
Google Cloud Next ’24 にて行われたセッション「Best practices to maximize the availability of your Cloud SQL databases」のレポートです。
Google Cloud Next ’24 とは?
2024 年 4 月 9 ~ 11 日にラスベガスのマンダレイ ベイで開催されている、Google Cloud が主催する最大級規模のイベントです。
https://cloud.withgoogle.com/next/
登壇者
Google Cloud, Product Manager
Rahul Deshmukh 氏
Workday, VP, Software Engineering
Patrick Kirby 氏
セッション内容
Cloud SQL について
- フルマネージドのリレーショナル データベース サービス
- ソース データベース エンジンとの完全な互換性:PostgreSQL、MySQL、SQL Server をサポート
- フルマネージドでエンタープライズ対応:セットアップ、操作、拡張が簡単
- 99.99%の稼働時間:SLA (メンテナンスを含む) を備えた、信頼性の高いエンタープライズ グレードのデータ保護、セキュリティ、ガバナンス
- 開発者に優しい:アプリケーション中心の可観測性とAPIファーストの管理
- Google Cloudの上位100社の顧客のうち、95%以上がCloud SQLを使用している
Cloud SQL Enterprise Plus について
- コストパフォーマンスの向上
- パフォーマンスが 3 倍向上
- 構成可能なデータキャッシュ
- 可用性と信頼性の向上
- 「99.99%(フォーナイン)」のSLAによる計画メンテナンスのため、ほぼゼロのダウンタイム
- データ保護の向上
- ポイントインタイム リカバリ(PITR) 保持期間の延長により、最大35日間の保持が可能(GCS でのログの保持)
HA と DR
- 未来の変化に対する準備
- 計画済み:定期メンテナンス、インスタンスのスケーリング、その他設定変更
- 計画外:ゾーン障害、リージョン障害、ユーザーエラー
- 3つのベストプラクティス
- メンテナンスウィンドウを設定する
- 業務への影響が最も少ない時間にメンテナンスを確実に実施できるようになる
- 通知順序を設定する
- メンテナンスが行われる1週間または2週間前に通知を受け取ることが可能
- 本番インスタンスとクリティカルなインスタンスについては、準備に十分な時間を確保できるように2週間前に通知を設定する
- 拒否メンテナンスの活用
- 本番環境にメンテナンスを適用する準備ができていない場合は、メンテナンスの適用を数週間延期することが可能
- 最長90日間の拒否メンテナンスウィンドウを四半期ごとに設定する
- それでもダウンタイムが発生する → 最小限に抑えるにはどうすれば良いか?
- ほぼゼロダウンタイム メンテナンスを開始
- インスタンス IP はメンテナンスが行われたときと同じままになり、バックアップして実行される
- プライベート IP とパブリック IP の組み合わせがある場合でも可能
- ドキュメントには 10 秒未満と記載されているが、これはシステムによっては長すぎる
- さらに短縮し、ミリ秒単位を実現した
- 実際にどのくらいのダウンタイムなのかデモ(780 msくらいだった)
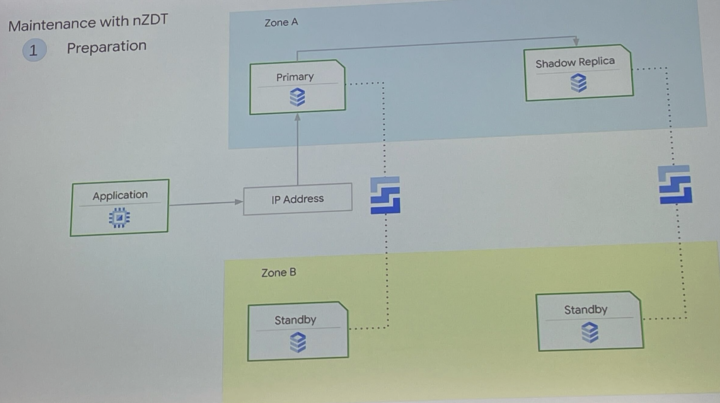
- インスタンスのスケーリング
- 128 vCPU
- 864 GB RAM
- 9000 GBのデータキャッシュ
- 実際にどのくらいのダウンタイムなのかデモ(700 msくらいだった)
- ストレージはダウンタイムなしで自動拡張
- 64 TB
- 100 K / 80 K 読み取り/書き込み IOPS
- ここまでは計画済みに対する対策だが、計画外への対策は?
- プライマリインスタンスで高可用性を有効にし、ゾーン障害から保護
- クロスリージョン リードレプリカを作成してリージョン障害から迅速に回復
- PITRを有効にして、人的エラーから迅速に回復する
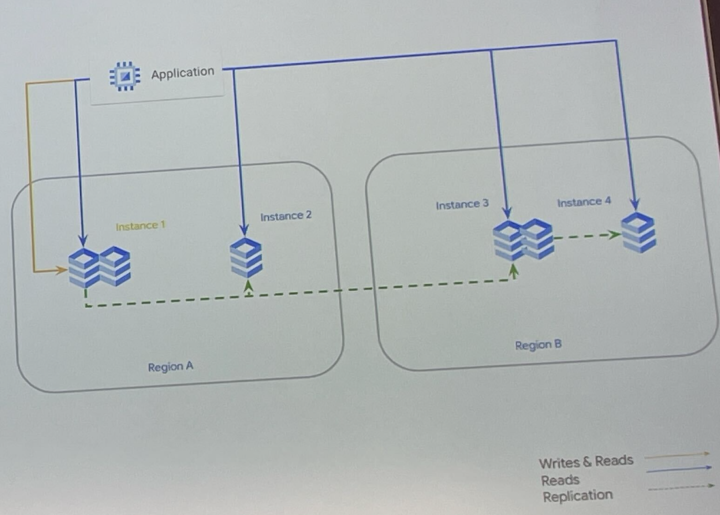
クロスリージョン リードレプリカ
- 特徴
- リージョン障害から数分以内に回復
- レプリカのサイズは変更可能
- HAとカスケードレプリカにより、復旧時間はさらに短縮
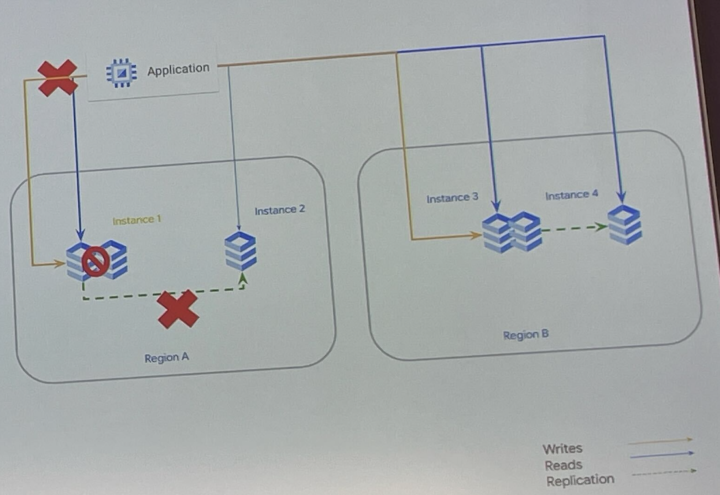
- DR
- クロスリージョン リードレプリカの動きにより、レプリカがプライマリから切断される
- HA用にレプリカを構成し、カスケードリードレプリカを作成してRTOを削減する
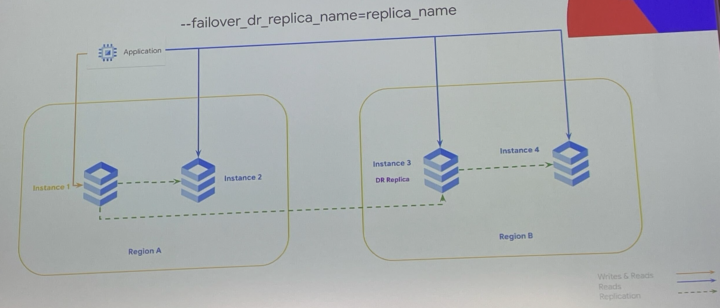
- 高度なDR
- シンプルなDRとシミュレーション
- レプリカ フェイルオーバー:トポロジの残りの部分を維持しながらレプリカを昇格
- スイッチオーバー:データ損失をゼロにして、元のレプリケーション トポロジを復元
感想
主にCloud SQLの耐障害性やDRについての構成やベストプラクティスについてのセッションでした。
従来は、メンテナンスは数分以上のダウンタイムが発生するため、お客様と要調整のうえ実施するようなフローを行なっていましたが、ゼロダウンタイムがGAされてからは、1秒未満ならいつでも大丈夫といったお客様も増えており、やはり非常に魅力的な機能だと実感しています。
また、クロスリージョン リードレプリカを用いたDR構成および切り替えの仕組みについても詳しく解説されており、大変勉強になりました。




