
DX開発事業部の西田です。
Cloud DLP(Data Loss Prevention)は個人情報やカード番号などの機密データを検出や匿名加工できるGoogle Cloudのサービスです。
Cloud Storageにアップロードされた機密情報をCloud DLPで検出、匿名化して安全に扱える状態にするというユースケースを実現するために検証を行ったのでまとめます。
Cloud Storageにアップロードされたデータの分類の自動化
Cloud DLPによる機密情報データの隔離のユースケースで公式のチュートリアルがすでにあったため、まずはこちらを試してみました。
作るものの構成は以下のようになります。
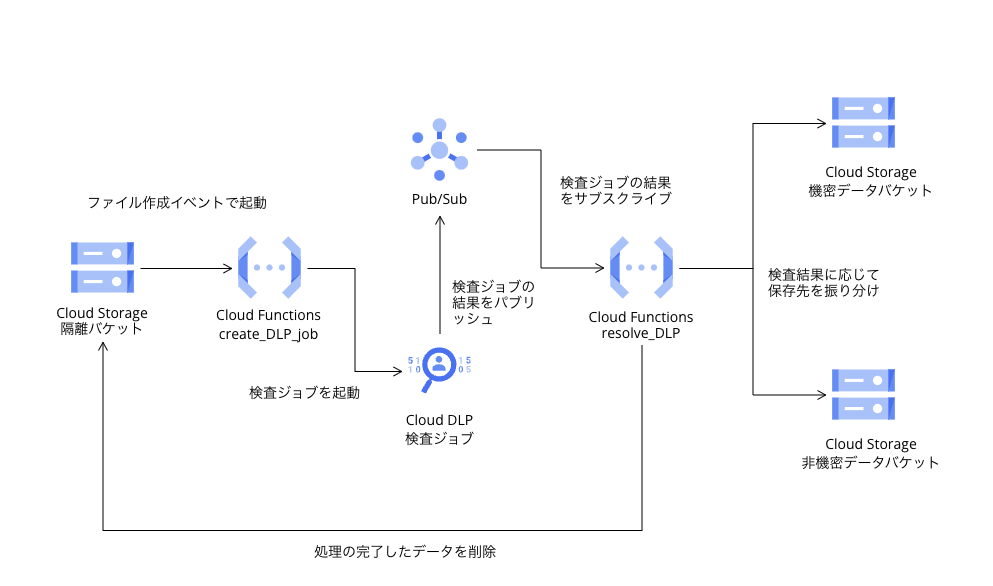
APIを有効化
以下のAPIを有効化します。
- Cloud Functions API
- Cloud Build API
- Sensitive Data Protection (DLP)
サービス アカウントへの権限の付与
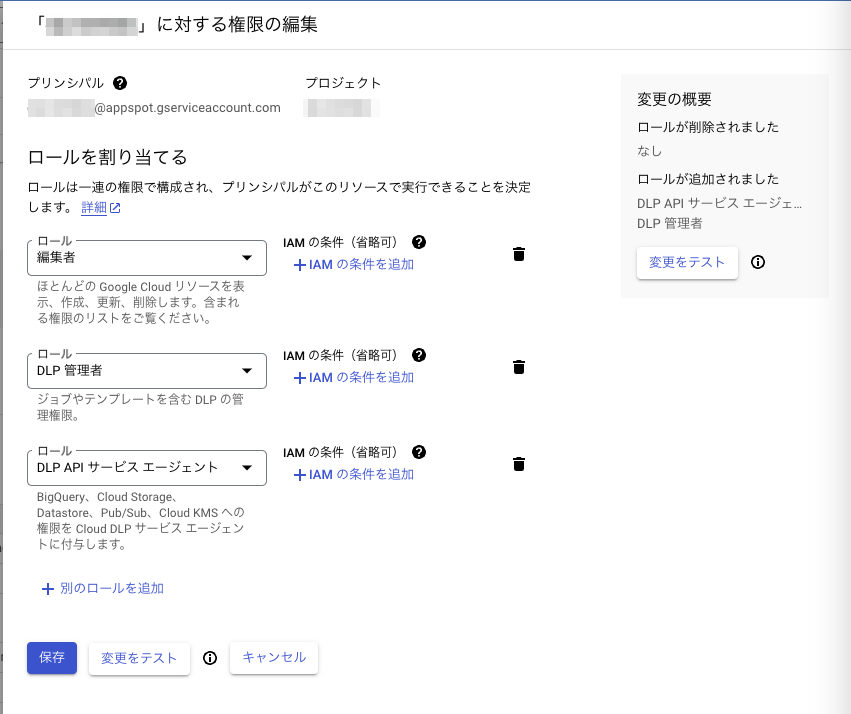
機密データの保護のサービス アカウントに権限を付与する
Cloud Shellで、InspectContentを呼び出してCloud DLP サービス エージェントを作成します。
PROJECT_ID=`gcloud config get project`
curl --request POST \
"https://dlp.googleapis.com/v2/projects/$PROJECT_ID/locations/asia-northeast1/content:inspect" \
--header "X-Goog-User-Project: $PROJECT_ID" \
--header "Authorization: Bearer $(gcloud auth print-access-token)" \
--header 'Accept: application/json' \
--header 'Content-Type: application/json' \
--data '{"item":{"value":"google@google.com"}}' \
--compressed
サービスエージェントのサービスアカウントに権限を付与します。
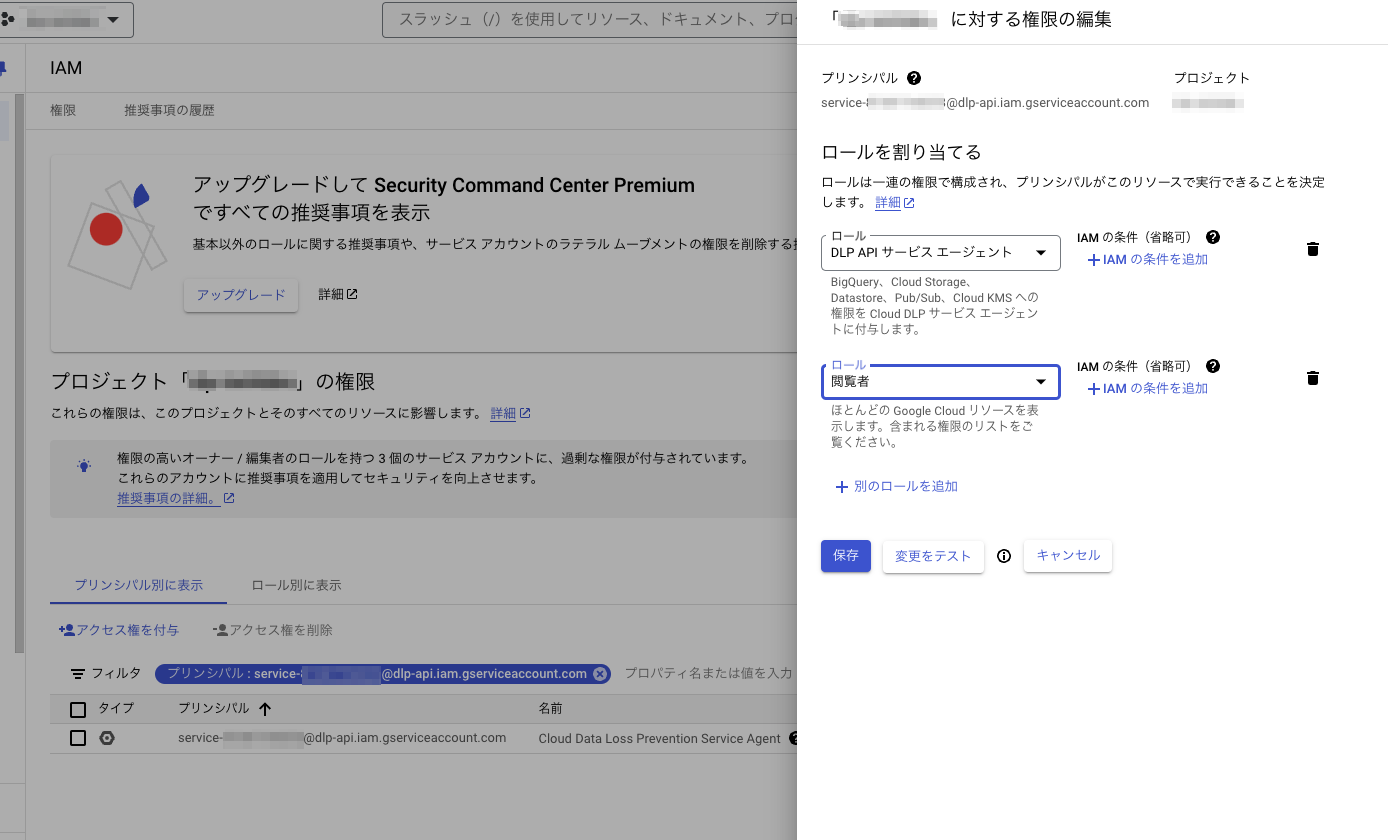
隔離と分類のパイプラインを作成する
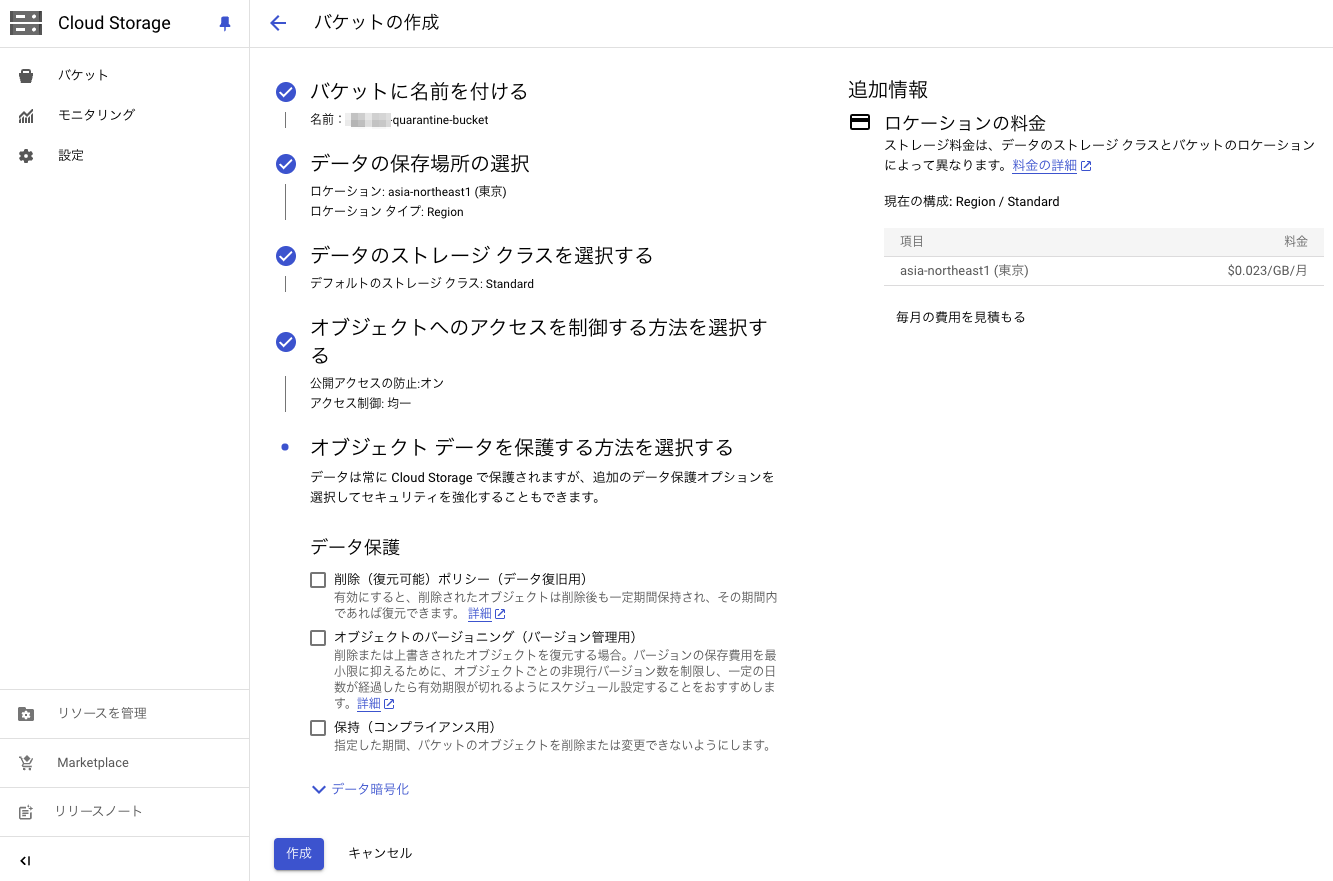
Cloud Storage バケットを作成する
以下の3つのバケットを作成します。
- 検疫バケット
- 機密データを隔離したバケット
- 機密データが存在しないバケット
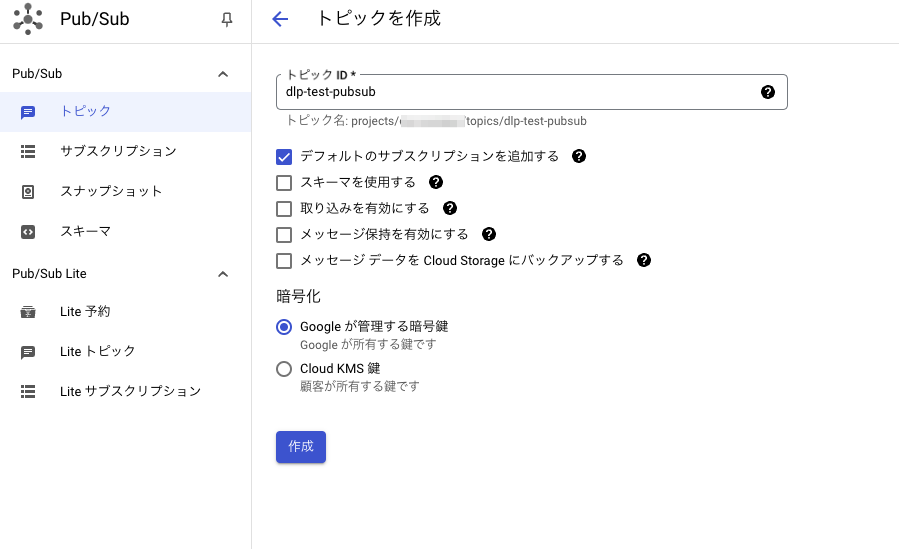
Pub/Sub トピックとサブスクリプションを作成する
DLPジョブから通知を受け取ってCloud FunctionsがサブスクライブするためのPub/Subトピックを作成します。
トピックを作成
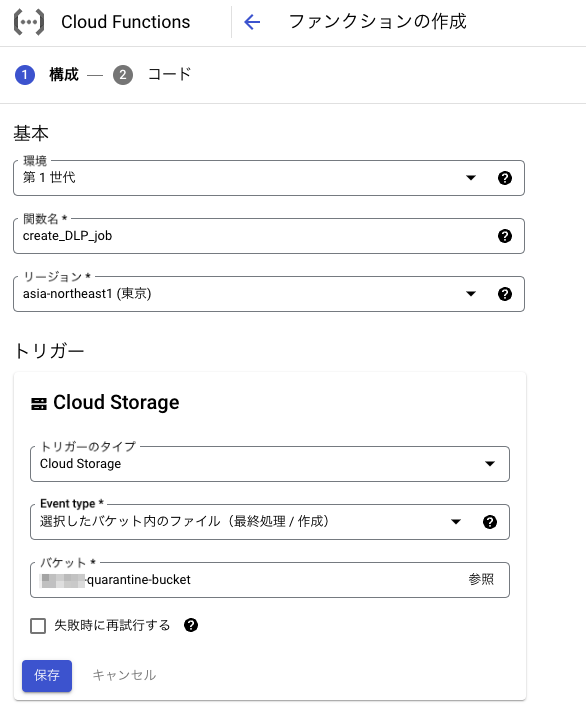
Cloud Functions を作成する
2つのCloud Functions関数を作成します。
ランタイムはPython 3.12としています。
オブジェクトが Cloud Storage にアップロードされたときに呼び出される関数
from google.cloud import dlp
from google.cloud import logging
import os
# ----------------------------
# User-configurable Constants
PROJECT_ID = os.getenv('DLP_PROJECT_ID', '<my-project>')
"""The bucket the to-be-scanned files are uploaded to."""
STAGING_BUCKET = os.getenv('QUARANTINE_BUCKET', '<quarantine-bucket>')
""" Pub/Sub topic to notify once the DLP job completes."""
PUB_SUB_TOPIC = os.getenv('PUB_SUB_TOPIC', 'dlp-test-pubsub')
"""The minimum_likelihood (Enum) required before returning a match"""
"""For more info visit: https://cloud.google.com/dlp/docs/likelihood"""
MIN_LIKELIHOOD = os.getenv('MIN_LIKELIHOOD', 'POSSIBLE')
"""The maximum number of findings to report (0 = server maximum)"""
MAX_FINDINGS = 0
"""The infoTypes of information to match. ALL_BASIC for common infoTypes"""
"""For more info visit: https://cloud.google.com/dlp/docs/concepts-infotypes"""
INFO_TYPES = os.getenv('INFO_TYPES', 'FIRST_NAME,PHONE_NUMBER,EMAIL_ADDRESS,US_SOCIAL_SECURITY_NUMBER').split(',')
APP_LOG_NAME = os.getenv('LOG_NAME', 'DLP-classify-gcs-files-create-dlp-job')
# End of User-configurable Constants
# ----------------------------------
# Initialize the Google Cloud client libraries
dlp = dlp.DlpServiceClient()
LOG_SEVERITY_DEFAULT = 'DEFAULT'
LOG_SEVERITY_INFO = 'INFO'
LOG_SEVERITY_ERROR = 'ERROR'
LOG_SEVERITY_WARNING = 'WARNING'
LOG_SEVERITY_DEBUG = 'DEBUG'
def log(text, severity=LOG_SEVERITY_DEFAULT, log_name=APP_LOG_NAME):
logging_client = logging.Client()
logger = logging_client.logger(log_name)
return logger.log_text(text, severity=severity)
def create_DLP_job(data, done):
"""This function is triggered by new files uploaded to the designated Cloud Storage quarantine/staging bucket.
It creates a dlp job for the uploaded file.
Arg:
data: The Cloud Storage Event
Returns:
None. Debug information is printed to the log.
"""
# Get the targeted file in the quarantine bucket
file_name = data['name']
log('Function triggered for file [{}] to start a DLP job of InfoTypes [{}]'.format(file_name, ','.join(INFO_TYPES)),
severity=LOG_SEVERITY_INFO)
# Prepare info_types by converting the list of strings (INFO_TYPES) into a list of dictionaries
info_types = [{'name': info_type} for info_type in INFO_TYPES]
# Convert the project id into a full resource id.
parent = f"projects/{PROJECT_ID}"
# Construct the configuration dictionary.
inspect_job = {
'inspect_config': {
'info_types': info_types,
'min_likelihood': MIN_LIKELIHOOD,
'limits': {
'max_findings_per_request': MAX_FINDINGS
},
},
'storage_config': {
'cloud_storage_options': {
'file_set': {
'url':
'gs://{bucket_name}/{file_name}'.format(
bucket_name=STAGING_BUCKET, file_name=file_name)
}
}
},
'actions': [{
'pub_sub': {
'topic':
'projects/{project_id}/topics/{topic_id}'.format(
project_id=PROJECT_ID, topic_id=PUB_SUB_TOPIC)
}
}]
}
# Create the DLP job and let the DLP api processes it.
try:
dlp.create_dlp_job(parent=(parent), inspect_job=(inspect_job))
log('Job created by create_DLP_job', severity=LOG_SEVERITY_INFO)
except Exception as e:
log(e, severity=LOG_SEVERITY_ERROR)
# Function dependencies, for example: # package>=version google-cloud-dlp google-cloud-logging
この関数では、ファイル名を受け取り、「FIRST_NAME,PHONE_NUMBER,EMAIL_ADDRESS,US_SOCIAL_SECURITY_NUMBER」のinfoType検出器を使いDLPジョブを起動。
検出結果をトピックにパブリッシュします。
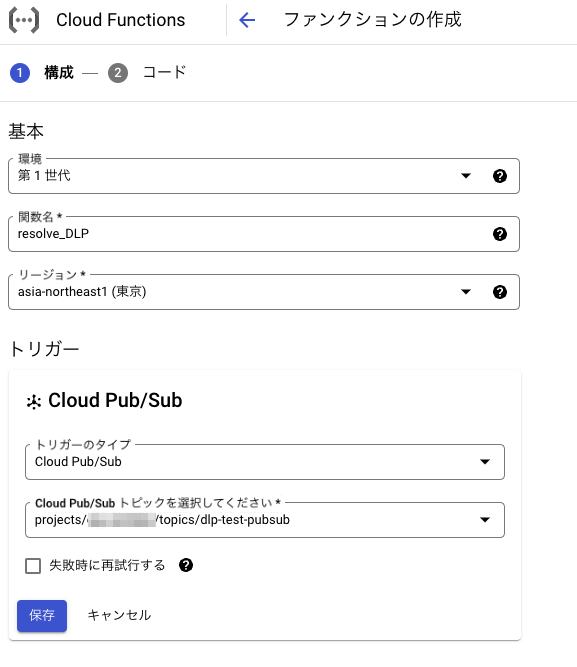
Pub/Sub キューでメッセージを受信したときに呼び出される関数
from google.cloud import dlp
from google.cloud import storage
from google.cloud import logging
import os
# ----------------------------
# User-configurable Constants
PROJECT_ID = os.getenv('DLP_PROJECT_ID', '<my-project>')
"""The bucket the to-be-scanned files are uploaded to."""
STAGING_BUCKET = os.getenv('QUARANTINE_BUCKET', '<quarantine-bucket>')
"""The bucket to move "sensitive" files to."""
SENSITIVE_BUCKET = os.getenv('SENSITIVE_DATA_BUCKET', '<sensitive-data-bucket>')
"""The bucket to move "non sensitive" files to."""
NONSENSITIVE_BUCKET = os.getenv('INSENSITIVE_DATA_BUCKET', '<non-sensitive-data-bucket>')
APP_LOG_NAME = os.getenv('LOG_NAME', 'DLP-classify-gcs-files-resolve-dlp')
# End of User-configurable Constants
# ----------------------------------
# Initialize the Google Cloud client libraries
dlp = dlp.DlpServiceClient()
storage_client = storage.Client()
LOG_SEVERITY_DEFAULT = 'DEFAULT'
LOG_SEVERITY_INFO = 'INFO'
LOG_SEVERITY_ERROR = 'ERROR'
LOG_SEVERITY_WARNING = 'WARNING'
LOG_SEVERITY_DEBUG = 'DEBUG'
def log(text, severity=LOG_SEVERITY_DEFAULT, log_name=APP_LOG_NAME):
logging_client = logging.Client()
logger = logging_client.logger(log_name)
return logger.log_text(text, severity=severity)
def resolve_DLP(data, context):
"""This function listens to the pub/sub notification from function above.
As soon as it gets pub/sub notification, it picks up results from the
DLP job and moves the file to sensitive bucket or nonsensitive bucket
accordingly.
Args:
data: The Cloud Pub/Sub event
Returns:
None. Debug information is printed to the log.
"""
# Get the targeted DLP job name that is created by the create_DLP_job function
job_name = data['attributes']['DlpJobName']
log('Received pub/sub notification from DLP job: {}'.format(job_name), severity=LOG_SEVERITY_INFO)
# Get the DLP job details by the job_name
job = dlp.get_dlp_job(request={'name': job_name})
log('Job Name:{name}\nStatus:{status}'.format(name=job.name, status=job.state), severity=LOG_SEVERITY_INFO)
# Fetching Filename in Cloud Storage from the original dlpJob config.
# See defintion of "JSON Output' in Limiting Cloud Storage Scans':
# https://cloud.google.com/dlp/docs/inspecting-storage
file_path = (
job.inspect_details.requested_options.job_config.storage_config
.cloud_storage_options.file_set.url)
file_name = file_path.split("/", 3)[3]
info_type_stats = job.inspect_details.result.info_type_stats
source_bucket = storage_client.get_bucket(STAGING_BUCKET)
source_blob = source_bucket.blob(file_name)
if (len(info_type_stats) > 0):
# Found at least one sensitive data
for stat in info_type_stats:
log('Found {stat_cnt} instances of {stat_type_name}.'.format(
stat_cnt=stat.count, stat_type_name=stat.info_type.name), severity=LOG_SEVERITY_WARNING)
log('Moving item to sensitive bucket', severity=LOG_SEVERITY_DEBUG)
destination_bucket = storage_client.get_bucket(SENSITIVE_BUCKET)
source_bucket.copy_blob(source_blob, destination_bucket,
file_name) # copy the item to the sensitive bucket
source_blob.delete() # delete item from the quarantine bucket
else:
# No sensitive data found
log('Moving item to non-sensitive bucket', severity=LOG_SEVERITY_DEBUG)
destination_bucket = storage_client.get_bucket(NONSENSITIVE_BUCKET)
source_bucket.copy_blob(
source_blob, destination_bucket,
file_name) # copy the item to the non-sensitive bucket
source_blob.delete() # delete item from the quarantine bucket
log('classifying file [{}] Finished'.format(file_name), severity=LOG_SEVERITY_DEBUG)
# Function dependencies, for example: # package>=version google-cloud-dlp google-cloud-storage google-cloud-logging
この関数ではトピックからサブスクライブしたDLPジョブの結果を元にバケットにファイルを振り分けて移動しています。
隔離バケットにサンプル ファイルをアップロードする
サンプルデータはこちら。
こちらを検疫バケットにアップロードするとファイルは数分後削除されます。
機密情報が検知されたファイルは機密データを隔離したバケット。
機密情報が検知されなかったファイルは機密データが存在しないバケットに保存されています。
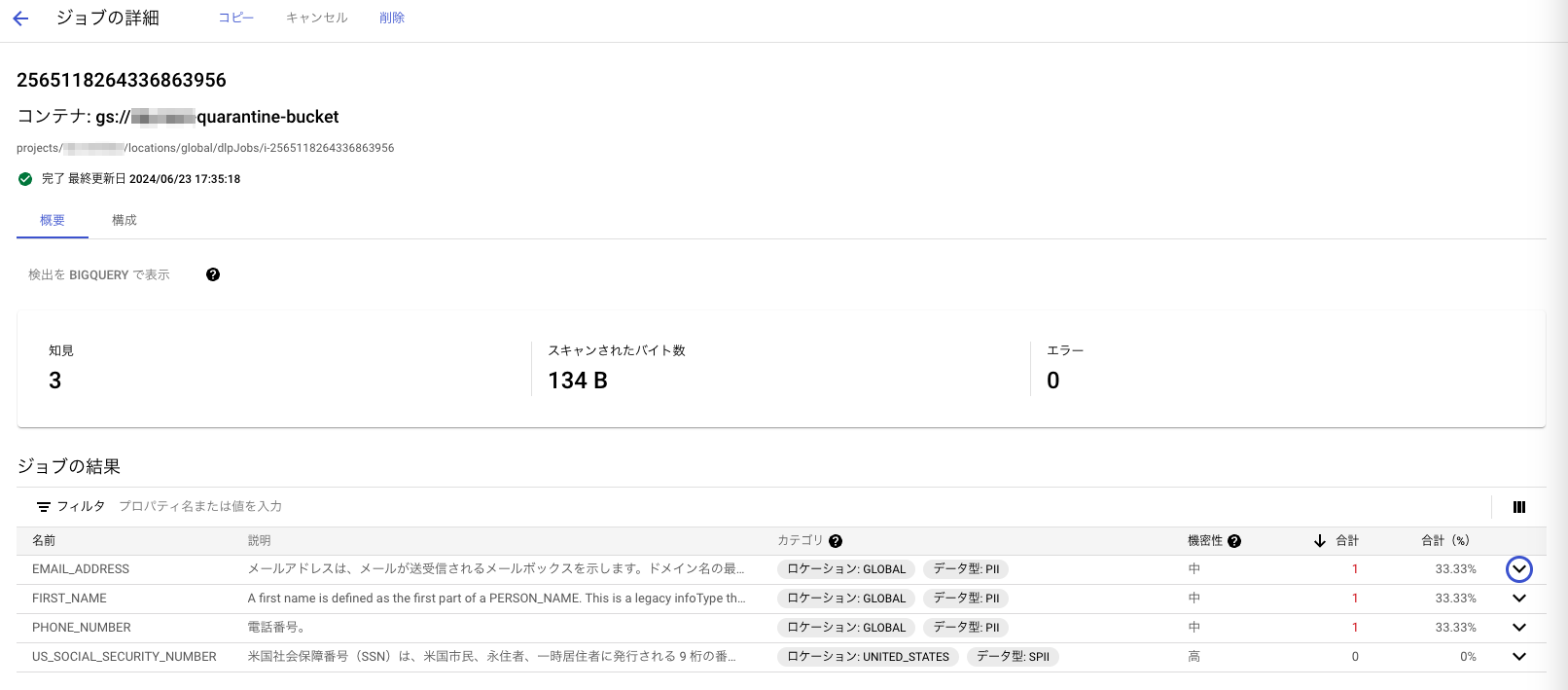
DLPジョブの実行結果はこちらから確認でき何が検出されたかを見ることができます。
Cloud Storageにアップロードされたデータの匿名化
公式のチュートリアルでは検知までで、匿名化ではなかっため手を加えて匿名化するようにしてみました。
Cloud Storage バケットを作成する
2つのバケットを作成します。
- 検疫バケット
- 匿名化後バケット
オブジェクトが Cloud Storage にアップロードされたときに呼び出される関数
こちらをサンプルに匿名化の処理を記述しました。
DLPジョブを利用しなくてよいので関数は1つにしています。
from google.cloud import dlp_v2
from google.cloud import storage
from google.cloud import logging
import os
# ----------------------------
# User-configurable Constants
PROJECT_ID = os.getenv('DLP_PROJECT_ID', '<my-project>')
"""The bucket the to-be-scanned files are uploaded to."""
STAGING_BUCKET = os.getenv('QUARANTINE_BUCKET', '<quarantine-bucket>')
"""The bucket to move "deidentify" files to."""
DEIDENTIFY_BUCKET = os.getenv('DEIDENTIFY_DATA_BUCKET', '<deidentify-bucket>')
"""The infoTypes of information to match. ALL_BASIC for common infoTypes"""
"""For more info visit: https://cloud.google.com/dlp/docs/concepts-infotypes"""
INFO_TYPES = [
'FIRST_NAME',
'AGE',
'EMAIL_ADDRESS',
'CREDIT_CARD_NUMBER',
]
APP_LOG_NAME = os.getenv('LOG_NAME', 'DLP-classify-gcs-files-deidentify-dlp')
ALLOWED_EXTENSIONS = ['.txt', '.csv']
# End of User-configurable Constants
# ----------------------------------
# Initialize the Google Cloud client libraries
dlp = dlp_v2.DlpServiceClient()
storage_client = storage.Client()
LOG_SEVERITY_DEFAULT = 'DEFAULT'
LOG_SEVERITY_INFO = 'INFO'
LOG_SEVERITY_ERROR = 'ERROR'
LOG_SEVERITY_WARNING = 'WARNING'
LOG_SEVERITY_DEBUG = 'DEBUG'
def log(text, severity=LOG_SEVERITY_DEFAULT, log_name=APP_LOG_NAME):
logging_client = logging.Client()
logger = logging_client.logger(log_name)
return logger.log_text(text, severity=severity)
def deidentify_DLP(data, done, masking_character="*"):
"""This function is triggered by new files uploaded to the designated Cloud Storage quarantine/staging bucket.
It creates a dlp job for the uploaded file.
Arg:
data: The Cloud Storage Event
Returns:
None. Debug information is printed to the log.
"""
# Get the targeted file in the quarantine bucket
source_file_name = data['name']
log('Function triggered for file [{}] to start a DLP of InfoTypes [{}]'.format(source_file_name, ','.join(INFO_TYPES)),
severity=LOG_SEVERITY_INFO)
if not any(source_file_name.endswith(ext) for ext in ALLOWED_EXTENSIONS):
print(f"Ignored file: {source_file_name}")
return
# Download file
source_bucket = storage_client.bucket(STAGING_BUCKET)
source_blob = source_bucket.blob(source_file_name)
temp_file_path = f"/tmp/{source_file_name.replace('/', '_')}"
source_blob.download_to_filename(temp_file_path)
with open(temp_file_path, 'r', encoding='utf-8') as file:
file_content = file.read()
# Prepare info_types by converting the list of strings (INFO_TYPES) into a list of dictionaries
info_types = [{'name': info_type} for info_type in INFO_TYPES]
# Convert the project id into a full resource id.
parent = f"projects/{PROJECT_ID}"
# Execute deidentify
try:
response = dlp.deidentify_content(
request={
'parent': parent,
'inspect_config': {
'info_types': info_types,
'include_quote': True
},
'deidentify_config': {
'info_type_transformations': {
'transformations': [
{
'primitive_transformation': {
'character_mask_config': {
'masking_character': masking_character,
}
}
}
]
}
},
'item': {
'value': file_content
}
}
)
modified_content = response.item.value
# Save deidentify contents
with open(temp_file_path, 'w', encoding='utf-8') as file:
file.write(modified_content)
destination_bucket = storage_client.bucket(DEIDENTIFY_BUCKET)
destination_blob = destination_bucket.blob(source_file_name)
destination_blob.upload_from_filename(temp_file_path)
source_blob.delete() # delete item from the quarantine bucket
except Exception as e:
log(e, severity=LOG_SEVERITY_ERROR)
# Function dependencies, for example: # package>=version google-cloud-dlp google-cloud-storage google-cloud-logging
これで検疫バケットに下記のようなテキストファイルをアップロードしてみます。
田中太郎 メールアドレス:foobar@example.com 電話番号:4242424242424242
検疫バケットからは削除され匿名化後バケットにこのように匿名化されたファイルが保存されることが確認できました。
田中** メールアドレス:****************** 電話番号:****************
データの安全性を確保してから分析や機械学習用途で利用する際に有用なユースケースとなるのではないでしょうか。
以下の記事も匿名化に関連していますのでご興味があればぜひ確認ください。
