
内部統制推進室 兼 クラウドインテグレーション事業部の廣山です。
遅ればせながら、Google Cloud Next 2025 現地参加1日目のイベントレポートをお届けいたします。
セッション情報
セッションタイトル:Best-kept security secrets: How Sensitive Data Protection can support developer testing
はじめに
開発者の皆さんなら、テストの重要性は痛感しているはずです。アプリケーションの機能を隅々までテストするためには、本番環境に近いリアルなデータが不可欠です。
しかし、ここで大きな課題となるのがデータプライバシーです。本番データをそのまま利用することは論外です。顧客の個人情報、財務情報、医療情報などの機密データをそのままテストに利用することは、情報漏洩のリスクを高め、企業の信頼失墜や経済的損失につながりかねません。
かといって、合成データや偽のデータだけでは、現実世界の複雑なエッジケースを捉えきれず、テストの品質が低下する可能性があります。
さらに、データも必要十分な数を用意する必要があります。
このように、「現実味」「規模」「ガバナンス」のバランスをどう取るかは、開発者にとって頭を悩ませる問題です。
Sensitive Data Protection
そこで登場するのが、Google Cloud Sensitive Data Protection (STP) です。STPは、クラウド環境における機密データの検出、分類、保護を支援する強力なツールです。特に開発者にとって重要なのは、STPがリアルなデータを検査し、匿名化(de-identification)できる点です。
STPは、機密データ保護のためにデータ検出と保護の機能を提供します
データ検出 (Discovery)
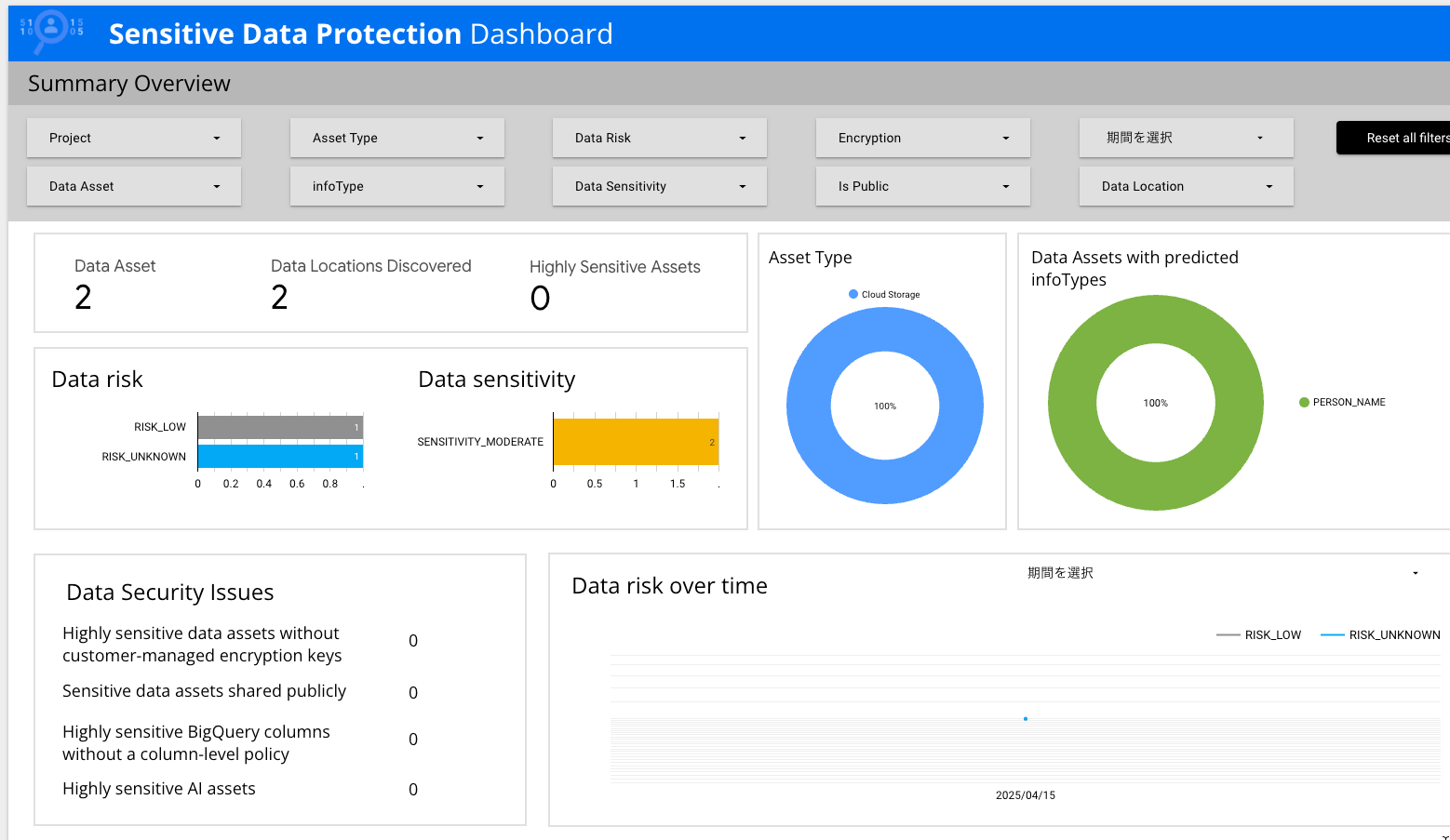
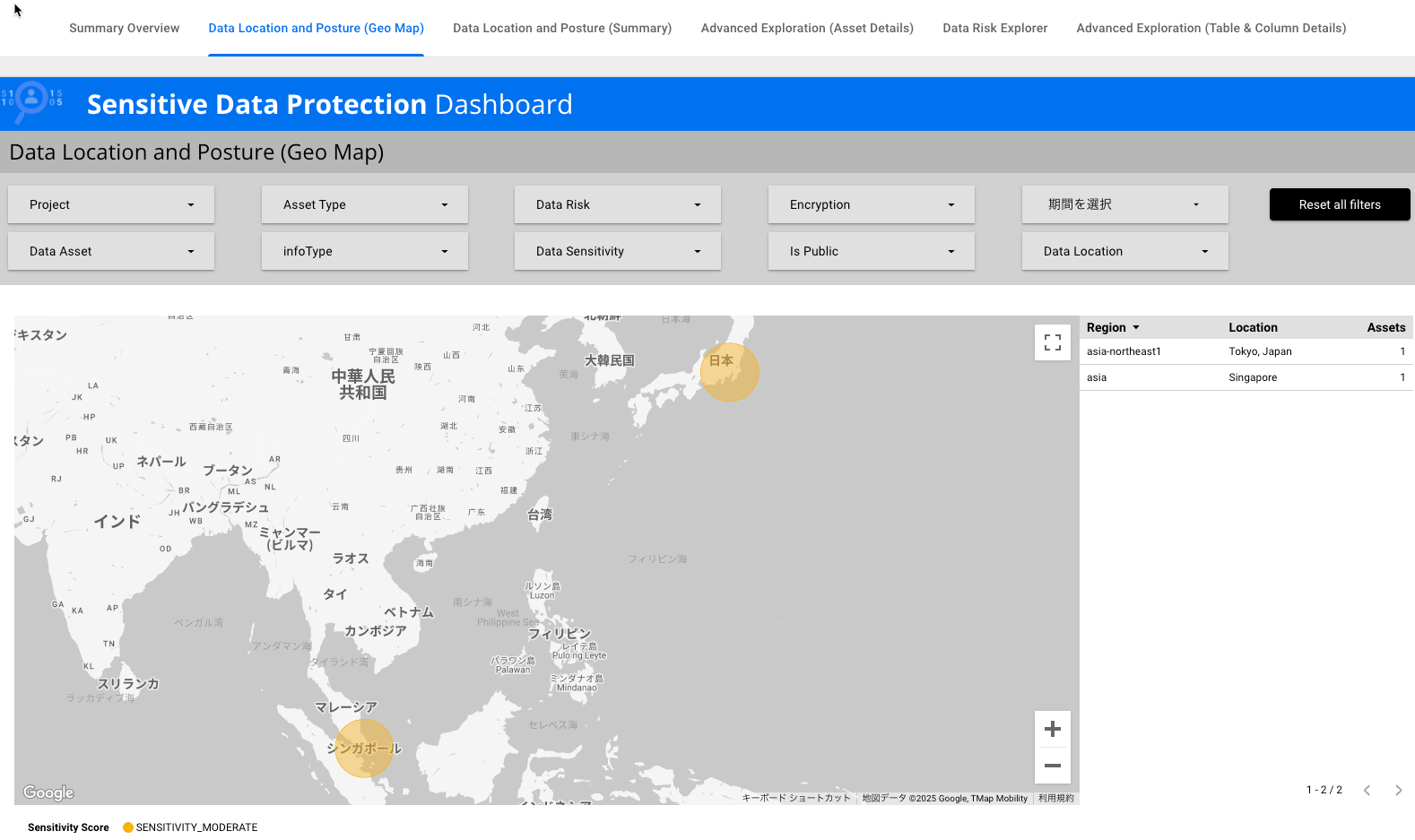
プロジェクト、フォルダ、ワークレベル全体から機密データのサンプルを採取し、プロファイリングします。Cloud Storageバケット、BigQueryデータセット、Cloud SQLなどを対象に、どのような機密データがどこに存在するかを把握できます。結果は、Looker Studio で確認可能です。
200種類以上の組み込みの分類子(個人名、メールアドレスなど)や、正規表現や辞書ベースのカスタム分類子を利用して、データの機密性を特定・分類します。
実際に設定してみましたが、ものの数分で検出の設定が完了し、以下のようなダッシュボードまで作ることができました。
保護 (Safeguarding)
検出された機密データに対して、多様な匿名化手法を適用できます。
STPが提供する匿名化手法は多岐にわたります。
墨消し (Redaction): 機密データを完全に削除します。
置換 (Replacement): 機密データを指定した文字列(例:「メールアドレス」)やアスタリスクなどに置き換えます。
マスキング (Masking): メールアドレスなどの個々の文字を置換します。
バケット化 (Bucketing): データを一般的なカテゴリに分類します(例:年齢層)。
トークン化 (Tokenization): 一方向(ハッシュ化)または双方向(可逆的)の暗号化を用いて、機密データを意味のないトークンに置き換えます。独自の暗号鍵を使用することも可能です。
日付と時間のシフト (Date/Time Shifting): 特定の期間内で日付をランダムにずらすことで、個人を特定できる可能性を低減します。
画像のリダクション (Image Redaction): 画像内の特定の情報(テキストなど)を削除または隠蔽します。
STP を活用した開発ワークフロー
検出した機密データを、自動的に匿名化して、指定のストレージに保存することができます。
これによって、開発者は極めて本番データに近い量、かつデータは本番のものだが、安全なもののみを利用することができます。
まとめ
STP はそれほど新しい機能ではないですが、AI 時代によるデータの安全な利活用へのニーズの高まりに対して、改めて重要になってくるであろうサービスと思いました。




