
DX開発事業部の前野佑宜です。
6月26日に開催された「AWS Summit Japan 2026」Day2の参加レポートをお届けします。今回は建築業界の事例セッションや展示ブースを中心に視察してきました。普段の業務で向き合っている「図面など非構造化データのAI活用」にも応用できそうなヒントをいくつか得ることができました。本記事では、その内容を整理して共有します。
なぜ「建築DX」を見に行ったのか
私は普段、製造業のお客様のDX支援を担当しています。作るものは違っても、製造業も「図面などの非構造化データが多い」「ベテランの経験則に依存している」という共通の課題があり、他業界のやり方が参考になるのではと考えていました。
そこで今回は、以下の3点に注目して会場を見て回りました。
- 非構造化データをどうやってAI活用に乗せているのか?
- 設計図などのデータ検索精度をどうやって上げているのか?
- 実業務でエージェントAIを活用するためにどんな工夫をしているのか?
① ANDPAD社に学ぶ、Agentic RAGの実践事例
まず聴講したのが、株式会社アンドパッド・山下氏による「建設データ×Agentic RAG-Amazon Bedrock Knowledge Bases 実践」というセッションです。
ゴールは「社内データを自然言語で探せる」こと
セッションで掲げられていたゴールは以下の通りです。
「聞けば、根拠つきで答える。出典をたどれる状態にする」
これまで眠っていたデータを自然言語で検索できるようにする。その実現に向けて、「自然言語で問い合わせできる」「根拠を示す」、そして「根拠が無ければ答えない(でっち上げない)」の3点が重視されていました。

3つ目の「根拠が無ければ答えない」は、業務利用における必須条件と言えます。
最初はフルマネージドで始め、要る所だけ独自化する
技術選定の方針として参考になったのが、「最初はフルマネージドで始め、必要になった領域から順に作り込む」という進め方です。
| レイヤ | 最初:KBをフル活用 | 今:独自化 | 独自化した理由 |
|---|---|---|---|
| 取り込み | KB標準の同期 | EventBridge + SQS で独自キュー管理 | リアルタイム反映・取りこぼし制御・図面/写真対応 |
| 検索+生成 | RetrieveAndGenerate(1コール) | Retrieve のみ+自前のAgentic RAG | 精度・引用・振る舞いの作り込み |
| ベクトルストア | Amazon OpenSearch Serverless | Amazon OpenSearch Service(OR1) | 固定費を大幅に削減(見込み) |

「まずマネージドで価値を確かめる」。この割り切りが早期リリースに繋がっています。
フルマネージド(Amazon Bedrock Knowledge Bases)から始めた最大の理由はスピードとのこと。ベクトルDBもプロンプトも自前で組まず、S3にドキュメントを置いて同期するだけで、約1ヶ月で本番リリースまで持っていったそうです。

インフラ運用を手放して、まずは製品としての価値検証に集中する。その割り切りが1ヶ月という数字に出ていると思います。
課題が見えたら「独自化」していく
ただ、マネージドの標準機能だけでは建築特有の「図面や写真」への対応や、リアルタイム反映が難しかったため、取り込みレイヤをイベント駆動の独自構成に切り替えていました。
図面や施工写真といったマルチモーダルデータについても、「画像主体のPDFを読み取ってテキスト化してからKBに取り込む」といった前処理を挟んで対応されていました。

検索・生成のレイヤでは、「Corrective-RAG」を自前で構築していました。AIが取得した文書を採点し、点数が低ければクエリを書き換えて再取得させる。この精度調整を自分たちでコントロールすることで、実用レベルに引き上げているそうです。
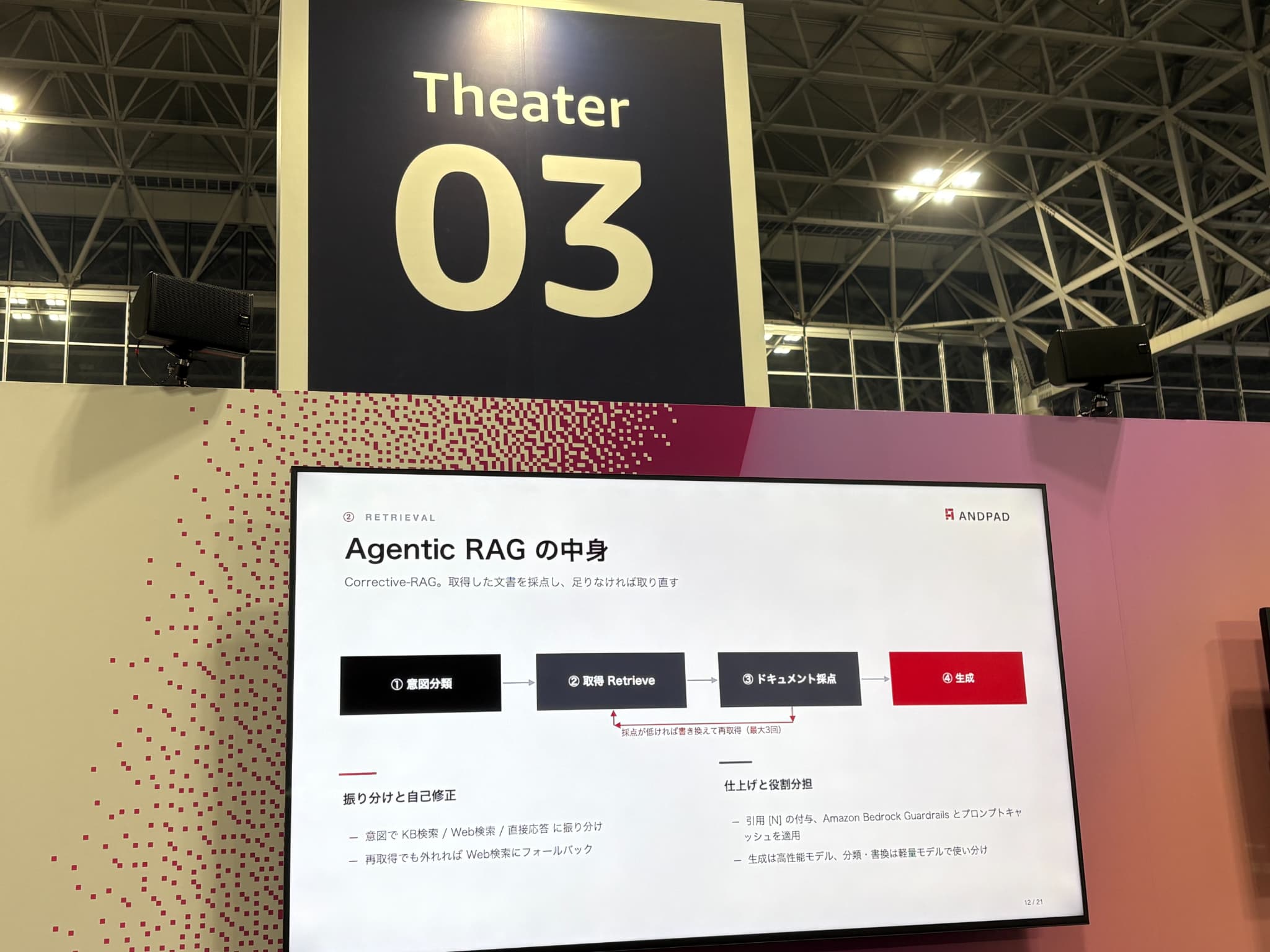
実装でハマった4つの落とし穴
実際の運用知見として参考になったのが、この「実装でハマった落とし穴」です。
| ハマった症状 | 原因 | 対処 |
|---|---|---|
| 大量取り込みが途中で頭打ち | embeddingの内部レート上限(画面から変更不可) | 上限を前提に計画し、監視を入れる |
| 画像だけのPDFで時間を浪費 | テキストが無く取り込み対象外として無視される | 無効ファイルを取り込み前に除外 |
| ストア移行がその場でできない | KBのストレージ構成・チャンク設定は後から変更不可 | 新しいKBを作り、S3から全件再取り込み |
| 再取得ループが空回り | 採点が低くても書き換えで改善しないことがある | 改善しないと判断したら打ち切る |

「ストア移行がその場でできない」は個人的に一番刺さりました。Amazon OpenSearch ServerlessのKBは後から設定変更できないため、移行時は新規でKBを作ってS3から全件取り込み直すことになります。最初の設計で決めたことが後々まで響きます。
② AWSブースでの気づきと、データ基盤の全体像
セッションの後、会場内のAWS出展ブース(建設DXゾーン)にも立ち寄りました。

図面検索における「手段の目的化」
ブースでは、担当の方に「図面の検索精度を上げるためには、どんな工夫ができるか」について質問しました。
図面内の番号等を抽出してメタデータを付与するため、OCRにAmazon Textractを使うという構成の話になりました。ただ、「Textractは日本語非対応だったはずですが、図面の読み取りで困りませんか?」と疑問に思い、聞いてみました。
すると、このような回答がありました。
「図面を検索する際、キーになる情報(図番やパーツ番号など)は数字やアルファベットで書かれることがほとんどです。なので、特段日本語を読み取る必要がなくても問題ないんですよ。最終的に必要な情報にたどり着ければいいわけですからね」
これを聞いて、「図面検索=図面内の日本語も全て高精度にテキスト化しなければならない」と思い込んでいたことに気づきました。
目的に立ち返れば、「ユーザーが図面を探すとき、どんなキーワード(番号)で検索するのか」が重要です。検索キーさえ抽出できれば、日本語が読めなくても目的は果たせます。
AI-Readyなデータ基盤の構成例
ブースには「AI Ready な設計データ基盤の例」というアーキテクチャ図も展示されていました。
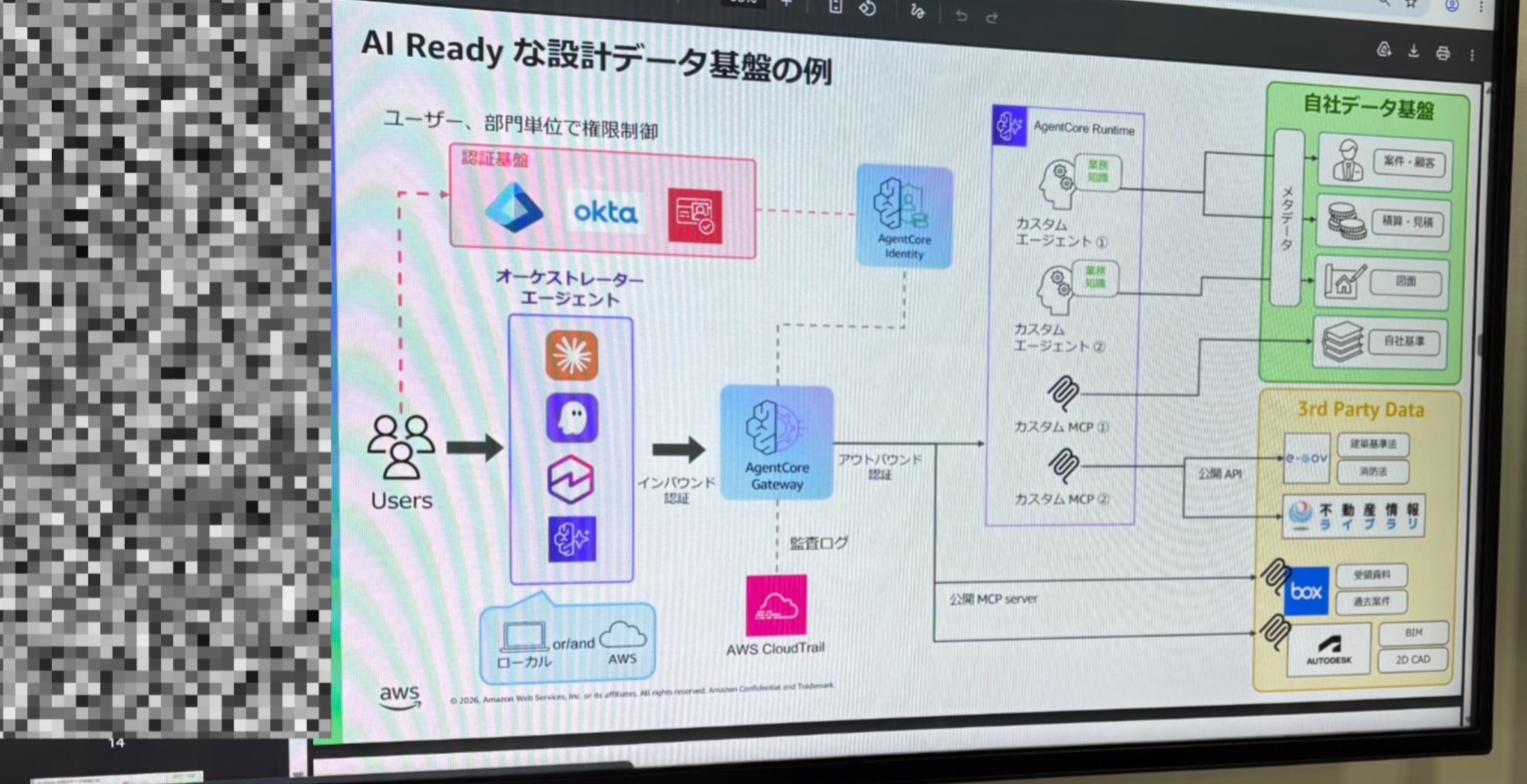
認証・権限制御から、オーケストレーターエージェントによる処理の振り分け、MCPを使った外部サービス連携まで含んだ全体像です。
このアーキテクチャ図を見ながら話していた中で、「今あるデータをいかに接続可能にして、AIが使える形にするかが重要」という話が印象に残っています。新しいデータを作るのではなく、すでに社内に存在するデータをつないでいく、という発想です。MCPで外部サービス(BoxやAutodeskなど)を接続しているのも、その一環だと理解しました。
おわりに
建築業界の事例でしたが、図面や仕様書の扱いや、ベテランの経験をどうシステムに落とし込むかといった悩みは、普段支援している製造業のお客様とも共通する部分が多かったなと感じました。
また、技術ファーストで考えるのではなく、お客様の課題ファーストで考える重要性を改めて感じさせられました。
「新しく作り直すのではなく、今あるデータ資産をいかに接続し、AIが使える形にするか」。この思想を大切にしながら、技術の目的化に陥ることなく、お客様にとって本当に価値のある実用的なDX支援を今後も推進していきたいと思います。




