
データ関連のアップデート紹介
※本ブログはDr. SwamiのKeynoteの後半部分についてのブログです。前半部分についてもブログを書いていますので、ぜひそちらも併せてご覧ください。
【AWS re:Invent 2023】Dr. Swami Sivasubramanian Keynote 前半パート[Keynote]
最初に、AWSでは包括的にデータ基盤のサービスを提供しているという話からスタートしました

ベクトル検索の話に移り、Vector engine for OpenSearch Serverlessの発表がありました

また、DocumentDB、DynamoDBでもベクトル検索をサポートしたとの発表がありました

さらに、MemoryDB for Redisのベクトル検索のGAも発表されました

さらにさらに、Neptune向けのデータベース分析機能のNeptune Analyticsも発表されました

これで、AWS全体でベクトル検索サービスを十分に揃えられたと言っていました

続いてデータの統合についての話に移り、S3とOpenSearchのzero-ETL integrationの発表がありました

その次はデータのガバナンスについての話に移り、Clean Rooms MLのプレビューの発表がありました
データを共有することなくMLモデルを提供できるとのことです

その後はAmazon Qを開発した背景について説明がされていました
ユーザーがほとんどの時間をドキュメントの検索やトラブルシュートに費やしていることが背景にあり、それを解決したかったとのことです


そして、Amazon QとRedshift、Glueの機能統合が発表されました

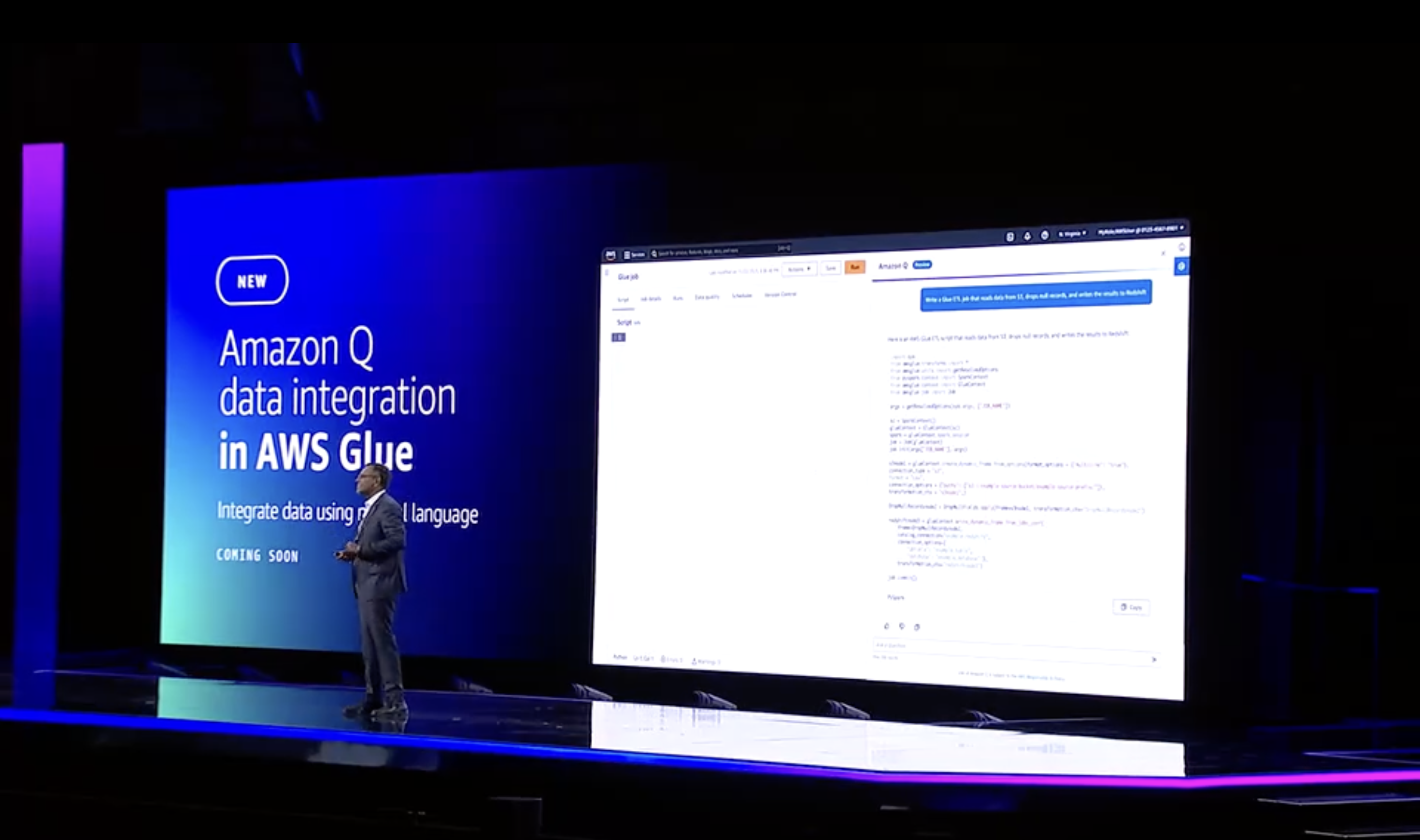
ここでAWSのシニアテクニカルプロダクトマネージャーが登場しました

Redshiftを中心に添えることでデータ管理にかかる時間を大幅に削減できる、強いデータ基盤があれば意思決定を迅速化し、価値創造に繋げることができる、といった話をされていました
その後Swamiが戻ってきて、Model Evaluation on Amazon Bedrockの発表がありました
ユースケースに応じたモデル評価をすることができるとのことでした

また、AI/ML関連のAWSのトレーニングプログラムの紹介もされていました

最後に学習プログラムの関連で、最近リリースされたPartyRockの話に移りました

個人個人が自身のアイディアを共有するツールとして、PartyRockを使って欲しいとのことでした

所感
Keynoteを聴いた感想としては、「ここまでツールを揃えてきたか、、、」という感じでした
zero-ETLもほとんどのサービスで統合がされましたし、ベクトル検索やデータのガバナンスなども充実させていることに驚きました
AIの領域でも全方位で戦っていく、そんなAWSの意気込みを感じるようなKeynoteでした