概要
アーティスト名と曲名の表記ゆれを修正するために、BigQueryのML.GENERATE_TEXT関数を利用してVertex AIのtext-bisonモデルに問い合わせを行う。
BigQuery側作業
接続を作成する
公式の手順に従い、BigQueryでCloudリソース接続を作成する。
サービス アカウントにアクセス権を付与する
公式の手順に従い、前項で作成したCloudリソース接続が利用するサービスアカウントにIAMロールを付与する。
モデルを作成
公式の手順に従い、BigQueryでモデルを作成する。
この際、クエリ内のOPTIONSに指定するモデルがVertex AIのプロンプトの問い合わせ先のモデルとなる。
これをPaLM2のtext-bisonモデルに問い合わせたいため、以下のように変更する。
CREATE OR REPLACE MODEL `clp-iret4dev.makita_generete_text_test.makita-generete-text-test` REMOTE WITH CONNECTION `projects/clp-iret4dev/locations/asia-northeast1/connections/makita-generete-text-test` OPTIONS (ENDPOINT = 'text-bison');
アーティスト名と曲名を格納するテーブルを作成
テーブルを作成
以下のクエリを実行する。
inserto into makita_generete_text_test.test (arttist string, title string)
データを挿入
以下のクエリを実行し、アーティスト名も曲名も正式名称ではない値で登録する。
insert into makita_generete_text_test.test values ("TMレボリューション", "ホットリミット")
insert into makita_generete_text_test.test values ("キングヌー", "はくじつ")
データを確認
以下のクエリを実行し、正常に登録されていることを確認する。
select * from makita_generete_text_test.test
表記ゆれを修正
公式の手順を参考に、ML.GENERATE_TEXT関数を呼び出し表記ゆれを修正する。
以下のクエリを実行する。
なお、ML.GENERATE_TEXT関数内のSelectでpromptと名付けている列にtext-bisonモデルに渡したいプロンプトの質問を指定する。
ここでは先程作成したテーブルに格納されているアーティスト名と曲名を利用している。
SELECT *
FROM
ML.GENERATE_TEXT(
MODEL `makita_generete_text_test.makita-generete-text-test`,
(
SELECT
CONCAT(
arttist, "の正式な表記を教えてください。また正式な表記だけを回答してください"
) AS prompt,
*
FROM
`makita_generete_text_test.test`
),
STRUCT(
0.4 AS temperature, 100 AS max_output_tokens, 0.5 AS top_p,
40 AS top_k, TRUE AS flatten_json_output));
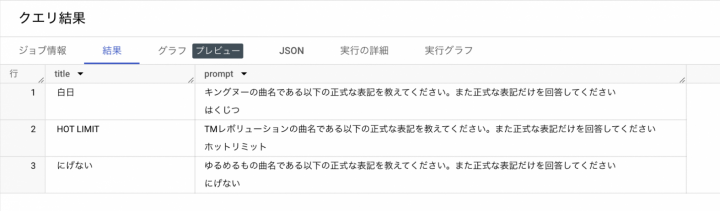
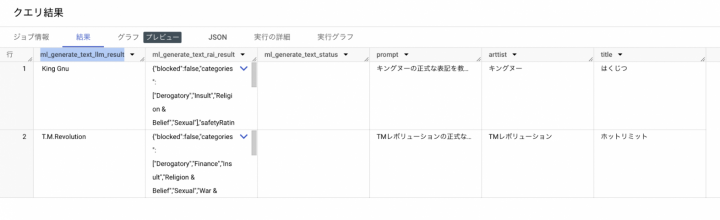
ml_generate_text_llm_result列にVertex AIからのレスポンスが格納され、正式な表記が返っていることが確認できる。
クエリを修正
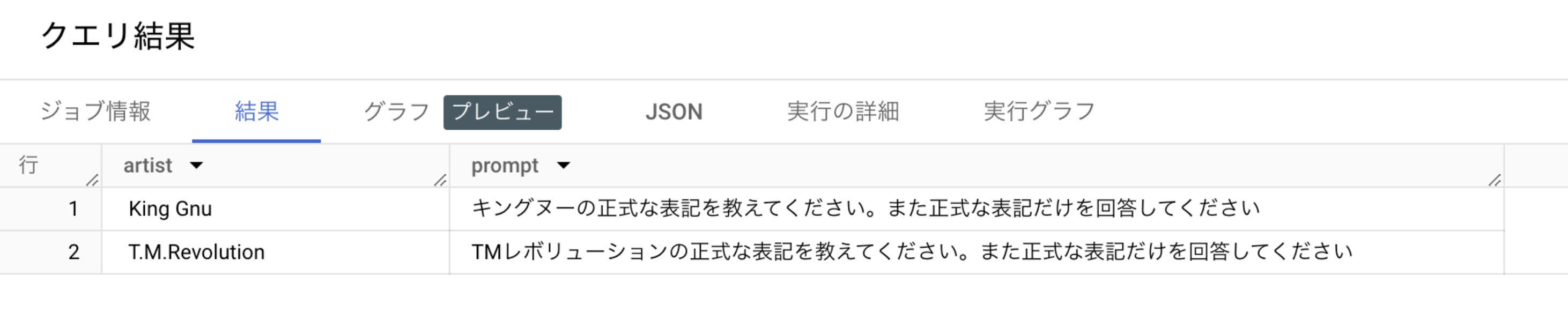
クエリを修正し結果とプロンプトだけを表示させる。
SELECT ml_generate_text_llm_result as artist, prompt
FROM
ML.GENERATE_TEXT(
MODEL `makita_generete_text_test.makita-generete-text-test`,
(
SELECT
CONCAT(
arttist, "の正式な表記を教えてください。また正式な表記だけを回答してください"
) AS prompt,
*
FROM
`makita_generete_text_test.test`
),
STRUCT(
0.4 AS temperature, 100 AS max_output_tokens, 0.5 AS top_p,
40 AS top_k, TRUE AS flatten_json_output));
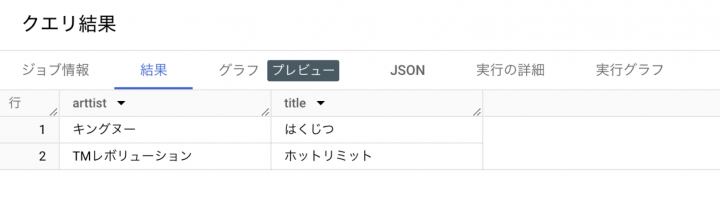
結果がシンプルになった。
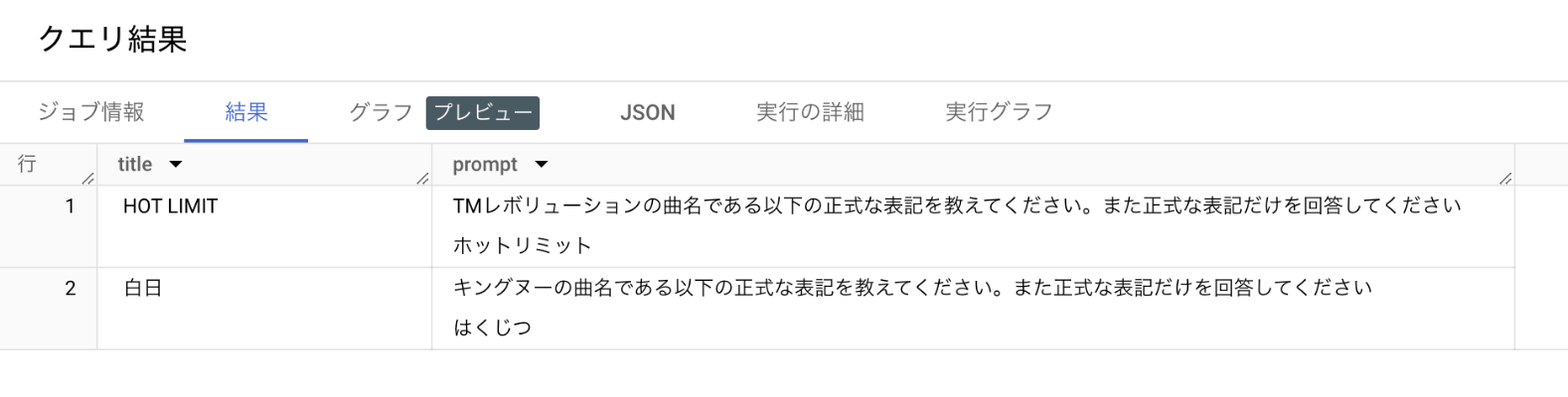
曲名の表記ゆれ修正
曲名の表記ゆれ修正も試してみる。
SELECT ml_generate_text_llm_result as title, prompt
FROM
ML.GENERATE_TEXT(
MODEL `makita_generete_text_test.makita-generete-text-test`,
(
SELECT
CONCAT(
arttist, "の曲名である以下の正式な表記を教えてください。また正式な表記だけを回答してください", "\n",
title
) AS prompt,
*
FROM
`makita_generete_text_test.test`
),
STRUCT(
0.4 AS temperature, 100 AS max_output_tokens, 0.5 AS top_p,
40 AS top_k, TRUE AS flatten_json_output));
正しい曲名が返っていることが確認できる。
アーティスト名と曲名を一括で修正
アーティスト名と曲名を一括で修正してみる。
SELECT ml_generate_text_llm_result as result, prompt
FROM
ML.GENERATE_TEXT(
MODEL `makita_generete_text_test.makita-generete-text-test`,
(
SELECT
CONCAT(
arttist, "とその曲名である以下の正式な表記を教えてください。回答の1行目にはアーティストの正式な表記を、2行目には曲名の正式な表記を回答し、それぞれ表記のみを回答してください\n",
title
) AS prompt,
*
FROM
`makita_generete_text_test.test`
),
STRUCT(
0.4 AS temperature, 100 AS max_output_tokens, 0.5 AS top_p,
40 AS top_k, TRUE AS flatten_json_output));
なぜかT.M.RevolutionがTM NETWORKとなった。
質問を変えてみたがダメだったので、恐らく両方一気にやるとtext-bisonのキャパを超えて精度が低下してしまうようだ。

特殊記号を含む場合
ふと気になったのでゆるめるモ!の逃げない!!もビックリマークの全角・半角含め、正常に修正できるか追加で検証してみる。
間違った表記の以下をテーブルに追加する。
insert into makita_generete_text_test.test values ("ゆるめるも", "にげない")
アーティスト名はビックリマーク含め正常に修正されている。

ただ曲名は変換されていない。
驚くべきなのは漢字にすら変換されていないが、Geminiを指定できるようになればこの辺りの精度の問題は解決しそう…?