
Google Cloudのサーバーレスサービスを使ってデータ分析基盤を作りたい——そう考えている方に向けて、本記事では Cloud Run functions(旧Cloud Functions)・BigQuery・Eventarc・Terraform を組み合わせたサーバーレスETLパイプラインの構築方法を、実例とともに解説します。
題材には国土交通省のオープンデータ(不動産取引価格情報)を使い、東京・大阪・愛知・福岡の主要4都市・約146万件のデータを分析しました。CSVをアップロードするだけで自動的にBigQueryへ取り込まれる仕組みを、つまずいたポイントも含めて紹介します。
目次
- この記事で作るもの・対象読者
- アーキテクチャ全体像と仕組みの解説
- データソース:国交省オープンデータの使い方
- TerraformでGoogle Cloudインフラを構築する方法
- Cloud Run functionsでETLを自動化する方法
- BigQueryのテーブル設計とパーティション
- Data Studio(旧Looker Studio)で可視化する方法
- データ分析の結果:4都市の不動産価格動向
- 設計の振り返りと改善点
- まとめ
1. この記事で作るもの・対象読者
本記事で構築するのは、「CSVファイルをCloud Storageに置くだけで、自動的にデータがBigQueryに取り込まれ、ダッシュボードで可視化される」 という一連のサーバーレスETLパイプラインです。
データ分析基盤の構築というと大掛かりに聞こえますが、Google Cloudのサーバーレスサービスを組み合わせることで、サーバーの管理を一切せず、低コストで実現できます。
この記事の対象読者
- Google Cloudでデータ分析基盤を構築したいエンジニア
- Cloud Run functions・BigQuery・Terraformの実践例を知りたい方
- サーバーレスなETL処理の設計を学びたい方
使用するGoogle Cloudサービス
| サービス | 役割 |
|---|---|
| Cloud Storage | CSVファイルの保管 |
| Eventarc | ファイルアップロードの検知 |
| Cloud Run functions(旧Cloud Functions) | データ変換・加工(ETL処理) |
| BigQuery | データの蓄積・集計 |
| Data Studio(旧Looker Studio) | ダッシュボードによる可視化 |
| Terraform | インフラのコード管理(IaC) |
不動産データは国土交通省「不動産情報ライブラリ」にも公式の地図表示機能があります。本記事では自前で分析基盤を持つことで、任意の集計軸で自由に分析できる構成を目指しました。公式ツールでは固定の集計しかできませんが、自前のBigQuery基盤があれば「築年数別の価格」「駅距離別の単価」など、好きな切り口で分析できるのが強みです。
2. アーキテクチャ全体像と仕組みの解説
まず、今回構築したシステムの全体像を見てみましょう。
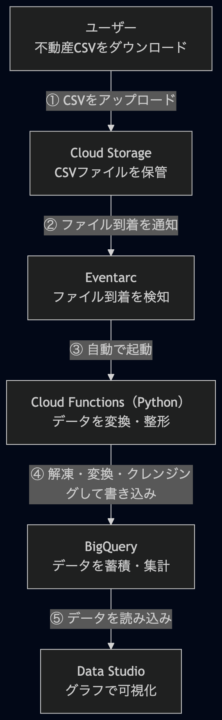
図1:Google CloudサーバーレスETLパイプラインの全体構成
このパイプラインはどう動くのか
処理の流れはシンプルです。
- ユーザーがCSV(ZIP形式)をCloud Storageにアップロードする
- Eventarcがアップロードを検知し、Cloud Run functionsを起動する
- Cloud Run functionsがZIPを解凍し、データを整形してBigQueryに書き込む
- Data StudioがBigQueryのデータを可視化する
ユーザーが手を動かすのは「CSVをアップロードする」ところだけ。それ以降はすべて自動で進みます。
なぜ「サーバーレス・イベント駆動」を選んだのか
このパイプラインの肝は 「イベント駆動」 という考え方です。
従来のバッチ処理では「毎日深夜2時に実行する」のようにスケジュールを組むのが一般的でした。決まった時間にサーバーが起動し、処理がない時間帯もサーバーは待機しているため、その分のコストがかかります。
しかし今回は、Cloud StorageにCSVが置かれた瞬間をEventarcがキャッチして、Cloud Run functionsを起動します。この方式には以下のメリットがあります。
- コスト効率が良い:サーバーを24時間起動しておく必要がなく、処理が必要な瞬間だけリソースが使われます。アイドル時間のコストがゼロです。
- 即時性がある:ファイルを置けばすぐに処理が始まります。
- スケーラブル:複数ファイルを同時に置けば、自動的に並列処理されます。1ファイルでも100ファイルでも、仕組みは同じです。
「サーバーレス」とは、サーバーの管理から解放されるという意味です。「サーバーを何台用意して、メモリをいくつ割り当てて、OSのパッチを当てて……」と考える必要はなく、処理が必要なときだけGoogleが自動でリソースを確保し、終われば解放してくれます。インフラ管理の手間が劇的に減るのが、サーバーレス構成の最大の魅力です。
3. データソース:国交省オープンデータの使い方
データは国土交通省「不動産情報ライブラリ」から取得しました。会員登録不要で、誰でも無料でCSVをダウンロードできます。2024年4月に旧「土地総合情報システム」の後継として公開されたサイトで、不動産の取引価格情報や地価公示などが一元的に提供されています。
データの取得条件
| 項目 | 内容 |
|---|---|
| 対象都府県 | 東京都・大阪府・愛知県・福岡県 |
| 対象期間 | 2020年Q1〜2025年Q4(6年・24四半期) |
| 種別 | 宅地(土地及び土地と建物)・中古マンション等 |
| 合計件数 | 約146万件 |
データ取得時に知っておくべき特徴
- 文字コードがShift-JIS:行政データに多い形式です。BigQueryの標準であるUTF-8への変換が必要になります。
- アンケート調査ベース:実際の取引当事者へのアンケートに基づくため、全取引が網羅されているわけではありませんが、市場のトレンド把握には十分な量です。
- 粒度は市区町村まで:個人情報保護の観点から、番地レベルの所在地は含まれません。
これらの特徴は、後続のETL処理(特に文字コード変換とデータクレンジング)の設計に直結します。
本記事のデータは、国土交通省「不動産情報ライブラリ」(https://www.reinfolib.mlit.go.jp/)の不動産取引価格情報を加工して作成しています。
4. TerraformでGoogle Cloudインフラを構築する方法
インフラはすべてTerraformでコード管理(IaC:Infrastructure as Code)しました。手動でGUIを操作するのではなく、コードで構成を定義することには大きなメリットがあります。
なぜTerraformを使うのか
- 再現性:同じコードから何度でも同じ環境を作れます。手作業による属人化やミスがなくなります。
- 一括削除が簡単:
terraform destroyコマンド一発で、作成したリソースをすべて綺麗に削除できます。 - 変更履歴が残る:コードをGitで管理すれば、いつ・誰が・どんな変更をしたかが明確になります。
モジュール構成と必要なAPIの有効化
機能ごとにモジュールを分割し、メインの設定ファイルから呼び出す構成にしました。冒頭で必要なGoogle CloudのAPIをまとめて有効化しています。
resource "google_project_service" "apis" {
for_each = toset([
"cloudfunctions.googleapis.com",
"eventarc.googleapis.com",
"bigquery.googleapis.com",
"storage.googleapis.com",
"cloudbuild.googleapis.com",
"run.googleapis.com",
"artifactregistry.googleapis.com",
"pubsub.googleapis.com",
"iam.googleapis.com",
"compute.googleapis.com",
])
service = each.value
disable_on_destroy = false
}
このAPIリストを見ると、「サーバーレス」と一言で言っても、裏ではCloud Build・Artifact Registry・Cloud Run・Pub/Subなど多くのサービスが連携していることが分かります。Terraformのstorage・bigquery・iam・functionsの各モジュールは、これらのAPIが有効化された後に実行されるようdepends_onで依存関係を定義しています。
ハマりポイント①:Cloud Build のデフォルトSA問題
ここで最初の落とし穴にぶつかりました。
Cloud Run functions(旧Cloud Functions)は、デプロイ時に内部でCloud Buildを使ってコンテナイメージをビルドします。このときCloud Buildは、デフォルトでCompute Engineのサービスアカウントを使います。
ところがこのサービスアカウントは、Compute Engine APIを有効化してから数分後に自動作成されるものです。そのため、TerraformでAPI有効化からデプロイまでを一気に実行すると、サービスアカウントの作成が間に合わずデプロイが失敗してしまいました。
解決策: ビルド用のサービスアカウントを、自前で用意したETL用のサービスアカウントに明示的に指定することで、デフォルトSAへの依存をなくしました。これによりタイミング問題を回避できただけでなく、ビルドに使う権限を最小限に絞れるというセキュリティ上のメリットも得られました。
「サーバーレスだから手軽」と思いきや、Cloud Run functionsは裏で複数のサービスと連携しています。その暗黙の依存関係を理解しておくことが、Terraform管理では重要だと学びました。
5. Cloud Run functionsでETLを自動化する方法
CSVをCloud Storageにアップロードすると、Eventarcがイベントを検知してCloud Run functionsが自動起動します。
エントリポイントの実装
CloudEvent形式でイベントを受け取り、データを宅地とマンションに振り分けてBigQueryに書き込みます。全体の流れがこの関数に集約されています。
@functions_framework.cloud_event
def process_upload(cloud_event: CloudEvent) -> None:
data = cloud_event.data
bucket_name = data["bucket"]
object_name = data["name"]
# GCSからファイルを取得して読み込み
df = load_from_gcs(bucket_name, object_name)
# クレンジングして宅地・マンションに分割
house_df, mansion_df = transform(df)
# それぞれ該当するBigQueryテーブルへ書き込み
if len(house_df) > 0:
insert(house_df, PROJECT_ID, DATASET_NAME,
"transactions_house", "residential_schema.json")
if len(mansion_df) > 0:
insert(mansion_df, PROJECT_ID, DATASET_NAME,
"transactions_mansion", "mansion_schema.json")
並列処理の仕組み
8つのファイルを一括アップロードすると、Eventarcが8つのイベントを発火し、複数のCloud Run functionsが並列で起動します。それぞれが独立して処理するため、ファイル数が増えても全体の処理時間は大きく変わりません。今回は約146万件のデータが、わずか数分ですべてBigQueryに投入されました。
ハマりポイント②:データ型の変換エラー
2つ目の落とし穴は、データ型の変換でした。最初のアップロードで、BigQueryへの書き込み時にこんなエラーが大量に発生しました。
Error converting Pandas column with name: "取引時期_DATE"
and datatype: "object" to an appropriate pyarrow datatype原因: 「2025年第2四半期」という文字列をDATE型に変換する処理で、変換後の値がdatetime.dateオブジェクトではなく文字列のままになっていました。pandasのカラムの型(dtype)がobjectのままで、BigQueryのDATE型へのロード時にPyArrowが型変換に失敗していたのです。
解決策: 四半期の文字列を、明示的にdatetime.dateオブジェクトに変換する処理を実装しました。
_QUARTER_MONTH = {"第1四半期": 1, "第2四半期": 4, "第3四半期": 7, "第4四半期": 10}
def _quarter_date(val):
"""取引時期 "2025年第2四半期" を datetime.date(2025, 4, 1) に変換する。"""
if pd.isna(val) or str(val).strip() == "":
return None
m = re.match(r"(\d{4})年(第[1-4]四半期)", str(val).strip())
if not m:
return None
month = _QUARTER_MONTH[m.group(2)]
return datetime.date(int(m.group(1)), month, 1)
df["取引時期_DATE"] = df["取引時期"].apply(_quarter_date)
ポイントは、文字列ではなくdatetime.dateオブジェクトを返すことです。データ処理ツールからデータウェアハウスへデータを移す際は、カラムの型を移送先のスキーマに正確に合わせておくことが重要だと痛感しました。
ハマりポイント③:行政データならではの表記ゆれ
国交省のデータには、機械的に処理しづらい表記がいくつかありました。たとえば最寄駅までの距離が「30分?60分」のような範囲表記になっているため、中央値を取る処理を入れました。
def _station_distance(val):
"""最寄駅距離の範囲表記("30分?60分")を中央値(int)に変換する。"""
if pd.isna(val) or str(val).strip() == "":
return pd.NA
val = str(val).strip()
m = re.match(r"(\d+)分[??](\d+)分", val)
if m:
return (int(m.group(1)) + int(m.group(2))) // 2
try:
return int(float(val))
except (ValueError, TypeError):
return pd.NA
同様に、面積の「5000㎡以上」という上限表記や、建築年の「戦前」という文字列も、それぞれ数値化する処理を加えています。実データを扱うと、こうした「想定外の値」との戦いが必ず発生します。
設計上の注意:WRITE_APPENDによる重複リスク
ハマりポイントとは別に、本番運用に向けて意識しておくべき設計上のポイントを1つ紹介します。
今回のloaderでは、BigQueryへの書き込み設定をWRITE_APPEND(追記)にしています。
job_config = bigquery.LoadJobConfig(
schema=_load_schema(schema_file),
write_disposition=bigquery.WriteDisposition.WRITE_APPEND,
)
これは検証用途では十分動きますが、本番運用では注意が必要です。同じCSVを再投入すると重複データが発生しますし、Eventarcは「少なくとも1回」配信の仕様のため、ユーザーが1回しかアップロードしなくてもインフラ側の都合で重複イベントが発生する可能性があります。
本番運用では、一時テーブルへの書き込みと主キーでの重複排除(MERGE文など)を組み合わせた冪等な設計が必要です。
6. BigQueryのテーブル設計とパーティション
BigQueryはクエリ料金が「スキャンしたデータ量」に比例する従量課金です。そのため、テーブル設計次第でコストが大きく変わります。
パーティションとクラスタリングでコストを最適化
今回は「取引時期でパーティション分割」「都道府県・市区町村でクラスタリング」という設計にしました。
- パーティション:データを取引時期ごとに区切って保存します。「2024年のデータだけ見たい」というクエリで、2024年のパーティションだけがスキャンされます。
- クラスタリング:パーティション内でさらに都道府県・市区町村ごとに整理します。「東京都だけ」のような絞り込みが効率化されます。
この設計により、無駄なデータ読み込みを避けられます。実際、今回の規模(約146万件)であれば、BigQueryのストレージもクエリも無料枠の範囲内に収まり、運用コストはほぼゼロでした。
宅地とマンションでテーブルを分けた理由
不動産データには「宅地(戸建・土地)」と「中古マンション」がありますが、両者は持っている情報の項目が異なります。たとえばマンションには「間取り」がありますが、宅地には「前面道路の幅員」「土地の形状」といった項目があります。
性質の異なるデータを無理に1つのテーブルに混ぜると、多くの項目が空欄(NULL)になり扱いづらくなります。そこで今回は、宅地用とマンション用の2つのテーブルに分けて設計しました。可視化の際には、両者を統合したビューを別途用意することで、1つのデータソースとしても扱えるようにしています。
7. Data Studio(旧Looker Studio)で可視化する方法
BigQueryに蓄積したデータを、Data Studioに接続してダッシュボードを構築しました。Data StudioはGoogleが提供する無料のBIツールで、BigQueryとの相性が良く、ノーコードでグラフやダッシュボードを作成できます。
ハマりポイント④:日本語カラム名の非対応
可視化の段階でも落とし穴がありました。
BigQueryのテーブルでは、元データに忠実に「都道府県名」「取引価格_総額」といった日本語のカラム名を使っていました。BigQuery自体は日本語カラム名に対応しています。ところが、Data StudioのBigQueryコネクタは日本語カラム名を正しく処理できず、「無効なフィールド」として扱ってしまうという問題に直面しました。これはGoogle公式ドキュメントにも明記されている既知の制限です。
解決策: 英語のカラム名を付けたビューをBigQuery側に作成し、Data Studioはそのビューに接続するようにしました。たとえば「都道府県名」を「prefecture」、「取引価格_総額」を「total_price」というように、日本語カラムに英語の別名を付けたビューです。
CREATE OR REPLACE VIEW real_estate.transactions_all_en AS SELECT 種類 AS property_type, 都道府県名 AS prefecture, 市区町村名 AS city, 取引価格_総額 AS total_price, 面積_m2_数値 AS area_m2, 取引時期_DATE AS transaction_date FROM real_estate.transactions_all
これにより、データを格納するテーブル層は元データに忠実な日本語のまま残しつつ、BIツールに見せる層は英語にするという、データ基盤でよく使われる役割分担を実現できました。
8. データ分析の結果:4都市の不動産価格動向
ダッシュボードを構築して可視化したところ、興味深いパターンが見えてきました。
東京は「高い」、福岡は「上がっている」
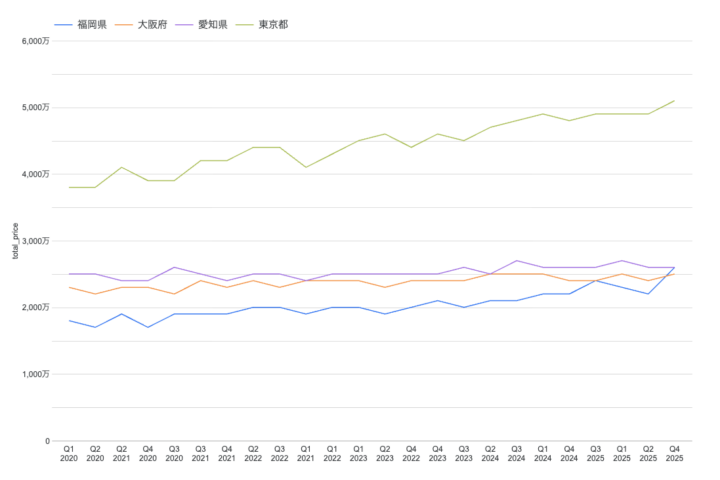
図2:4都市別の不動産価格の時系列推移(2020年〜2025年)
2020年〜2025年の価格推移を見ると、東京都が約3,800万円→約5,100万円と一貫して上昇しています。一方で福岡県は約1,700万円→約2,500万円と、こちらも急激な伸びを見せています。コロナ禍の2020年〜2021年には一時的な揺れが見られますが、その後は全都市で上昇トレンドが続いています。
現在の価格水準:東京の区が上位を独占
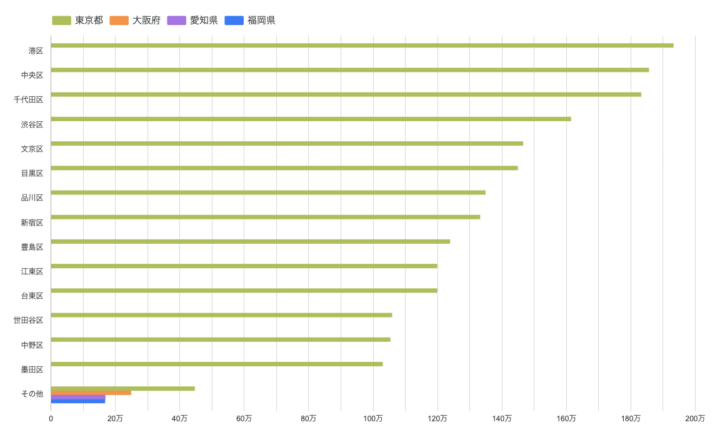
図3:市区町村別の取引価格中央値ランキング(Top20)
市区町村別の取引価格(中央値)Top20を見ると、港区・目黒区・渋谷区など東京の区が上位を独占しています。「やはり東京が高いのか」という、ある意味で予想通りの結果です。しかし、次の上昇率ランキングで意外な事実が判明します。
価格上昇率で逆転:福岡が107%でダントツ1位
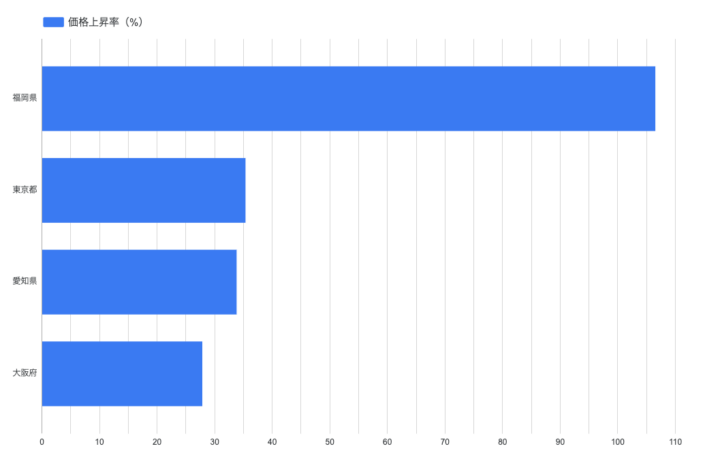
図4:4都市別の価格上昇率
2020年Q1から2025年Q4にかけての価格上昇率を都市別で見ると、結果は予想を裏切るものでした。
| 都府県 | 価格上昇率 |
|---|---|
| 福岡県 | 107% |
| 東京都 | 35% |
| 愛知県 | 33% |
| 大阪府 | 28% |
東京・愛知・大阪が30%前後で揃っているのに対し、福岡だけが100%を超える伸びを見せています。価格水準では他都市に劣る福岡が、伸び率では他を圧倒する——こういう対比が見えてくるのが面白いですね。
市区町村別ランキング:飯塚市(福岡)が突出
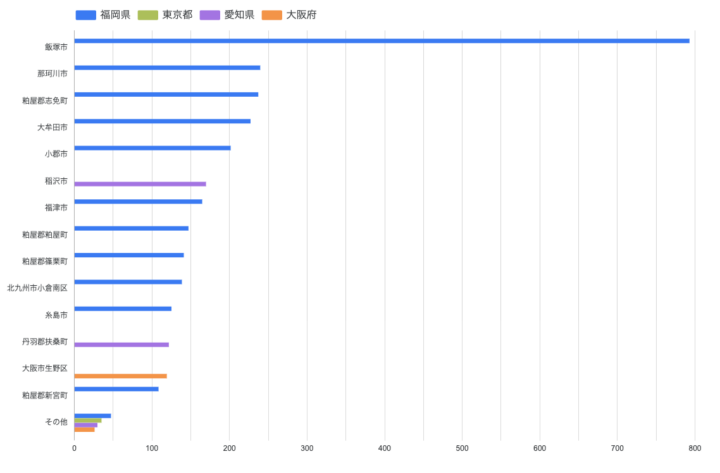
図5:市区町村別の価格上昇率ランキング(飯塚市が突出)
さらに市区町村レベルまで掘り下げて上昇率ランキングを見ると、1位は飯塚市(福岡県)でした。上位には福岡県の市が数多く並び、価格水準では上位を独占していた東京の区は、上昇率ランキングにはほとんど登場しません。
「価格が高いエリア」と「価格が上がっているエリア」は全く別物——これは集計値を眺めているだけでは気づけない、市区町村レベルまで掘り下げて初めて見える発見でした。自前のデータ基盤を持ち、自由な切り口で分析できたからこそ得られた知見です。
9. 設計の振り返りと改善点
実際に作ってみて、いくつか改善すべき点も見えてきました。技術記事として、うまくいった点だけでなく反省点も共有します。
本番運用に向けた改善点
本記事のコードは検証用であり、書いてみて本番運用に向けた改善点も見えてきました。
- 冪等性の確保:今回の実装は同じファイルを再処理すると重複が発生する設計でした。処理済みファイルの記録や、主キーでの重複排除が必要だと感じました。
- エラーハンドリング:1ファイルの失敗が他に波及しない設計ですが、失敗ファイルの再処理機構までは作り込めていませんでした。本番では再処理の仕組みを用意する必要があると感じました。
日本語カラム名は最初から避けるべきだった
BigQueryでは日本語カラム名が使えますが、Data Studioとの連携で詰まりました。元データに忠実であろうとして日本語カラム名を採用したものの、結局BIツール用に英語ビューを作る二度手間が発生しました。データ基盤を設計する際は、最初からBIツールとの互換性を考慮して英語カラム名を採用するのが無難だと感じました。
テーブル命名の改善余地
今回は宅地用テーブルを「house」、マンション用を「mansion」と命名しました。しかし「house(家)」は、実際には土地のみの取引も含む「宅地」全体を指すには不正確な命名でした。テーブル名は後から変更すると影響範囲が大きいため、最初の命名段階で、格納するデータの範囲を正確に表す名前を付けることの重要性を改めて感じました。
10. まとめ
本記事では、Google Cloudのサーバーレス構成(Cloud Run functions・BigQuery・Eventarc)とTerraformを使って、不動産取引データの分析基盤を構築しました。
構築したもの:
- CSVをCloud Storageに置くだけで自動でBigQueryに取り込まれるETLパイプライン
- Terraformによる完全なインフラのコード管理(
terraform destroyで一括削除可能) - Data Studioによるインタラクティブなダッシュボード
コストと拡張性:
約146万件のデータでも、BigQueryのクエリ・ストレージともに無料枠内に収まる規模感で運用できました。また、対象とする都道府県を増やしたい場合も、設定を変更してCSVを追加アップロードするだけで対応できる、拡張性の高い設計になっています。
今回得られた発見:
「東京が一番高い」という当たり前の結果よりも、「福岡が上昇率107%でダントツ1位」「市区町村別では飯塚市が突出」という意外な発見の方が、はるかに面白い結果になりました。データ分析の醍醐味は、こうした「知らなかった事実」との出会いにあると改めて感じます。
Google Cloudでサーバーレスなデータ分析基盤を作りたい方の参考になれば幸いです。


