(agent_configs)) as executor:
# Scatter: 全Agentに同時リクエスト
futures = {
executor.submit(
self._invoke_inline_agent, config, input_text
): config for config in agent_configs
}
# Gather: 結果を収集
for future in as_completed(futures):
config = futures[future]
try:
result = future.result(timeout=30)
results.append({
'agentName': config['name'],
'model': config['foundationModel'],
'status': 'success',
'completion': result['completion'],
'executionTime': result['executionTime']
})
except Exception as e:
results.append({
'agentName': config['name'],
'status': 'failed',
'error': str(e)
})
return self._aggregate_results(results)
def _invoke_inline_agent(self, config, input_text):
start_time = time.time()
response = self.bedrock.invoke_inline_agent(
sessionId=str(uuid.uuid4()),
actionGroups=config.get('actionGroups', []),
foundationModel=config['foundationModel'],
instruction=config['instruction'],
inputText=input_text,
sessionState={
'sessionAttributes': {},
'promptSessionAttributes': {}
}
)
completion = ""
for event in response['completion']:
if 'chunk' in event:
chunk = event['chunk']
if 'bytes' in chunk:
completion += chunk['bytes'].decode('utf-8')
return {
'completion': completion,
'executionTime': time.time() - start_time
}
def _aggregate_results(self, results):
successful = [r for r in results if r['status'] == 'success']
summary_prompt = "以下の専門家の分析を統合してください:\n\n"
for r in successful:
summary_prompt += f"【{r['agentName']}の分析】\n{r['completion']}\n\n"
return {
'total': len(results),
'successful': len(successful),
'results': results,
'summary_prompt': summary_prompt,
'totalExecutionTime': max(
(r.get('executionTime', 0) for r in successful), default=0
)
}
_aggregate_results が返す summary_prompt は、そのまま統合用のAgentCoreに渡して最終レポートを生成します。
# 集約結果を統合Agentに渡して最終レポートを生成
aggregated = scatter_gather.scatter_gather(agent_configs, input_text)
bedrock = boto3.client('bedrock-agent-runtime')
response = bedrock.invoke_inline_agent(
sessionId=str(uuid.uuid4()),
foundationModel='anthropic.claude-sonnet-4-6',
instruction='複数の専門家の分析を統合し、簡潔なレポートにまとめてください',
inputText=aggregated['summary_prompt'],
actionGroups=[]
)
モデル選択の最適化
AgentCoreの最大の利点は、タスクの性質に応じてモデルを使い分けられることです。
def create_optimized_agent_configs():
return [
{
'name': '財務Agent',
'foundationModel': 'anthropic.claude-opus-4-6-v1', # 高精度が必要
'instruction': '財務諸表を詳細に分析してください',
'actionGroups': [financial_action_group]
},
{
'name': '営業Agent',
'foundationModel': 'anthropic.claude-sonnet-4-6', # バランス型
'instruction': '営業データを分析してください',
'actionGroups': [sales_action_group]
},
{
'name': '在庫Agent',
'foundationModel': 'anthropic.claude-sonnet-4-6', # バランス型
'instruction': '在庫データを分析してください',
'actionGroups': [inventory_action_group]
},
{
'name': '通知Agent',
'foundationModel': 'anthropic.claude-haiku-4-5-20251001-v1:0', # 高速・低コスト
'instruction': '簡潔な通知文を生成してください',
'actionGroups': [notification_action_group]
}
]
高精度が求められる財務分析にはOpus 4.6、定型的な通知生成にはHaiku 4.5を使うことで、品質を維持しながらコストを最適化できます。
Scatter-Gatherでは並列実行されるため、逐次実行と比較して大幅な高速化が期待できます。
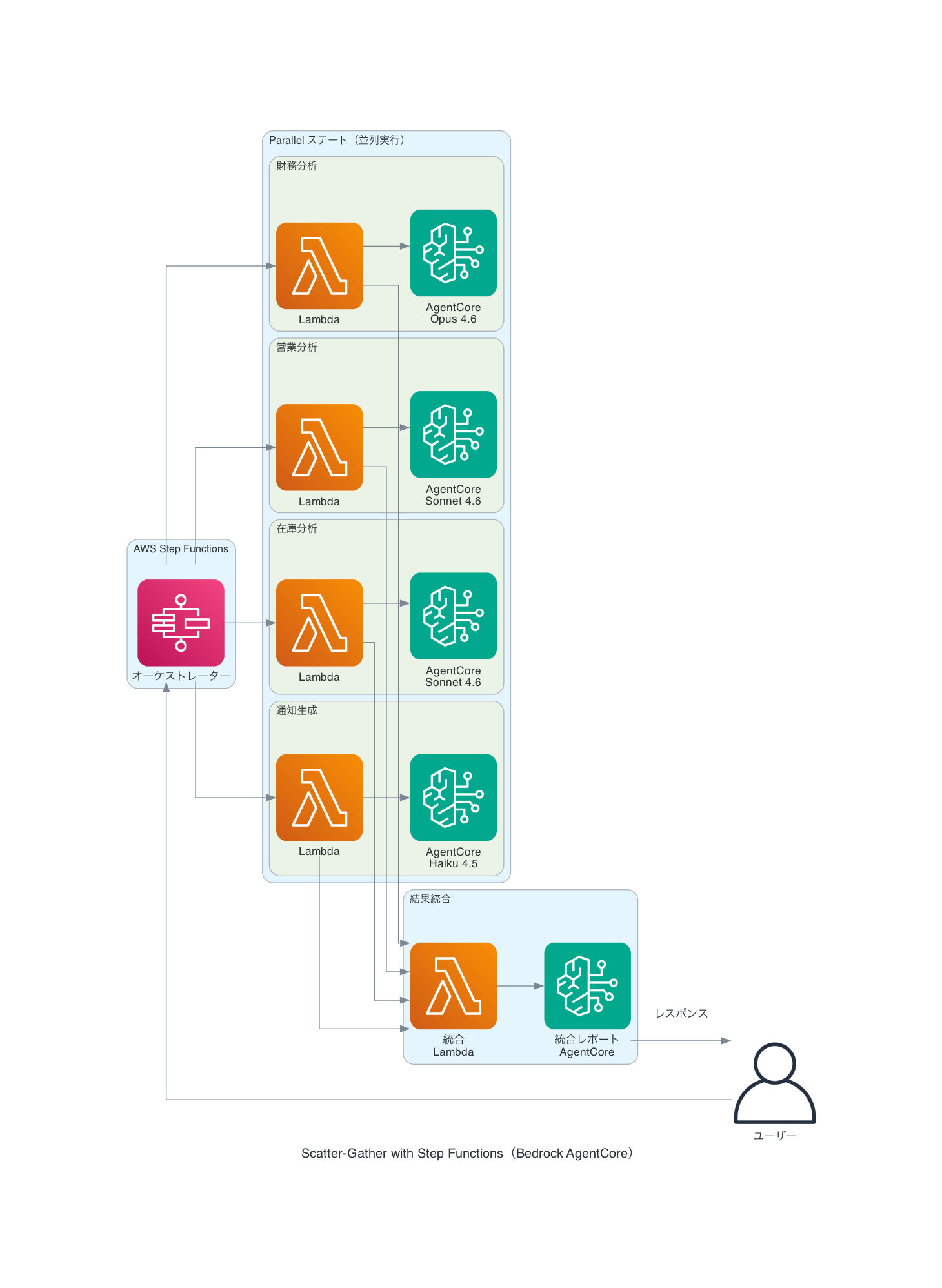
Step Functionsとの統合
前述の ThreadPoolExecutor による実装はLambda内で完結する簡易的なアプローチです。本番環境では、Step Functionsの Parallel ステートを使うことで、各ブランチの独立したリトライ・タイムアウト制御や実行履歴の可視化が可能になります。
{
"Comment": "AgentCore Scatter-Gather with Step Functions",
"StartAt": "ParallelAnalysis",
"States": {
"ParallelAnalysis": {
"Type": "Parallel",
"Branches": [
{
"StartAt": "FinancialAnalysis",
"States": {
"FinancialAnalysis": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "agentcore-scatter-executor",
"Payload": {
"agent": "financial",
"foundationModel": "anthropic.claude-opus-4-6-v1",
"inputText.$": "$.inputText"
}
},
"Retry": [{"ErrorEquals": ["States.TaskFailed"], "MaxAttempts": 2}],
"End": true
}
}
},
{
"StartAt": "SalesAnalysis",
"States": {
"SalesAnalysis": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "agentcore-scatter-executor",
"Payload": {
"agent": "sales",
"foundationModel": "anthropic.claude-sonnet-4-6",
"inputText.$": "$.inputText"
}
},
"Retry": [{"ErrorEquals": ["States.TaskFailed"], "MaxAttempts": 2}],
"End": true
}
}
},
{
"StartAt": "InventoryAnalysis",
"States": {
"InventoryAnalysis": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "agentcore-scatter-executor",
"Payload": {
"agent": "inventory",
"foundationModel": "anthropic.claude-sonnet-4-6",
"inputText.$": "$.inputText"
}
},
"Retry": [{"ErrorEquals": ["States.TaskFailed"], "MaxAttempts": 2}],
"End": true
}
}
},
{
"StartAt": "Notification",
"States": {
"Notification": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "agentcore-scatter-executor",
"Payload": {
"agent": "notification",
"foundationModel": "anthropic.claude-haiku-4-5-20251001-v1:0",
"inputText.$": "$.inputText"
}
},
"Retry": [{"ErrorEquals": ["States.TaskFailed"], "MaxAttempts": 2}],
"End": true
}
}
}
],
"Next": "AggregateResults"
},
"AggregateResults": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "agentcore-scatter-aggregator",
"Payload": {
"results.$": "$"
}
},
"End": true
}
}
}
Parallel ステートの各ブランチに Retry を設定することで、一時的な障害に対する自動リトライが可能です。Parallel ステートの出力は各ブランチの結果が配列として返されるため、後続の AggregateResults Lambda で配列を受け取り、各Agentの分析結果を整形・統合します。ThreadPoolExecutor 版ではこうしたリトライやタイムアウトの制御を自前で実装する必要がありますが、Step Functionsではステートマシンの定義だけで宣言的に管理できます。
パターン2:Saga Orchestration ― 分散トランザクションの管理
概要
Sagaは、AWS Prescriptive Guidanceでも紹介されているクラウドデザインパターンの1つで、複数のステップからなる長時間トランザクションを管理します。分散システムでは単一のデータベーストランザクション(ACID)で全体を包むことができないため、各ステップを個別のトランザクションとして実行し、失敗時には補償トランザクションを逆順に実行して整合性を保ちます。
このパターンが有効なのは、以下のような場面です。
- 複数のサービスにまたがるトランザクションを管理したい
- 途中のステップが失敗した場合に、それまでの処理を安全にロールバックしたい
- 各ステップの実行状態を追跡・監査したい
「在庫確保や決済なら従来のLambdaだけで十分では?」と思うかもしれません。AgentCoreを挟む価値があるのは、各ステップで自然言語による指示解釈や、外部APIのレスポンスを判断して動的に分岐するような柔軟性が求められる場合です。たとえば、在庫確保時に「類似商品での代替提案」を行ったり、決済エラーの内容を解釈して適切なリトライ戦略を選択するといったケースが該当します。
ECサイトの注文処理を例に考えてみましょう。
在庫確保 → 決済処理 → 配送手配
↓ 失敗
在庫解放 ← 補償トランザクション
決済が失敗した場合、すでに確保した在庫を自動的に解放する必要があります。
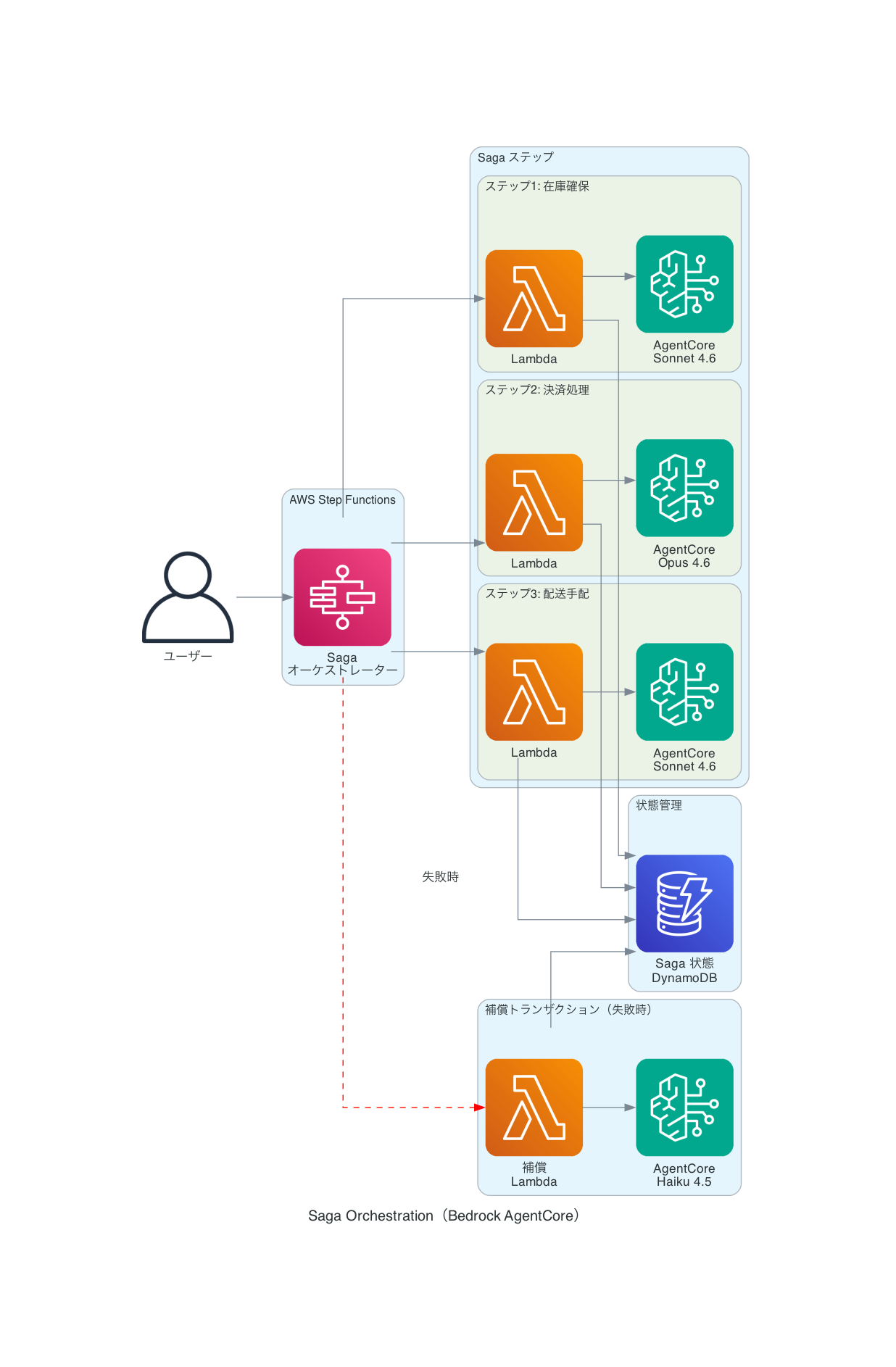
実装
import json
import time
import uuid
import boto3
class AgentCoreSagaOrchestrator:
def __init__(self):
self.bedrock = boto3.client('bedrock-agent-runtime')
self.dynamodb = boto3.resource('dynamodb')
self.saga_table = self.dynamodb.Table('saga-state')
def execute_saga(self, saga_id, steps):
executed_steps = []
try:
for step in steps:
print(f"Executing: {step['name']}")
result = self._execute_step(step['config'], step['inputText'])
executed_steps.append({
'name': step['name'],
'result': result,
'compensate': step.get('compensate')
})
self._save_saga_state(saga_id, executed_steps, 'IN_PROGRESS')
self._save_saga_state(saga_id, executed_steps, 'COMPLETED')
return {'status': 'COMPLETED', 'steps': executed_steps}
except Exception as e:
print(f"Saga failed: {e}")
compensated = self._compensate(executed_steps)
self._save_saga_state(saga_id, executed_steps, 'COMPENSATED')
return {
'status': 'FAILED',
'error': str(e),
'compensated': compensated
}
def _execute_step(self, config, input_text):
response = self.bedrock.invoke_inline_agent(
sessionId=str(uuid.uuid4()),
actionGroups=config.get('actionGroups', []),
foundationModel=config['foundationModel'],
instruction=config['instruction'],
inputText=input_text,
sessionState=config.get('sessionState', {})
)
completion = ""
for event in response['completion']:
if 'chunk' in event:
chunk = event['chunk']
if 'bytes' in chunk:
completion += chunk['bytes'].decode('utf-8')
return {'completion': completion}
def _compensate(self, executed_steps):
compensated = []
for step in reversed(executed_steps):
if step.get('compensate'):
try:
print(f"Compensating: {step['name']}")
result = self._execute_step(
step['compensate']['config'],
step['compensate']['inputText']
)
compensated.append({'step': step['name'], 'status': 'compensated'})
except Exception as e:
compensated.append({
'step': step['name'],
'status': 'compensation_failed',
'error': str(e)
})
return compensated
def _save_saga_state(self, saga_id, steps, status):
self.saga_table.put_item(Item={
'sagaId': saga_id,
'timestamp': int(time.time()),
'status': status,
'steps': json.dumps(steps, default=str)
})
注文処理への適用例
各ステップで異なるモデルを使い、補償トランザクションにはコストの低いモデルを割り当てます。なお、補償トランザクションの inputText にあるプレースホルダ({reservation_id} 等)は、実際には各ステップの実行結果から抽出したIDで動的に置換する必要があります。ここでは簡略化のためプレースホルダのまま記載しています。
def create_order_saga_steps():
return [
{
'name': 'ReserveInventory',
'config': {
'foundationModel': 'anthropic.claude-sonnet-4-6',
'instruction': '在庫管理システムと連携してください',
'actionGroups': [inventory_action_group]
},
'inputText': '商品ID: ABC123 の在庫を1個確保してください',
'compensate': {
'config': {
'foundationModel': 'anthropic.claude-haiku-4-5-20251001-v1:0',
'instruction': '在庫管理システムと連携してください',
'actionGroups': [inventory_action_group]
},
'inputText': '予約ID: {reservation_id} の在庫を解放してください'
}
},
{
'name': 'ProcessPayment',
'config': {
'foundationModel': 'anthropic.claude-opus-4-6-v1', # 決済は高精度
'instruction': '決済システムと連携してください',
'actionGroups': [payment_action_group]
},
'inputText': '金額: 10000円 を決済してください',
'compensate': {
'config': {
'foundationModel': 'anthropic.claude-sonnet-4-6',
'instruction': '決済システムと連携してください',
'actionGroups': [payment_action_group]
},
'inputText': '取引ID: {transaction_id} をキャンセルしてください'
}
},
{
'name': 'ArrangeShipping',
'config': {
'foundationModel': 'anthropic.claude-sonnet-4-6',
'instruction': '配送システムと連携してください',
'actionGroups': [shipping_action_group]
},
'inputText': '配送を手配してください',
'compensate': {
'config': {
'foundationModel': 'anthropic.claude-haiku-4-5-20251001-v1:0',
'instruction': '配送システムと連携してください',
'actionGroups': [shipping_action_group]
},
'inputText': '配送ID: {shipping_id} をキャンセルしてください'
}
}
]
ポイントは、補償トランザクション(キャンセル処理)には高精度モデルが不要なため、Haiku 4.5を使ってコストを抑えている点です。
Step Functionsとの統合
本番環境では、Sagaの各ステップをStep Functionsで管理することで、可視性・リトライ・エラーハンドリングが強化されます。
{
"Comment": "AgentCore Saga with Step Functions",
"StartAt": "ReserveInventory",
"States": {
"ReserveInventory": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "agentcore-saga-executor",
"Payload": {
"step": "ReserveInventory",
"config.$": "$.inventoryConfig",
"inputText.$": "$.inventoryInput"
}
},
"Catch": [{
"ErrorEquals": ["States.ALL"],
"Next": "NotifyFailure"
}],
"Next": "ProcessPayment"
},
"ProcessPayment": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "agentcore-saga-executor",
"Payload": {
"step": "ProcessPayment",
"config.$": "$.paymentConfig",
"inputText.$": "$.paymentInput"
}
},
"Catch": [{
"ErrorEquals": ["States.ALL"],
"Next": "CompensateInventory"
}],
"Next": "ArrangeShipping"
},
"ArrangeShipping": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "agentcore-saga-executor",
"Payload": {
"step": "ArrangeShipping",
"config.$": "$.shippingConfig",
"inputText.$": "$.shippingInput"
}
},
"Catch": [{
"ErrorEquals": ["States.ALL"],
"Next": "CompensatePayment"
}],
"End": true
},
"CompensatePayment": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "agentcore-saga-compensator",
"Payload": {
"step": "ProcessPayment",
"compensateConfig.$": "$.paymentCompensateConfig"
}
},
"Next": "CompensateInventory"
},
"CompensateInventory": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "agentcore-saga-compensator",
"Payload": {
"step": "ReserveInventory",
"compensateConfig.$": "$.inventoryCompensateConfig"
}
},
"Next": "NotifyFailure"
},
"NotifyFailure": {
"Type": "Fail"
}
}
}
AgentCore vs マネージドAgent ― どちらを選ぶか
| シナリオ | 推奨 | 理由 |
|---|---|---|
| 標準的なチャットボット | マネージドAgent | シンプル、自動管理 |
| 複数モデルの使い分け | AgentCore | モデル選択の柔軟性 |
| カスタムオーケストレーション | AgentCore | 細かい制御が可能 |
| コスト最適化が重要 | AgentCore | タスク別モデル選択 |
| 迅速なプロトタイピング | マネージドAgent | 実装が簡単 |
マネージドAgentは「すぐに動くものが欲しい」場合に最適です。一方、複数モデルの使い分けやカスタムオーケストレーションが必要な場合は、AgentCoreが力を発揮します。
実装時の注意点
AgentCoreで複数Agent連携を構築する際に気をつけるべきポイントです。
1.セッション状態の管理 ― AgentCoreではセッション状態を自分で管理する必要があります。DynamoDBによる自前管理のほか、マネージドな短期・長期メモリを提供するGet started with AgentCore Memory – Amazon Bedrock AgentCoreも選択肢になります。要件に応じて使い分けましょう。
2.ストリーミングレスポンスの処理 ― InvokeInlineAgent はストリーミングで応答を返します。チャンク単位でのエラー検知と、部分的な結果の保存を実装しておくと安心です。
3.段階的な移行 ― 既存のマネージドAgentからの移行は、一部のAgentをAgentCoreに置き換えて効果を検証してから拡大するのがおすすめです。
4.モニタリングと可観測性 ― CloudWatch Metricsで各Agentの呼び出し回数・レイテンシ・エラー率を監視し、AWS X-Rayでリクエスト全体のトレースを取得しましょう。Scatter-Gatherではレイテンシ分布、Sagaでは補償トランザクションの発生頻度が重要な運用指標になります。
まとめ
Amazon Bedrock AgentCoreとクラウドデザインパターンを組み合わせることで、以下の効果が期待できます。
- 処理時間の短縮 ― Scatter-Gatherによる並列化
- コストの最適化 ― タスクに応じた最適なモデル選択
- 高い信頼性 ― Saga Orchestrationによる分散トランザクション管理
- 保守性の向上 ― Agent単位での独立した開発・テスト・デプロイ
単一の万能Agentを作ろうとするのではなく、専門化された小さなAgentを組み合わせる。マイクロサービスで学んだ教訓は、AI Agentの世界でも有効です。

