
はじめに
AWS Summit Japan 2026 の2日目(6/26)に参加し、ブレイクアウトセッション 「Amazon Aurora DSQL Deep Dive ― 内部アーキテクチャの設計思想と実装の勘所」(登壇:永末 健太 様/AWS ソリューションアーキテクト)を聴いてきました。
この記事は、Amazon Aurora DSQL(以下 Aurora DSQL)をまだ使ったことがない初学者の視点で、セッションで語られた内容を私なりに噛み砕いてまとめたものです。
データベースの基本(テーブル、トランザクション、リレーショナルデータベース くらい)が分かる方なら読めるように書きました。
「Aurora DSQL が何をしたいのか」「何ができるようになるのか」という流れは掴めたので、同じく初めて触れる方の入り口になればと思います。
なお、本文の技術的な記述は、聴講メモを AWS 公式ドキュメントと突き合わせて確認しています(出典は末尾にまとめました)。
このセッションの要点(先にまとめ)
- Aurora DSQL は、インフラ管理が不要なサーバーレスの分散SQLデータベース。PostgreSQL 互換。
- マルチリージョンでもプライマリ/セカンダリの区別がなく、アクティブ-アクティブでどこからでも読み書きできる。
- 速さの裏側は、読み取りはスナップショット分離、書き込みはコミット時に Adjudicator が競合を検知する楽観的同時実行制御(OCC)、そして Firecracker の μVM(軽量な仮想マシン)でクエリ処理を高速起動する設計。
- 実装は AWS Lambda と Aurora DSQL のコネクタで繋ぐとリトライが自動。パスワード不要のトークン認証。
- 設計思想は 「Simple by design」。各種の上限は「制約」ではなく安定した性能のための設計で、使いこなしのコツは 「並列・小さく・接続プール」。
なぜ今 Aurora DSQL が注目されているのか(背景)

データベースには昔から「データの正しさ(整合性)」と「スケールしやすさ・止まりにくさ(可用性)」を同時に満たすのが難しい、という悩みがありました。
リレーショナルデータベースは整合性が強い反面スケールさせにくく、特に複数リージョンで「書き込みも整合性も」両立するのは長年の難題でした。
Aurora DSQL は、ここに正面から取り組んだサービスです。
マルチリージョンでどこからでも読み書きできて、かつ強い整合性を保ち、しかもサーバーレスでインフラ管理がいらない。PostgreSQL 互換なので既存の知識も活かせます。
2025年5月に一般提供(GA)が開始され、本番採用を見据えた検証が各所で進んでいることが、注目度の高さにつながっていると感じました。
前提:知っておくと読みやすい用語
- OLTP:注文・決済のような「小さな更新を大量に・即時に」さばく処理。Aurora DSQL が得意とする領域です。
- スナップショット分離(Snapshot Isolation):読み取りが「トランザクション開始時点のデータ」を一貫して見る方式。
- 楽観的同時実行制御(OCC):行ロックでガチガチに止めず、まず処理を進め、コミット時に競合をチェックする考え方。
セッションの中身
1. AWS のデータベースの中での位置づけ
セッションは「実装ポイント」を軸に進みました。まず、AWS のデータベースの選択肢の中での位置づけです。
- Amazon DynamoDB:NoSQL
- Amazon RDS:リレーショナルだが、インフラまわりの作業が必要
- Amazon Aurora、Amazon Aurora Serverless:マネージドで運用が楽になる方向
その先に、「インフラ管理をなくしつつ、複数リージョンで読み書きしたい」というニーズに応えるのが Aurora DSQL、という整理だったと理解しました。
2. マルチリージョンで「主従なし」
特に印象的だったのが、マルチリージョン構成ではプライマリ・セカンダリの区別がないという点です。
両方のリージョンで読み書きでき、データは内部で分散して保持されます。
「どちらが主か」を意識しなくていいのは、これまでのレプリケーションのイメージを更新してくれました。
3. トランザクションはどう処理されるのか
いよいよ本題、トランザクション処理の「中身」です。スライドの流れに沿って追ってみます。
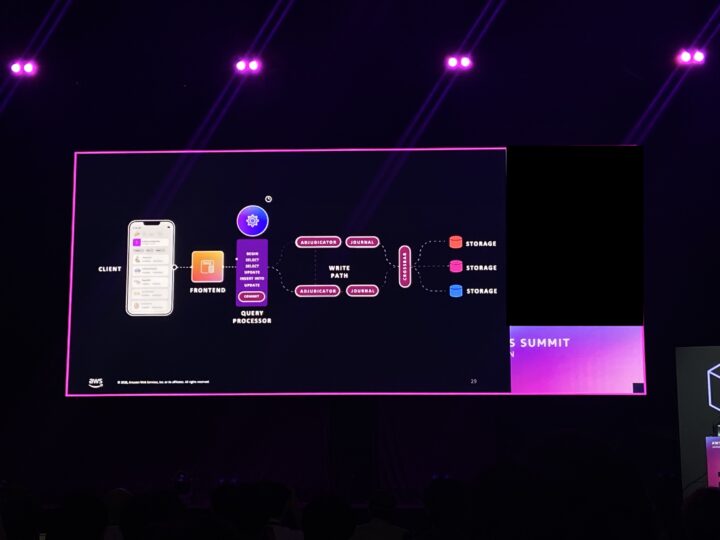
- トランザクション開始時点のデータを見る(スナップショット分離)。
- 書き込みセットはクエリプロセッサ(QP)上に一時的に保持され、QP がトランザクションのペイロードを生成する。
- 同時に実行されている他のトランザクションとの間で、Adjudicatorが書き込みの競合を検知する。
- 競合がなければコミットを続行する。
つまり、行ロックで守るのではなく、コミットの瞬間に競合チェックを回すわけです(楽観的同時実行制御)。初めて聞く私には新鮮でした。
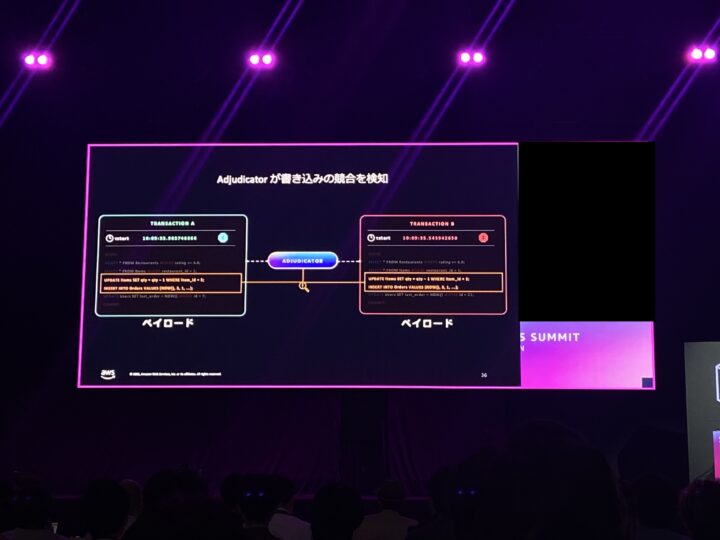

そして永続性(Durability)の持たせ方も従来と違いました。
一般的なデータベースは永続性をストレージレイヤーが担いますが、Aurora DSQL では Journal(ジャーナル)が担う、という説明でした。
4. アーキテクチャ Dive Deep ―「軽くて速い」を支える仕組み
設計の合言葉は 「Simple by design」。アクティブ-アクティブで水平スケールする、という方針でした。
中身を支える要素として、次が紹介されました。
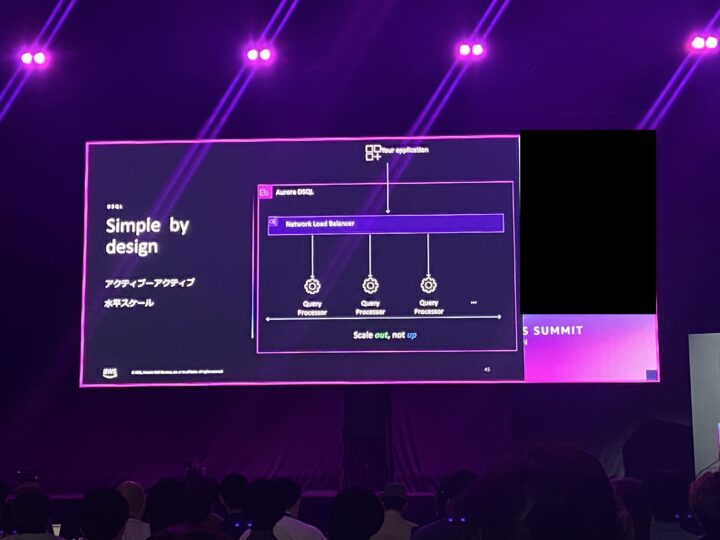
- Firecracker:ハードウェアレベルの仮想化技術。ミリ秒で起動し、オーバーヘッドが最小限。
- Query Processor in Firecracker:クエリプロセッサを μVM で動かす。各 μVM は完全な OS を持つので、接続は低コストである必要がある(だからこそ後述の接続プールが効いてくる、と理解しました)。
- Snapstart:μVM はスナップショットから起動し、メモリページを複数の μVM 間で共有する。だから大量の μVM を素早く立ち上げられる。
- Relay:認証・認可や配置を担う層。
- Zonal routing:同一 AZを優先して選び、障害時は自動でフォールバックする。
「プライマリがない=どこからでも処理できる」ので、レイテンシが安定し、障害時もすぐ別の場所へ切り替わる、という説明が腑に落ちました。
補足(公式ドキュメントより):Aurora DSQL は クエリプロセッサ/Adjudicator/Journal/Crossbar といった独立コンポーネントに分解(disaggregate)され、それぞれが独立してスケールする設計になっています。QP が動く Firecracker は AWS Lambda や AWS Fargate と同じ技術です。
5. アプリからの繋ぎ方(認証と実装)
接続認証はパスワード不要でした。
- パスワード不要
- トークンを使って認証
- 認証トークンは AWS SDK を使ってローカルの高速な暗号処理で生成
- AWS Signature Version 4(SigV4)アルゴリズムを使用
インフラは AWS SAM による Infrastructure as Code、接続プールには JDBC 用ライブラリの HikariCP が例に出ていました。さらに Aurora DSQL のコネクタを使うと、
- IAM トークンの生成を自動処理
- パスワード管理が不要
- 既存の Python / Node.js / JDBC / Go / Ruby / PHP / .NET / Rust のコネクタで動作
- トランザクション競合時のリトライ処理を自動化
となり、HikariCP の接続プールと組み合わせるとシンプルに書けるとのことでした。ORM も Hibernate / SQLAlchemy / Django / Tortoise ORM に対応しています。
考慮事項:主なクォータと“できないこと”
「使う前に知っておくべき制限」も具体的に共有されました。
主なものを表にまとめます(いずれも AWS 公式ドキュメントで確認済み)。
| 項目 | 値 | 変更可否 |
|---|---|---|
| 最大接続数(クラスターあたり) | 10,000 | 可 |
| 最大トランザクション時間 | 5分 | 不可 |
| 最大接続時間 | 60分 | 不可 |
| トランザクション内の最大変更行数 | 3,000行 | 不可 |
| 1書き込みトランザクションの最大変更サイズ | 10 MiB | 不可 |
| 1行の最大サイズ | 2 MiB | 不可 |
サポートされていないオブジェクト・コマンドもあります。
- 非対応オブジェクト:デフォルト値を持つカラム、一時テーブル、トリガー、パーティション、SQL 以外の言語で書かれた関数
- 非対応の制約・コマンド:外部キー(Foreign keys)、TRUNCATE、VACUUM(そもそも不要な設計)
- 未対応の PostgreSQL 拡張機能(要望が多いもの):pgvector、pgaudit、pg_stat_statements
PostgreSQL の感覚そのままだと「あれ?」となる部分なので、移行前にここを押さえるのが大事だと感じました。
アーキテクチャの設計思想とベストプラクティス
セッションの締めは、「なぜこういう制限になっているのか」という設計意図の話でした。
個人的にもっとも面白かったのが、ここです。

- Firecracker の μVM で QP を動かすメリット:ウォームプールで非常に高速な起動、CPU・メモリの拡大縮小が可能、リソースのクリーンアップが容易、VM は60分の固定期間で終了。
- トランザクション最大時間 5分の意図:コミット時の Adjudicator の競合検出作業が減り、マルチリージョン書き込みのクエリ性能が安定する。古い参照を破棄でき、MVCC のガベージコレクションも容易になる。
- 最大変更行数 3,000行の意図:メモリバッファの1回のフラッシュだけで済み、安定したクエリ性能になる。
その上で、最高の性能を出すためのアドバイスとして、
- 多くのトランザクションを並列に行い、QP の水平スケーリングを活かす
- 小さな行・小さなトランザクションを優先する
- マイクロサービスごとに別々のクラスターの使用を検討する
- EXPLAIN ANALYZE をプロファイリングに使う
- クライアントサイドの接続プーリングを使う
がまとめられていました。「制約」ではなく「安定した性能のための設計上の選択」という言い方が、考え方の転換として刺さりました。
自社の業務にどう活かせそうか
正直、私はまだ Aurora DSQL を触ったことがないので、現時点では「使いどころを見極めたい」という段階です。
それでも、インフラの面倒を見ずにマルチリージョンで読み書きできるのは、可用性を求められる案件で選択肢になりそうだと感じました。
一方で、同じ行や狭いキー範囲に同時アクセスが集中する用途では、コミット時に競合が起きてリトライが増えやすくなります。そのため 冪等なリトライ処理を実装し、主キーを分散させて単一キーへの集中を避ける設計が推奨されています。こうした得意・不得意があるので、「何でもこれ」ではなく向き・不向きを押さえて選ぶことが大事だと学びました。まずは個人で小さく触ってみて、トークン認証や接続プール、リトライ前提の書き方を体感したいです。
おわりに
初学者として聴いた率直な感想は、「話の流れは理解できたが、使ったことがないぶんイメージしづらい場面があった」です。
知らない単語で追いつけない箇所もありました。ただ、データベースの基礎は知っていたおかげで、Aurora DSQL が何をやりたくて、何を実現し、それによって何ができるのかという大枠は掴めました。
特に「主従の区別がない」「μVM で軽く速く起動する」「各種の上限は制約ではなく安定性能のための設計」というあたりは、これまでのデータベースのイメージを更新してくれる気づきでした。
次は実際に手を動かして、今回ふわっとしか分からなかった部分を埋めていきたいと思います。
同じくこれから触る方の参考になればうれしいです。




