
はじめに
この記事はGoogle Cloud Next 2025で公開されたセッション「Bridge the gap: Unify your data with BigQuery multimodal tables」についてのセッションメモです。速報の記事になりますので、誤りなどがありましたら随時、修正していく予定です。
本セッションを理解するために必要な知識をおさらい
このセッションの内容を深く理解するためには、以下の分野に関する前提知識があると役立ちます。
データベースとデータウェアハウスの基礎:
【必須レベル:これがないと内容の理解が難しい】
テーブル、カラム、行、データ型: データベースの基本的な構成要素。
SQL: データを操作・照会するための言語。特にSELECT, FROM, WHERE, JOINなどの基本的な構文を知っていると、デモのクエリが理解しやすくなります。
データウェアハウス (DWH) とは何か: 大量のデータを分析目的で格納するシステムの概念。BigQueryがこれに該当します。
データの種類(構造化・半構造化・非構造化):
構造化データ: テーブル形式で整理されたデータ(例:顧客リスト、販売履歴)。
非構造化データ: 画像、音声、動画、自由記述テキストなど、決まった形式を持たないデータ。
半構造化データ: JSON、XMLなど、構造を持つがテーブル形式ではないデータ。
⇒ このプレゼンテーションの核心は「構造化データと非構造化データをいかに統合して扱うか」なので、これらの違いを理解していることが大前提となります。
Google Cloud の主要サービス知識:
- BigQuery: サーバーレス・データウェアハウスサービス。基本的な機能や特徴を知っているとスムーズです。
- Cloud Storage: オブジェクトストレージ。ファイルがここに保存されることが前提となっています。
- Vertex AI: 統合AIプラットフォーム。プレゼン内で触れられるGeminiモデルなどがホストされています。
- IAM (Identity and Access Management): アクセス権限管理の仕組み。Authorizer(認証・認可)の概念に関連します。
AI・機械学習 (ML) の基礎知識:
【推奨レベル:これがあるとより深く理解できる】
機械学習とは何か: データからパターンを学習し、予測や分類を行う技術。
大規模言語モデル (LLM): Geminiのような、大量のテキストデータで学習したAIモデル。
マルチモーダルAI: テキスト、画像、音声など複数の種類のデータを扱えるAI。
Pythonプログラミング:
【あれば尚可レベル:特定のトピックの理解に役立つ】
プレゼン後半で触れられるPython連携(BigQuery DataFrames, Python UDF)の部分を理解するのに役立ちます。
特にデータ分析ライブラリ(Pandasなど)の経験があればなお良いです。
データガバナンスの概念:
データに対するアクセス制御、セキュリティ、マスキングなどの管理手法。
列レベル・行レベルセキュリティなどの用語が出てきます。
とりわけ「構造化/非構造化データの違い」 と 「SQLの基本」 をおさえておくと、中心的なメッセージは理解しやすくなるでしょう。
セッションの内容を要約するとつまり
- 課題の提示: 従来、BigQuery内の構造化データと、Cloud Storage等にある画像・音声・動画といった非構造化データは分断されており、統合的な分析が困難でした。
- 新機能「Object Ref」導入: この課題を解決するため、BigQueryテーブル内にCloud Storage上の非構造化オブジェクトへの参照(URI、バージョン、権限情報など)を保持できる新しいカラム型「Object Ref」が導入されます。
- 統合分析の実現: Object Refを使うことで、構造化データと非構造化データへの参照を一つのテーブルで管理し、使い慣れたSQLやPythonを用いてシームレスに組み合わせた分析が可能になります。
- AI/ML連携の強化: BigQuery ML関数(
ml.generate_text等)にObject Refを直接渡すことで、SQLクエリから直接GeminiなどのAIモデルを呼び出し、非構造化データの内容分析(画像認識、音声テキスト化、感情分析など)を簡単に行えます。 - 高度な活用例: デモで示されたように、市民サービスのレポート(構造化)と提出されたメディア(画像、音声、動画)を組み合わせ、AIで潜在的な問題を検出したり、緊急度を判定したりするなど、より高度なインサイト抽出や業務効率化が期待できます。
本セッションで紹介されたObject RefというBigQueryの新機能は構造化データと非構造化データの間の壁を取り払い、両者を統合した高度な分析機能です。特にAI/MLを活用した分析をSQLやPythonを使ってより簡単かつスケーラブルに行うことを可能にできます。
セッションの内容(本編)
問題提起
データ活用の現場では、日々増え続ける多様なデータにどう向き合うかが大きな課題となっています。

特に、データベースに整然と格納された「構造化データ」と、画像、音声、動画、ドキュメントといった「非構造化データ」はそれぞれ異なるシステムで管理・分析されることが多いです。
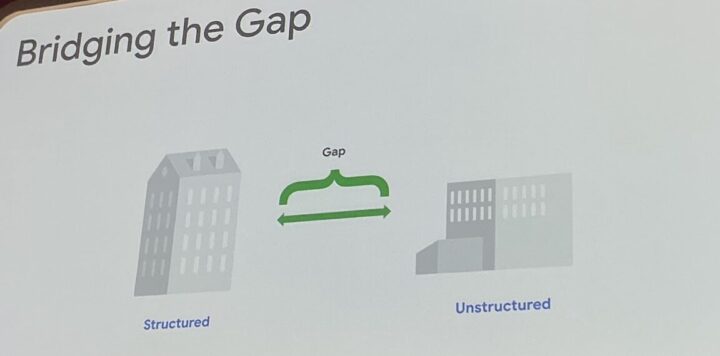
構造化データと非構造化データの両者を組み合わせて深い洞察を得ることは容易ではありませんでした。
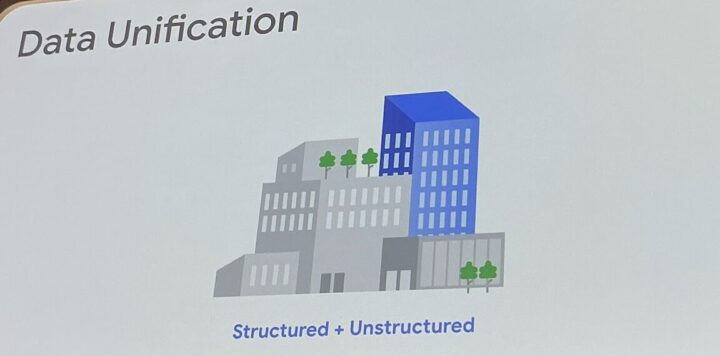
この長年の課題に対し、Google Cloudは強力な解決策を提示しました。
それが、データウェアハウスサービスであるBigQueryの新機能「Object Ref」です。この機能は、構造化データと非構造化データの間の壁を取り払い、真の統合データ分析プラットフォームへの道を拓く可能性を秘めています。
本記事では、この注目の新機能「Object Ref」について、その概要、可能になること、具体的な活用例、そして今後の展望までを詳しく解説します。
「Object Ref」とは何か? – 非構造化データへの”参照”をテーブルに格納
従来、BigQueryからCloud Storage上の非構造化データを利用するには、ファイルのパス(URI)を文字列として持つか、メタデータのみを扱う「Object Tables」機能を利用する必要がありました。
Object Tablesの説明
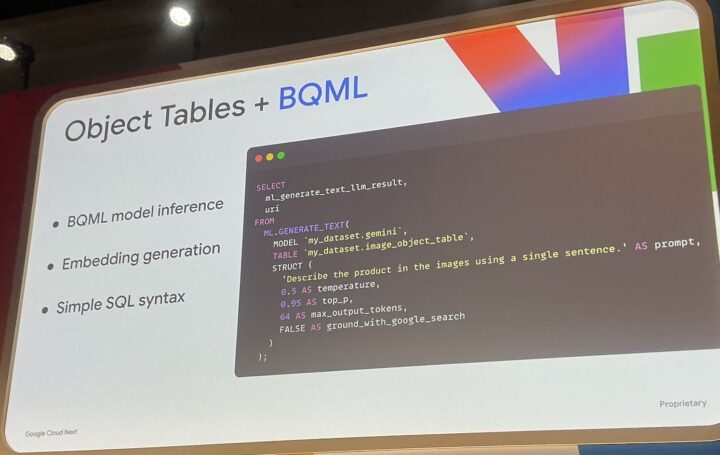
Object Tablesは一歩前進でしたが、読み取り専用、固定スキーマ、スケーラビリティといった制限も抱えていました。

Object Refは、これを根本的に進化させるアプローチです。これはBigQueryテーブル内の新しいカラム型(STRUCT型)であり、Cloud Storage上の非構造化オブジェクトへの参照情報を格納します。具体的には、以下の要素を含みます。
- URI: オブジェクトのCloud Storage上の場所
- Authorizer: そのオブジェクトへのアクセス権限情報(BigQueryが安全にアクセスするために使用)
- Version: オブジェクトの特定の世代ID(再現性の確保、特にMLワークフローで重要)
- Details: コンテンツタイプやサイズなどのCloud Storageメタデータ
これにより、非構造化データそのものではなく、その「参照」を構造化データと同じテーブル内で、ファーストクラスの市民として扱えるようになります。
Object Refの使い方・文法
Object Ref(Object Refs)を使い始める場合は以下のようにSQLを書きます。
SELECT OBJ.FETCH_METADATA(
OBJ.MAKE_REF(
'gs://bucket_name/file_name',
'us-central1.conn'
)
) As audio_ref
別の書き方もできます。
CREATE OR REPLACE EXTERNAL TABLE `db.table`
WITH CONNECTION `us-central1.conn`
OPTIONS (
object_metadata = 'SIMPLE',
uris = [gs://bucket_name/file_name'],
)
Object Refが可能にすること:統合分析とAI連携のブレークスルー
Object Refの導入により、データ分析のワークフローは劇的に変化します。

1.シームレスな統合分析:
構造化データ(例:顧客情報、販売履歴)と、それに関連する非構造化データへの参照(例:問い合わせ時の音声ファイル、返品時の商品写真)を、同じSQLクエリ内で簡単にJOINしたり、フィルタリングしたりできます。「特定の期間に高評価を付けた顧客のレビュー音声」といった分析が、格段にシンプルになります。

※Object Refは配列で利用可能

※複数持たせることも可能

2.SQLからのダイレクトAI/ML連携:
これがObject Refの最も強力な側面の一つです。
BigQuery MLの関数(ml.generate_text, ai.generate_boolなど)に、Object Refカラムを直接渡すことができます。これにより、例えば以下のようなことがSQLだけで可能になります。
SELECT ml.generate_text(product_image_ref, 'この商品の説明文を生成して') FROM products;(商品画像のObject Refから説明文を自動生成)-
SELECT customer_id, ai.generate_bool(call_audio_ref, 'この顧客は購入意欲が高いか?') FROM call_logs;(通話音声のObject Refから購入意欲を判定)
さらに、Geminiのような強力なマルチモーダルAIモデルと連携し、画像の内容記述、音声の文字起こしや感情分析、動画の要約などを、使い慣れたSQLインターフェースから実行できるのです。複数のObject Ref(例:画像とテキスト指示)を同時にモデルに渡すことも可能です。

3.Pythonとの親和性:
SQLだけでなく、Pythonユーザーも恩恵を受けられます。BigQuery DataFramesやPython UDF(ユーザー定義関数)内でObject Refを扱うことができ、Pandasライクな操作やカスタムライブラリを用いた高度な処理も可能です。

4.堅牢なガバナンス:
Object Refカラムにも、既存のBigQueryの列レベル・行レベルのアクセス制御やデータマスキングといったガバナンス機能をそのまま適用できます。これにより、機密性の高い非構造化データへのアクセスも安全に管理できます。


活用事例:市民サービス「311」でのマルチモーダル分析
セッションでは市民からのインシデント報告サービス「311」を例にしたデモンストレーションが紹介されました。

- データ: 市民からの報告内容(テキスト、発生場所などの構造化データ)と、添付されたメディアファイル(写真、音声、動画)のObject Refを統合したテーブルを作成。
- 分析:
- 画像分析: 報告された問題(例:不法投棄)の写真から、AIが二次的な問題(例:背景の落書き)を自動検出。
- 音声分析: 報告時の音声データから、AIが声のトーンなどを分析し、緊急度を判定。
- 動画分析: 状況の推移を示す動画から、AIが安全への影響度を評価。
- 統合評価: テキスト、画像、音声、動画のすべての情報をAIに入力し、状況の総合的なサマリー、推奨される対応部署、AIによる緊急度スコアを生成。これにより、人間が見落としがちな情報も加味した、より客観的で効率的な優先順位付けが可能に。
※不法投棄された画像から動画を生成、デモではこのシーンに投棄されたゴミが燃える演出を加えていた
このように、Object Refは複数のデータモダリティを組み合わせた高度な分析を可能にし、より的確な意思決定や業務プロセスの改善に貢献します。
メリットと考慮点
- メリット
- データ分析パイプラインの大幅な簡素化
- 構造化・非構造化データを組み合わせた新たなインサイトの発見
- SQL/Pythonによる開発効率の向上
- 既存のBigQueryエコシステム(セキュリティ、ML、BIツール連携)の活用
- 考慮点
- 現時点ではCloud Storage上のオブジェクトが対象。
- AI/ML関数を利用する場合、BigQueryのコンピューティングコストとは別に、Vertex AIなどのモデル利用コストが発生(ただしBigQueryからは割安なバッチAPIを利用)。
- 本記事執筆時点(2025年4月)ではプレビュー段階であり、一般提供に向けて機能が変更・追加される可能性があります。

まとめと今後の展望

BigQuery Object Refは、構造化データと非構造化データの統合という長年の課題に対するGoogle Cloudの意欲的な実装です。
SQLやPythonといった使い慣れたツールで、画像、音声、動画といった多様なデータをシームレスに扱い、さらにAI/MLの力を容易に組み合わせることを可能にします。
この機能は、2025年5月上旬にプレビューが開始される予定で、夏にはAllowlistなしのパブリックプレビュー、秋には一般提供(GA)が計画されています。将来的には、接続管理の簡素化、パフォーマンスとスケーラビリティの向上、データリネージュとの連携強化、Analytics Hubを通じた非構造化データ参照の共有なども検討されています。

データ分析の可能性を大きく広げるObject Ref。ぜひプレビューにサインアップし、その力をいち早く体験してみてはいかがでしょうか。
今後のBigQueryの進化から目が離せません。

感想
最初に構造化と非構造化の紹介、定義を説明している場面があったのですが、説明に使っている画像がとてもわかりやすいものでした。
本セッションではわかったこととしてはBigQueryはさらなる進化を遂げるということです。
それを裏付けるような機能として今回はObject Refの紹介がありました。
この機能は構造化データと非構造化データの統合という長年の課題に対するGoogle Cloudの意欲的な実装だと思いました。
Object RefはSQLやPythonといった使い慣れたツールで画像、音声、動画といった多様なデータをシームレスに扱い
その上でAI/MLの力を容易に組み合わせることを可能にします。
本セッションでも取り扱いがありましたが、複数の画像をBigQueryに保存
保存した画像それぞれに対してGeminiによる推論を実行して動画することができます。
これはメディアを扱う企業にとっては非常に大きなメリットになるのではないのでしょうか。
また、デモを見た時に最初に思い浮かんだこととしてはOpening Keynoteでも紹介があったVertex AI Media Studioでできることが
データサイエンスのスタックに流れ込んだというイメージでした。
今後のBigQueryの進化によってはデータとAI/MLの組み合わせがさらに簡単になり、ある種のメディアプラットフォームになる可能性があります。
ロードマップも示されていたので今後の動向に期待したいと思います。
ここも読んでおきたい(関連資料)
- Object Table
- 本セッションで比較対象に挙げられていた機能




