
この記事は、Google Cloud Next ’26 のセッションレポートです。
セッション情報
- セッション名: From notebook to production: Streamlining MLOps with Colab Enterprise and Gemini Enterprise
- 登壇者:
- Eric Schmidt 氏(Staff Developer Relations Engineer, Google Cloud)
- Neama Dadkhahnikoo 氏(Outbound Product Manager, Google Cloud)
- Raj Katakam 氏(Staff Machine Learning Engineer, Credit Karma)
先に30秒でまとめ
- 発表されたもの: ノートブックでの分析から本番運用までを、ひと続きで楽に進めるための話。Colab Enterprise の機能拡充と、規制業界の Credit Karma が一般提供済みのサービスだけで構築した本番 MLOps アーキテクチャの2本立てでした
- 何が変わったか:
- BigQuery 上のノートブック整理が、ファイル/フォルダ階層と Inline Git で IDE 並みになった
- SQL セル、ノーコード可視化、Data Apps によって、ノートブック1枚で取り込みから共有まで完結できるようになった
- Vertex AI Workbench、Analytics Hub、VPC Service Controls の組み合わせで、規制業界でも実データのまま ML を回せる構成が GA 部品だけで実現可能になった
- 具体的に何が嬉しいか: 例えば、これまでは BigQuery のデータを Python kernel に読み込みすぎてカーネルが落ちる問題がありました。SQL Cells と BigQuery DataFrames を使えば、結果セットがサーバ側に残ったまま大量行を扱えます
- 一番強い主張: 規制下の MLOps では、セキュリティを手順ではなく仕組みで担保する。抜け道を事故でも作れない設計にする。これが Credit Karma の核心メッセージでした
- 印象的だった事例: Credit Karma が本番投入後に達成した、メンバーのサブスクリプション操作 +20%、解約アクション +36% という数字
Colab Enterprise は Gemini Enterprise Agent Platform のどこにいるか
このセッションの最初は、全体像の整理から始まります。これまで Vertex AI と呼ばれていたものは、今回 Gemini Enterprise Agent Platform にブランド統合されました。Gemini Models や Model Garden、トレーニング/サービング/チューニング、Colab、MLOps、Grounding/Search/RAG といった既存のコンポーネントは、Build レイヤーの「Tools, data, and other agents」の中に位置付けられています。
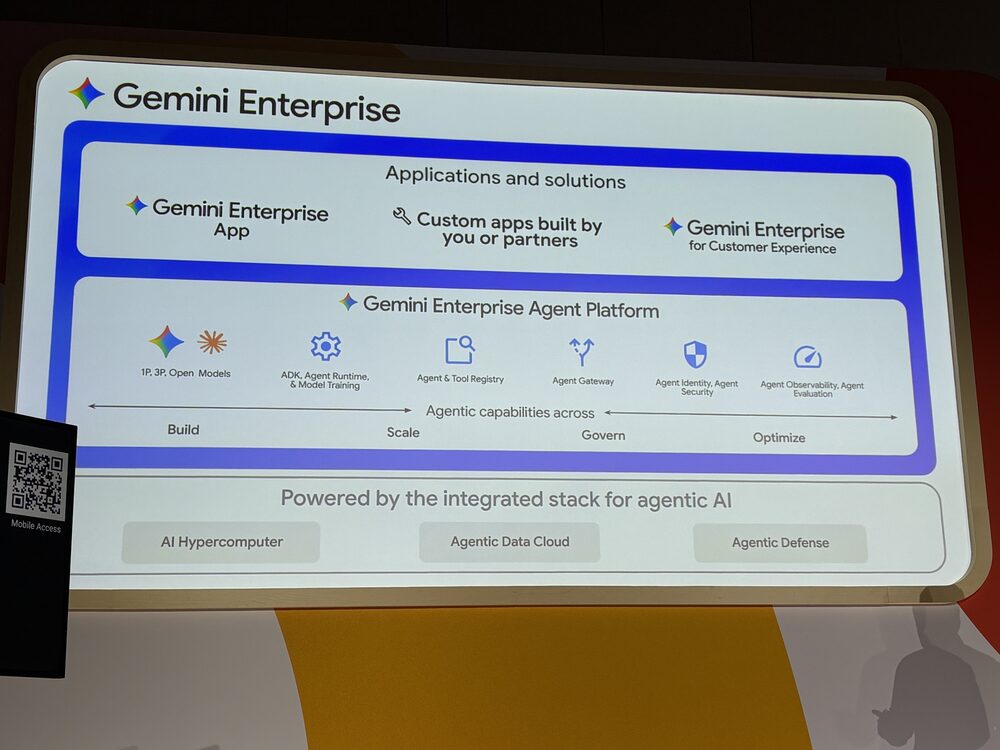
ポイントは、エージェント時代になっても従来のデータサイエンスや ML のワークフローは消えないどころか、むしろ重要度が増している、というところです。意図的にトークンを大量消費するエージェントを使わずとも、決定論的に動く予測モデルが既にあるなら、エージェントはそれをツールとして呼び出せばいい、という整理です。
そのうえで示された問題意識は、データの取り込みから可視化、モデル作成からモニタリングまでの高頻度タスクを一つの環境で完結させたい、というものです。
フルスタック化が進んだ結果、一人のデータサイエンティストがこの全工程を回すケースが増えていて、ツール間のコンテキストスイッチが人的コストを直接押し上げてしまうわけです。

Google Cloud のノートブック環境は Colab Enterprise と Vertex AI Workbench の二択で、本セッションでは前者に焦点が当たります。Colab Enterprise は設定項目が少なく、入ったらすぐ作業を始められることを優先した管理環境です。
Colab Enterprise の新機能
ここからは Colab Enterprise の新機能を順に見ていきます。Code Management、SQL Cells、Visualization Cells、Data Apps、Runtimes、Scheduling、Data Science Agent の7つです。

Code Management
BigQuery 内に新しいファイル/フォルダ管理機能が入りました(GA)。これまで BigQuery 上でノートブックなどのアセットを整理するときは、フラットなリストしかなく階層を持てませんでしたが、今回からファイル/フォルダのマネージャが提供され、IDE と同じようなフォルダ階層でコードを整理できるようになっています。
Developer Connect を経由した Inline Git 連携、Fuse 経由でフォルダをランタイムに自動でマウントする仕組みもサポートされます。

ドラッグアンドドロップでフォルダを動かせる UI のほかに、Team folders という Google Drive の共有フォルダに近い仕組みもあり、チームメンバーを招待して軽量にコラボレーションできます。
登壇では「BigQuery 利用者にとって一番ワクワクする機能」と紹介されていました。BigQuery 中心に開発する人ほど効きそうな改善です。
SQL Cells
ノートブック内で BigQuery 用 SQL を書くための専用セルです(GA)。フォーマット、lint、dry-run(処理されるバイト数の事前確認)に対応していて、BigQuery コンソール内のエディタと同等以上の編集体験になっています。
スキーマと DataFrame のインスペクションパネルがあり、パラメータでセル間のチェイニングやフィルタリングも可能です。
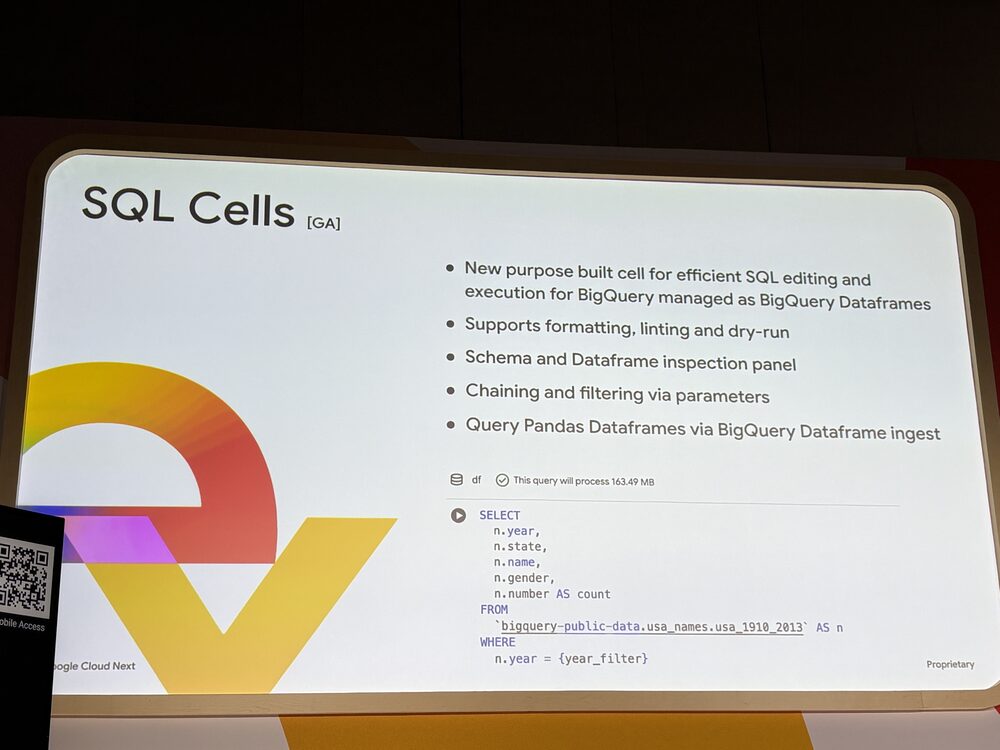
実行結果は BigQuery DataFrames として扱われ、Pandas DataFrame との混在も自然にできます。
ここがかなり実用的なポイントで、これまで BigQuery のデータを Python kernel にすべてロードしてカーネルを落とすトラブルが頻発していたのが、結果セットがサーバ側に残ったまま 5,000 行でも 5,000 万行でもクエリできるようになります。SQL と Pandas を同じノートブックの中で自然に行き来できるようになった、という感覚ですね。
Visualization Cells
Data Studio(旧 Looker Studio)を使ったノーコード可視化セルです(GA)。ウォーターフォール、散布図、ファネルなど30種類以上のチャートタイプがあり、BigQuery DataFrames と Pandas DataFrame のどちらにもバインドできます。
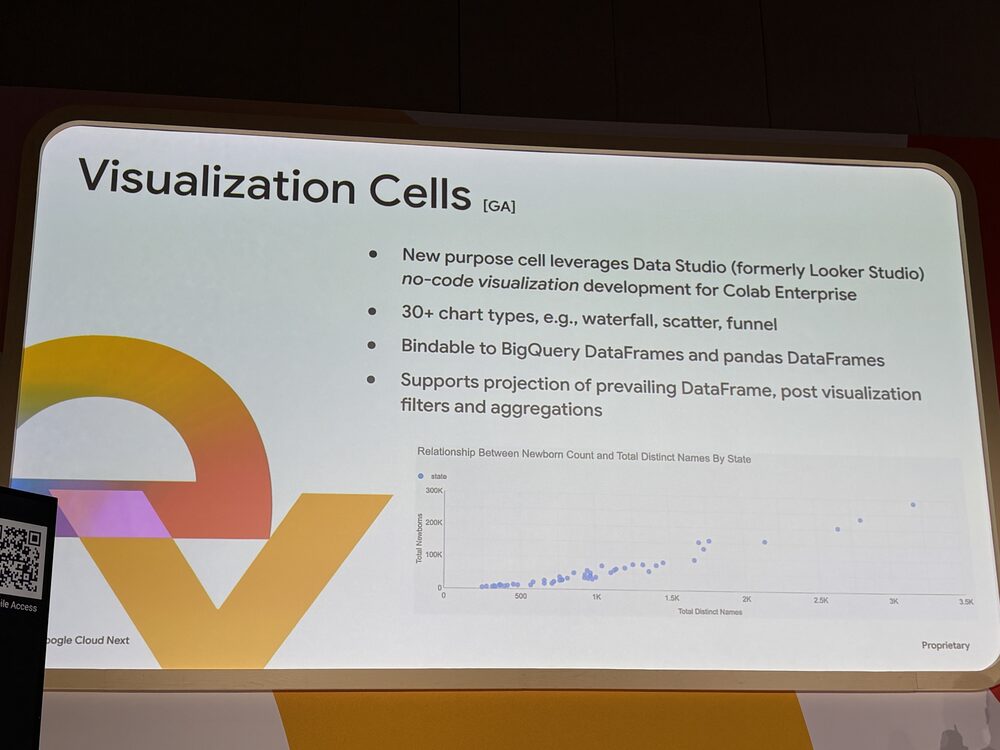
可視化したあとに、その上でフィルタや集計をかけることもできるので、表形式の出力から1ステップで分布やトレンドを確認するといった使い方が、コードを書かずにできます。SQL Cells で取った結果をそのまま Visualization Cells に渡せて、ノートブック内で完結します。
Data Apps
ノートブックの中で作った可視化や対話的コントロールを、そのままアプリとして公開できる機能です(Public Preview)。任意の Python ライブラリが使えて、ノートブックのコンポーネントを WYSIWYG インターフェイスで組み立てられます。
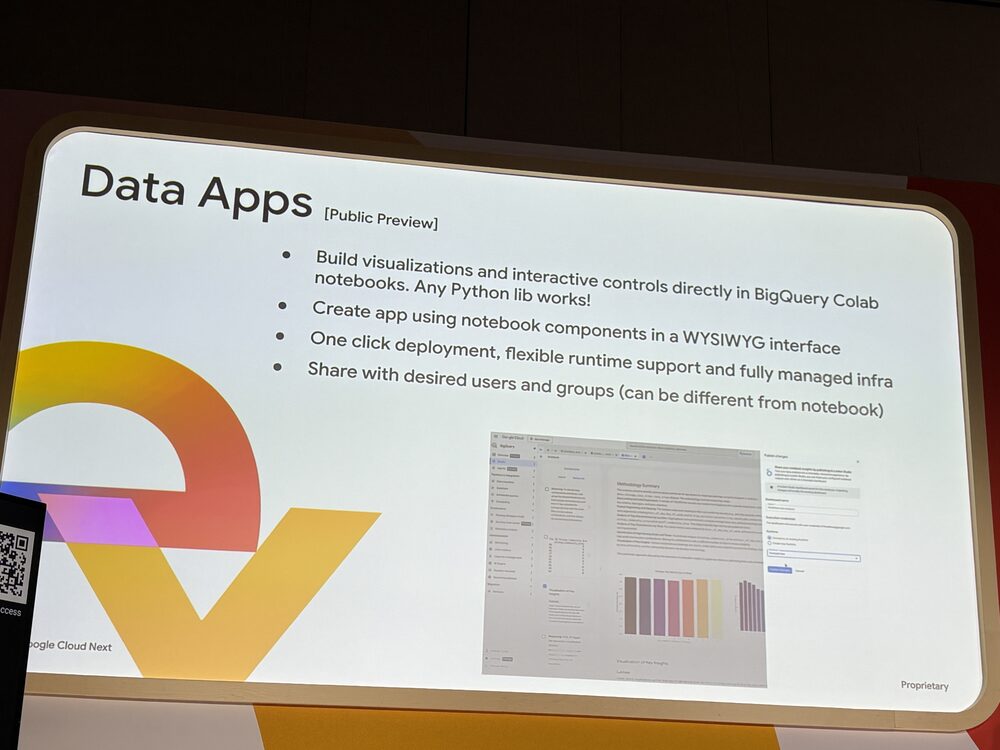
ワンクリックでデプロイ、ランタイムも柔軟に選べて、共有先はノートブックの共有設定とは独立して指定できます。データサイエンティストがビジネスパートナーに分析結果を渡すときに、ノートブックを直接共有するのではなく、必要な可視化とコントロールだけを切り出した小さなアプリにして渡せるのが嬉しいところです。
Runtimes
ランタイム周りの強化です(GA)。Python kernel の選択(N-2 まで)、Post-Startup スクリプトの実行、環境変数の注入が可能になっています。
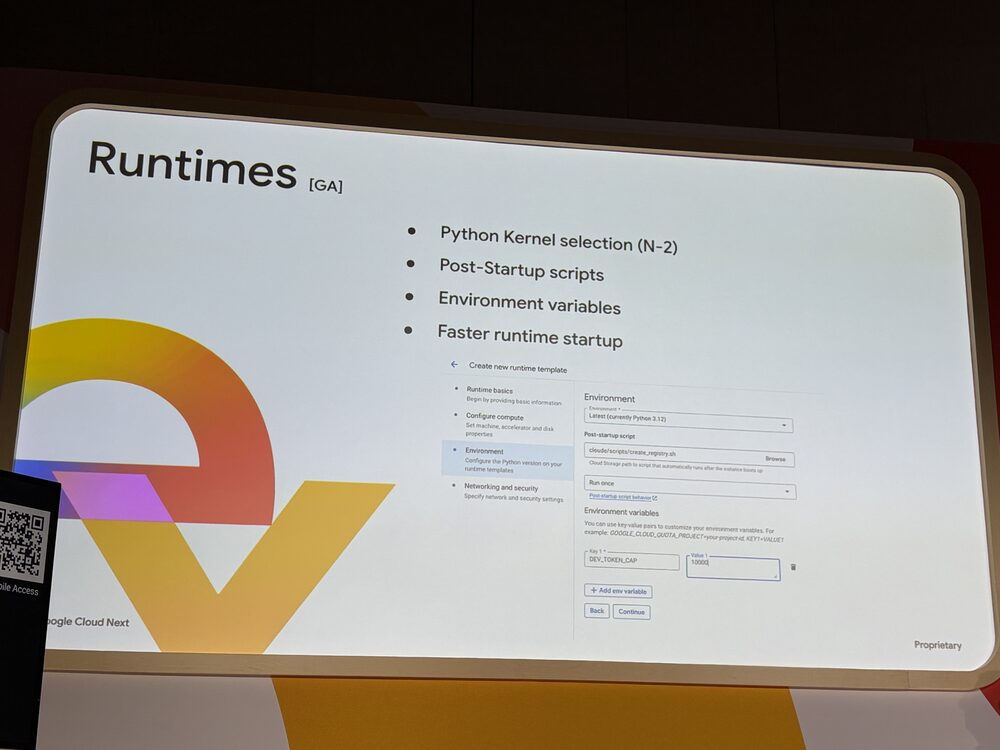
カーネルの起動時間も短縮されていて、おおむね50〜60秒で起動し、デフォルトで17時間稼働します。Post-Startup スクリプトは、たとえばノートブック起動時に共通のセットアップを流したいケースで使えますし、環境変数も組み合わせるとパラメータ化されたノートブックを作りやすくなります。
Scheduling
ノートブックのスケジュール実行機能です。Notebook scheduler 自体は既に GA で、今回新しく End User Credentials(EUC)とサービスアカウント認証が Public Preview として加わりました。Vertex のスケジューラと BigQuery のスケジューラのどちらからでも実行できます。
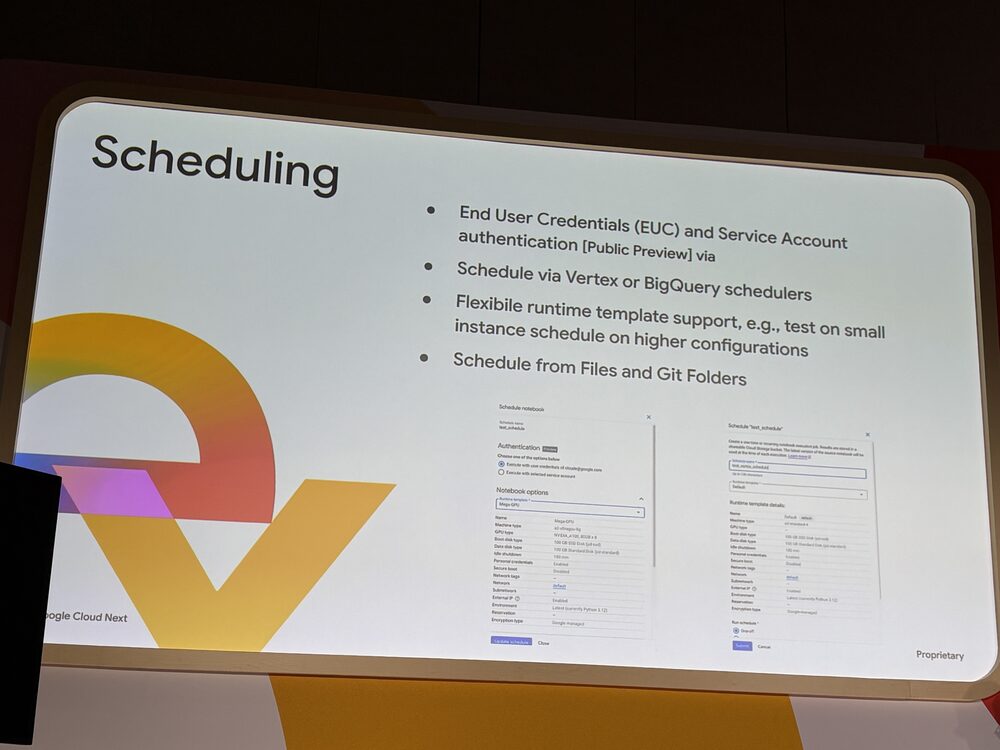
実行時のランタイムテンプレートを柔軟に切り替えられるのが地味に効くところで、開発時は小さいインスタンスでテストして、スケジュール実行のときだけ大きい構成にする、といったことができます。
スケジュール対象はファイル単位だけでなく Git フォルダも指定可能です。
コンプライアンス要件で実行 ID を人間ではなくサービスアカウントに紐付けたい、というケースは EUC とサービスアカウント認証で対応できます。
Data Science Agent
ノートブックに組み込まれたエージェントプランナーです(Public Preview)。BigQuery データセットに最適化されていて、データサイエンスのタスク(クラスタリング、可視化、モデリングなど)を計画して進めてくれます。

セッションのデモは、自分の手でコードを書く方の進め方でした。プロトタイピングを高速に回したいケースなどでは Data Science Agent を呼び出せばよく、自分で書きたいときとエージェントに任せたいときで使い分けられます。
Credit Karma の事例
ここからは Credit Karma の事例です。「セキュリティは仕組みで作る、手順で作らない」(Secure by Architecture, Not by Policy) と題された、規制業界における MLOps アーキテクチャの再設計の話です。
規制された ML チームの “Impossible Choice”
Credit Karma は1.4億メンバー超を抱える金融サービスで、Money Management、Marketplaces、Credit Building、Credit Karma Money といった複数領域のプロダクトを ML が支えています。トランザクションの分類、クレジットオファーのレコメンデーション、AI エージェントの評価、いずれも保護対象の金融データが必要で、データ保護違反は許されません。

そういう環境で、これまで規制下の ML チームには2つの選択肢しかありませんでした。
ひとつは、データへのアクセスを厳しく制限するやり方。サンプルデータでモデルを学習することになるため、精度が落ちて、プロダクト側のシグナルを取りこぼします。Raj 氏はこれを 「データは守れているが、何も見えていない」(Safe but Blind) と呼んでいました。
もうひとつは、データへのアクセスを開放するやり方。ただしセキュリティレビューに3〜6ヶ月かかり、その間は ML の速度がゼロになって市場機会を逃します。これを 「規則は守れているが、何も進まない」(Valid but Bottlenecked) と表現していました。
この板挟みをどう埋めるか、というのが Credit Karma が向き合った問いでした。
ステージではなく機能で環境を分ける
従来のインフラ分割は Dev / Staging / Prod のステージ単位でした。問題は、各ステージにデータ・デプロイ・検証がすべて詰め込まれていて、データサイエンティストが複数の環境にアクセスできてしまう点です。たとえば Dev で作ったアーティファクトが、Staging のバリデーションをスキップして Prod に流れる、といった事故が起きうる構造になっています。

これをポリシーやチェックリストで防ごうとすると、必ず速度が落ちます。10項目のチェックを通過しないと次に進めない、という運用は、結局「規則は守れているが、何も進まない」側に倒れます。
そこで Credit Karma が選んだ解決策が、ステージで分けるのではなく機能で分けることでした。ML ライフサイクルの機能を Experimentation(実験) / Automation(自動化) / Validation(検証) の3つに切り出して、それぞれを物理的に分離した環境として再設計します。各環境はひとつの目的だけに最適化されていて、それがアーキテクチャで強制される、という構成です。

Experimentation はデータサイエンティストが探索する場所、Automation は CI/CD トリガで本番パイプラインを動かす場所、Validation は5つのチェック(品質、フェアネス、データ保護、統計分析、カスタムドメインルール)を通過した署名済みアーティファクトだけを次工程に出す場所、という分け方になっています。
各機能を独立して最適化できるのが大きな利点で、Experimentation 側でいろいろ試行錯誤しても Automation や Validation には一切影響しません。
データは動かさず、コードを動かす
Experimentation 環境の中身を細かく見ると、独特なところがあります。データそのものは Analytics Hub の ゼロコピーリンクされたデータセットとして参照されるだけで、提供元(パブリッシャ)に残ったまま動きません。データサイエンティストが触れるのは、リンク経由で読みに行ける BigQuery のクエリだけです。
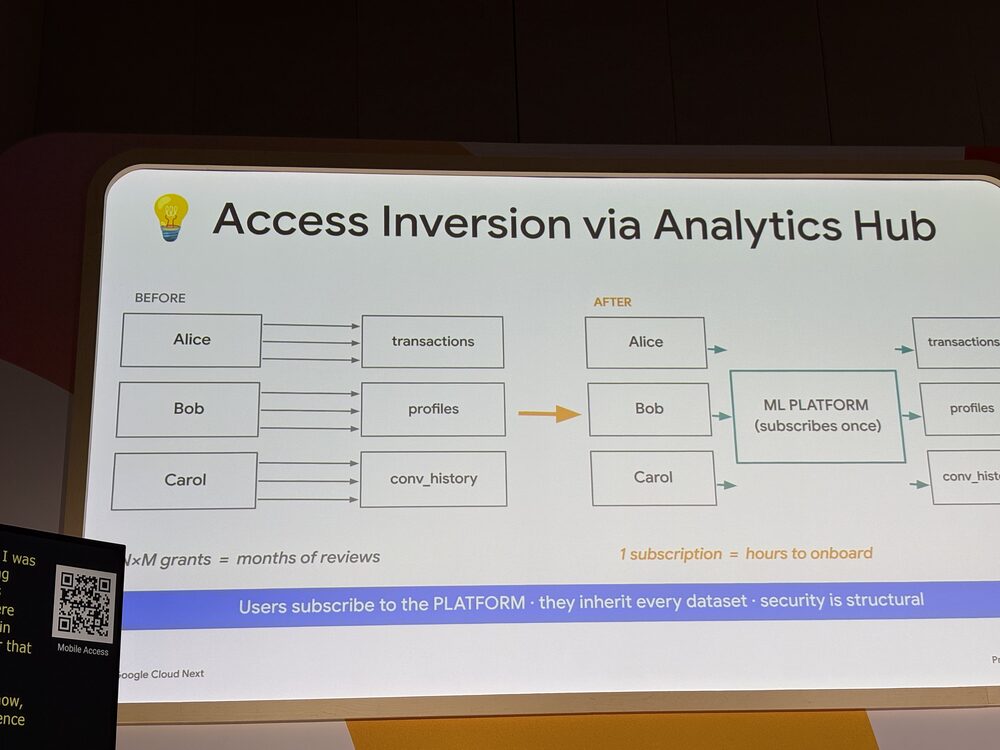
ここで効いてくるのが Access Inversion という考え方です。従来は N人 × M データセットの権限付与で、何ヶ月もレビューが続いていました。アリス、ボブ、キャロルが10個のデータセットにアクセスするには、3 × 10 = 30件のアクセスレビューが必要です。
これを、ML プラットフォームが代理で1回だけ Analytics Hub を購読する形に変えることで、データサイエンティストはプラットフォームに所属するだけで全データセットにアクセスできるようになります。1回の購読登録だけで、数時間でオンボードが完了します。ユースケースが終われば、プラットフォームごと破棄してアクセスも一括で消えます。
そして Experimentation 環境からは、データはもちろんファイルすら出ていけません。VPC Service Controls が外部ネットワークへの egress を完全にブロックしていて、curl は HTTP 403、scp は connection timed out で止まります。Hugging Face からモデルをダウンロードしようとしても、外に出るルート自体が存在しません。これは「ポリシーで禁止」ではなく「アーキテクチャで不可能」になっている状態です。

唯一この環境から出てくるのは、Git 経由のコードだけです。Pull Request → Code Review → Merge を経て、別の GCP プロジェクトの Vertex AI Pipelines がそのコードを引き取って、同じ BigQuery を独立に再読み込みします。
データは元の場所から一度も動いていません。Production 側は本番側のクレデンシャルで自分でデータを取りに行く、という独立性があります。これが 「コードは動く、データは動かない」(Code Moves. Data Doesn’t.) の中身ですね。
ML Platform SDK が環境を抽象化する
ここまでの仕組みは、データサイエンティストには見えません。データサイエンティストが書くコードは同じ5行だけです。
from ml_core import MLPlatformContext
ctx = MLPlatformContext.detect()
model = (
ctx.load_data('transactions_v2')
.preprocess()
.train(XGBoostConfig())
)
ctx.save_model(model, 'txn_categorizer')

ポイントは MLPlatformContext.detect() で、SDK が実行コンテキストを自動検出します。
Vertex AI Workbench の中で動いていれば Experimentation モードになり、load_data() は BigQuery のリンクデータセットから読み取り専用でロードし、save_model() はエフェメラルな GCS バケットに保存されます。
Vertex AI Pipelines(CI/CD)で動いていれば Automation モードに切り替わり、load_data() は同じ BigQuery を新規に再読み込みし、save_model() は署名済みアーティファクトを生成して Export Validation をトリガします。
同じ5行のコードが、まったく異なるインフラ上でまったく異なる挙動をする。データサイエンティストは環境のことを気にしなくていい、という形で抽象化できています。
結果と、3つの原則
このプラットフォームを本番投入したあとの数字が、かなり印象的です。

メンバーのサブスクリプション操作が 20%増加、解約アクションが 36%増加しました。解約アクションが伸びた背景には、従来サンプルデータでは見えていなかった定期課金のパターン(請求サイクルが不規則なものなど)が拾えるようになったことがあるそうです。全件のトランザクション履歴をモデルに見せられるようになった、ということですね。
AI エージェントの評価精度も大きく改善しました。
ただしここで強調されていたのは、これらは「性能改善」ではなく Previously Impossible(従来は不可能だったこと)だ、という点です。サンプルデータでどれだけチューニングしても、全件のデータが取れなかった以上、この水準には到達できなかった、ということでした。

最後に持ち帰るべき3原則として、以下が示されました。
- Separate by Function, Not by Stage(機能で分ける、ステージで分けない): Experimentation、Automation、Validation のそれぞれが Dev、Staging、QA とは別物として、ひとつの目的だけに最適化される。アーキテクチャで強制される。
- Code Moves. Data Doesn’t.(コードは動く、データは動かない): データサイエンティストはコードを書く、Git がそれを運ぶ、各環境は独立にソースデータを読み直す。抜け道は事故でも作れない。
- Security is a Platform, Not a Process(セキュリティは仕組みで担保するもので、手順では担保できない): 深夜2時に追い込まれた状況で人間が手順を守ることに頼ったセキュリティは破綻する。アーキテクチャでセキュアな道を唯一の道にする。
そしてもうひとつ、忘れてはいけないのが、このアーキテクチャで使われている GCP コンポーネントはすべて GAであることです。Vertex AI Workbench や Vertex AI Pipelines、VPC Service Controls、Analytics Hub など、Private Preview や experimental API は含まれていません。「来四半期から構築できる」というのが締めの言葉でした。
ステータス表
本記事で扱った Colab Enterprise の機能のステータスを以下にまとめます。
| 機能 | ステータス |
|---|---|
| Code Management | GA |
| SQL Cells | GA |
| Visualization Cells | GA |
| Data Apps | Public Preview |
| Runtimes | GA |
| Scheduling(本体) | GA |
| Scheduling の EUC・サービスアカウント認証 | Public Preview |
| Data Science Agent | Public Preview |
おわりに
個人的に刺さったのは、Credit Karma の「セキュリティはプロセスではなくアーキテクチャ」という言い切りでした。
チェックリストを増やすことでセキュリティを担保しようとすると、結局チェックリスト自体が形骸化するか、速度が死ぬか、どちらかになります。VPC Service Controls と Analytics Hub と SDK を組み合わせて「やってはいけないことが物理的に発生しない構成」を作り込むのは、思想として強いです。
しかも、Credit Karma の事例は規制下の MLOps というかなりピンポイントな課題に対する解決策ではあるのですが、「ステージで分けるのではなく機能で分ける」という発想は、規制業界以外でも応用が効きそうです。本番事故の多くは Dev/Staging/Prod の権限境界が曖昧なところから生まれるので、「環境はひとつの目的にだけ最適化する」という整理は、自分の関わるシステムでも一度頭の整理に使えるなと感じました。
一方で Colab Enterprise の方は、もっと身近な「ツールの行き来」のコストを潰しに来ていて、こちらは明日からでも使い始められる手触りがあります。SQL Cells と Visualization Cells と Data Apps の組み合わせだけでも、ノートブック1枚で完結する分析タスクが一気に増えそうです。
思想と実用、両方の手応えがある、密度の高いセッションでした!




