
はじめに
本記事は、Google Cloud Next ’26のセッション「What’s new in AlloyDB: Scale PostgreSQL for agentic AI and hybrid clouds」ついての記事となります。
現代のデータ戦略における最大の障壁は、「運用(OLTP)」と「分析(OLAP)」の分断です。
運用データベースにある最新データと、データレイクにある膨大な履歴データがサイロ化し、その間を複雑なETLパイプラインが繋ぐといった難解な仕組みを解消する可能性が提示されました。これだけで単体記事にできる内容だったので、より細かく分割しました。
「データサイロ」を解消するユニファイドアーキテクチャ
これまでは、AlloyDB上のトランザクションアプリと、BigQuery上の分析環境は別個の存在でした。しかし、セッション中に発表された新しいアーキテクチャではこれらを「単一のプラットフォーム」として扱います。
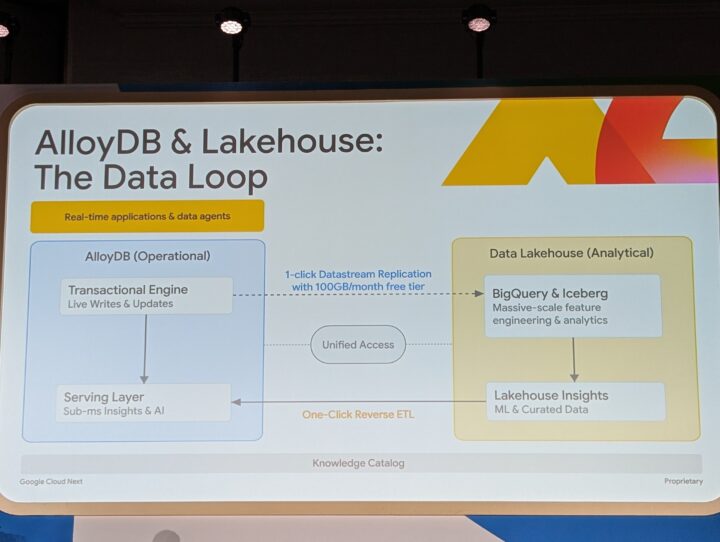
- 左側(運用): リアルタイムな書き込みとAIによる洞察を行うAlloyDB
- 右側(分析): 履歴データや大規模な特徴量エンジニアリングを担うBigQuery & Apache Iceberg
この両翼が統合されることで、開発者はデータの所在を意識することなく、Postgres互換のSQLから透過的にアクセスできるようになります。
- データ連携機能
- Datastreamによる 運用 DB → BigQuery への変更データレプリケーション
- AlloyDB コンソールからの「ワンクリック複製」エクスペリエンス
- AlloyDB → BigQuery などのパイプラインを簡単に設定
- 「逆方向」のデータ連携
- BigQuery やデータレイク側から AlloyDB 側にデータを戻す/同期するユースケースをサポート
- 統一アクセスレイヤ
- BigQuery External Query
- BigQuery から AlloyDB のデータを外部テーブルとして参照し、SQL で統合クエリ
- Lake House Foundation
- Iceberg テーブルなどのレイクハウス形式を、Postgres 互換の SQL で扱う基盤
- AlloyDB/BigQuery/Iceberg を同一の SQL から透過的にクエリ可能
- Knowledge Catalog(データカタログ/ガバナンス)
- メタデータ管理とデータ発見を提供、特に AI/アナリティクス・ワークロードでのデータガバナンスに重要
- BigQuery External Query
※Knowledge Catalogについて
https://docs.cloud.google.com/dataplex/docs/use-cases?hl=ja
この構成がもたらすパラダイムシフト
このデータループが実現することで、エンジニアリングとビジネスの両面で決定的なメリットが生まれます。
- ETLパイプラインの運用コストが無くなる
- 「設定」「変換」「書き戻し」をバラバラのツールで管理する必要がなくなり、1-Click連携によりエンジニアはパイプラインの保守ではなく、価値を生むための「分析ロジック」に集中できます
- 「データが古い」という制約の撤廃
- 「分析結果はバッチ処理待ち」というタイムラグがなくなります。ビジネスサイドは、常に「今の状況」に基づいた意思決定と自動アクションを実行可能に
- AI活用の民主化
- AlloyDB AIとBigQuery MLが直結し、高度なデータサイエンティストがいなくても、使い慣れたSQLの延長線上で、予測モデルをリアルタイムにアプリケーションへ組み込むことが可能になります
データエンジニアリングの再定義へ
このデータループにより例えば以下のようなパーソナライズされたEC体験が実現できるようになります。
- 運用: ユーザーが商品をカートに入れる(AlloyDB)
- 分析: 数秒後にBigQueryへ同期され、過去の全履歴と照らし合わせて「今、このユーザーに追加商品の提案、購入完了へ誘導するためのクーポンを出すべきか」をAIが判定(BigQuery ML)
- フィードバック: 判定結果をAlloyDBに書き戻し、ユーザーの画面に即座に最適な商品提案、クーポンを表示
Knowledge Catalogによる一貫したガバナンスのもと、AI・アナリティクスワークロードはさらに加速していくなと。例に挙げたようにECへの活用にかなり可能性を感じました。




