
はじめに
生成AIの活用が当たり前になる中、「AIの回答が本当に正しいのか?」「ハルシネーション(もっともらしい嘘)を含んでいないか?」をどう担保するかが重要な課題になっています。これまでは、人間が目視で一つずつ確認していて非効率であり、判断基準が明確でないことが課題となっていました。
そこで今回は、生成AIの回答品質を定量的に評価できる仕組みである「Gen AI Evaluation Service」を実際に検証してみました。
本記事では、その検証プロセスや結果について詳しく解説します。
Gen AI Evaluation Service とは?
Gen AI Evaluation Serviceは、Google CloudのVertex AI上で提供されている、生成AIモデルやアプリケーションの出力品質を自動・定量的に評価するマネージドサービスです。
生成AIの回答が適切かどうかを判断するルーブリック(評価基準)を自動生成したり、独自の基準に基づいて回答の精度や安全性、ハルシネーション(嘘)の有無を自動的に評価したりすることができます。高度な AI を「評価者」として活用することで、人間が行うような複雑な評価を自動化・高速化します。
ユースケース
主に以下の5つの開発タスクで活用されます。
- モデルの移行
バージョン間の動作を比較し、プロンプトや設定を最適化する。 - 最適なモデルの特定
Google製とサードパーティ製のモデルを直接比較し、自社の用途に最適なモデルを選ぶ。 - プロンプトの改善
評価と修正を繰り返すことで、プロンプトを継続的に改善する。 - ファインチューニングの評価
一貫した基準を用いて、微調整したモデルの品質を正確に評価する。 - エージェントの評価
トレースや応答品質など、AIエージェント特有の指標を用いてパフォーマンスを測る。
評価指標
Gen AI Evaluation Service は、モデルベースと計算ベースの両方の評価方法を使用して、Google のモデル、サードパーティのモデル、さまざまな言語のオープンモデルで動作します。
モデルベースの指標
Google 所有のモデルを使用して、候補モデルの出力を評価します。このモデルはエバリュエータとして機能し、定義済みの基準に基づいて回答にスコアを付けます。
| 指標の種類 | 説明 |
|---|---|
| ポイントワイズの指標 | 判定モデルが候補モデルの出力に数値スコア(0~5 のスケールなど)を割り当て、評価基準との整合性を示します。スコアが高いほど適合度が高くなります。 |
| ペアワイズの指標 | 判定モデルが 2 つのモデルの回答を比較し、優れているモデルを特定します。このアプローチは、候補モデルをベースライン モデルと比較するためによく使用されます。 |
計算ベース(Computing-based)の指標
モデルの出力をグラウンド トゥルースまたは基準値と対比する数式を使用します。
よく使用される例としては、ROUGEやBLEUがあります。
実現したい構成
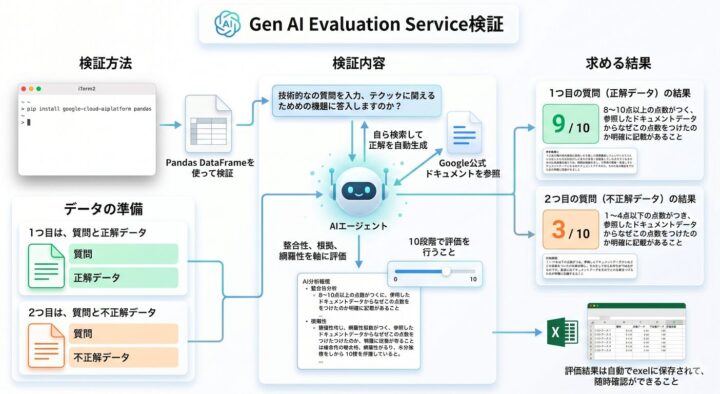
今回実現したい構成図です。詳細は以下に記載しておりますが、簡潔にいうと
【AIが「質問」の内容に対して自らGoogle 公式ドキュメント検索を行い、正解を自動生成した後に「回答」の精度を判定】する仕組みです。
評価条件
▪️AIが「質問」から自ら検索して正解を自動生成すること(Google 公式ドキュメントを参照)
▪️取得した正解に基づく妥当性評価として、整合性、根拠、網羅性を軸に評価を行う。
▪️採点基準としては、こちらで設定した10段階で評価を行うこと
▪️評価結果は自動でExcelに保存されて、随時確認ができること。
データの準備
Google Cloudに対する技術質問を2パターン用意
▪️1つ目は、質問と正解データ
▪️2つ目は、質問と不正解データ
求める結果
▪️1つ目の質問 (正解データ)
・8~10点以上の点数がつき、参照したドキュメントデータからなぜこの点数をつけたのか明確に記載があること
▪️2つ目の質問 (不正解データ)
・1~4点以下の点数がつき、参照したドキュメントデータからなぜこの点数をつけたのか明確に記載があること
検証の開始
Gen AI Evaluation Serviceの検証をするにあたって以下2パターンがございましたが、
今回は「Vertex AI SDK の生成 AI クライアントを使用」する方法にて検証しました。
・コンソールを使用して評価を行う
・Vertex AI SDK の生成 AI クライアントを使用して評価を行う
準備
1.Vertex AI SDK for Python をインストールします。
(Python 用の Vertex AI 公式パッケージ(SDK)をインストールしています。)
pip install google-cloud-aiplatform[evaluation]
2.ライブラリを読み込みます。
(インストールした Vertex AI のライブラリを、現在の Python プログラムで使えるように読み込みます。)
import vertexai
3.Vertex AI を初期化します。
(「これ以降のプログラムで Vertex AI の機能を使うときは、このプロジェクトとリージョンを使ってくださいね」という設定が完了します)
PROJECT_ID = "PROJECT_ID" LOCATION = "LOCATION" vertexai.init(project=PROJECT_ID, location=LOCATION)
評価データの準備
データセットは、Pandas DataFrame で作成をしております。
実際に用意したデータは、「prompt(ユーザーの入力)」と「response(生成AIの回答)」 になります。
data = {
"prompt": [
"Cloud StorageのStandardストレージクラスのデータ耐久性はどれくらいですか?",
"Cloud Functions (第2世代) の最大実行時間は何分ですか?"
],
"response": [
"Cloud Storageの耐久性は、年間99.999999999%(11個の9)として設計されています。",
"Cloud Functionsは最大で30分間実行し続けることができます。"
]
}
※上記2つの質問について、1つ目は正解、2つ目は不正解の回答を準備
評価指標の作成
公式には、Gen AI Evaluation Service を使用したモデルベースの評価に使用できるテンプレートのリストが用意されておりますが、今回は、「独自の指標」をベースに定義しています。
※ただし、作成されたカスタムプロンプト内で以下概念を明示的に取り入れています。
・根拠性 ・指示実行
以下は、「独自の指標」として設定したプロンプトになります。
①AIが「質問」から自ら検索して正解を自動生成するプロンプト
※本記事では ai_client の初期化コードは省略しています
print(f"【Step 1】{MODEL_NAME} が質問内容を分析し、公式ドキュメントを自律検索中...")
def auto_fetch_reference(prompt_text):
"""お客様の質問を元に、AI自身に検索させて正解を作らせる関数"""
instruction = f"""
あなたはGoogle Cloudの専門エンジニアです。
以下の質問に関するGoogle Cloud公式の仕様を、Google検索で調べて簡潔に要約してください。
検索する際は "site:cloud.google.com" を含めてください。
質問: {prompt_text}
回答は日本語で、数値や仕様を正確に含めてください。
"""
try:
# 新しい SDK (ai_client) と、正しい google_search ツール指定を使ってリクエスト
res = ai_client.models.generate_content(
model=MODEL_NAME,
contents=instruction,
config=types.GenerateContentConfig(
tools=[types.Tool(google_search=types.GoogleSearch())],
temperature=0.0
)
)
return res.text
except Exception as e:
return f"検索・抽出エラー: {str(e)}"
# reference_text列を作成
eval_dataset["reference_text"] = eval_dataset["prompt"].apply(auto_fetch_reference)
for i, row in eval_dataset.iterrows():
print(f"\n--- 質問{i+1} ---")
print(f"質問: {row['prompt']}")
print(f"取得した参照テキスト:\n{row['reference_text'][:300]}") # 最初の300文字だけ表示
②取得した正解に基づく妥当性評価
print("【Step 2】Vertex AI評価サービスを利用して、回答の妥当性を評価中...")
gc_eval_prompt_template = """
# Instruction
あなたはGoogle Cloud (GC) のプロフェッショナルな品質監査官です。
お客様からの質問に対するオペレーターの回答(Response)が、提供されたGoogle Cloud公式ドキュメント(Reference)の内容と整合しているかを厳格に評価してください。
# Evaluation Criteria (評価項目)
1. GC Accuracy (整合性): 回答は公式ドキュメントの内容と一致していますか?
2. Groundedness (根拠): 回答に含まれる情報は、Referenceに含まれる内容のみに基づいていますか?
3. Completeness (網羅性): 重要な注意点や前提条件を漏らさず伝えていますか?
③1~10段階で各採点基準を設けて評価
# Rating Rubric (採点基準)
* 10 (極めて優秀): 指示に完璧に従い、提供された参考情報のみに正確に基づいている。非常に簡潔かつ流暢で、模範となる情報と完全に一致している。すべての評価基準において非の打ち所がない。
* 9 (非常に良い): 指示にほぼ完璧に従い、提供された参考情報のみに正確に基づいている。簡潔かつ流暢で、模範となる情報と高度に一致している。全体的に非常に高品質で、改善の余地はごくわずかである。
* 8 (良い): 指示に従い、提供された参考情報のみに基づいている。簡潔かつ流暢である。概ね模範となる情報と一致しているが、一部にわずかな改善の余地があるか、他の基準においてごく軽微な不足がある。
* 7 (やや良い): 概ね指示に従い、提供された参考情報に基づいている。簡潔さや流暢さにおいて改善の余地があるかもしれないが、内容は明確に理解できる。模範となる情報と部分的に一致している。
* 6 (平均的): 概ね指示に従い、提供された参考情報に基づいている。しかし、簡潔さ、流暢さ、または一致度のいずれか1つ以上に課題がある。内容は理解できるが、改善が望ましい。
* 5 (やや欠陥あり): 指示に対する理解がやや不十分であるか、参考情報には基づいているものの、簡潔さや流暢さが低い。一致度も低い。重要な情報が欠けているか、冗長な部分がある。
* 4 (欠陥あり): 指示への準拠度が低い。参考情報には基づいているものの、簡潔さ、流暢さ、および一致度が低い。回答内容の理解に支障をきたすレベルである。
* 3 (不十分): 参考情報には基づいているが、大部分の指示に従っていない。回答が不明瞭であるか、文章構成が不適切である。
* 2 (非常に不十分): 提供された参考情報に基づいていないことが明らかである(例:外部情報の持ち込み、ハルシネーション)。指示に従っていない。回答として不適切である。
* 1 (完全に不足): 提供された参考情報に全く基づいておらず、指示にも完全に反している。回答として成立していないか、全くの無関係な内容である。
## User Inputs
### Reference (Google Cloud Official Doc)
{reference}
### Prompt (Customer Question)
{prompt}
## AI-generated Response (Operator Answer)
{response}
"""
gc_validity_metric = PointwiseMetric(
metric="gc_answer_validity",
metric_prompt_template=gc_eval_prompt_template,
)
eval_task = EvalTask(
dataset=eval_dataset,
metrics=[gc_validity_metric],
experiment="gc-fully-auto-eval",
metric_column_mapping={
"reference": "reference_text",
}
)
eval_result = eval_task.evaluate()
result_df = eval_result.metrics_table
④主要な結果の画面表示 & Excelファイルへの保存
display_columns = [
"prompt",
"response",
"reference_text",
"gc_answer_validity/score",
"gc_answer_validity/explanation"
]
print("\n【詳細評価結果】")
print(result_df[[c for c in display_columns if c in result_df.columns]])
filename = "gc_fully_auto_evaluation_results.xlsx"
result_df.to_excel(filename, index=False)
print(f"\nExcelファイル '{filename}' を作成しました!")
実行が完了すると以下のように出力されます。
送信した2つの評価リクエストが、通信エラーやAPIの制限などに引っかかることなく、すべて正常に計算・完了したという最終報告になります。
Computing metrics with a total of 2 Vertex Gen AI Evaluation Service API requests. 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:15<00:00, 7.78s/it] All 2 metric requests are successfully computed. Evaluation Took:15.592492458003107 seconds
評価結果はいかに。。。
こちらが「Gen AI Evaluation Service」によって出力された評価結果となります。

1問目(質問と正解データ)
- 期待する点数: 8〜10点以上
- 結果: 10点
- 採点理由: 回答は、プロンプトで問われたStandardストレージクラスのデータ耐久性について、提供された公式ドキュメントの情報を正確かつ簡潔に伝えています。数値、単位(年間)、および「11個の9」という表現も完全に一致しており、情報源のみに基づいています。重要な注意点や前提条件の漏れもありません。
- 検索精度: ⭕
- 分析内容: ⭕
評価に対する感想
Gen AI Evaluation Serviceによって用意された正解データとあらかじめ与えていたデータが完全一致し、10点というスコアがつきました。期待通りの挙動で、採点理由も問題ありませんでした。
2問目(質問と不正解データ)
- 期待する点数: 1〜4点以下
- 結果: 2点
- 採点理由: 回答された最大実行時間「30分」は、提供された公式ドキュメントに記載されておらず、明確なハルシネーションです。ドキュメントにはHTTPトリガーで最大60分、イベントドリブンで最大9分と明確に記載されており、この重要な区別も欠落しているため、整合性と根拠が完全に不足しています。
- 検索精度: ⭕
- 分析内容: ⭕
評価に対する感想
Gen AI Evaluation Serviceによって用意された不正解データとあらかじめ与えていたデータが一致せず、2点というスコアがつきました。こちらも期待通りの挙動で、採点理由も問題ありませんでした。
まとめ
本記事では、生成AIの回答品質を自動・定量的に評価するGoogle Cloudの「Gen AI Evaluation Service」について、実際の検証を交えて解説しました。
生成AIの業務利用が拡大する中、出力の「正しさ」や「安全性」をどう担保するかは避けて通れない課題です。
本サービスは独自の評価基準を設けるなど柔軟なカスタマイズが可能であり、生成AIを実業務へ安全かつ確実に組み込むための強力なツールとして、非常に有効な選択肢となると感じました。



